引言
本着“凡我不能创造的,我就不能理解”的思想,本系列文章会基于纯Python以及NumPy从零创建自己的深度学习(Deep learning)框架,该框架类似PyTorch能实现自动求导。
要深入理解深度学习(Deep learning),从零开始创建的经验非常重要,从自己可以理解的角度出发,尽量不适用外部完备的框架前提下,实现我们想要的模型。本系列文章的宗旨就是通过这样的过程,让大家切实掌握深度学习(Deep learning)底层实现,而不是仅做一个调包侠。
本系列文章首发于微信公众号:JavaNLP

逻辑回归(Logistic Regression )(Regression)只能处理二分类(Binary classification)问题,但是很多时候我们遇到的是多分类(Multi-class classification)问题。此时就需要用到多元逻辑回归(Logistic Regression )(Regression)(multinomial logistic regression),也称为Softmax回归(Regression)。本文就来了解下Softmax回归(Regression)。
Softmax回归(Regression)
在softmax回归(Regression)中,我们希望为每个样本从个类别中标记(token)一个类别,假设(Hypothesis)只有一个类别是正确的。
我们使用下面的表示:每个输入(input)对应的输出
是一个长度为
的向量。如果类
是正确的类别,我们设
,然后设置
向量中所有其他元素为
。即
同时
,这种叫作独热向量(ont-hot vector)。分类器(Classifier)需要输出一个估计向量
。对于每个类
,
的值就是分类器(Classifier)对于概率
的估计。
Softmax回归(Regression)中使用Sigmoid函数的推广版——Softmax函数,来计算。
输入(input)一个向量,其中元素可以是任意值,映射它为一个概率分布(probability distribution)(Distribution),即每个元素的值被映射到
之间,同时所有映射值总和为
。
对于维度为的向量
,softmax定义为:
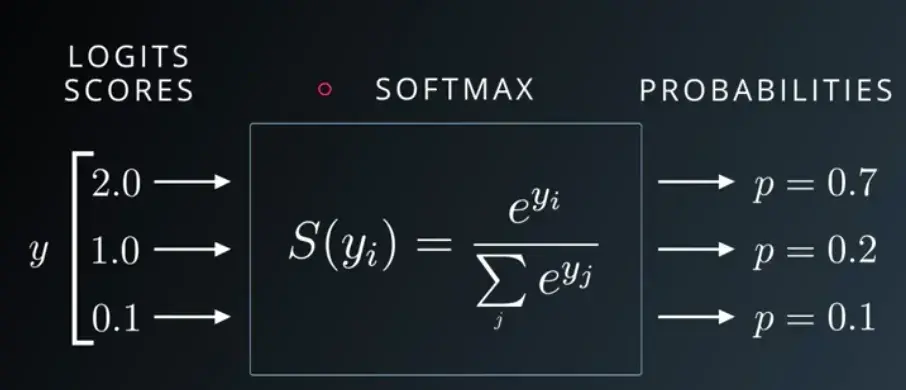
输入(input)向量经过softmax后得到向量:
该向量内所有元素总和为,分母
用于将所有的值标准化成概率。
应用Softmax
类似逻辑回归(Logistic Regression )(Regression),输入(input)是一个权重向量和一个输入(input)向量
之间的点积(dot product),加上偏差(Bias 偏置 )
。但不同的是,这里我们要为每个类提供独立的权重向量
和偏差(Bias 偏置 )
。这样,我们的每个输出类
的概率可以计算为:
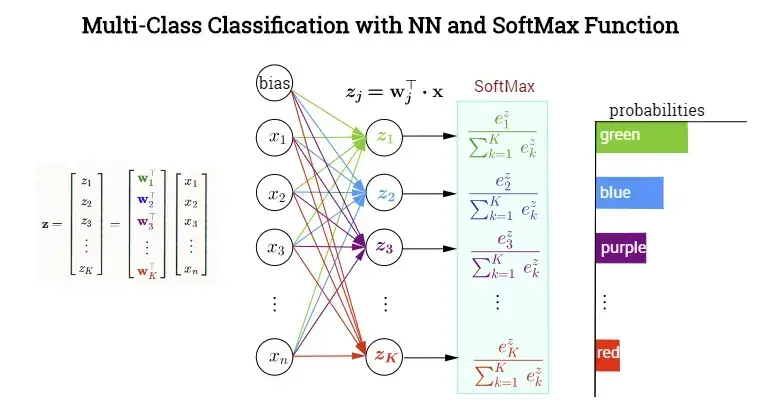
上图是公式的可视化,Softmax有
个权重和偏差(Bias 偏置 )(上图没有体现出来)。
公式形式看起来似乎会分别计算每个输出。相反,更常见的做法是通过向量化利用GPU来更有效地计算。我们将通过将
个权向量的集合表示为权矩阵(matrix)
和偏差(Bias 偏置 )向量
。
的第
行对应于
的权重向量。因此,
有形状
,
是输出类的数量,
是输入(input)特征的数量。偏差(Bias 偏置 )向量
对每个输出类都有一个值。如果我们用这种方式表示权值,我们可以通过一个优雅的方程来计算
,一次计算
个类的输出概率:
Softmax回归(Regression)的损失函数(Loss function)
Softmax回归(Regression)的损失函数(Loss function)是将逻辑回归(Logistic Regression )(Regression)的损失函数(Loss function)从类推广到
类。回顾一下,逻辑回归(Logistic Regression )(Regression)的交叉熵(Cross entropy)是:
Softmax回归(Regression)的损失函数(Loss function)推广了上式中的这两项(当时的
和
时的
)。对于Softmax回归(Regression),
和
会被表示成向量。真实标签
是一个带有
个元素的向量,每个元素都对应一个类,假设(Hypothesis)正确的类是
,则
,
的所有其他元素都是
。模型也将生成一个带有
个元素的估计向量
,其中每个元素
代表估计概率
。
对于单个样本的损失函数(Loss function),从逻辑回归(Logistic Regression )(Regression)推广,是
个输出的对数和,每个乘上对应的
,见下
。这正好变成了正确类别
的负对数概率:
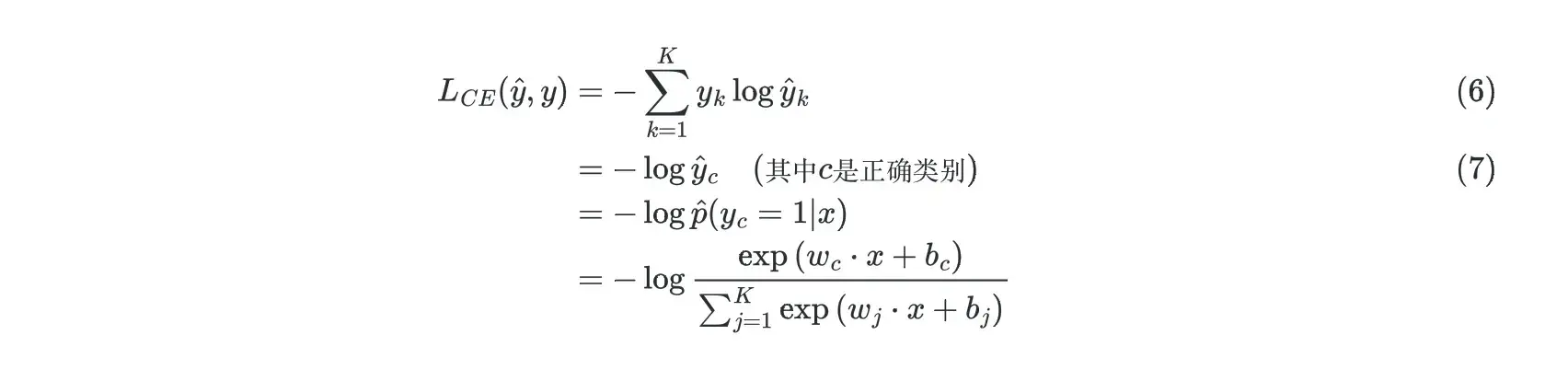
从到
是怎么转换的呢?因为只有一个类,假设(Hypothesis)记为
,是正确类别,向量
只有其对应的元素为
,比如
同时
。这意味着
中的求和项都是
,除了正确类
对应的那项。就变成了
。因此交叉熵(Cross entropy)损失简单的变成了正确类别的输出概率的对数,因此称
为负对数似然(Negative Log Likelihood)(Log likelihood)损失。
Softmax回归(Regression)的梯度(gradient)
当然,对于梯度(gradient)下降(Gradient Descent),我们不需要损失,我们需要它的梯度(gradient)。单个样本的梯度(gradient)与我们在前文中看到的逻辑回归(Logistic Regression )(Regression)的梯度(gradient)非常相似。让我们考虑一下梯度(gradient)的一部分,即单个权重的导数。对于每个类
,输入(input)
的第
个元素的权重是
,假设(Hypothesis)
共有
个特征。与
有关的损失的偏导数(partial derivative)是多少?因为
被占用了,因此我们用新的符号(symbol)
。
由于分母中包含
,因此我们推导如下:

因为只有项与
有关,其他的偏导数(partial derivative)都是
,所以上面进行了简化。
同理,第二项:
到
是因为
与
无关,因此可以提到求和符号(symbol)左边。而
,因此变成了
。
联立公式就得到了最后的公式。
事实证明,这个导数只是类的真实值(即1或0)和
类分类器(Classifier)输出的概率之间的差额。
Softmax回归(Regression)与逻辑回归(Logistic Regression )(Regression)的关系
逻辑回归(Logistic Regression )(Regression)处理二分类(Binary classification)问题,而Softmax回归(Regression)可以处理多分类(Multi-class classification)问题。那么它们之间有什么关系呢?
Softmax回归(Regression)具有参数冗余的特点,即参数中有些是没有用的,比如从参数向量(
)中减去某个向量
,为了方便描述,我们将偏置项
增广到
中,变成:
可以看到,从参数向量中减去
对预测结果没有任何影响,即在模型中存在多组最优解。
假设(Hypothesis)一个样本只属于一个类别,使用Softmax回归(Regression)来进行分类:
当类别数为2时,
利用参数冗余的特点,我们将参数减去
,
变成了
又令,得上式,整理后的式子与逻辑回归(Logistic Regression )(Regression)一致。
因此,Softmax回归(Regression)实际上是逻辑回归(Logistic Regression )(Regression)在多分类(Multi-class classification)下的一种推广。
版权声明:本文为博主愤怒的可乐原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/yjw123456/article/details/122546843