概念和组成
概念:当我们谈论机器学习中的神经网络时,我们指的是神经网络,或者机器学习和神经网络这两个学科的交集。我们在这里是为了建立一个类似于神经模型的分类器,但实际上我们又回到了分类的问题上。在训练过程中,神经网络的复杂程度也反映了其分类的准确性和可靠性。
神经元模型
使用生物学知识!你如何看待最简单的被激发的神经?其过程大致分为:感觉刺激–>钾离子流出,钠离子流入–>达到激发所需的电位差立即被激发–>传导…
那么我们的神经元在机器学习中是什么样子的呢?肯定不同于我们自己的神经元,至少不会流血。
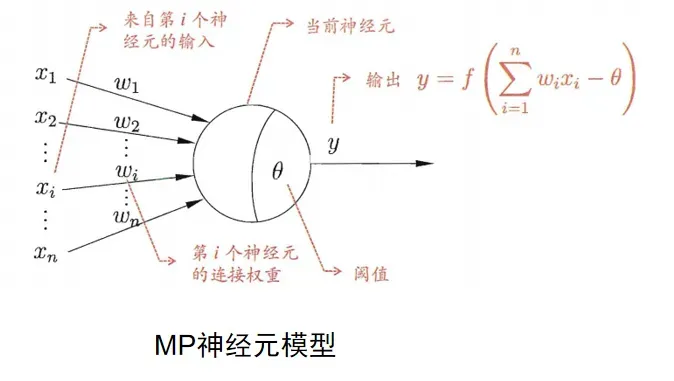 这个神经元 x 端是其他神经元传递过来的信号,w 表示权重。什么意思?就是你传过来的东西我要消化处理一下才传递给下一层级。比如吃饭时,把食物送进空腔,没牙的老奶奶也知道用牙床磨两下食物后再送进胃里。
这个神经元 x 端是其他神经元传递过来的信号,w 表示权重。什么意思?就是你传过来的东西我要消化处理一下才传递给下一层级。比如吃饭时,把食物送进空腔,没牙的老奶奶也知道用牙床磨两下食物后再送进胃里。
我们求学也要有自己的理解不是吗?这个 w 就是两个神经元“通道的带权值”。当前神经元里面有一个阈值,将这个神经元的总输入值和阈值比较,然后通过“激活函数”产生神经元的输出。
激活函数
理想中的激活函数便是阶跃函数(左图),输出值只有0,1。0代表抑制,1代表兴奋,但是它不连续,不光滑,因此我们实际上用的是sigmoid函数(右图)作为激活函数。它把可能在较大范围内变化的输入值挤压到 (0 1) 输出值范围内,因此有 时也称为 “挤压函数”。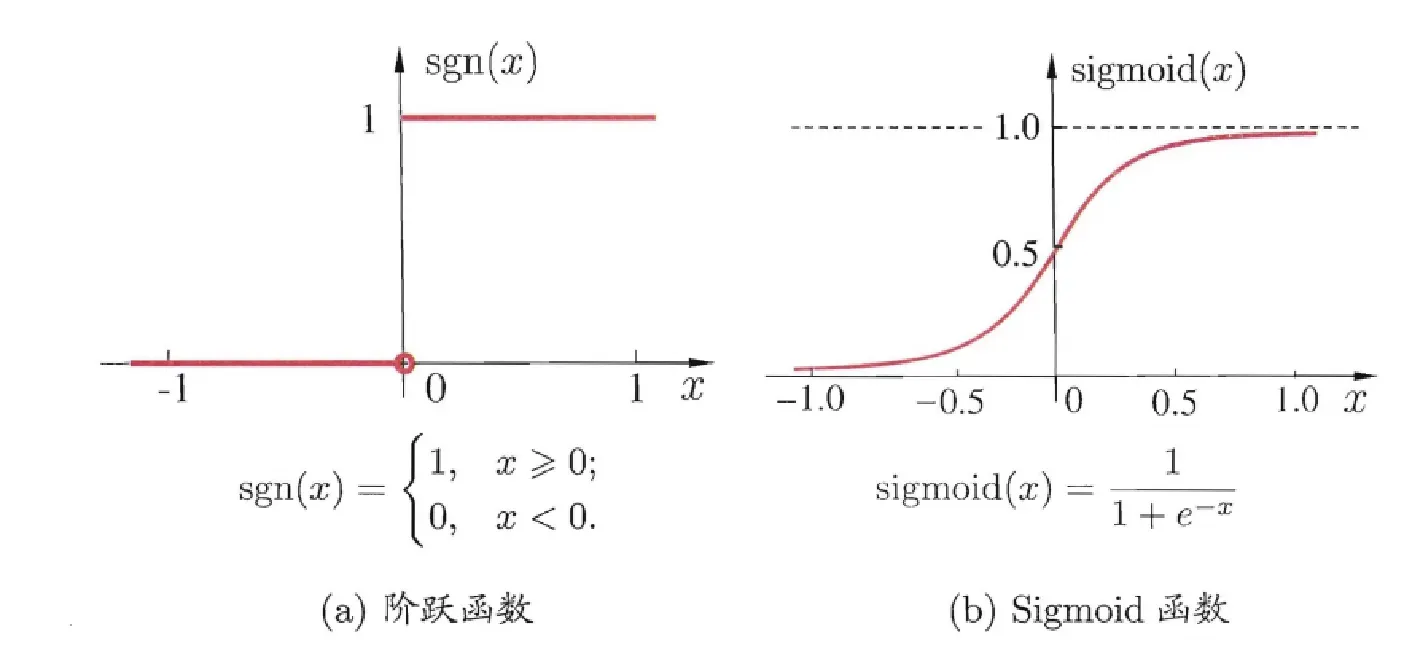 事实上,从计算机科学的角度看,我们可以先不考虑神经网络是否真的模拟了生物神经网络,只需将一个神经网络视为包含了许多参数的数学模型,这个模型是若干个函数相互(嵌套)带入而得.有效的神经网络学习算法大多以数学证明为支撑的。知道小时候为啥需要学数学乐吧,你只要学深一点除了文科领域哪儿都逃不过数学。
事实上,从计算机科学的角度看,我们可以先不考虑神经网络是否真的模拟了生物神经网络,只需将一个神经网络视为包含了许多参数的数学模型,这个模型是若干个函数相互(嵌套)带入而得.有效的神经网络学习算法大多以数学证明为支撑的。知道小时候为啥需要学数学乐吧,你只要学深一点除了文科领域哪儿都逃不过数学。
感知器和神经网络
感知机由两层神经元组成,输入层接收外界输入信号后传递给输出层,输出层是M-P神经元,亦称”阔值逻辑单元”.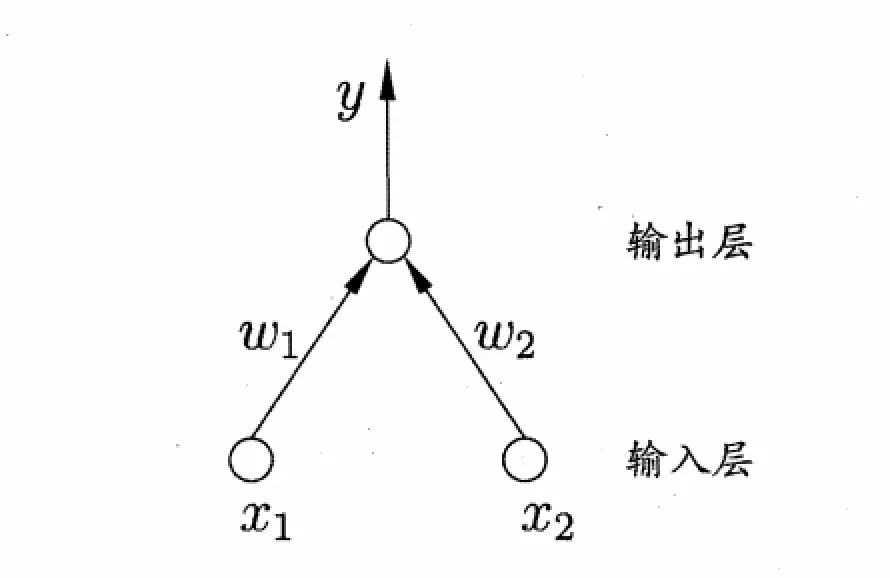 但是太简单了,就像下意识反射一样,不需要动脑筋。所以我们必须增加它的层数来实现更精确和合理的功能。在此之前,我们还是要从这个简单的模型开始,从高楼平地开始,好好看看,好好学习。
但是太简单了,就像下意识反射一样,不需要动脑筋。所以我们必须增加它的层数来实现更精确和合理的功能。在此之前,我们还是要从这个简单的模型开始,从高楼平地开始,好好看看,好好学习。
更一般的,在给定的训练集中,权重Wi(i=01,2…,n)和θ都是通过学习得到。域值θ可以看做固定输入的亚结点所对应的连接权重Wn+1。**这样权重和域值的学习可以统一为权重的学习。**感知机学习的规则,对于训练集(x,y),若对感知机的输出为y`,则感知机的权重将这样调整:
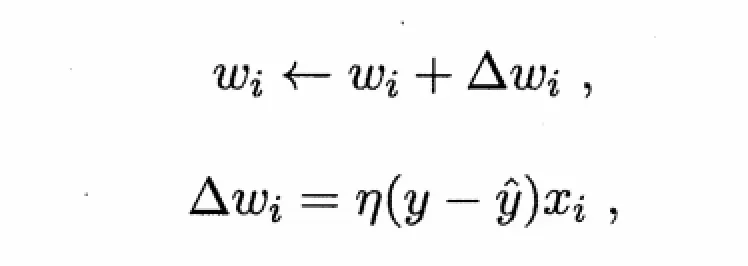 其中η∈(0,1),称为学习效率,从第一个式子可以看出,当y`=y时,预测全部正确△Wi = 0,不调整,不相等就会根据二式调整。
其中η∈(0,1),称为学习效率,从第一个式子可以看出,当y`=y时,预测全部正确△Wi = 0,不调整,不相等就会根据二式调整。
需要注意的是感知机只有输出层神经元进行激活函数处理,即只拥有一层功能神经元,其学习能力非常有限。与或非问题都是线性可分的,若两个模式线性可分则存在一个线性超平面把他们分开如图。则感知机学习过程一定会收敛求得权向量Wi.否则感知机学习过程将发生动荡不稳定,就不能解决d图的非线性可分问题。
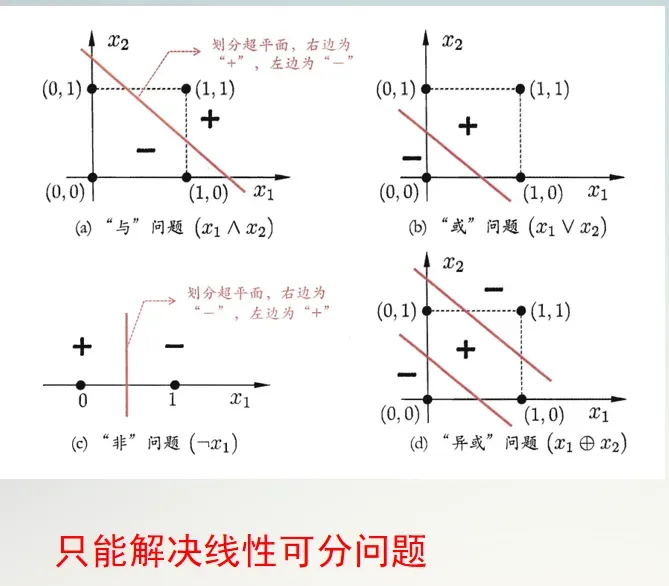 要解决非线性可分问题,需要多层功能神经元。如下a图这个两层的感知机,输入层和输出层之间的一层,叫做隐层或隐含层。隐含层和输出层都具有激活函数的功能。
要解决非线性可分问题,需要多层功能神经元。如下a图这个两层的感知机,输入层和输出层之间的一层,叫做隐层或隐含层。隐含层和输出层都具有激活函数的功能。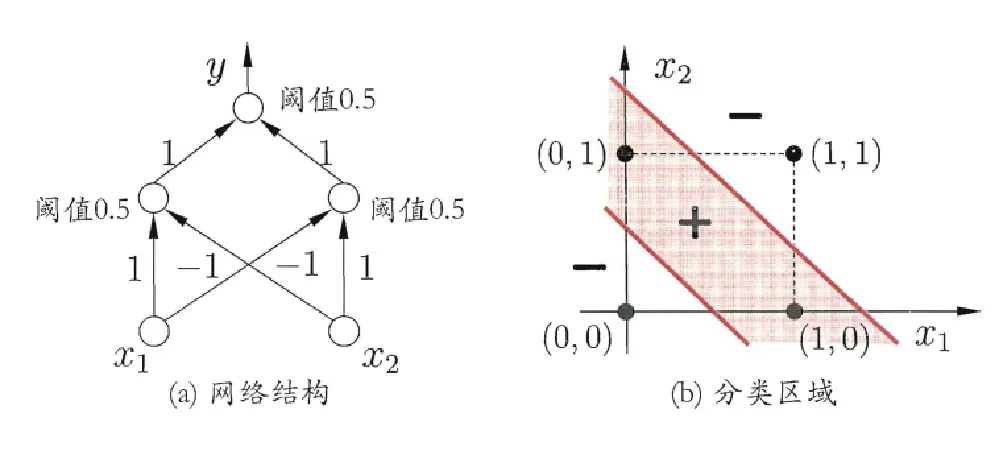 更一般的,常见的神经网络有如下两图所示的层次结构,每一层神经元都与下一层神经元完全互连。神经元之间既没有兄弟连接,也没有跨级连接。这样的神经网络被称为“多层前馈神经网络”。
更一般的,常见的神经网络有如下两图所示的层次结构,每一层神经元都与下一层神经元完全互连。神经元之间既没有兄弟连接,也没有跨级连接。这样的神经网络被称为“多层前馈神经网络”。
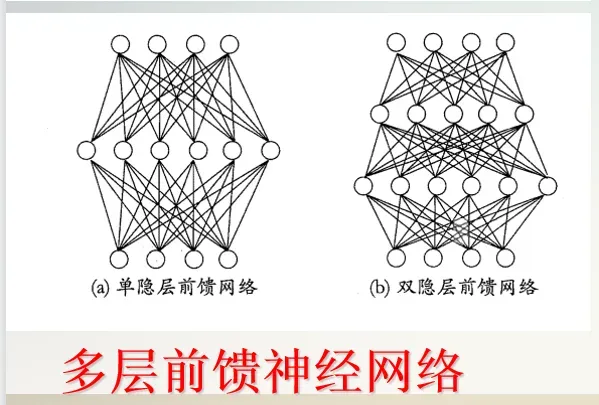 其中传入层神经元接收外界输入,隐层和输出层神经元对信号进行加工,最终结果有输出层神经元输出。强调输入层神经元只是接收输入,隐层和输出层包含功能神经元。图a叫做“两层网络”也叫作“单隐层网络”。在机器学习过程中,通过训练集来调整神经元之间的“连接权”以及每个功能神经元的域值。也就是说:神经元学的东西蕴含在连接权和域值里面。
其中传入层神经元接收外界输入,隐层和输出层神经元对信号进行加工,最终结果有输出层神经元输出。强调输入层神经元只是接收输入,隐层和输出层包含功能神经元。图a叫做“两层网络”也叫作“单隐层网络”。在机器学习过程中,通过训练集来调整神经元之间的“连接权”以及每个功能神经元的域值。也就是说:神经元学的东西蕴含在连接权和域值里面。
误差逆传播算法(标准BP)
介绍
多层网络的学习能力比单层感知机强得多,想要训练多层网络,简单的感知机学习规则显然不够。需要更强大的算法,误差逆传播算法(Error BackPropagation ,简称 BP)就是最杰出的算法代表。
功能
- 大多数现实中任务中使用的神经网络,都使用BP训练算法
- BP算法不仅可用于多层前馈神经网络,还可用于其他类型的神经网络。如:训练递归神经网络,一般我们指的BP网络都是训练的多层前馈网络。
公式推导
 给定训练集D={(
给定训练集D={(,
),(
,
)…(
,
)}
∈
,
∈
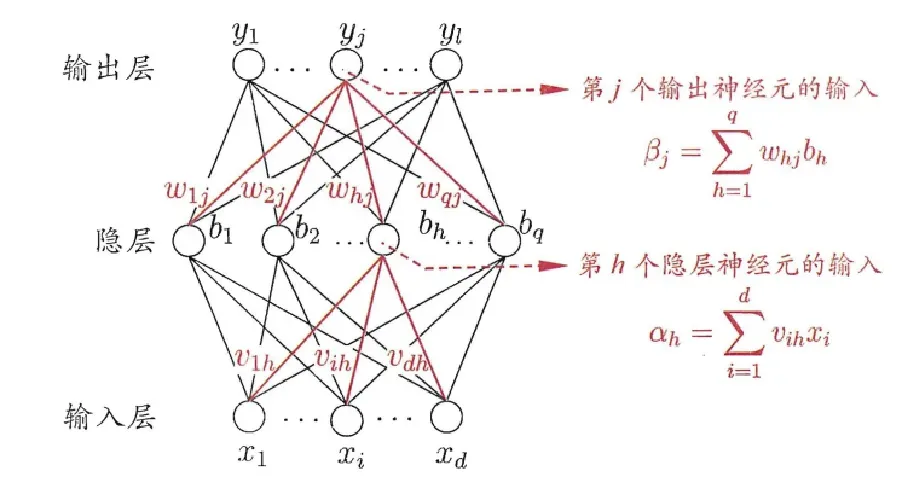
,输入事例由d个属性描述,输出l个实维向量。我们来看图:d个输入神经元,q个隐层神经元,l个输出神经元构成的多层前馈网络结构。第j个输出层神经元的域值用
表示,隐层第h个神经元用γh表示。输入层第i个神经元和隐层第h个神经元之间的连接权记
,隐层第h个神经元和输出层第j个神经元之间的连接权
,记第h个神经元接收的输入为
=
输出层第j个神经元接收的输入为
,其中bh为第h个隐层神经元的输出。
假设隐层和输出层的神经元都使用sigmoid函数,对训练例,假定神经网络的输出为
然后是:
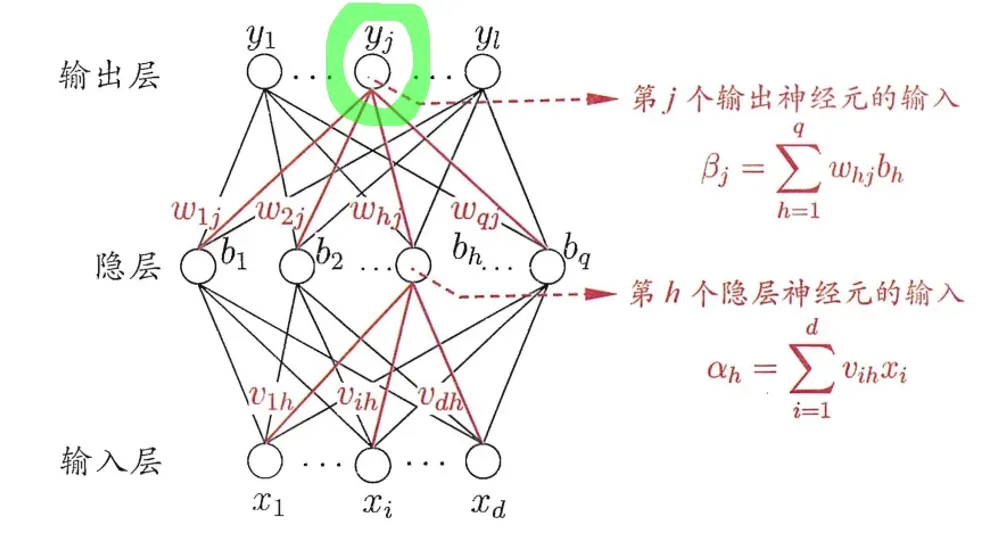 根据算法名字我们知道从结果逆向更新权重值,我们用这个绿色的结点。注意强调:
根据算法名字我们知道从结果逆向更新权重值,我们用这个绿色的结点。注意强调:是用sigmoid函数处理而来,
分别表示
的输入和域值。输入是所有隐层都参与了,累计求和而来。
输出和实际
之间存在误差,我们需要用它来更新权重和阈值。这里我们使用均方误差:
这里的是输出层所有结点的误差处理,1/2是方便后面的求导。
我们更新估计器:
现在我们来推导的链接权。BP算法基于梯度下降策略以目标的负梯度方向来调整,由输出层的误差E_k和给定的学习率
:
注意先影响到第j个输出层神经元的输入值βj,再影响到输出
最后影响到
,那么就类似于我们的符合函数,进行链式求导。
我们有βj的定义:
是: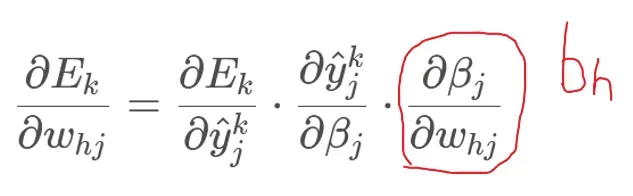 sigmoid函数有一个非常好的导数性质:
sigmoid函数有一个非常好的导数性质:
由公式 1 和 2 我们设一个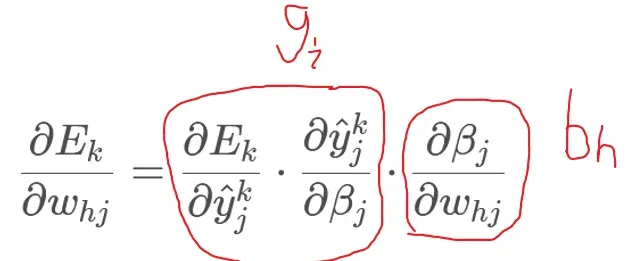 带入 5 公式:
带入 5 公式:
类似的可用:
我们求下一层的权重变化 ΔVih,如法炮制一遍:
链式推导找关系,把->
->
加到上面的关系中:
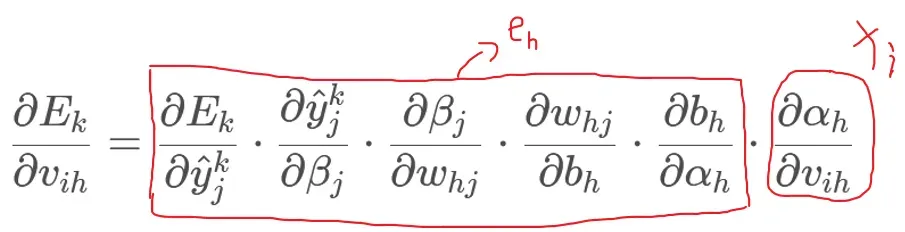
同时我们介绍:
因此对隐藏层的更新:
学习率η∈(0,1)控制着算法每一轮的迭代中更新步长,η太大容易振荡,太小收敛太慢了(就是这个过程)。我们要做到精细可以是每一层的η都不一样,比如此处我们不妨设输出层η1,隐层η2。
工作过程

累计BP算法
我们需要注意BP算法的目标是要最小化训练集D上的累计误差:
我们上面说的是标准BP算法,每一次仅对一个训练样例更新连接权和阈值,其更新规则是根据单个的Ek而言。如果类似的推导基于累积误差最小化的更新规则,就得到了累积误差逆传播算法。这两个算法都很常用,标准BP算法往往需要进行更多次的迭代,而累积BP算法读取整个训练集D一遍后才对参数进行更新,其更新频率低很多。但是在很多任务中,累计误差Ek下降到一定程度后,进一步下降会非常缓慢,这是标准BP往往会更快获得较好的解。数据多更新次数越多标准BP较好
新问题拟合
仍未解决的问题:隐藏层需要多少个神经元?我们无法给出准确的数据样本,只能通过反复试验确定隐藏层神经元的数量。
拟合问题
正是由于神经网络强大的表示能力,BP神经网络经常曹禺拟合:其训练误差逐渐降低,但是测试误差可能持续升高。
解决方案
1.早停:将数据分成训练集和验证集,训练集用来计算梯度、更新连接权和阈值,验证集用来估计误差。如果训练集误差降低,验证集的误差反而升高,立刻终止训练,同时返回最小误差的连接权和阈值。
2.正则化:在误差目标中增加一个用于描述网络复杂的部分,例如连接权和阈值的平方和.
其中λ∈(0,1)用于验证经验误差与网络复杂度这两项进行折中,常通过交叉验证法来估计。增加连接权与阈值平方和这一项后,训练过程将会偏向比较好的链接权和阈值,使网络输出更加平滑,从而对拟合有所缓解。
全局和局部最小值
知识理解
我们神经网络的训练过程可以看做一个参数的寻优过程,即在参数空间中,寻找一组最优的链接权w,阈值参数θ使得误差E最小。
在很多情况下,我们知道参数在两个位置是最优的:局部最小值和全局最小值。直观上,局部最小值是参数空间中的一个点,其相邻点的误差值不小于该点的函数值;全局最小解是参数空间中期望点的误差值不小于该点的误差函数值。
显然,参数空间梯度为零的点,其误差函数是局部最小值。想想这张图,可能有多个极小值,极小值就隐藏在其中,我们必须要找到它。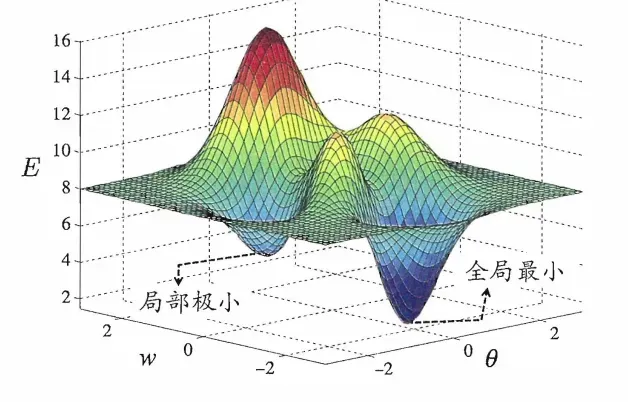
基于梯度的搜索是最广泛使用的参数优化方法。每次迭代,我们计算误差函数在当前点的梯度,然后根据梯度确定搜索方向。这里,我们的负梯度方向是函数下降最快的方向,所以我们沿着这个方向寻找最优解。当梯度为零时,达到局部最小值,可以停止搜索。但是,在有多个极值点的情况下,我们只能找到一个极值点并停止。这就像说我要去寻找西瓜一样。当你在路边看到芝麻时,你会停止寻找它。显然,情况并非如此。
跳出局部最小值
我们一般采用以下策略:
- 用多组不同参数初始化神经网络,按照标准锥法训练后,取误差最小的解作为最终参数。这相当于从多个不同的初始点开始搜索,这样就有可能陷入不同的局部最小值,选择最接近全局最小值的参数组作为结果。
- 使用“模拟退火”技术,每一步都有助于以一定的概率接受比当前解决方案更差的结果。每次迭代中次优解的选择应随着时间的推移逐渐减少,从而保证算法的稳定性。
- 使用随机梯度下降,与精确计算梯度的标准梯度下降不同,随机梯度下降在算法中添加了一个随机因素。那么即使落入局部最小值,但梯度不为零,继续更新,这样就有机会跳出局部最小值继续搜索。
这些解决方案是启发式的,缺乏理论保证。也就是说,你可以以一定的概率逼近或得到全局最小值,但也有你得不到的风险。
BP算法举例
多说无益,一起来看看最直观的数据操作流程,放松心情,马上开始。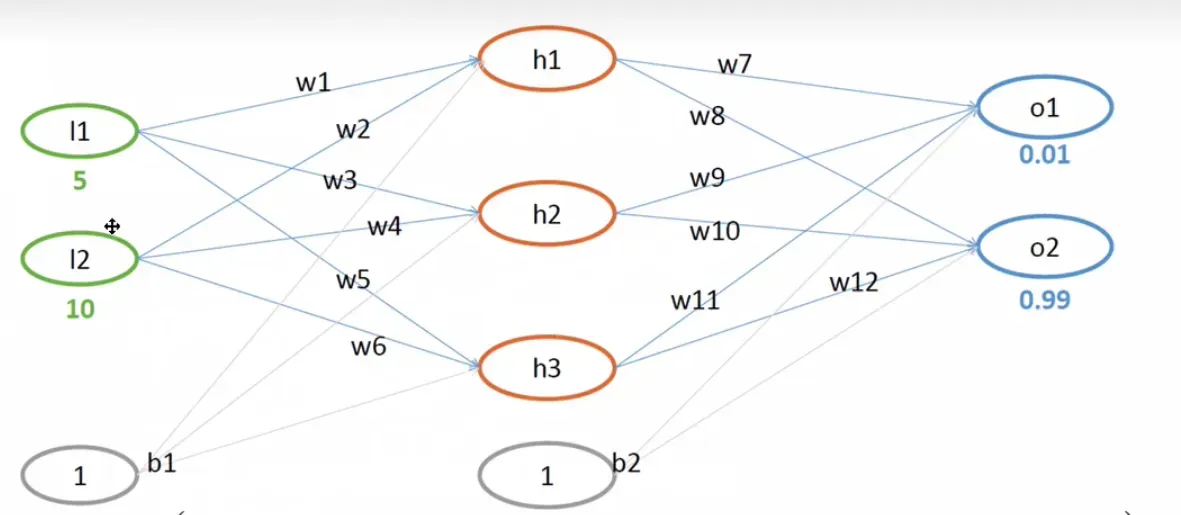 这里我们输出层 2 个神经元,隐层 3 个神经元,输出层 2 个神经元。
这里我们输出层 2 个神经元,隐层 3 个神经元,输出层 2 个神经元。
初始重量值:
| 连接权 | w1 | w2 | w3 | w4 | w5 | w6 | w7 | w8 | w9 | w10 | w11 | w12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 权值 | 0.1 | 0.15 | 0.2 | 0.25 | 0.3 | 0.35 | 0.4 | 0.45 | 0.5 | 0.55 | 0.6 | 0.65 |
偏执项b1=0.35 b2=0.65
我们先进行前向传播。 (我手写的,你也可以试试,你可以再复制一遍)

**接下来,计算输出层的输入输出值。 **做同样的事情。
我们得到了第一轮的均方误差E,现在我们以更新 w7 权重为例来更新权值。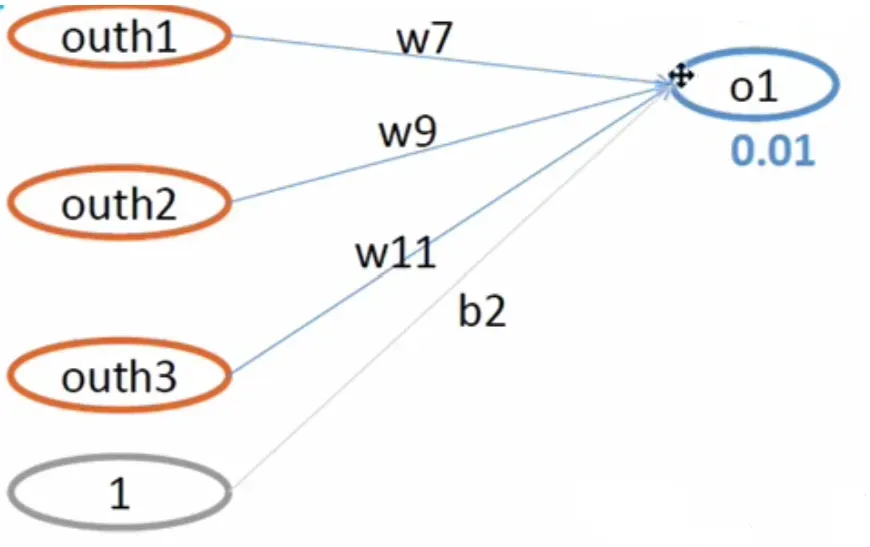

我们遵循以下公式:
请我们已经求出了,加入我们初始化η=0.5
那么根据 w7 的更新公式:
同样,我们可以发现:
结合初始值这张表:w7~w12
| 连接权 | w1 | w2 | w3 | w4 | w5 | w6 | w7 | w8 | w9 | w10 | w11 | w12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 权值 | 0.1 | 0.15 | 0.2 | 0.25 | 0.3 | 0.35 | 0.4 | 0.45 | 0.5 | 0.55 | 0.6 | 0.65 |
| 我们发现 w 7 w_{7} w7的值0.4更新为 w 7 + w_{7}^+ w7+ = 0.360968 它变小了, w 9 + w_{9}^+ w9+, w 11 + w_{11}^+ w11+也变小了.另外 w 8 + w_{8}^+ w8+ , w 10 + w_{10}^+ w10+ , w 12 + w_{12}^+ w12+变大了。 |
接下来我们更新,看关系图,找到推导的关系链
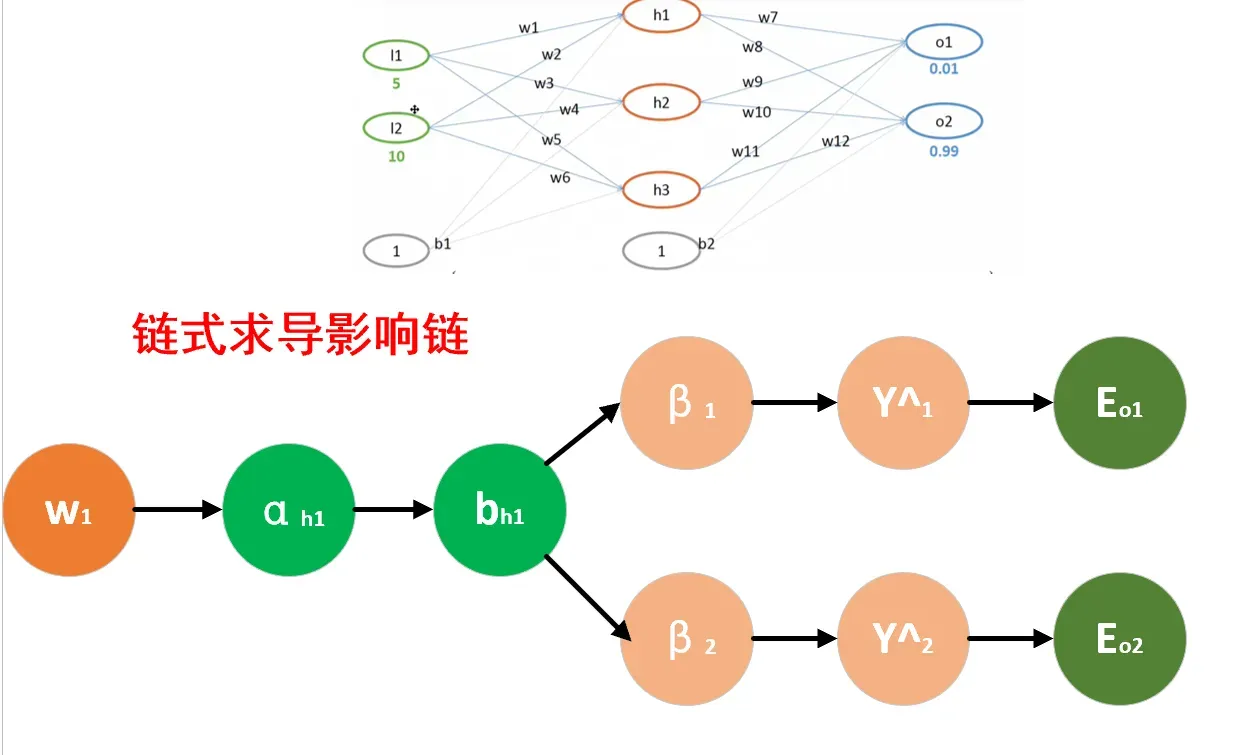 用笔推一下,过程大致是这样的:
用笔推一下,过程大致是这样的:
特别提示:此处已更新
类似的:
计算出=-0.453383,然后计算出
.进而:
同样更新其他连接权重: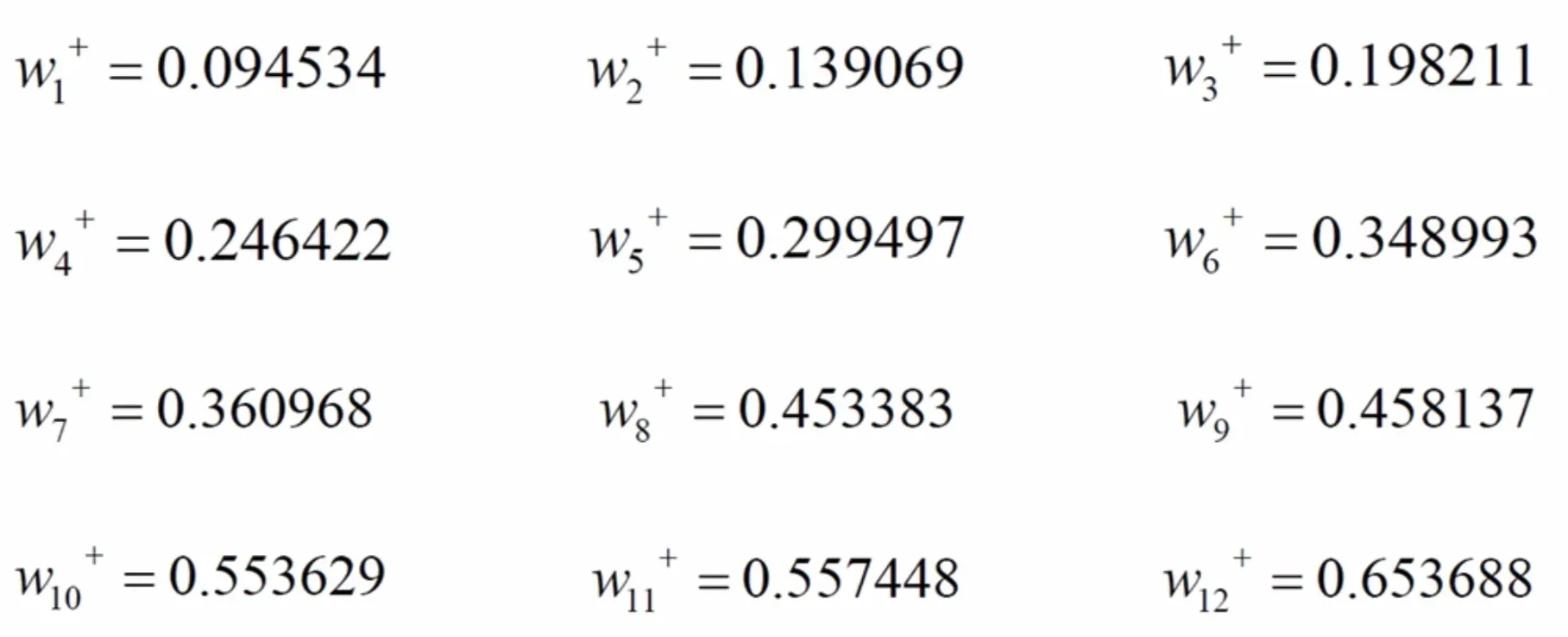 前面更新的权重越多,计算复杂度越高,消耗越大。更新越多,越接近真实值。
前面更新的权重越多,计算复杂度越高,消耗越大。更新越多,越接近真实值。
代码
这里我使用我老师的代码和详细的解释。我老师的密码
文章出处登录后可见!