过往情况回顾
在上一次的博文中,学习了感知机和BPNN算法,我们可以做一个简单的知识点总结:
- 激活函数是非线性的
- 深度网络比浅层网络更具表现力
- 一个三层神经网络可以表达任意函数(足够的隐藏单元)
- 神经网络相当于图灵机(现代计算机)
- 计算性能的发展推动神经网络的发展
- 深度神经网络可以充分利用计算机能力
- 多层感知器是一个神经网络
激活函数
- sigmoid函数
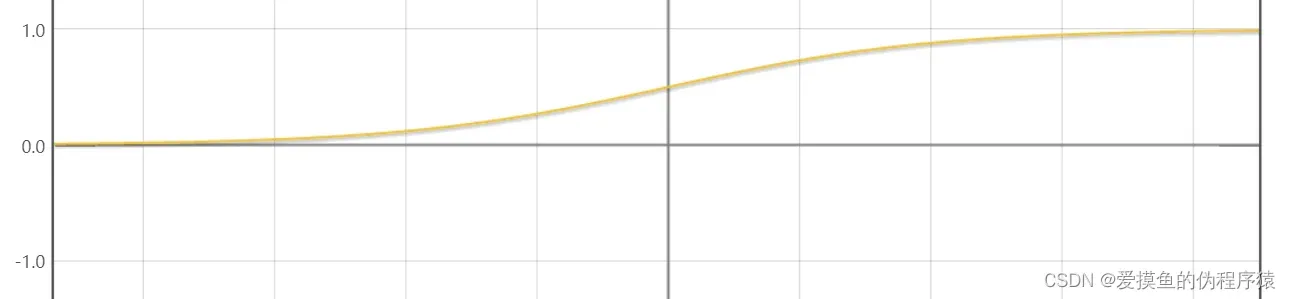
特征:
- 由于该函数的取值范围为(0,1),所以我们可以很轻易地将其与概率对应起来
- 其实这个函数经常被用来解决或反映二分类问题
- 这个函数在反向传播中更容易计算,因为它的导数是
- 但该功能将存在
渐变消失
现象
- tanh函数
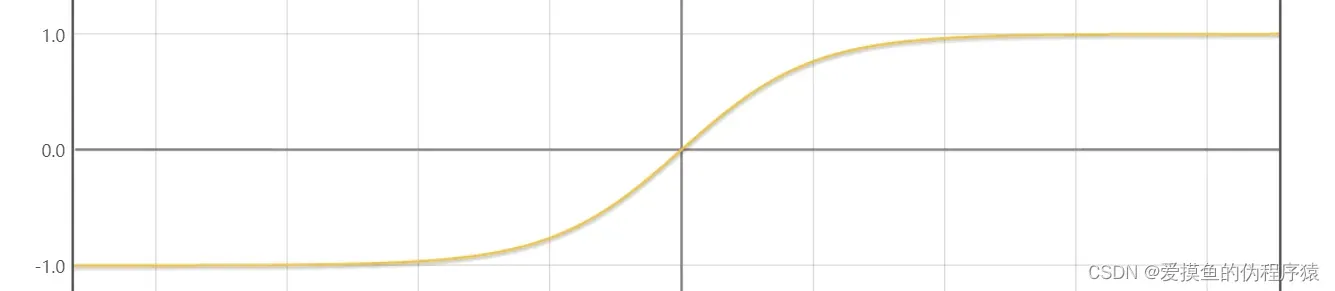
特征:
- 跟sigmoid函数非常像,可以看成sigmoid函数在竖直方向拉伸了两倍
- 解决了sigmoid函数收敛较慢的问题,提高了收敛速度
- 由于其导数的取值范围为(0,1),所以不用担心
梯度爆炸
问题
- ReLu函数
(PS:画不出来,随便搜了一个)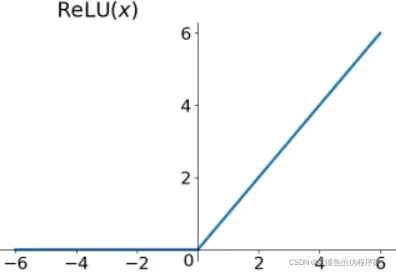
特征:
- 虽然这个函数的结构很简单,但是在梯度下降方面,这个算法可以说是一个里程碑式的算法,极大地提升了深度学习的性能。
- 由于它的有效导数是1,所以ReLu函数可以完美避免梯度爆炸和梯度消失的问题
- 同时它的计算也很简单,只需要简单的判断,几乎不需要计算导数。
- ReLu函数的收敛速度相较于sigmoid函数和tanh函数要快很多
- 缺点是x<0的部分导数为0,这会导致一些节点失效,为计算带来影响
实验题:自动微分算法的应用
- 计算图
: 简单理解,就是用图表的形式来表达计算。 - 自动微分
:是一种数值计算方法,用于计算因变量对自变量的导数。
建筑模型:
- 计算图
:
首先计算整体的局部微分,然后根据我们的需要对局部微分进行积分,得到我们想要的结果。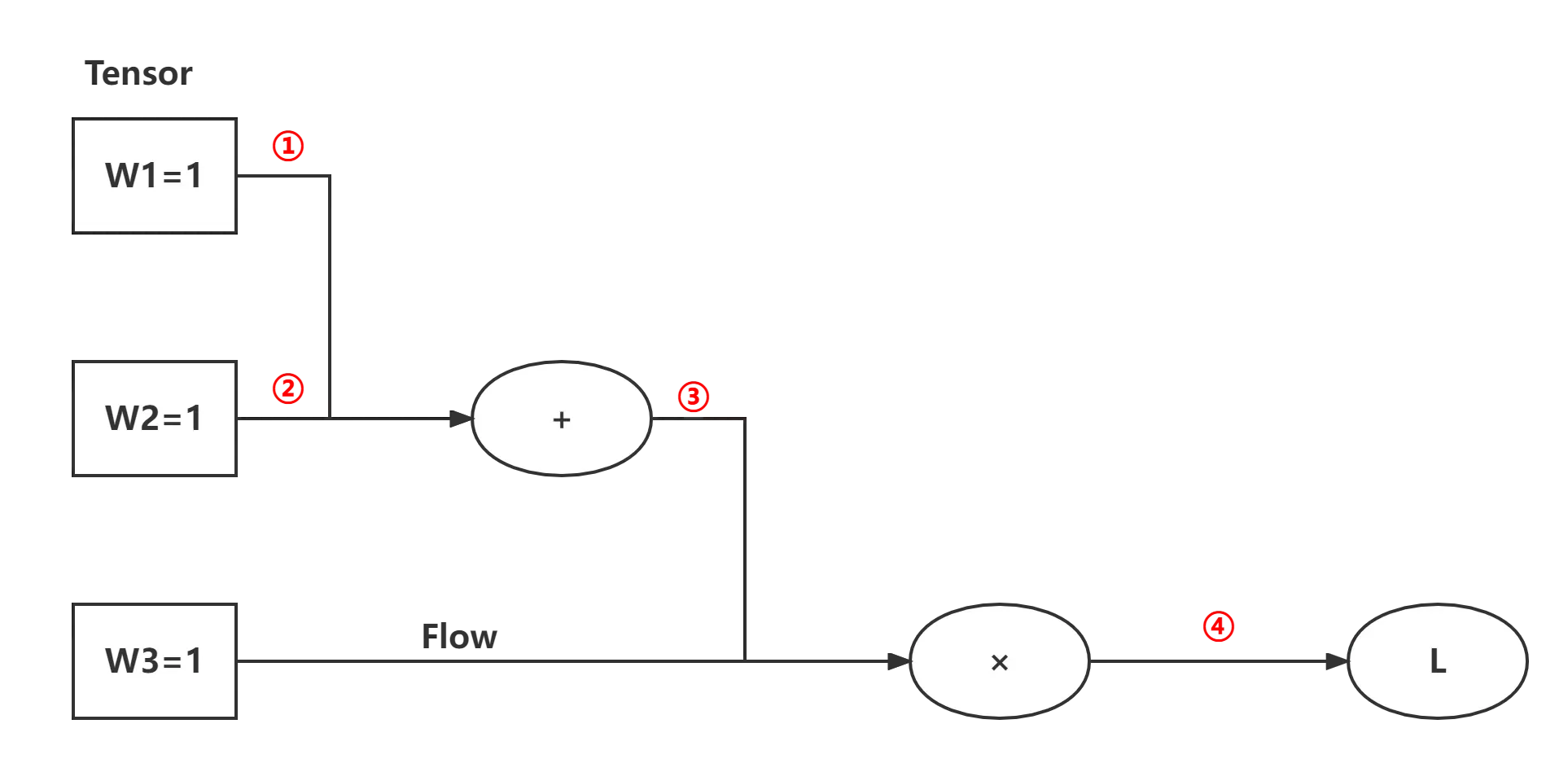
- 链式法则
:
- 自动微分
:
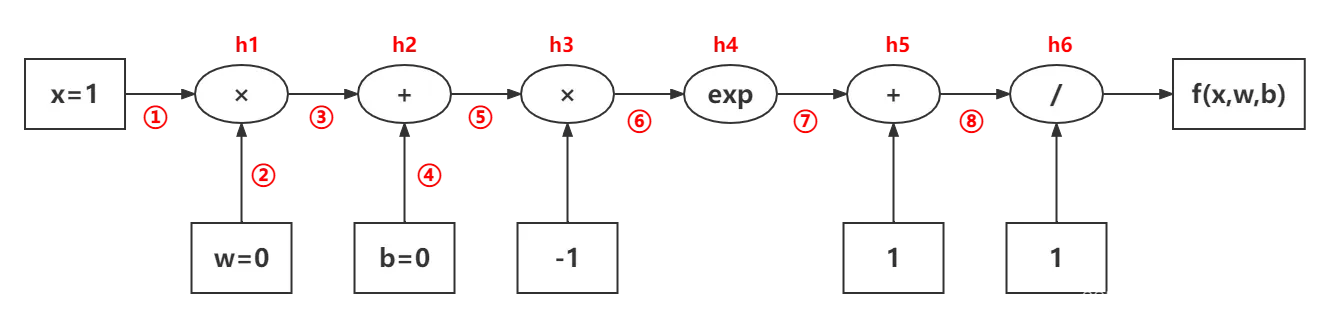
可见,反向传播算法只是自动微分的一种特殊形式
优点:计算复用,提高计算效率
- 渐变消失
:梯度消失是传统神经网络训练中一个非常致命的问题,其本质是由链式法则的乘法性质引起的。
例如,在只有三个隐藏层的神经网络中,当梯度消失时,靠近输出层的隐藏层的权重更新比较正常,但对于靠近输入层的隐藏层,权重几乎没有更新。变化或者变得很慢,而且还是很接近初始化的权重,这就导致了靠近输入层的部分隐藏层其实只是一个映射层,只对所有输入起映射作用。
实验程序
这个实验是为了更好的研究自动微分,我们做了不同的实验:
- 用计算图和自动微分解决简单的逻辑问题,例如 XOR
- 利用自动微分观察sigmoid函数存在的梯度消失问题
- 用ReLu函数代替sigmoid函数,看看是否能解决梯度消失的问题
- 使用计算图和自动微分解决简单的 XOR 问题
在做第一个实验之前,我们需要研究 XOR 问题的计算图
对感知器的一些了解可以参考我之前的文章:
AI学习——感知机和BPNN算法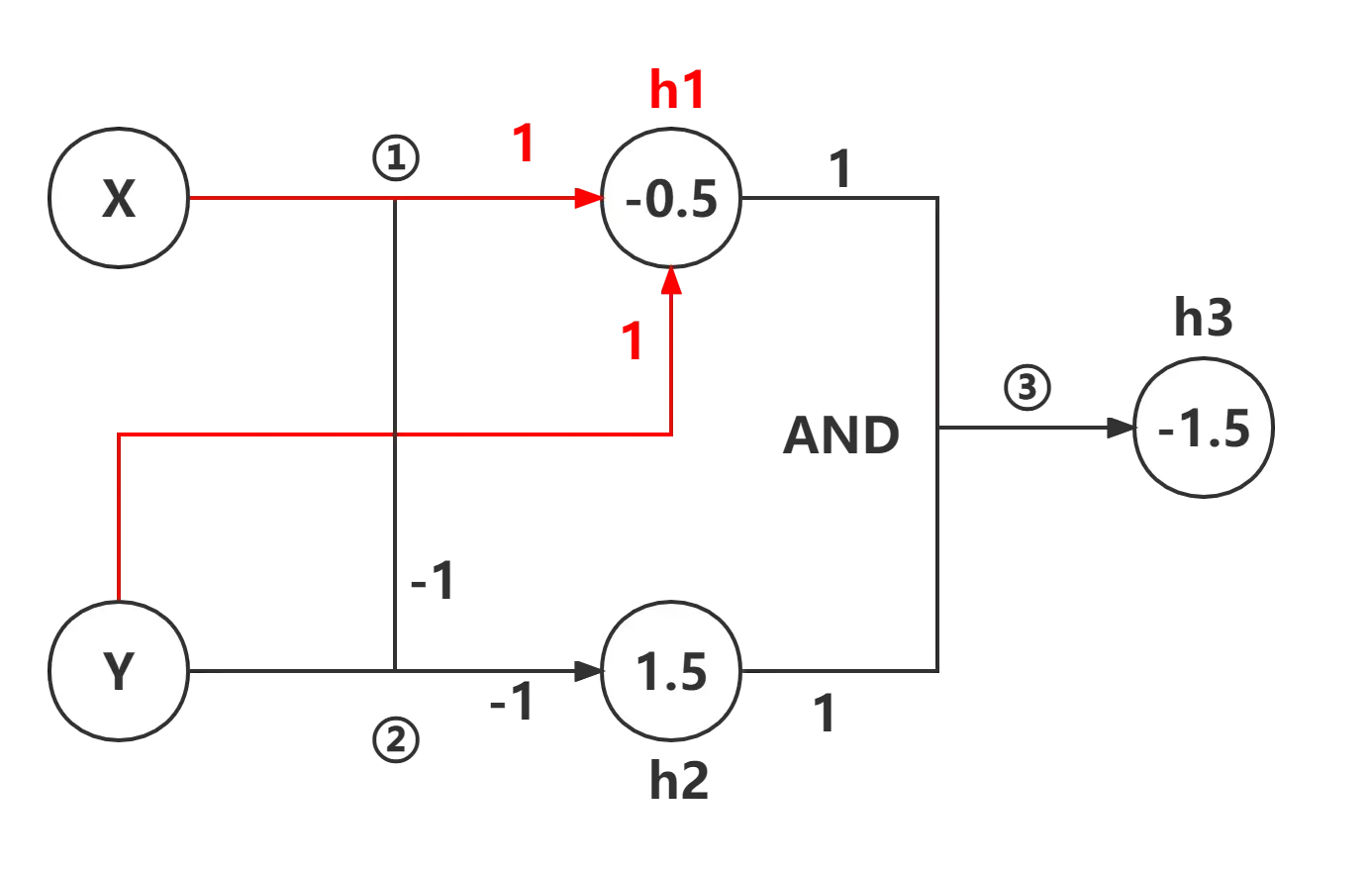
计算图的计算思路是
:将相同路径的梯度相乘,不同路径的梯度相加
分析如下:
从计算图和分析的结果可知,除了输入x,Y和我们最终所需要的预测值y,我们至少还需要共计9个参数。
于是,实验开始
- 利用自动微分的框架,我们首先需要定义一个激活函数,这里我们选用的是sigmoid函数。因为我们前面提到过,sigmoid函数在解决二分类问题非常有效,且计算简单

- 接下来我们开始定义输入的值,以及我们预测的值和另外9个参数,其中预测值需要根据我们之前分析的结果,代入9个参数进行迭代。由于当时的能力不足,在最初做实验的时候我只能将值一个一个的输入,无法像之前的实验那样一次输入一个数组进行判断,这样的计算效率无疑是非常低的

- 调用梯度下降函数,放入循环,训练,迭代,计算其中的损失函数,直到预测值不断接近我们想要的结果

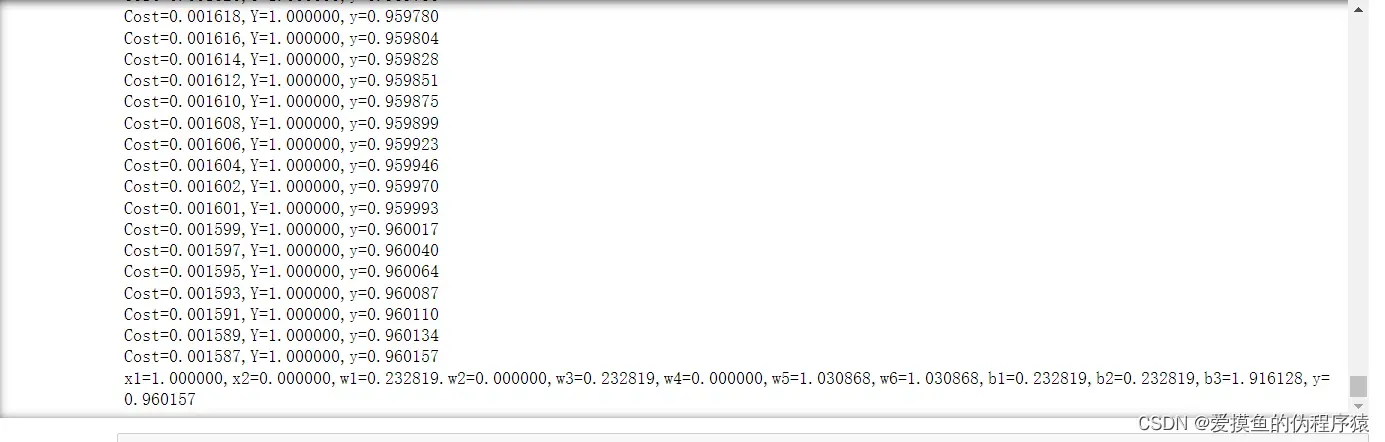
- 求解异或问题的自动微分优化
在上面的实验中,我们提到了一次只能输入一个值进行计算的缺点,效率低下且笨拙。方法)

核心思想保持不变,但老师的代码看起来明显更简洁干净
- 利用自动微分观察sigmoid函数存在的梯度消失问题
为了更好地研究梯度消失,我们还需要设计一个简单的神经网络。下面的神经网络一共有四个隐藏层,但是每个隐藏层只包含一个单元节点,这就导致了这个神经网络虽然隐藏层比较多,但是还是很简单的

根据梯度的值,我们可以做一个简单的判断来判断结果的取值范围,将结果分为三个部分:
,由于不断的迭代,最后的预测值y一定会无限接近于3,所以这个值应该是无限接近于0
,这部分的权值是我们给定的,一般来说不会太大,通常情况下都为1
,由于我们使用的激活函数是sigmoid函数,我们知道其导数的取值范围是
,所以该部分的取值范围应该是
综上可知,其求导的结果的取值应该是小于0的,而我们的神经网络自动微分,是通过每一层的梯度自动运算,来求解其他的参数或权值,由于每一层的梯度太小,通过链式法则求到的值自然也是非常小的,这种细微的变化可以忽略不计,这就是我们之前提到的梯度消失,神经网络最靠近输入层的那部分隐藏层也就成了映射层
为了更好地观察到梯度消失的现象,在实验过程中我将神经网络设置了10层隐藏层

- 移花接木,ReLu函数登场!
之前我们就提到,ReLu函数可以完美地解决梯度爆炸和梯度消失的问题。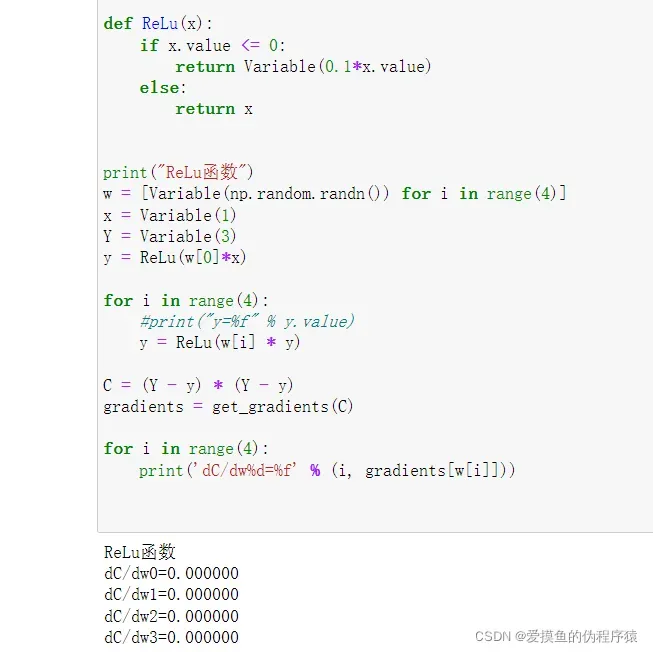
这种感觉似乎充满了热情。
为什么带入了ReLu函数之后结果反而没有了。
经过反复研究和观察,我得出结论:
由于我这次设计的神经网络过于简单,每层都只有一个节点,而ReLu函数的值在遇到<0的输入时,其导数是0,这也就意味之,只要其中一个节点的导数值为0,在链式法则求解出后续值的过程中,结果都为0。
解决方案:
- 为了使神经网络复杂化,为每个隐藏层设置几个神经单元
- ReLu函数的改造,给<0的部分的函数同样设置一个系数,让其不等于0
- 卷土重来,进化吧!ReLu函数!
- 这次我们将ReLu函数稍作修改,将其进化成leaky ReLu函数,x<0时,给其带上一个系数0.01

- 然后根据前面的分析,我们把我们的神经网络复杂化了。由于能力问题,我只能手动写一个两层隐藏层和三节点神经网络

这时候我们会发现我们得到了一个乱七八糟的渐变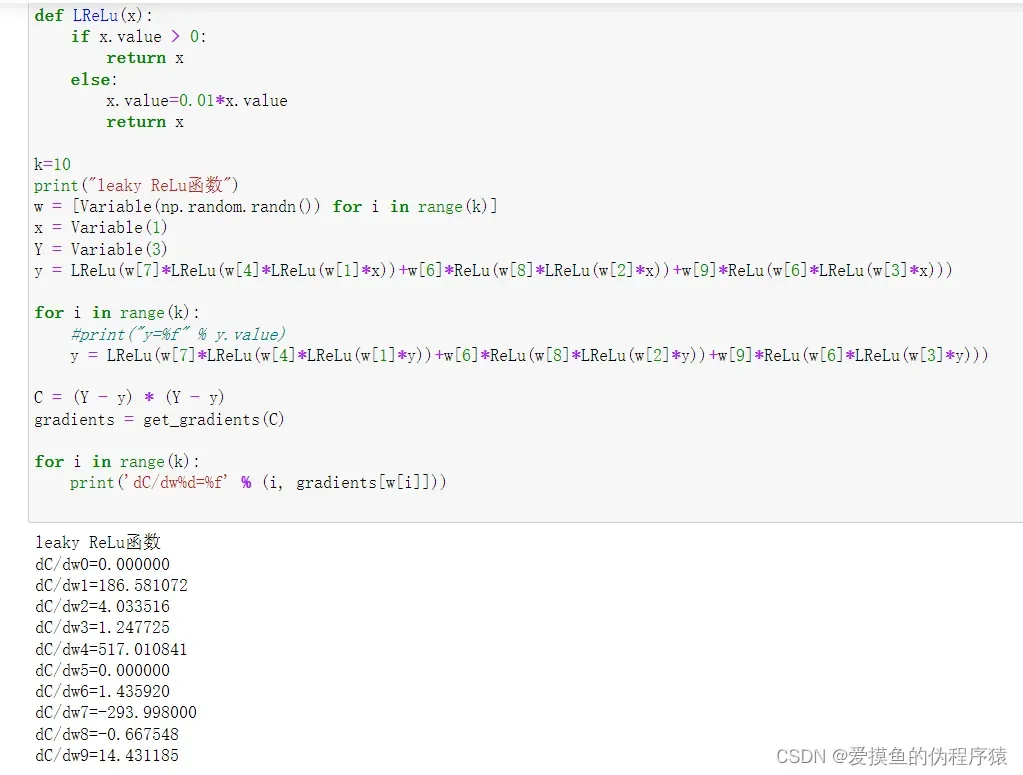
是的,虽然还是会有个别零值,但也是因为神经网络不够复杂,训练次数不够。至少我们已经能够成功解决梯度消失的问题。
实验结果
- 使用计算图和自动微分解决简单的 XOR 问题
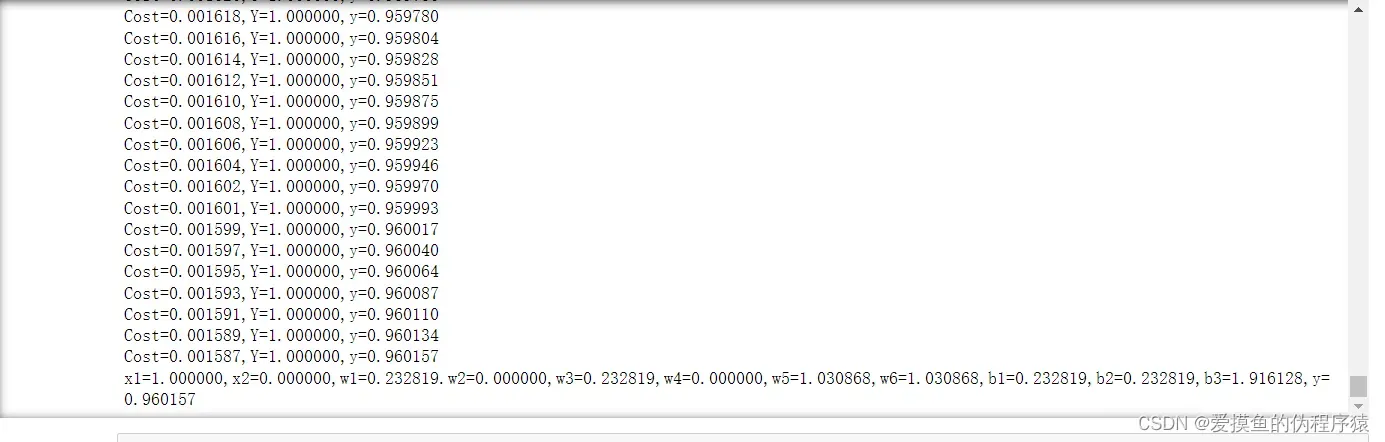
- 求解异或问题的自动微分优化

- 利用自动微分观察sigmoid函数存在的梯度消失问题

- 进化的ReLu函数(leaky ReLu)解决梯度消失问题

概括
在这个自动微分算法的学习过程中,我们学到了以下知识:
- 神经网络的本质——一个接一个的计算表达式
- 计算图和自动微分原理
- Python编程能力的提升
- 逐渐学会用电脑思维去思考问题
作为一个AI小白,通过这次学习我能够感觉到自己的学识有了很大的提升,但是AI领域深似海,一望无际,我在其中飘荡,好似一叶扁舟,越是往深处走,越是发觉自己的无知,越要谦虚谨慎,我的代码仍有许多不足,我的理解也会有很多欠缺的、没有考虑到地方。
有新想法,欢迎交流指正!

代码
# 自动微分框架源码
from collections import defaultdict
import numpy as np
class Variable:
def __init__(self, value, local_gradients=[]):
self.value = value
self.local_gradients = local_gradients
def __add__(self, other):
return add(self, other)
def __mul__(self, other):
return mul(self, other)
def __sub__(self, other):
return add(self, neg(other))
def __neg__(self):
return neg(self)
def __truediv__(self, other):
return mul(self, inv(other))
def add(a, b):
value = a.value + b.value
local_gradients = ((a, 1), (b, 1))
return Variable(value, local_gradients)
def mul(a, b):
value = a.value * b.value
local_gradients = ((a, b.value), (b, a.value))
return Variable(value, local_gradients)
def neg(a):
value = -1 * a.value
local_gradients = ((a, -1),)
return Variable(value, local_gradients)
def inv(a):
value = 1. / a.value
local_gradients = ((a, -1 / a.value ** 2),)
return Variable(value, local_gradients)
def exp(a):
value = np.exp(a.value)
local_gradients = ((a, value),)
return Variable(value, local_gradients)
def get_gradients(variable):
gradients = defaultdict(lambda: 0) # 可以根据Variable变量地址索引对应的梯度
def compute_gradients(variable, path_value):
for child_variable, local_gradient in variable.local_gradients: # 两条路径循环2次
value_of_path_to_child = path_value * local_gradient # 从后往前,乘以每条边的梯度
gradients[child_variable] += value_of_path_to_child # 不同路径的梯度相加,算的是局部偏微分
compute_gradients(child_variable, value_of_path_to_child) # 递归整个计算图
compute_gradients(variable, path_value=1) # path_value=1,输出对自己的偏微分为1
return gradients
def sigmoid(z):
ONE = Variable(1)
return ONE / (ONE + exp(-z))
x = Variable(1)
w = Variable(0)
b = Variable(0)
Y = Variable(1)
y = sigmoid(w * x + b)
gradients = get_gradients(y)
print('dy/dw=%f, dy/db=%f' % (gradients[w], gradients[b]))
for i in range(1000):
y = sigmoid(w * x + b)
C = (y - Y) * (y - Y)
print('Cost=%f,y=%f' % (C.value, y.value))
gradients = get_gradients(C)
w.value = w.value - 0.1 * gradients[w]
b.value = b.value - 0.1 * gradients[b]
# 感知机初始代码,但是由于Variable类型,最开始只能一次输入一个值进行运算
from collections import defaultdict
import numpy as np
class Variable:
def __init__(self, value, local_gradients=[]):
self.value = value
self.local_gradients = local_gradients
def __add__(self, other):
return add(self, other)
def __mul__(self, other):
return mul(self, other)
def __sub__(self, other):
return add(self, neg(other))
def __neg__(self):
return neg(self)
def __truediv__(self, other):
return mul(self, inv(other))
def add(a, b):
value = a.value + b.value
local_gradients = ((a, 1), (b, 1))
return Variable(value, local_gradients)
def mul(a, b):
value = a.value * b.value
local_gradients = ((a, b.value), (b, a.value))
return Variable(value, local_gradients)
def neg(a):
value = -1 * a.value
local_gradients = ((a, -1),)
return Variable(value, local_gradients)
def inv(a):
value = 1. / a.value
local_gradients = ((a, -1 / a.value ** 2),)
return Variable(value, local_gradients)
def exp(a):
value = np.exp(a.value)
local_gradients = ((a, value),)
return Variable(value, local_gradients)
def get_gradients(variable):
gradients = defaultdict(lambda: 0) # 可以根据Variable变量地址索引对应的梯度
def compute_gradients(variable, path_value):
for child_variable, local_gradient in variable.local_gradients: # 两条路径循环2次
value_of_path_to_child = path_value * local_gradient # 从后往前,乘以每条边的梯度
gradients[child_variable] += value_of_path_to_child # 不同路径的梯度相加,算的是局部偏微分
compute_gradients(child_variable, value_of_path_to_child) # 递归整个计算图
compute_gradients(variable, path_value=1) # path_value=1,输出对自己的偏微分为1
return gradients
def sigmoid(z):
ONE = Variable(1)
return ONE / (ONE + exp(-z))
x1=Variable(1)
x2=Variable(0)
Y=Variable(1)
w1= Variable(0)
w2= Variable(0)
w3= Variable(0)
w4= Variable(0)
w5= Variable(0)
w6= Variable(0)
b1= Variable(0)
b2= Variable(0)
b3= Variable(0)
y = sigmoid(w5*sigmoid(x1*w1+x2*w2+b1)+w6*sigmoid(x1*w3+x2*w4+b2)+b3)
gradients = get_gradients(y)
#print('dy/dw1=%f, dy/dw2=%f,dy/dw3=%f,dy/dw3=%f,dy/dw3=%f' % (gradients[w1], gradients[w2],gradients[w3]))
for i in range(1000):
y = sigmoid(w5*sigmoid(x1*w1+x2*w2+b1)+w6*sigmoid(x1*w3+x2*w4+b2)+b3)
C = (y - Y) * (y - Y)
print('Cost=%f,Y=%f,y=%f' % (C.value,Y.value, y.value))
gradients = get_gradients(C)
w1.value = w1.value - 0.1 * gradients[w1]
w2.value = w2.value - 0.1 * gradients[w2]
w3.value = w3.value - 0.1 * gradients[w3]
w4.value = w4.value - 0.1 * gradients[w4]
w5.value = w5.value - 0.1 * gradients[w5]
w6.value = w6.value - 0.1 * gradients[w6]
b1.value = b1.value - 0.1 * gradients[b1]
b2.value = b2.value - 0.1 * gradients[b2]
b3.value = b3.value - 0.1 * gradients[b3]
print('x1=%f,x2=%f,w1=%f.w2=%f,w3=%f,w4=%f,w5=%f,w6=%f,b1=%f,b2=%f,b3=%f,y=%f' % (x1.value,x2.value,w1.value,w4.value,w3.value,w4.value,w5.value,w6.value,b1.value,b2.value,b3.value,y.value))
#感知机改良算法,成功的输入了数组,让计算更加简单便捷
from collections import defaultdict
import numpy as np
class Variable:
def __init__(self, value, local_gradients=[]):
self.value = value
self.local_gradients = local_gradients
def __add__(self, other):
return add(self, other)
def __mul__(self, other):
return mul(self, other)
def __sub__(self, other):
return add(self, neg(other))
def __neg__(self):
return neg(self)
def __truediv__(self, other):
return mul(self, inv(other))
def add(a, b):
value = a.value + b.value
local_gradients = ((a, 1), (b, 1))
return Variable(value, local_gradients)
def mul(a, b):
value = a.value * b.value
local_gradients = ((a, b.value), (b, a.value))
return Variable(value, local_gradients)
def neg(a):
value = -1 * a.value
local_gradients = ((a, -1),)
return Variable(value, local_gradients)
def inv(a):
value = 1. / a.value
local_gradients = ((a, -1 / a.value ** 2),)
return Variable(value, local_gradients)
def exp(a):
value = np.exp(a.value)
local_gradients = ((a, value),)
return Variable(value, local_gradients)
def get_gradients(variable):
gradients = defaultdict(lambda: 0) # 可以根据Variable变量地址索引对应的梯度
def compute_gradients(variable, path_value):
for child_variable, local_gradient in variable.local_gradients: # 两条路径循环2次
value_of_path_to_child = path_value * local_gradient # 从后往前,乘以每条边的梯度
gradients[child_variable] += value_of_path_to_child # 不同路径的梯度相加,算的是局部偏微分
compute_gradients(child_variable, value_of_path_to_child) # 递归整个计算图
compute_gradients(variable, path_value=1) # path_value=1,输出对自己的偏微分为1
return gradients
def sigmoid(z):
ONE = Variable(1)
return ONE / (ONE + exp(-z))
#自动微分实现异或
w = [Variable(np.random.randn()) for i in range(9)]
def f(x1,x2):
x1 = Variable(x1)
x2 = Variable(x2)
h1 = sigmoid(x1*w[0]+x2*w[1]+w[2])
h2 = sigmoid(x1*w[3]+x2*w[4]+w[5])
ho = sigmoid(w[6]*h1+w[7]*h2+w[8])
return ho
for i in range(30000):
C = (f(0,0) - Variable(0)) * (f(0,0) - Variable(0))
C = (f(0,1) - Variable(1)) * (f(0,1) - Variable(1)) + C
C = (f(1,0) - Variable(1)) * (f(1,0) - Variable(1)) + C
C = (f(1,1) - Variable(0)) * (f(1,1) - Variable(0)) + C
print('Epoch %d, Cost=%f' % (i,C.value))
gradients = get_gradients(C)
for j in range(len(w)):
w[j].value = w[j].value - 0.1 *gradients[w[j]]
print("f(0,0)=%f" % f(0,0).value)
print("f(0,1)=%f" % f(0,1).value)
print("f(1,0)=%f" % f(1,0).value)
print("f(1,1)=%f" % f(1,1).value)
# 研究我们之前提到的sigmoid函数存在的梯度消失现象
from collections import defaultdict
import numpy as np
class Variable:
def __init__(self, value, local_gradients=[]):
self.value = value
self.local_gradients = local_gradients
def __add__(self, other):
return add(self, other)
def __mul__(self, other):
return mul(self, other)
def __sub__(self, other):
return add(self, neg(other))
def __neg__(self):
return neg(self)
def __truediv__(self, other):
return mul(self, inv(other))
def add(a, b):
value = a.value + b.value
local_gradients = ((a, 1), (b, 1))
return Variable(value, local_gradients)
def mul(a, b):
value = a.value * b.value
local_gradients = ((a, b.value), (b, a.value))
return Variable(value, local_gradients)
def neg(a):
value = -1 * a.value
local_gradients = ((a, -1),)
return Variable(value, local_gradients)
def inv(a):
value = 1. / a.value
local_gradients = ((a, -1 / a.value ** 2),)
return Variable(value, local_gradients)
def exp(a):
value = np.exp(a.value)
local_gradients = ((a, value),)
return Variable(value, local_gradients)
def get_gradients(variable):
gradients = defaultdict(lambda: 0) # 可以根据Variable变量地址索引对应的梯度
def compute_gradients(variable, path_value):
for child_variable, local_gradient in variable.local_gradients: # 两条路径循环2次
value_of_path_to_child = path_value * local_gradient # 从后往前,乘以每条边的梯度
gradients[child_variable] += value_of_path_to_child # 不同路径的梯度相加,算的是局部偏微分
compute_gradients(child_variable, value_of_path_to_child) # 递归整个计算图
compute_gradients(variable, path_value=1) # path_value=1,输出对自己的偏微分为1
return gradients
def sigmoid(z):
ONE = Variable(1)
return ONE / (ONE + exp(-z))
#自动微分,sigmoid函数的梯度消失现象
w = [Variable(np.random.randn()) for i in range(10)]
x = Variable(1)
Y = Variable(3)
y = sigmoid(w[1]*x)
for i in range(10):
y = sigmoid(w[i]*y)
C = (Y-y)*(Y-y)
gradients = get_gradients(C)
for i in range(10):
print('dC/dw%d=%f' % (i,gradients[w[i]]))
# 使用leaky ReLu函数避免梯度下降
from collections import defaultdict
import numpy as np
class Variable:
def __init__(self, value, local_gradients=[]):
self.value = value
self.local_gradients = local_gradients
def __add__(self, other):
return add(self, other)
def __mul__(self, other):
return mul(self, other)
def __sub__(self, other):
return add(self, neg(other))
def __neg__(self):
return neg(self)
def __truediv__(self, other):
return mul(self, inv(other))
def add(a, b):
value = a.value + b.value
local_gradients = ((a, 1), (b, 1))
return Variable(value, local_gradients)
def mul(a, b):
value = a.value * b.value
local_gradients = ((a, b.value), (b, a.value))
return Variable(value, local_gradients)
def neg(a):
value = -1 * a.value
local_gradients = ((a, -1),)
return Variable(value, local_gradients)
def inv(a):
value = 1. / a.value
local_gradients = ((a, -1 / a.value ** 2),)
return Variable(value, local_gradients)
def exp(a):
value = np.exp(a.value)
local_gradients = ((a, value),)
return Variable(value, local_gradients)
def get_gradients(variable):
gradients = defaultdict(lambda: 0) # 可以根据Variable变量地址索引对应的梯度
def compute_gradients(variable, path_value):
for child_variable, local_gradient in variable.local_gradients: # 两条路径循环2次
value_of_path_to_child = path_value * local_gradient # 从后往前,乘以每条边的梯度
gradients[child_variable] += value_of_path_to_child # 不同路径的梯度相加,算的是局部偏微分
compute_gradients(child_variable, value_of_path_to_child) # 递归整个计算图
compute_gradients(variable, path_value=1) # path_value=1,输出对自己的偏微分为1
return gradients
def LReLu(x):
if x.value > 0:
return x
else:
x.value=0.01*x.value
return x
k=10
print("leaky ReLu函数")
w = [Variable(np.random.randn()) for i in range(k)]
x = Variable(1)
Y = Variable(3)
y = LReLu(w[7]*LReLu(w[4]*LReLu(w[1]*x))+w[6]*ReLu(w[8]*LReLu(w[2]*x))+w[9]*ReLu(w[6]*LReLu(w[3]*x)))
for i in range(k):
#print("y=%f" % y.value)
y = LReLu(w[7]*LReLu(w[4]*LReLu(w[1]*y))+w[6]*ReLu(w[8]*LReLu(w[2]*y))+w[9]*ReLu(w[6]*LReLu(w[3]*y)))
C = (Y - y) * (Y - y)
gradients = get_gradients(C)
for i in range(k):
print('dC/dw%d=%f' % (i, gradients[w[i]]))
文章出处登录后可见!