1. 循环神经网络概述
循环神经网络(Recurrent Neural Network,RNN),它是专为视频等序列输入而设计的。作为一种实际应用,我们将它们与卷积神经网络(Convolutional Neural Network,CNN)结合起来以检测短视频片段中包含的动作。
1、RNN
RNN是一种适用于序列(或循环)数据的神经网络。序列数据的示例包括句子(单词序列)、时间序列(例如,股票价格序列)或视频(帧序列)。由于每个时间步骤都与前一个相关,因此它们被视为循环数据。
虽然RNN最初是为时间序列分析和自然语言处理任务而开发的,但现在已应用于各种计算机视觉任务。
2、LSTM
常规RNN会遭受梯度爆炸问题。因此,有时很难训练它们在数据序列中的长期关系。此外,它们将信息存储在单一状态矩阵中。例如,如果枪击发生在一段很长视频的最开始,那么在到达视频结尾时,RNN的隐藏状态不太可能不会被噪声覆盖。这段视频可能未归类为暴力视频。
为了规避这两个问题,Sepp Hochreiter和Jürgen Schmidhuber在他们的论文“Long Short-Term Memory”(Neural Computation,1997)中提出了基本RNN的一种变体,即长短期记忆(Long Short-Term Memory,LSTM)单元。这些年来,随着许多变体的引入,它有了很大的改进。
2.视频处理任务概述
1、常用技术
(1)采样:每秒只能分析一到两帧,而不是所有帧。虽然效率更高,但是如果一个重要场景出现得很短暂,例如早些时候提到的枪击,我们可能会丢失信息。
(2)场景提取:这在分析电影时特别受欢迎。一种算法可以检测出视频何时从一个场景切换到另一个场景。景提取可以通过使用快速高效的算法来完成。它们处理图像的像素,并评估两个连续帧之间的差异。差异较大表示发生了场景变化。
2、常见任务
动作检测:视频分类的一种变体,其目标是对一个人正在执行的动作进行分类。动作的范围可以从跑步到踢足球,但也可以像跳舞或演奏乐器一样精确。
下一帧预测:给定N个连续帧,这将预测N+1帧会是什么样的。
超慢动作:也称为帧插值。该模型必须生成中间帧以使慢动作看起来不那么紧张。
对象跟踪:从历史上看,这是使用描述符等经典计算机视觉技术完成的。然而,深度学习现在被应用于跟踪视频中的对象。
3. 例子
1、UCF101数据集
这里使用UCF101 – 动作识别数据集,UCF101 是从 YouTube 收集的真实动作视频的动作识别数据集,具有 101 个动作类别。该数据集是 UCF50 数据集的扩展(具有 50 个动作类别)。
 样本图片
样本图片
UCF101 拥有来自 101 个动作类别的 13320 个视频,在动作方面具有最大的多样性,并且在相机运动、物体外观和姿势、物体尺度、视点、杂乱背景、照明条件等方面存在很大变化,它是最迄今为止具有挑战性的数据集。由于大多数可用的动作识别数据集都是不现实的,并且是由演员上演的,UCF101 旨在通过学习和探索新的现实动作类别来鼓励对动作识别的进一步研究。
CRCV | Center for Research in Computer Vision at the University of Central Florida![]() https://www.crcv.ucf.edu/data/UCF101.php101 个动作类别中的视频分为 25 组,每组可以包含 4-7 个动作视频。来自同一组的视频可能具有一些共同的特征,例如相似的背景、相似的观点等。
https://www.crcv.ucf.edu/data/UCF101.php101 个动作类别中的视频分为 25 组,每组可以包含 4-7 个动作视频。来自同一组的视频可能具有一些共同的特征,例如相似的背景、相似的观点等。
动作类别可分为五种类型:1)人与物体交互2)仅身体运动3) 人与人交互4)演奏乐器5)运动。
UCF101 数据集的动作类别有:上眼妆、上口红、射箭、婴儿爬行、平衡木、乐队行进、棒球场、篮球投篮、篮球扣篮、卧推、骑自行车、台球投篮、吹干头发、吹蜡烛, 自重深蹲, 保龄球, 拳击沙袋, 拳击速度袋, 蛙泳, 刷牙, 挺举, 悬崖跳水, 板球保龄球, 板球射击, 厨房切割, 跳水, 打鼓, 击剑, 曲棍球罚球, 地板体操,飞盘接球,前爬,高尔夫挥杆,理发,锤击,锤击,倒立俯卧撑,倒立步行,头部按摩,跳高,赛马,骑马,呼啦圈,冰上舞,标枪投掷,杂耍球,跳绳,跳跃杰克,皮划艇,针织,跳远,弓步,阅兵,混合面糊,拖地,修女夹头,双杠,比萨折腾, 弹吉他, 弹钢琴, 弹塔布拉, 拉小提琴, 拉大提琴, 演奏Daf, 演奏Dhol, 演奏长笛, 演奏西塔琴, 撑竿跳高, 鞍马, 引体向上, 打孔, 俯卧撑, 漂流, 攀岩室内,绳索攀登、赛艇、莎莎旋转、刮胡子、铅球、滑冰、滑雪、Skijet、跳伞、足球杂耍、足球点球、静止环、相扑、冲浪、秋千、乒乓球拍、太极拳、网球秋千、投掷铁饼,蹦床,打字,高低不平的酒吧,排球扣球,遛狗,墙俯卧撑,板上写字,溜溜球。刮胡子, 铅球, 滑冰, 滑雪, 滑水, 跳伞, 足球杂耍, 足球点球, 静止环, 相扑, 冲浪, 秋千, 乒乓球, 太极, 网球秋千, 掷铁饼, 蹦床, 打字, 高低不平酒吧,排球扣球,遛狗,墙俯卧撑,板上写字,溜溜球。刮胡子, 铅球, 滑冰, 滑雪, 滑水, 跳伞, 足球杂耍, 足球点球, 静止环, 相扑, 冲浪, 秋千, 乒乓球, 太极, 网球秋千, 掷铁饼, 蹦床, 打字, 高低不平酒吧,排球扣球,遛狗,墙俯卧撑,板上写字,溜溜球。
UCF101 – 动作识别数据集下载地址:
https://www.crcv.ucf.edu/data/UCF101/UCF101.rar![]() https://www.crcv.ucf.edu/data/UCF101/UCF101.rar
https://www.crcv.ucf.edu/data/UCF101/UCF101.rar
2、抽帧策略
为了生成特征向量,我们将使用在ImageNet数据集上训练过的预训练Inception网络,对不同类别的图像进行分类。
不会使用视频中的所有帧,因为很多帧都相似,并且计算量太大,所以需要提取帧。如何提取有这样几个选择,(1)每秒提取N帧(2)从所有帧中采样N帧(3)分割场景中的视频,每个场景提取N帧。
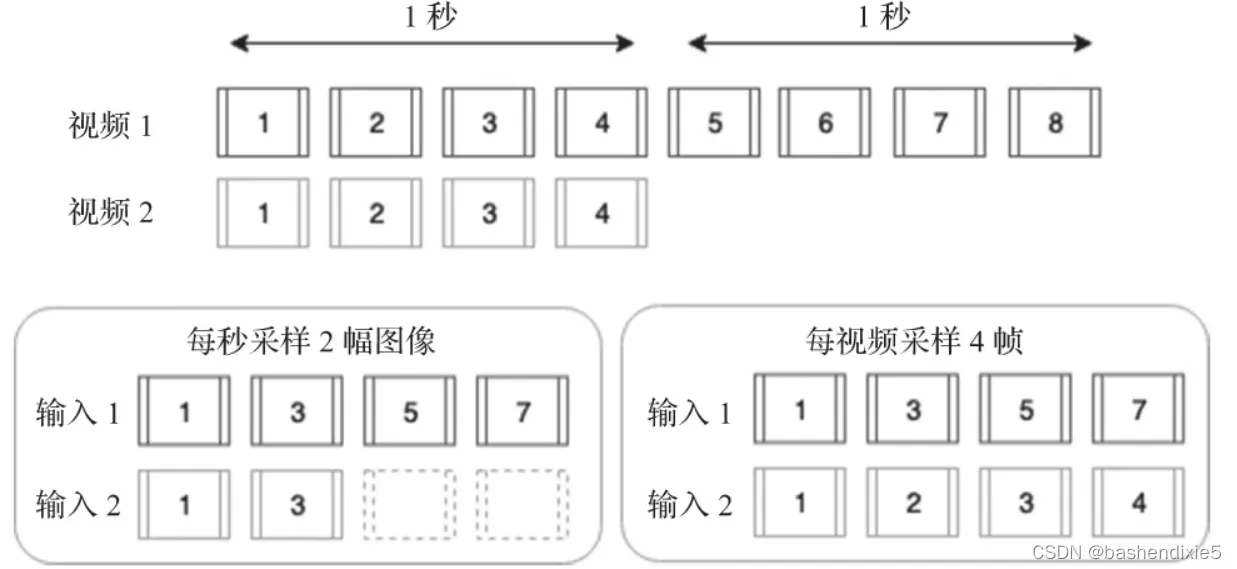
由于视频长度的变化很大,每秒提取N帧也会导致输入长度的变化很大。尽管这可以通过填充来解决,但最终会得到一些主要由零组成的输入,这可能导致训练性能不佳。因此,我们将从每个视频采样N幅图像。
我们使用tf.data.Dataset.from_generator提取特征。
3、训练网络识别动作
需要以下的包opencv-python 、matplotlib、tqdm、scikit-learn。
参考代码如下:
import tensorflow as tf
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
import tqdm
from sklearn.preprocessing import LabelBinarizer
BASE_PATH = '../data/UCF-101'
VIDEOS_PATH = os.path.join(BASE_PATH, '**','*.avi')
SEQUENCE_LENGTH = 40
########## 使用oencv进行视频帧的抽取
def frame_generator():
video_paths = tf.io.gfile.glob(VIDEOS_PATH)
np.random.shuffle(video_paths)
for video_path in video_paths:
frames = []
cap = cv2.VideoCapture(video_path)
num_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
sample_every_frame = max(1, num_frames // SEQUENCE_LENGTH)
current_frame = 0
label = os.path.basename(os.path.dirname(video_path))
max_images = SEQUENCE_LENGTH
while True:
success, frame = cap.read()
if not success:
break
if current_frame % sample_every_frame == 0:
# OPENCV reads in BGR, tensorflow expects RGB so we invert the order
frame = frame[:, :, ::-1]
img = tf.image.resize(frame, (299, 299))
img = tf.keras.applications.inception_v3.preprocess_input(
img)
max_images -= 1
yield img, video_path
if max_images == 0:
break
current_frame += 1
# `from_generator` might throw a warning, expected to disappear in upcoming versions:
# https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/data/Dataset#for_example_2
dataset = tf.data.Dataset.from_generator(frame_generator,
output_types=(tf.float32, tf.string),
output_shapes=((299, 299, 3), ()))
dataset = dataset.batch(16).prefetch(tf.data.experimental.AUTOTUNE)
########## 特征提取
inception_v3 = tf.keras.applications.InceptionV3(include_top=False, weights='imagenet')
x = inception_v3.output
# We add Average Pooling to transform the feature map from
# 8 * 8 * 2048 to 1 x 2048, as we don't need spatial information
pooling_output = tf.keras.layers.GlobalAveragePooling2D()(x)
feature_extraction_model = tf.keras.Model(inception_v3.input, pooling_output)
########## 提取特征并将它们存储在 .npy 文件中
current_path = None
all_features = []
for img, batch_paths in tqdm.tqdm(dataset):
batch_features = feature_extraction_model(img)
batch_features = tf.reshape(batch_features,
(batch_features.shape[0], -1))
for features, path in zip(batch_features.numpy(), batch_paths.numpy()):
if path != current_path and current_path is not None:
output_path = current_path.decode().replace('.avi', '.npy')
np.save(output_path, all_features)
all_features = []
current_path = path
all_features.append(features)
########## 标签预处理
LABELS = ['UnevenBars','ApplyLipstick','TableTennisShot','Fencing','Mixing','SumoWrestling','HulaHoop','PommelHorse','HorseRiding','SkyDiving','BenchPress','GolfSwing','HeadMassage','FrontCrawl','Haircut','HandstandWalking','Skiing','PlayingDaf','PlayingSitar','FrisbeeCatch','CliffDiving','BoxingSpeedBag','Kayaking','Rafting','WritingOnBoard','VolleyballSpiking','Archery','MoppingFloor','JumpRope','Lunges','BasketballDunk','Surfing','SkateBoarding','FloorGymnastics','Billiards','CuttingInKitchen','BlowingCandles','PlayingCello','JugglingBalls','Drumming','ThrowDiscus','BaseballPitch','SoccerPenalty','Hammering','BodyWeightSquats','SoccerJuggling','CricketShot','BandMarching','PlayingPiano','BreastStroke','ApplyEyeMakeup','HighJump','IceDancing','HandstandPushups','RockClimbingIndoor','HammerThrow','WallPushups','RopeClimbing','Basketball','Shotput','Nunchucks','WalkingWithDog','PlayingFlute','PlayingDhol','PullUps','CricketBowling','BabyCrawling','Diving','TaiChi','YoYo','BlowDryHair','PushUps','ShavingBeard','Knitting','HorseRace','TrampolineJumping','Typing','Bowling','CleanAndJerk','MilitaryParade','FieldHockeyPenalty','PlayingViolin','Skijet','PizzaTossing','LongJump','PlayingTabla','PlayingGuitar','BrushingTeeth','PoleVault','Punch','ParallelBars','Biking','BalanceBeam','Swing','JavelinThrow','Rowing','StillRings','SalsaSpin','TennisSwing','JumpingJack','BoxingPunchingBag']
encoder = LabelBinarizer()
encoder.fit(LABELS)
########## 定义模型
model = tf.keras.Sequential([
tf.keras.layers.Masking(mask_value=0.),
tf.keras.layers.LSTM(512, dropout=0.5, recurrent_dropout=0.5),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(len(LABELS), activation='softmax')
])
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy', 'top_k_categorical_accuracy'])
########## 读取并划分数据集
test_file = os.path.join('data', 'testlist01.txt')
train_file = os.path.join('data', 'trainlist01.txt')
with open('data/testlist01.txt') as f:
test_list = [row.strip() for row in list(f)]
with open('data/trainlist01.txt') as f:
train_list = [row.strip() for row in list(f)]
train_list = [row.split(' ')[0] for row in train_list]
def make_generator(file_list):
def generator():
np.random.shuffle(file_list)
for path in file_list:
full_path = os.path.join(BASE_PATH, path).replace('.avi', '.npy')
label = os.path.basename(os.path.dirname(path))
features = np.load(full_path)
padded_sequence = np.zeros((SEQUENCE_LENGTH, 2048))
padded_sequence[0:len(features)] = np.array(features)
transformed_label = encoder.transform([label])
yield padded_sequence, transformed_label[0]
return generator
train_dataset = tf.data.Dataset.from_generator(make_generator(train_list),
output_types=(tf.float32, tf.int16),
output_shapes=((SEQUENCE_LENGTH, 2048), (len(LABELS))))
train_dataset = train_dataset.batch(16).prefetch(tf.data.experimental.AUTOTUNE)
valid_dataset = tf.data.Dataset.from_generator(make_generator(test_list),
output_types=(tf.float32, tf.int16),
output_shapes=((SEQUENCE_LENGTH, 2048), (len(LABELS))))
valid_dataset = valid_dataset.batch(16).prefetch(tf.data.experimental.AUTOTUNE)
########## 进行训练
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir='/tmp', update_freq=1000)
model.fit(train_dataset, epochs=20, callbacks=[tensorboard_callback], validation_data=valid_dataset)文章出处登录后可见!