


周志华先生《机器学习》一书学习笔记
记录学习过程
本博客记录Chapter12
1 基础知识
计算学习理论(computational learning theory):关于通过“计算”来进行“学习”的理论,即关于机器学习的理论基础,其目的是分析学习任务的困难本质,为学习算法体统理论保证,并根据结果指导算法设计。
对于二分类问题,给定样本集

令
由于D是
我们将研究经验误差和泛化误差之间的逼近程度;若
我们将使用几个常见的不等式:
- Jensen不等式:对任意凸函数,有
- Hoeffding不等式:若
- McDiarmid不等式:若
那么对于任何
2 PAC学习
概率近似正确理论(Probably Approximately Correct,PAC):
- 先介绍两个概念:
- 如果
- 对于训练集,我们希望学习算法学习到的模型所对应的假设
- PAC辨识:对
则称学习算法能从假设空间 - PAC可学习:令
- PAC学习算法:满足PAC可学习的算法。(假定学习算法处理每个样本的时间为常数,因此
- 样本复杂度(Sample Complexity):满足
- PAC学习中一个关键因素是假设空间H的复杂度。H包含了学习算法所有可能输出的假设,若在PAC学习中假设空间与概念类完全相同,即H=C,这称为”恰PAC可学习” (properly PAC learnable)。直观地看,这意味着学习算法的能力与学习任务”恰好匹配“。
然而,这个要求拥有来自概念类的所有候选假设似乎是合理的,但并不实用,因为在现实世界的应用中我们通常对概念类一无所知
3 有限假设空间
3.1 可分情形
对于PAC来说,只要训练集
首先估计泛化误差大于
由于
我们事先并不知道学习算法会输出哪个假设,但我们只需要保证泛化误差大于
令上式不大于
可用的
由此可知,有限假设空间
3.2 不可分情形
当
令
则称假设空间是不可知PAC学习的。
4 VC维
VC维:假设空间
例如对二分类问题来说,m个样本最多有
应注意到,VC维与数据分布
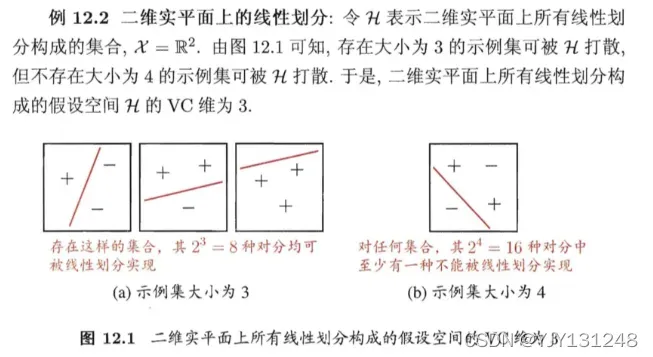

若假设空间
同时任何VC维有限的假设空间
5 Rademacher复杂度
Rademacher 复杂度 (Rademacher complexity) 是另一种刻画假设空间复杂度的途径,与VC维不同的是,它在一定程度上考虑了数据分布。
考虑实值函数空间
经验Rademacher复杂度衡量了函数空间
从
假设空间
6 稳定性
顾名思义,算法的“稳定性”考察的是当输入发生变化时,算法的输出是否会发生显着变化。学习算法的输入是训练集,所以我们首先定义训练集的两个变体:
- remove:
- 替换:
损失函数捕获预测标记和真实标记之间的差异:
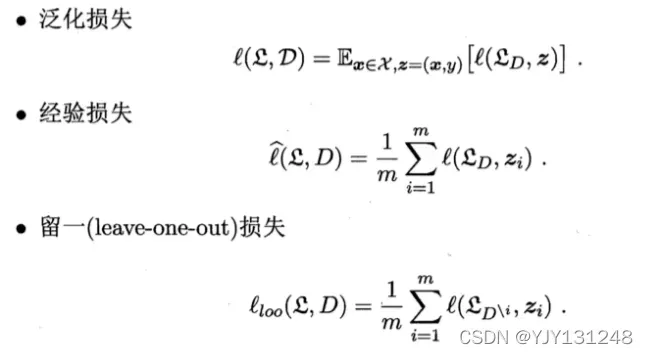

算法的均匀稳定性:


因此,移除示例的稳定性包括替换示例的稳定性。
若学习算法符合经验风险最小化原则(ERM)且稳定的,则假设空间
文章出处登录后可见!