



为了提高模型准确率,我们习惯用复杂的模型(网络层次深、参数量大),甚至会选用多个模型集成的模型,这就导致我们需要大量的计算资源以及庞大的数据集去支撑这个“大”模型。但是,在部署服务时,就会发现这种“大”模型推理速度慢,耗费内存/显存高,这时候我们又会想念“小”模型的好。那么,有没有一种方法能够尽可能继承大模型的泛化能力,又像小模型一样轻量级呢?今天来介绍一种模型压缩的方法——蒸馏(Distillation)。
传统蒸馏
首次提出知识蒸馏压缩模型思想的是2006年Bucilua,但是论文里没有实际工作阐述:https://www.cs.cornell.edu/~caruana/compression.kdd06.pdf。
所以,一般认为最早是Hinton在2015年提出并应用在了分类任务上:Distilling the Knowledge in a Neural Network。我们来阐述一下传统的知识蒸馏过程:简单地说,就是先用数据集训练一个效果非常好的Teacher模型,然后选择一个较为轻量级的Student模型,同时接受数据集和来自Teacher模型给予的Knowledge Transfer的“知识”来训练这个轻量级Student模型。那么整个蒸馏的过程中,我们主要关心的就是Teacher模型的选择、Student模型的选择、以及Student模型的训练过程(或者说是Knowledge Transfer过程)。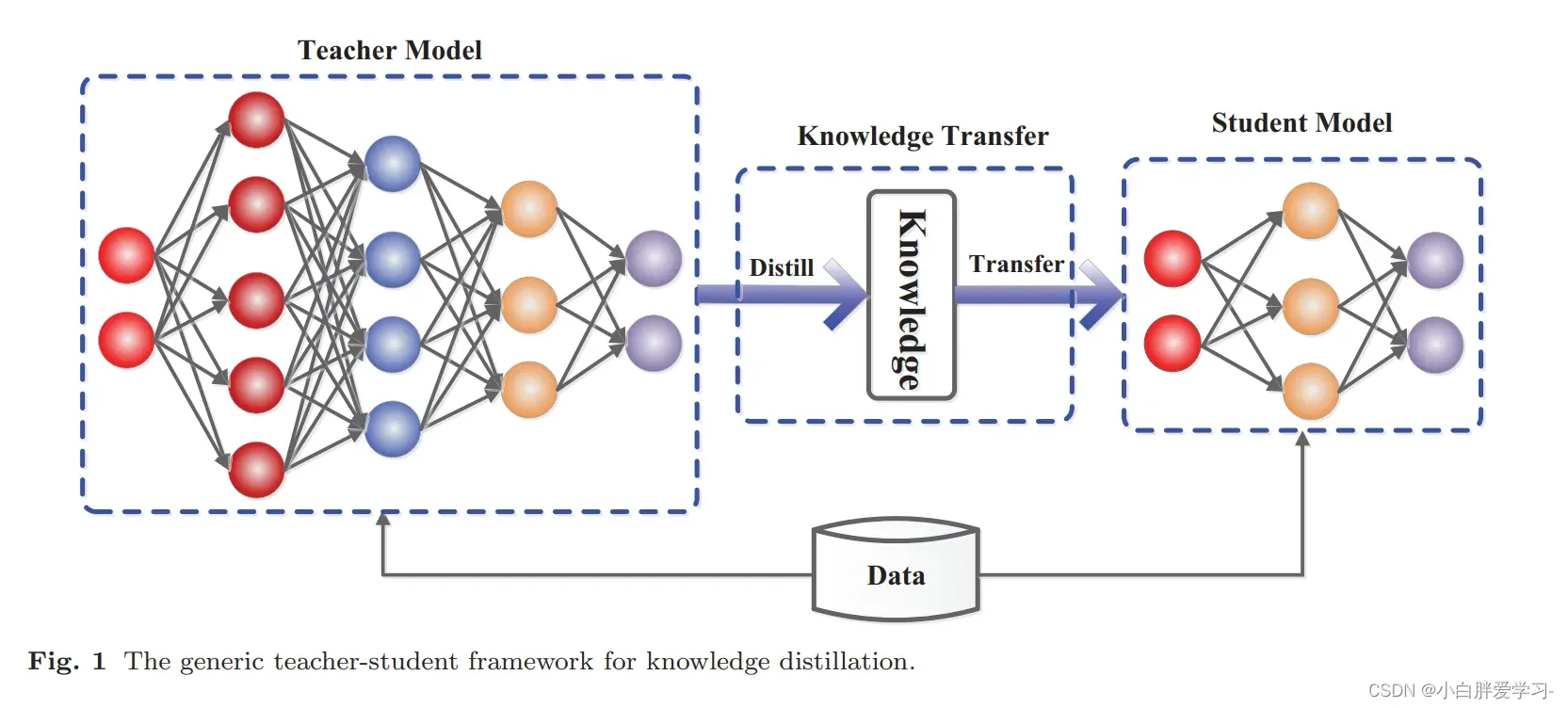
Teacher模型:首先,我们需要一个原始的“大”模型——Teacher模型,这个模型可以不限制其结构、参数量、是否集成,要求这个模型尽可能精度高,并且对于给定的输入X可以给出输出的监督信息Y,这个Y在分类任务中就是softmax的结果,也就是输出对应类别的概率值。这里我们称Y为soft targets,而训练数据的标注好的标签,我们称为hard targets。
Student模型:这个部分的模型选择会有很多限制,要求其参数量小,结构相对简单,当然最好是单模型。并且需要注意的是,训练过程中student模型学习的不再是单纯的hard targets(标注好的真实标签),而是融入teacher模型输出的soft targets(监督信息Y),这里也被称为knowledge transfer。蒸馏的损失函数distillation loss分为两部分:一部分计算teacher和student之间输出预测值的差别(student预测的y 和 soft targets),另一部分计算student原本的loss(student预测的y 和 hard targets),这两部分做凸组合作为整个模型训练的损失函数来进行梯度更新,最终获得一个同时兼顾精度和性能的student模型。
这里单独说一下teacher和student之间输出预测值的loss,这个部分被做的文章也是比较多,这实际上是两个分布的距离问题,可以选择传统的Cross,也可以选择MSE、KL散度等,在博主的实验里发现对不同的student模型,适合不同的loss函数,这里只能自己多做尝试。
为什么蒸馏有效?
那么,肯定有人想问,为什么蒸馏会有效?直接从数据集学习不是更为直观没有中间商赚差价吗?本质上,蒸馏的训练方式主要是改变了模型只能单一地学习label的这个缺陷。原本模型从数据集的标注数据中学习,而蒸馏过程学习的知识融入了Teacher模型输出的监督信息Y,在分类任务上也就是softmax结果,其中包含了Teacher模型的泛化能力。
具体的举个例子,我们做新闻分类,类别分别为社会、财经、娱乐、生活。此时我们有一条社会类目的新闻,其hard target为[1, 0, 0, 0]。而经过teacher模型,输出其soft target为[0.88, 0.01, 0.01, 0.1],那么我们可以发现soft target中学习到:首先,这条新闻确实是社会类目;其次,这条新闻是生活类目的可能性要比财经和娱乐类目的高。那么模型通过同时学习hard target和soft target获得的知识要比只学习hard target的更多。换句话说,在分类的模型中,我们的蒸馏模型不仅能学习到本身这个分类任务,还可以额外获得类别间的相似性知识,那么理论上,蒸馏模型的泛化能力一定要比同样模型结构在该数据集上训练的模型强。
也就是说,蒸馏模型学习的不仅是数据集中的知识,还有Teacher模型的泛化能力。
蒸馏模型的分类
从不同的角度来看,蒸馏模型可以有不同的分类。这里有两个区别,来自两篇文章。
区别于训练
论文地址:Knowledge Distillation and Student-Teacher Learning for Visual Intelligence: A Review and New Outlooks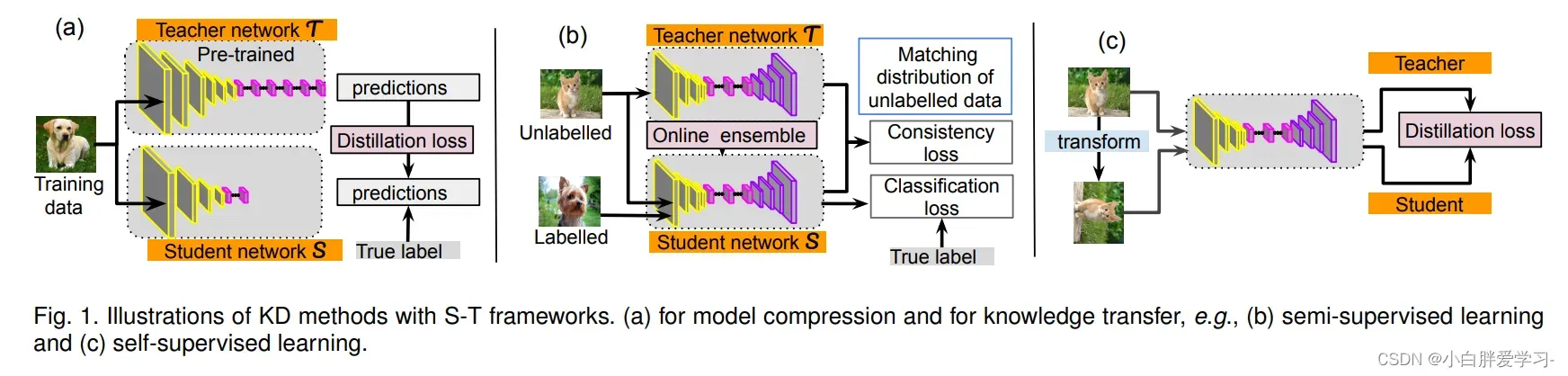

- 离线蒸馏方式,即为传统的知识蒸馏,如上图(a)。一般来讲,Teacher模型的参数在蒸馏训练过程中保持不变,选用的Teacher模型和Student模型准确性相对悬殊比较大,并且Student模型会在很大程度上依赖Teacher模型。
- 半监督训练方式,利用了Teacher模型的预测信息作为标签来对Sudent网络进行监督学习,如上图(b),不同于传统的离线蒸馏方式,在对Student模型训练之前,先输入部分未标记的数据,利用Teacher网络输出的标签作为监督信息,再输入到Student网络中来完成蒸馏,这样可以使用更少的标注数据,达到提升模型精度的目的。在online蒸馏中,Student模型和Teacher模型将同时更新,整个知识提炼框架是可以从端到端训练的。给出一篇online蒸馏的文章: Online Knowledge Distillation with Diverse Peers
- 自监督蒸馏,相比于传统的离线蒸馏方式,是不需要提前训练一个Teacher模型的,而是Student网络本身的训练是一个蒸馏过程,如上图(c)。具体的实现方式有很多种,比如训练Student模型时,在整个训练过程的最后几个epoch的时候,利用前面训练的Student模型作为监督模型,在剩下的几个epoch中对模型进行蒸馏。这样做的好处,是不需要提前训练一个Teacher模型,可以做到边训练边蒸馏,节省整个蒸馏过程的训练时间。同样给出一篇自监督的蒸馏: Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
区分知识源位置
论文地址:Knowledge Distillation: A Survey(这篇文章总结的特别全,可以看一下下图,这里只拎出来Sec2说说)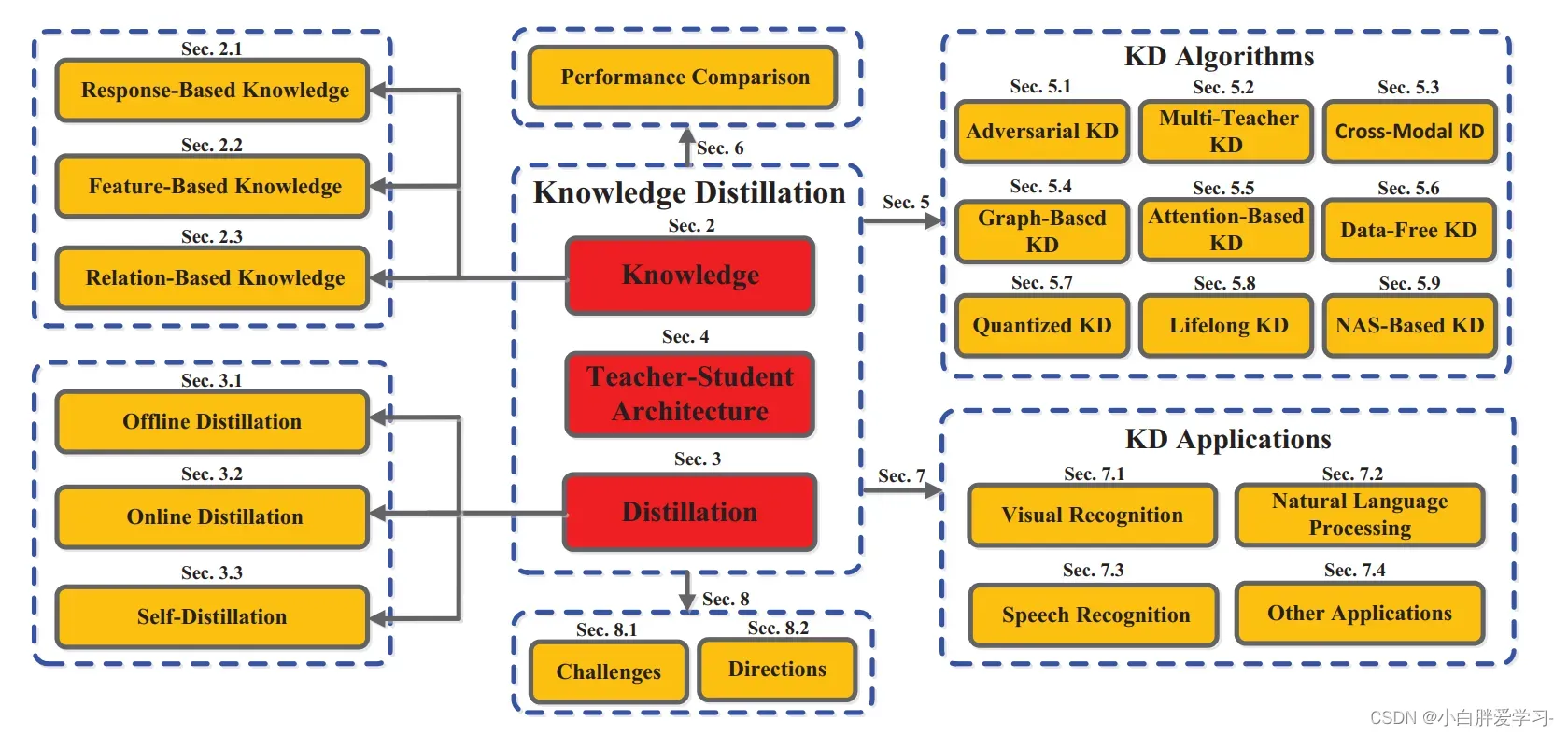

从知识来源位置维度考虑,蒸馏模型可以分为Response-Based、Feature-Based和Relation-Based的知识蒸馏。从下图可以直观感受到,Response-Based的知识是从teacher模型的output layer中学习到的,而Feature-Based是从hidden layer中学习到的知识,Relation-Based则是学习input-hidden-output之间的关系。
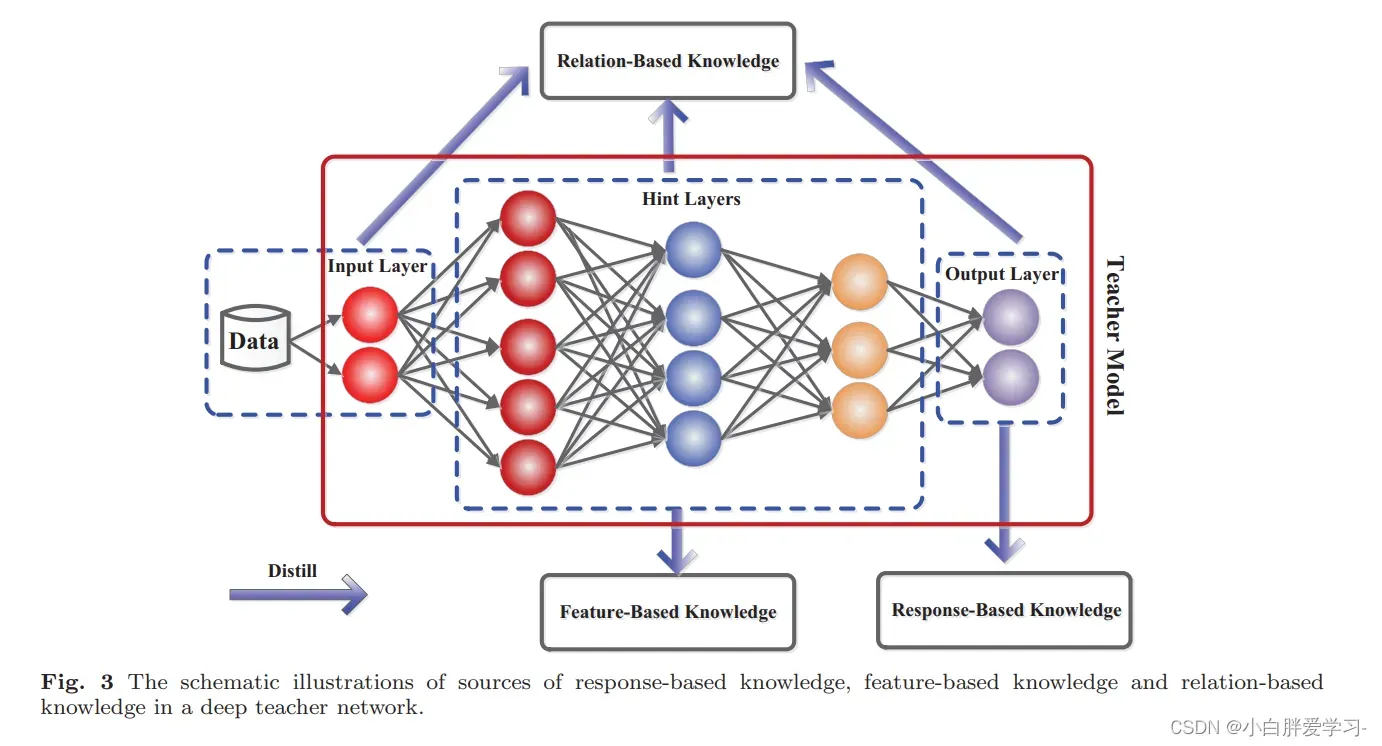

Response-Based
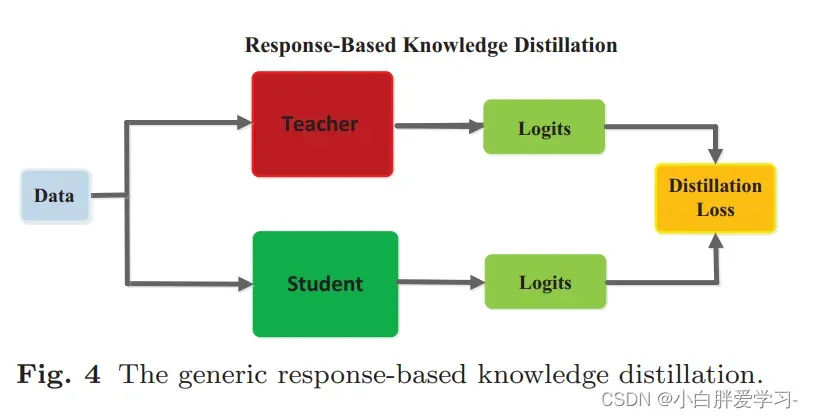
基于response的知识蒸馏实际上也就是传统是知识蒸馏模型,response通常指的是teacher模型最后一个输出层,比如分类任务中的softmax层的输出,其主要思想是直接模拟teacher的最终决策。基于response的知识蒸馏对于模型压缩来说是最简单有效的,并且被广泛应用于不同的任务和场合中。Hinton提出的蒸馏模型也是采用了这样的方法。Student学模型学习teacher模型的输出分布,相当于同时给予了类别之间的相似性信息,同时额外提供了监督信息,学习起来较为容易,实现起来也较为容易。但是蒸馏的效率依赖于softmax loss计算和类别的数量。从实验效果上看,如果student模型较小,或者和teacher模型差别过大的时候,蒸馏的效果不尽如人意。

Feature-Based
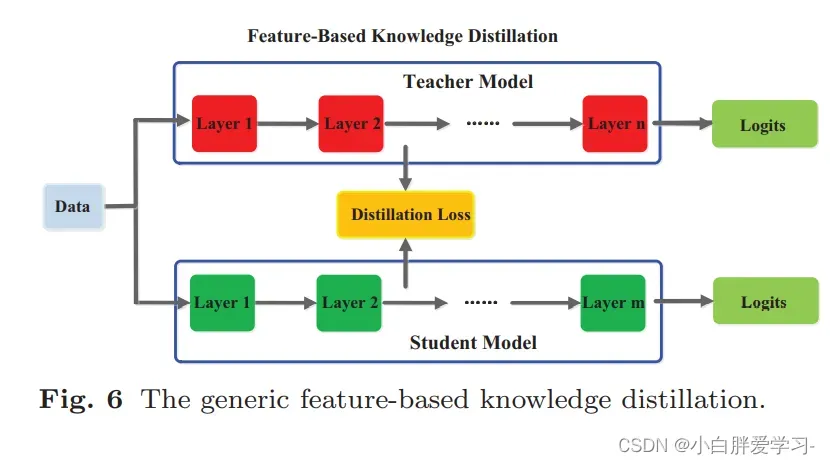
首次提出Feature-Based的文章是:FITNETS: HINTS FOR THIN DEEP NETS, 实际上是对Hinton提出的蒸馏模型的一种拓展。从上图可以清晰的明白,Feature-Based是从一些中间隐层中学习知识,其允许student网络可以比teacher网络更深更窄,从teacher网络中间层提取特征结果,作为student网络中间层输出的hint,也就是说teacher网络的中间层去指导student网络训练。因为student网络相比于teacher网络较窄,所以student网络中间层连接一个Wr网络和teacher网络进行适配,这个用于适配的网络选择了卷积网络,节省计算量。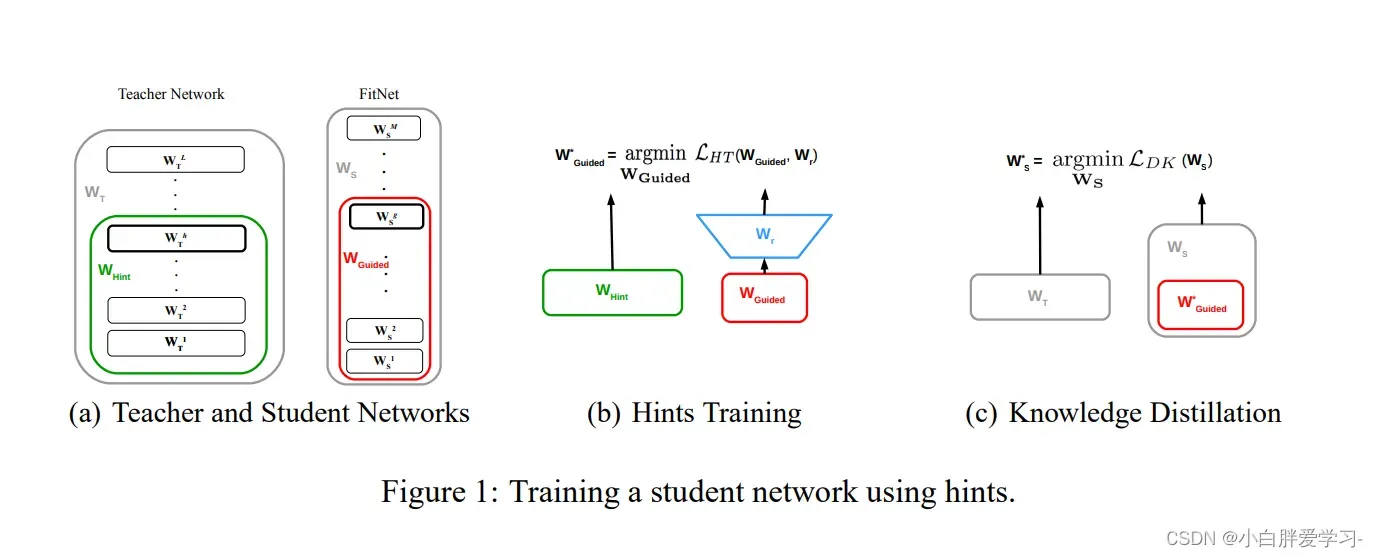


Relation-Based
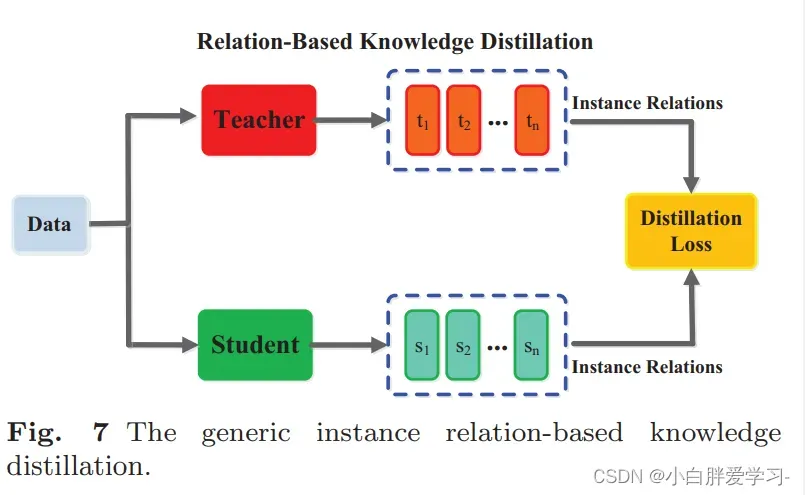
Relation-Based 不拟合Teacher模型中间层或者输出层的结果,而是拟合Teacher模型内层与层之间的关系,这个关系是用层与层之间的内积来定义的。参考论文:A Gift from Knowledge Distillation:Fast Optimization, Network Minimization and Transfer Learning。

蒸馏在NLP中的应用
在NLP的大部分任务中,我们可能习惯上追崇Bert大法,但是Bert本身参数量比较大,在一些特殊情况下,我们需要部署一个小而美的模型,这时候我们需要给Bert进行“瘦身”。一般认为比较有效的瘦身方法有上面介绍的蒸馏、量化(Quantization)、剪枝(Pruning)。这里我们介绍几个效果不错的Bert蒸馏模型。
DistillBERT
论文地址:https://arxiv.org/pdf/1910.01108.pdf
项目地址:暂未开放
这里选择了bert-base作为teacher网络,除此之外罗列一下DistillBERT的特别之处:
- Student模型结构变化:DistilBERT中Student模型的整体结构和Bert基本相同,不过Bert采用了12层的transformer encode,而DistilBERT采用的6层的transformer encode,这里作者注意到hidden size维度的变化对模型计算效率的影响小于层数变化的影响,因此DistilBERT主要改变的是Bert层数。其次Student模型移除了token-type embedding和pooler。
- Student模型初始化工作:DistilBERT没有进行自己的预训练,而是将Bert部分参数直接加载到DistilBERT的结构中,作为初始化。
- Student模型训练损失函数:这里是损失函数包含三个部分:1. 传统蒸馏的损失:teacher网络softmax层输出的概率分布和student网络softmax层输出的概率分布的交叉熵;2. 传统模型训练的损失:student网络softmax层输出和真实标签的交叉熵;3. student网络隐层输出和teacher网络隐层输出的余弦相似度值;
训练方法和Roberta类似,采用了大batch、动态mask、扔掉NSP任务等,关于Roberta可以回顾一下:bert的兄弟姐妹梳理——Roberta、DeBerta、Albert、Ambert、Wobert等
DistillBERT的思想还是比较简单的,根据文中给出的实验效果看,模型参数减小了40%(66M),推断速度提升了60%,但精度大概下降了3%左右。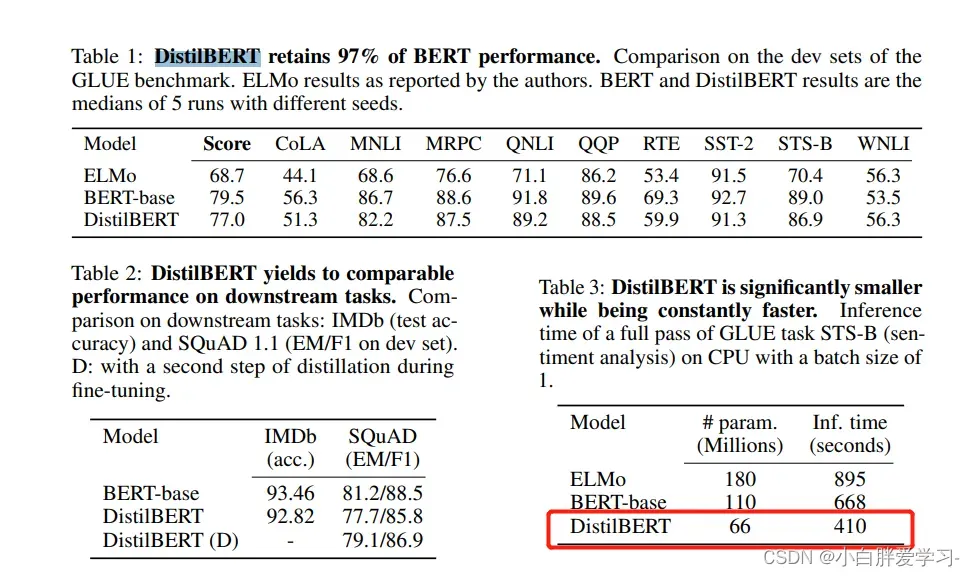

TinyBERT
论文地址:https://arxiv.org/pdf/1909.10351.pdf
项目地址:https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/TinyBERT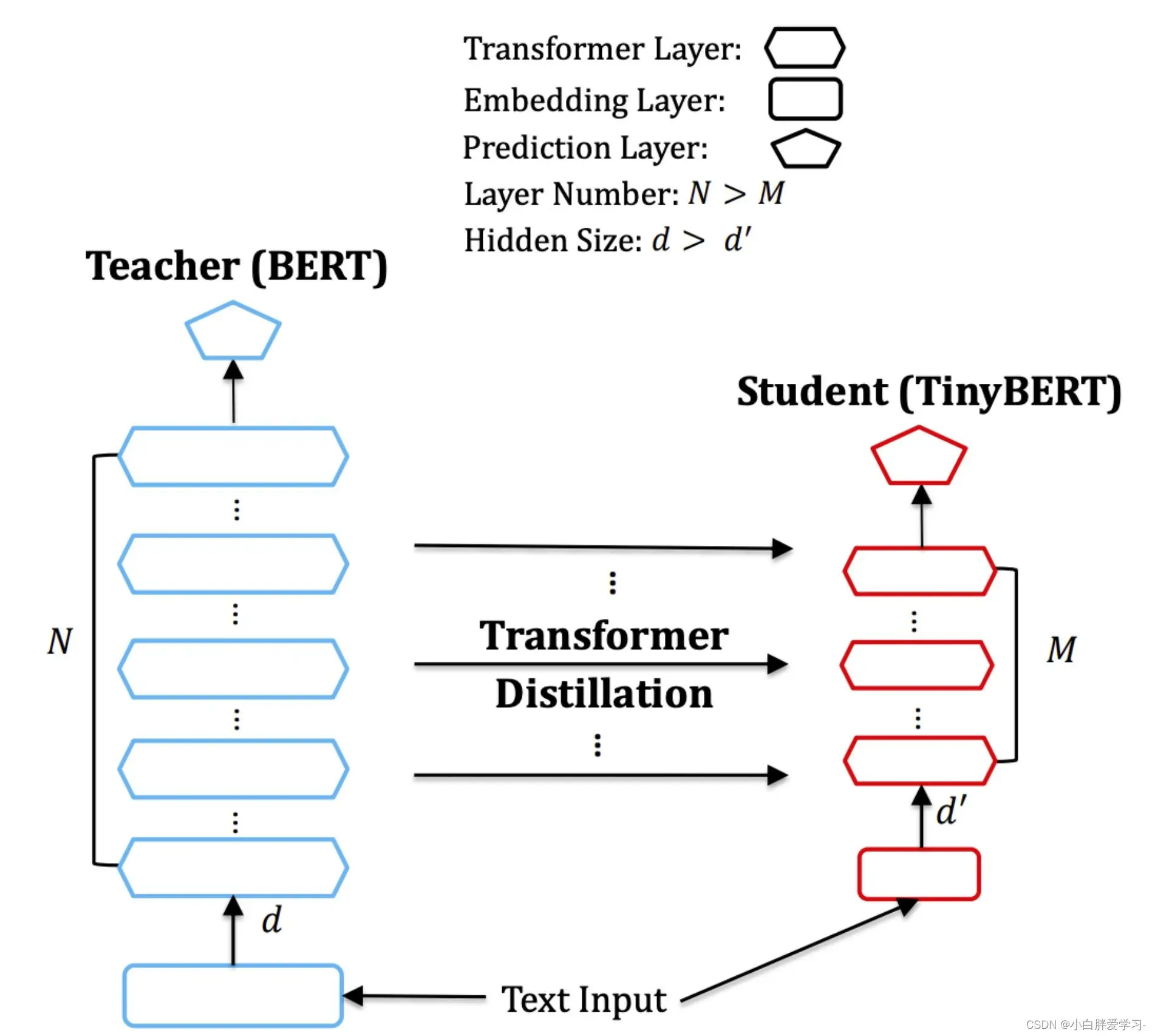
这篇也是从蒸馏角度出发,和DistillBERT的思路相差不大,都是缩减模型结构:减少层数和hidden size,差异可能更多体现在 loss 的设计上,此外,作者还提出了两段式学习框架,旨在提升特定任务的TinyBERT精度。

模型结构:TinyBERT层数相对bert-base从12层降低到4层;FFN层输出的大小从3072降低到1200,Head个数维持12不变,hiddent size从768降至312;最终参数量从110M降低到14.5M。
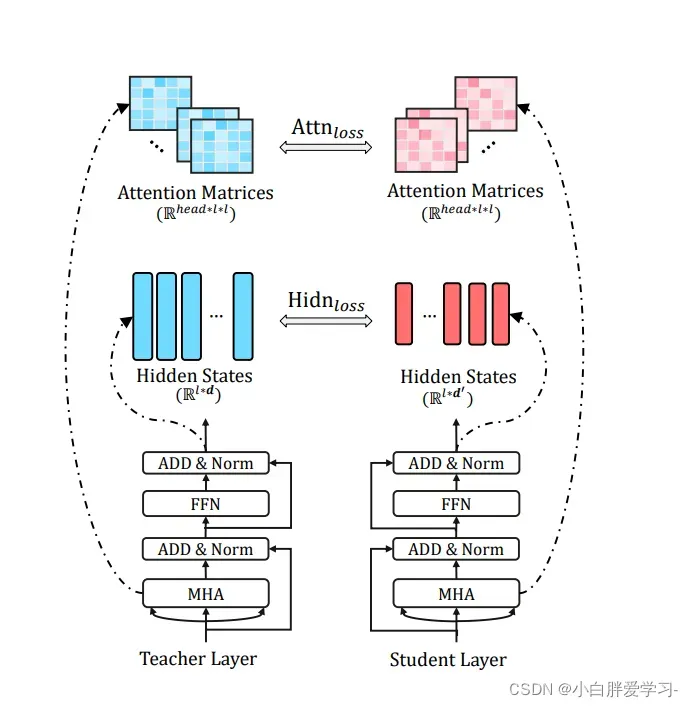

损失函数主要分为三个部分,但是和DistillBERT的设计差别还是挺大的:
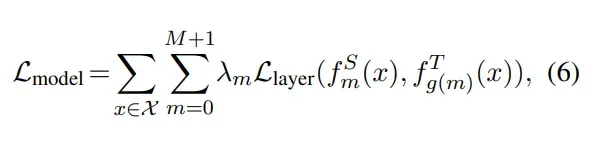

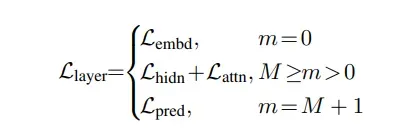

- Embedding-layer Distillation:student网络的embedding和teacher网络的embedding的MSE损失;
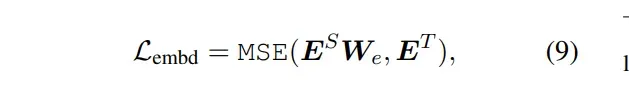
- Transformer-layer Distillation:这里分为两个部分:1. attention based distillation :student网络第 i 个attention头的attention score矩阵和teacher网络第 i 个attention头的 attention score矩阵的MSE损失的平均值;
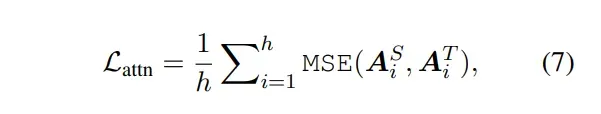


- hidden states based distillation:student transformer 和 teacher transformer 的隐层输出的MSE损失
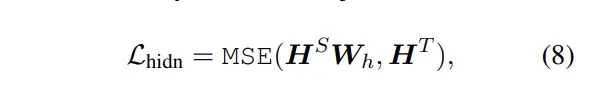

- Prediction-Layer Distillation: teacher 输出的概率分布和 student 输出的概率分布的 softmax 交叉熵
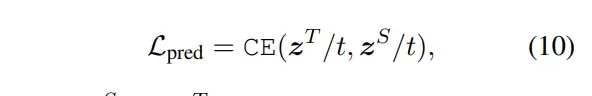

两段式学习框架:BERT 的应用通常包含:预训练和微调。BERT在预训练阶段学到的大量知识非常重要,并且迁移的时候也应该包含在内。因此,研究者提出了一个两段式学习框架,包含通用蒸馏和特定于任务的蒸馏,这样做的目的是:TinyBERT 可以获取 LargeBERT 的通用和针对特定任务的知识,两段式蒸馏可以尽可能地缩小 teacher 和 student 模型之间的差距。本质上就是在pre-training蒸馏一个通用的TinyBERT,然后再在通用的TinyBERT的基础上利用task-bert上再蒸馏出微调版的TinyBERT。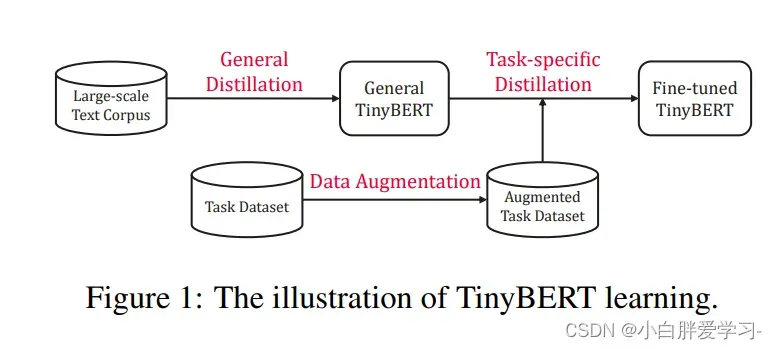

文章出处登录后可见!