一:数据挖掘过程
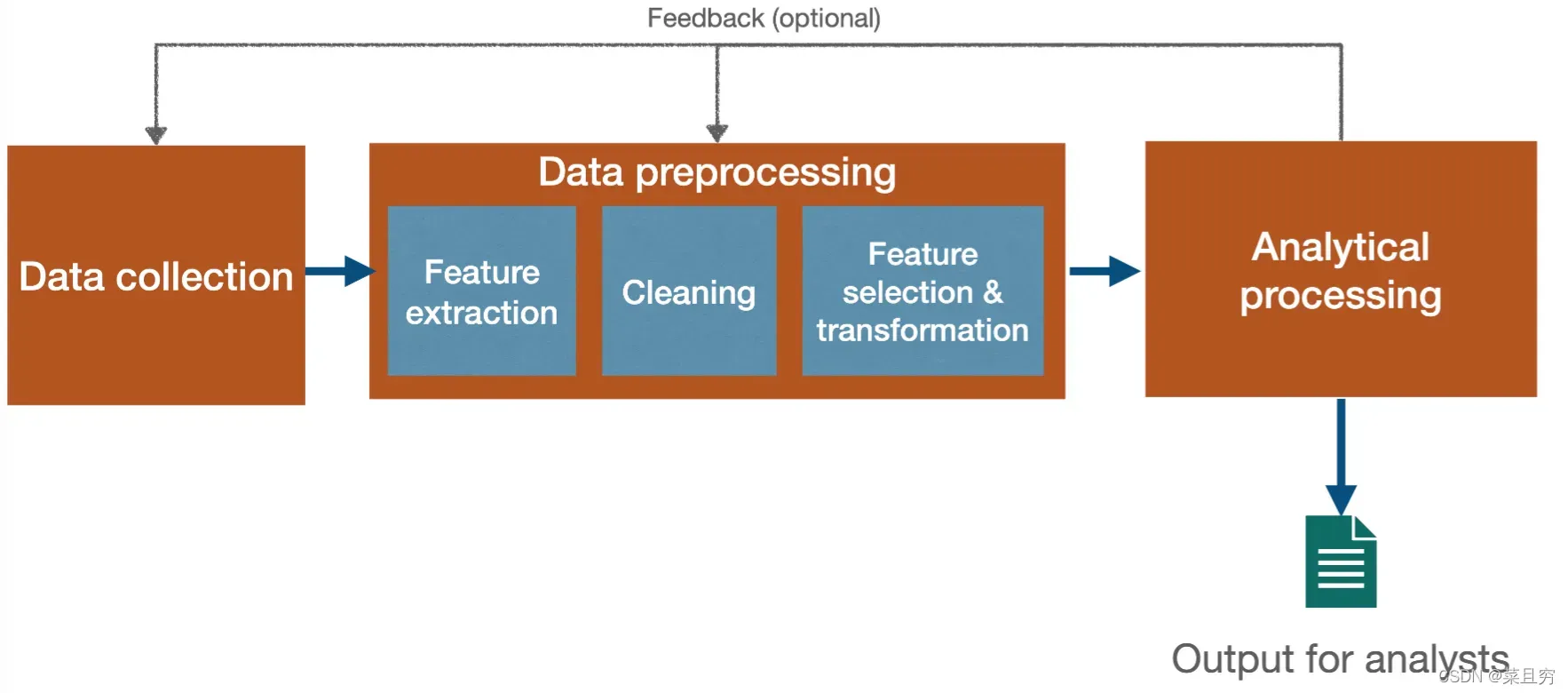
阶段1:数据收集
数据源:
- 传感器网络
- 用户调查
- 自动收集的文件
重要性:
非常重要,对整个数据挖掘过程产生重大影响
贮存:
数据仓库
阶段2:数据处理
特征提取
目的:将数据转换成对数据挖掘算法友好的格式
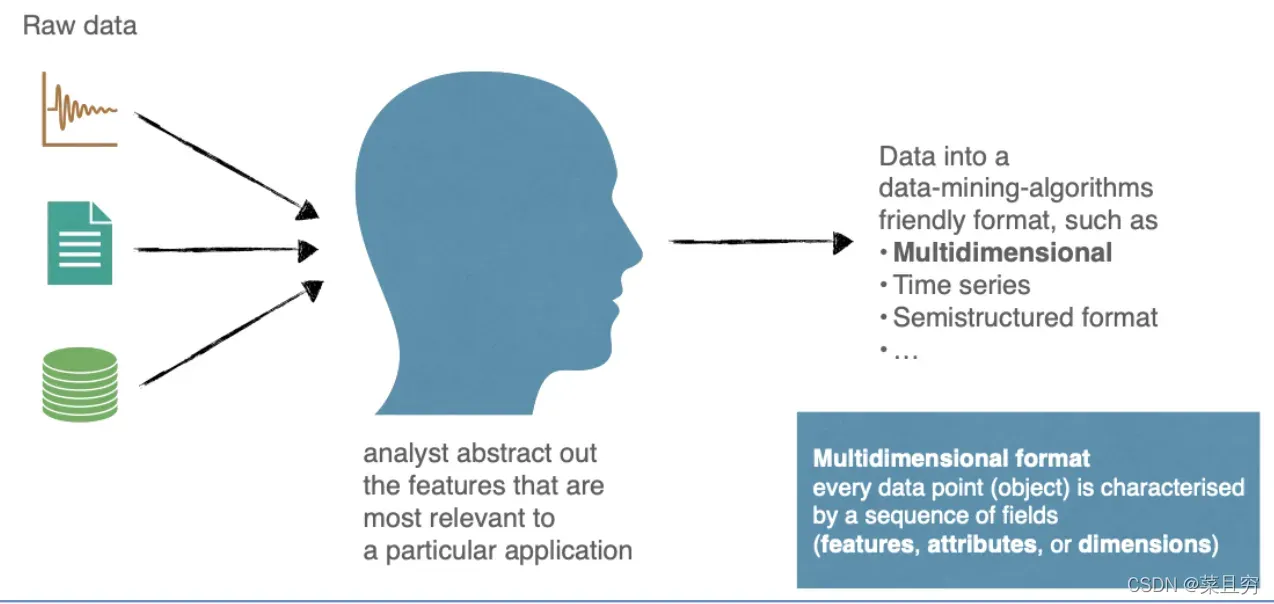
对象与特征(Objects and features)
数据级别的对象和特征的含义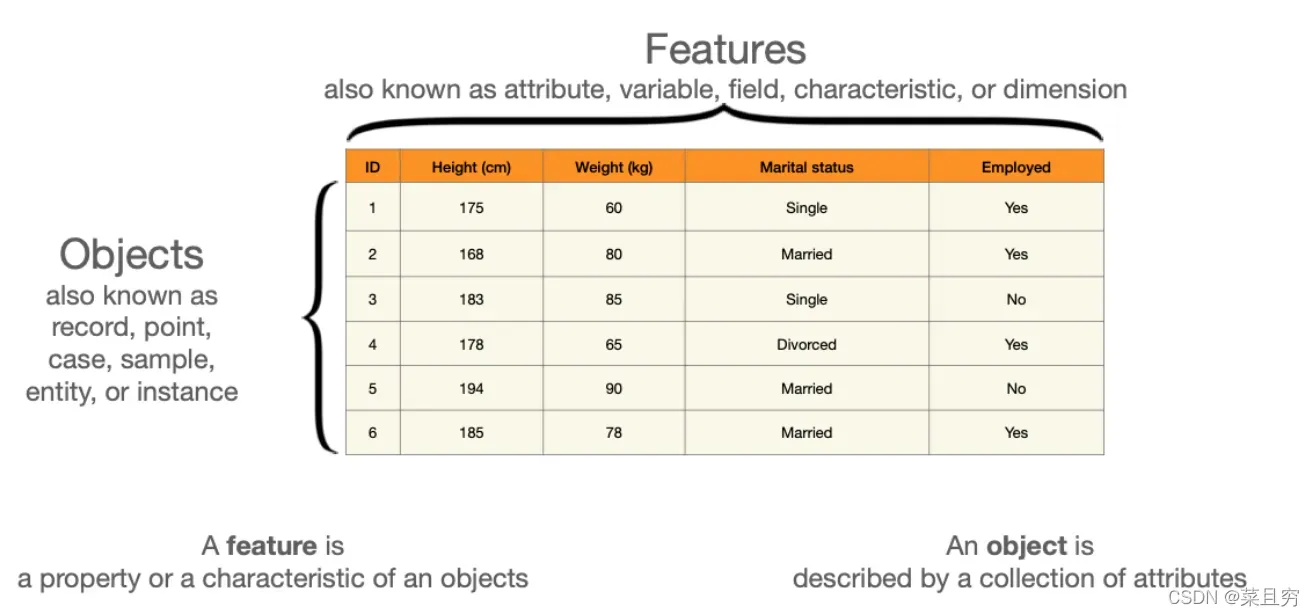
数据清洗
估计或纠正数据的缺失和错误部分。
可能的行动:
- 删除这条记录
- 估计缺失数据的价值
- 消除不一致
数据特征选择与转换
可能的行动:
- 删除不相关的特征
- 将现有特征转换为不同的尺寸或格式
例如:numerical age ->{young,middle,elderly}
阶段3:分析
主要任务:设计和应用用于预处理数据的算法方法
通常会把问题分解为以下4个模块:
- 关联模式挖掘
- 集群clustering
- 分类classification
- 离群点检测 outlier detection
二:数据类型
1:面向非依赖性的数据 (Nondependency-oriented data)
- 数值或定量
- 分类或无序离散值
- 二进制数据{0,1}。
- 文本数据
2:面向依赖性的数据(dependency-oriented data)
即:对象之间可能存在依赖关系
- 隐性(implicit):从传感器收集的连续的 测量数据
- 显性(explicit):网络连接:节点(对象)通过边(关系)连接
例如:Facebook social networks
三:数据展示
无论分类算法如何,不适当的数据都会导致分类性能问题
数据问题和挑战
- 对不同的数据特征使用不同的尺度(scales)
height:{100,230} 厘米
wight:{40,120}公斤 - 代表不同类型的数据
数字编码{是:0 否:-1} - 文本数据(除法规则)
- 所有单词(a list of words)
- 所有去重后单词(a set of words)
- 所有单词频率(By a vector of word frequency)
- 所有字母出现频率(by a vector of letter frequency)
- 特征修剪
许多
不相关的特征(即与预测完全无关的特征)
如何处理冗余特征? - 文本数据的不相关特征:一个词总是或几乎从不出现
- 数值数据的不相关特征:低方差特征
四:数据挖掘的主要问题
1. 模式发掘 :Association pattern mining
频繁模式挖掘(二进制数据集)
example: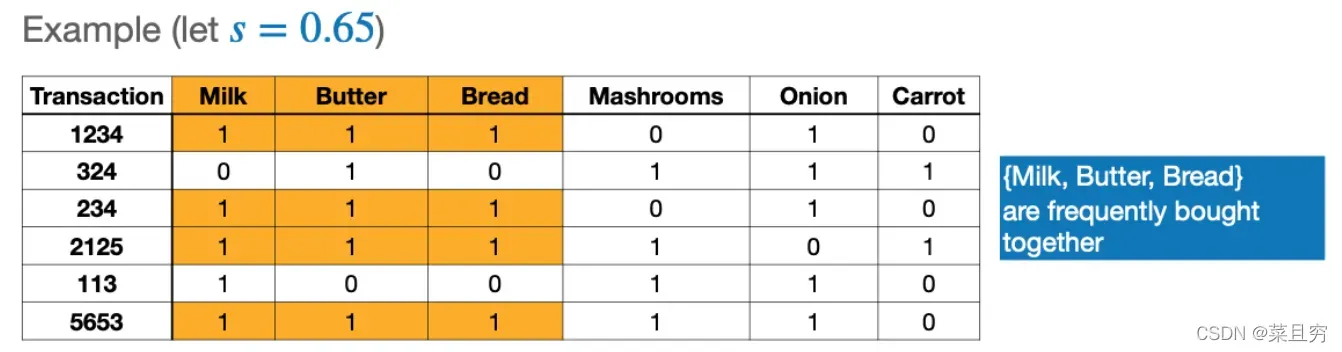
超市购物,人们总是与面包一起购买黄油和牛奶
2. 分类 classification
通过训练数据学习一个固定的特征,即类标签和数据中 剩余数据特征之间的关系。通过学习所产生的学习模型可以用来估计(预测),测试数据记录中的类标签(类标签值是不可知的)。 属于 监督学习(supervised learning )的一种。
监督学习:
解释一:
在标记的训练样本上进行学习,以便尽可能[对训练样本集之外的数据进行分类和预测]。
解释二:
通过对现有训练样本(即已知数据及其对应的输出)进行训练得到一个最优模型(这个模型属于一组函数,最优意味着它在一定的评价标准下是最好的),然后用这个模型将所有的输入映射到对应的输出,并对输出进行简单的判断,达到分类的目的,同时也具有对未知数据进行分类的能力。
如:KNN;SVM;训练神经网络;决策树
3. 聚类 clustering
给定一个数据集,将其对象划分为若干组(集群),使每个集群中的对象彼此相似。属于无监督学习(unsupervised version of classification)的一种:
无监督学习:
对未标记的样本进行训练学习,进而发现这些样本中的潜在结构知识。 (KMeans,DL),即事先没有任何训练样本,而需要直接对数据进行建模
exmpales:
客户产品推送,根据不同客户的情况,比如兴趣爱好,身体健康等特征,向客户推送不同的产品。如果是客户1喜欢运动,则优先推送户外运动,健身相关产品等
4. 离群检测 outlier detection
给定一个数据集,识别异常值,即与其他对象显着不同的对象。
examples:
- 信用卡诈骗
- 检测传感器事件
- 医疗诊断
- 地球科学
文章出处登录后可见!
已经登录?立即刷新