数据是深度学习的基础,我们解决的大多数深度学习问题都是需要数据的。而每一种深度学习框架都对数据的格式有自己的要求,因此,本文主要讲解了 PyTorch 对输入数据的格式要求,以及如何将现实中的数据处理成 PyTorch 能够识别的数据集合。
1.数据批处理
由于深度学习中的数据量通常很大,我们无法一次将所有数据加载到内存中。因此,在模型训练之前,我们一般对训练集进行批处理,将数据随机分成等份,每次迭代只训练一份,如下伪代码所示:
# training loop
for epoch in range(num_epochs):
# 遍历所有的批次
for i in range(total_batches):
batch_x, batch_y = ..
可以看到上面的伪代码:
1.epoch 每增加一次,表示完成了所有数据的一次正向传播和反向传播。
2.total_batches 表示分批后的数据集合。
3.i 每增加一次,表示完成了一批数据的一次正向传播和反向传播
PyTorch 为我们提供了torch.utils.data.DataLoader加载器,该加载器可以自动的将传入的数据进行打乱和分批。DataLoader()的加载参数如下:
1.dataset:需要打乱的数据集。
2.batch_size: 每一批的数据条数。
3.shuffle:True 或者 False,表示是否将数据打乱后再分批。
当然,使用这个loader不仅仅是对数据进行shuffle和batch,loader还可以对数据进行格式化,以便放入后续的神经网络模型中。
二、MNIST 的分批->原始数据集加载
首先让我们加载 PyTorch 中的自带数据集合,该数据集合存在于torchvision.datasets 中,可以直接利用torchvision.datasets.MNIST获得:
import torch
import torchvision
train_dataset=torchvision.datasets.MNIST(root='./data',
train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
print(train_dataset)
输出如下:
Dataset MNIST
Number of datapoints: 60000
Root location: ./data
Split: Train
StandardTransform
Transform: ToTensor()
从结果可以看出该数据集合共有 60000 条数据。由于这些数据都是图片,因此分批传入内存是非常必要的。
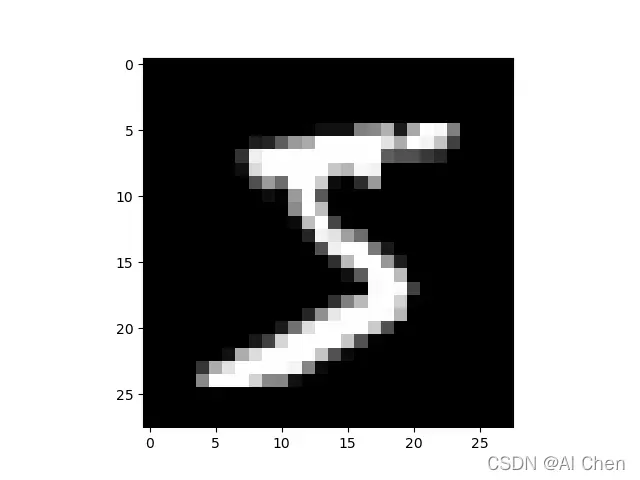
MNIST 数据集合是一个手写字符集合,该数据集合中存储了大量的手写字符图像。我们可以加载一张图片,观察一下:
import numpy as np
import matplotlib.pyplot as plt
a_data,a_label=train_dataset[0]
print(a_label)
img=np.array(a_data+1)*127.5
img=np.reshape(img,[28,28]).astype(np.uint8)
plt.imshow(img,'gray')
plt.show()
该数据集合的分批步骤很简单,只需要将我们得到的数据集合传入 DataLoader 中即可:
from torch.utils.data import DataLoader
train_loader=DataLoader(dataset=train_dataset,batch_size=100,shuffle=True)
num_epochs=1
for epoch in range(num_epochs):
for i ,(inputs,labels) in enumerate(train_loader):
#每100个批次展示一次
if (i+1)%100==0:
print(
f'Epoch: {epoch + 1}/{num_epochs},Step {i + 1}/{len(train_dataset) / 100}| Inputs {inputs.shape} | {labels.shape}')
输出如下:
Epoch: 1/1,Step 100/600.0| Inputs torch.Size([100, 1, 28, 28]) | torch.Size([100])
Epoch: 1/1,Step 200/600.0| Inputs torch.Size([100, 1, 28, 28]) | torch.Size([100])
Epoch: 1/1,Step 300/600.0| Inputs torch.Size([100, 1, 28, 28]) | torch.Size([100])
Epoch: 1/1,Step 400/600.0| Inputs torch.Size([100, 1, 28, 28]) | torch.Size([100])
Epoch: 1/1,Step 500/600.0| Inputs torch.Size([100, 1, 28, 28]) | torch.Size([100])
Epoch: 1/1,Step 600/600.0| Inputs torch.Size([100, 1, 28, 28]) | torch.Size([100])
3. wine数据的批处理->自定义数据集加载
针对于自己的数据集合,我们往往需要对原始的数据进行处理,将其封装成一个继承了Dataset的Python类。这样,我们才能够将其传入 PyTorch 之中,进行数据的分批和模型的训练。
接下来,我们以葡萄酒类型预测为例,详细讲解自定义数据应该如何打包和批处理。
首先,让我们加载数据集合:
import pandas as pd
df = pd.read_csv(
"https://labfile.oss.aliyuncs.com/courses/2316/wine.csv", header=None)
print(df)
输出如下:
0 1 2 3 4 5 ... 8 9 10 11 12 13
0 1 14.23 1.71 2.43 15.6 127 ... 0.28 2.29 5.64 1.04 3.92 1065
1 1 13.20 1.78 2.14 11.2 100 ... 0.26 1.28 4.38 1.05 3.40 1050
2 1 13.16 2.36 2.67 18.6 101 ... 0.30 2.81 5.68 1.03 3.17 1185
3 1 14.37 1.95 2.50 16.8 113 ... 0.24 2.18 7.80 0.86 3.45 1480
4 1 13.24 2.59 2.87 21.0 118 ... 0.39 1.82 4.32 1.04 2.93 735
.. .. ... ... ... ... ... ... ... ... ... ... ... ...
173 3 13.71 5.65 2.45 20.5 95 ... 0.52 1.06 7.70 0.64 1.74 740
174 3 13.40 3.91 2.48 23.0 102 ... 0.43 1.41 7.30 0.70 1.56 750
175 3 13.27 4.28 2.26 20.0 120 ... 0.43 1.35 10.20 0.59 1.56 835
176 3 13.17 2.59 2.37 20.0 120 ... 0.53 1.46 9.30 0.60 1.62 840
177 3 14.13 4.10 2.74 24.5 96 ... 0.56 1.35 9.20 0.61 1.60 560
[178 rows x 14 columns]
Process finished with exit code 0
如上表所示,第一列表示该条数据属于哪一种葡萄酒(0,1,2)。而后面 13 列的数据表示的就是葡萄酒的每种化学成分的浓度。这些化学成分分别为:酒精 、苹果酸 、灰分 、灰分的碱度、镁 、总酚、 黄酮类化合物 、非类黄酮酚 、原花色素 、颜色强度 、色相 、稀释酒的 OD280/OD315 和脯氨酸。
我们需要对这些数据进行分批,那么我们就需要将该数据转为 PyTorch 认识的数据集合。我们可以建立一个类WineDataset去继承Dataset。
如果继承了 Dataset 类,我们就必须实现下面三个函数:
__init__(self) :用于初始化类中需要的一些变量。__len__(self):返回数据集的长度,即数据量。__getitem__(self, index):返回第 index 条数据
from torch.utils.data import Dataset
class WineDataset(Dataset):
# 建立一个数据集合继承 Dataset 即可
def __init__(self):
# I初始化数据
# 以pandas的形式读入数据
xy = pd.read_csv(
"https://labfile.oss.aliyuncs.com/courses/2316/wine.csv", header=None)
self.n_samples = xy.shape[0]
# 将 pandas 类型的数据转换成 numpy 类型
# size [n_samples, n_features]
self.x_data = torch.from_numpy(xy.values[:, 1:])
self.y_data = torch.from_numpy(
xy.values[:, [0]]) # size [n_samples, 1]
# 返回 dataset[index]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
# 返回数据长度
def __len__(self):
return self.n_samples
# 测试
# 创造 dataset
dataset = WineDataset()
dataset[0]
输出如下:
(tensor([1.4230e+01, 1.7100e+00, 2.4300e+00, 1.5600e+01, 1.2700e+02, 2.8000e+00,
3.0600e+00, 2.8000e-01, 2.2900e+00, 5.6400e+00, 1.0400e+00, 3.9200e+00,
1.0650e+03], dtype=torch.float64),
tensor([1.], dtype=torch.float64))
至此,我们将葡萄酒数据也装上了一个“外壳”,使 PyTorch 能够识别出该数据集合。接下来,我们只需要利用DataLoader加载该数据集合即可:
import math
# 传入加载器
train_loader = DataLoader(dataset=dataset, batch_size=4, shuffle=True)
# 分批训练
# 迭代次数
num_epochs = 2
total_samples = len(dataset)
# 批次
n_iterations = math.ceil(total_samples/4)
print("该数据集合共有{}条数据,被分成了{}个批次".format(total_samples, n_iterations))
for epoch in range(num_epochs):
for i, (inputs, labels) in enumerate(train_loader):
# 178 个样本, batch_size = 4, n_iters=178/4=44.5 -> 45 个批次
if (i+1) % 5 == 0:
print(
f'Epoch: {epoch+1}/{num_epochs}, Step {i+1}/{n_iterations}| Inputs {inputs.shape} | Labels {labels.shape}')
输出如下:
该数据集合共有178条数据,被分成了45个批次
Epoch: 1/2, Step 5/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 1/2, Step 10/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 1/2, Step 15/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 1/2, Step 20/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 1/2, Step 25/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 1/2, Step 30/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 1/2, Step 35/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 1/2, Step 40/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 1/2, Step 45/45| Inputs torch.Size([2, 13]) | Labels torch.Size([2, 1])
Epoch: 2/2, Step 5/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 2/2, Step 10/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 2/2, Step 15/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 2/2, Step 20/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 2/2, Step 25/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 2/2, Step 30/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 2/2, Step 35/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 2/2, Step 40/45| Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])
Epoch: 2/2, Step 45/45| Inputs torch.Size([2, 13]) | Labels torch.Size([2, 1])
Process finished with exit code 0
文章出处登录后可见!