



yolov5-6.1版本功能测试(全)
此文段所述性能指标仅对此次数据具有参考价值,后续仍需佐证此观点
文章主题:yolov5-6.1版本性能对比,以及如何提升性能最佳,结果出乎意料,发现最优optimizer,最优scheduler。
1. 上个版本的表现如何?
示例:往期使用的框架为yolov5-3.0版本,时隔一年,老版本已经再打不起精神,在Ai时代的推演下,当时的呼声早已石沉大海。
话不多说,直接上图,先记住3.0版本的性能: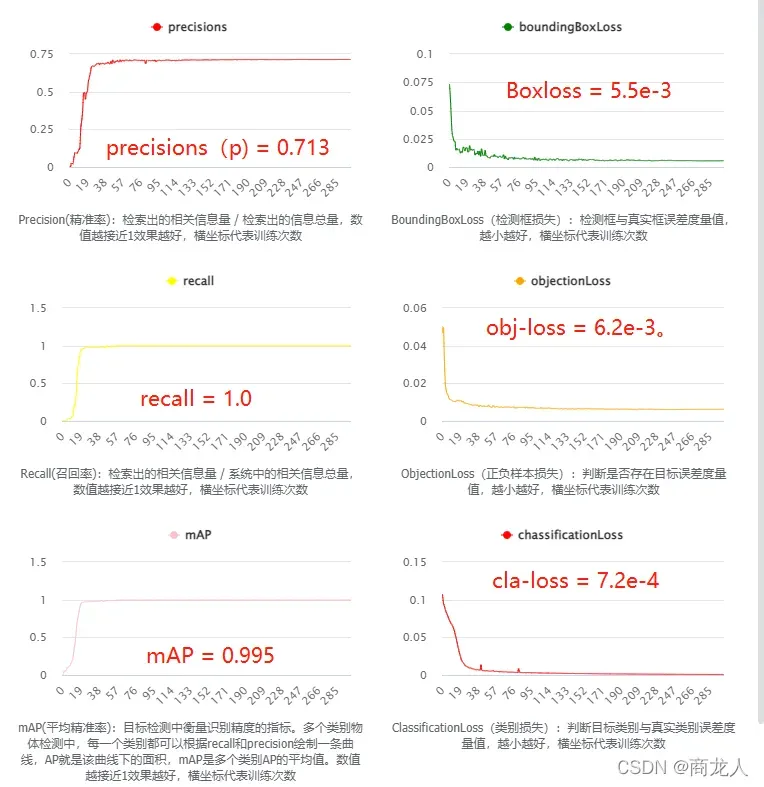
看起来还可以,我们先总结一下结果:
mAP = 0.995, recall = 1.0 , precisions(p) = 0.713 ,
cla-loss = 7.2e-4 , Boxloss = 5.5e-3 , obj-loss = 6.2e-3。
接下来,6.1版本走一波,然后做对比分析。
二、yolov5-6.1版本测试
1.exp1_原始代码无改动(红线)
代码下载:
https://github.com/ultralytics/yolov5/commit/3752807c0b8af03d42de478fbcbf338ec4546a6c
运行条件:GPU环境=Teslav100_32g , 数据样本量4000张图片 ,label引用量 = 11458 ,epochs = 200,
imagesize = 640 , lr = 0.01, lrf = 0.01 ,optim = SGD ,
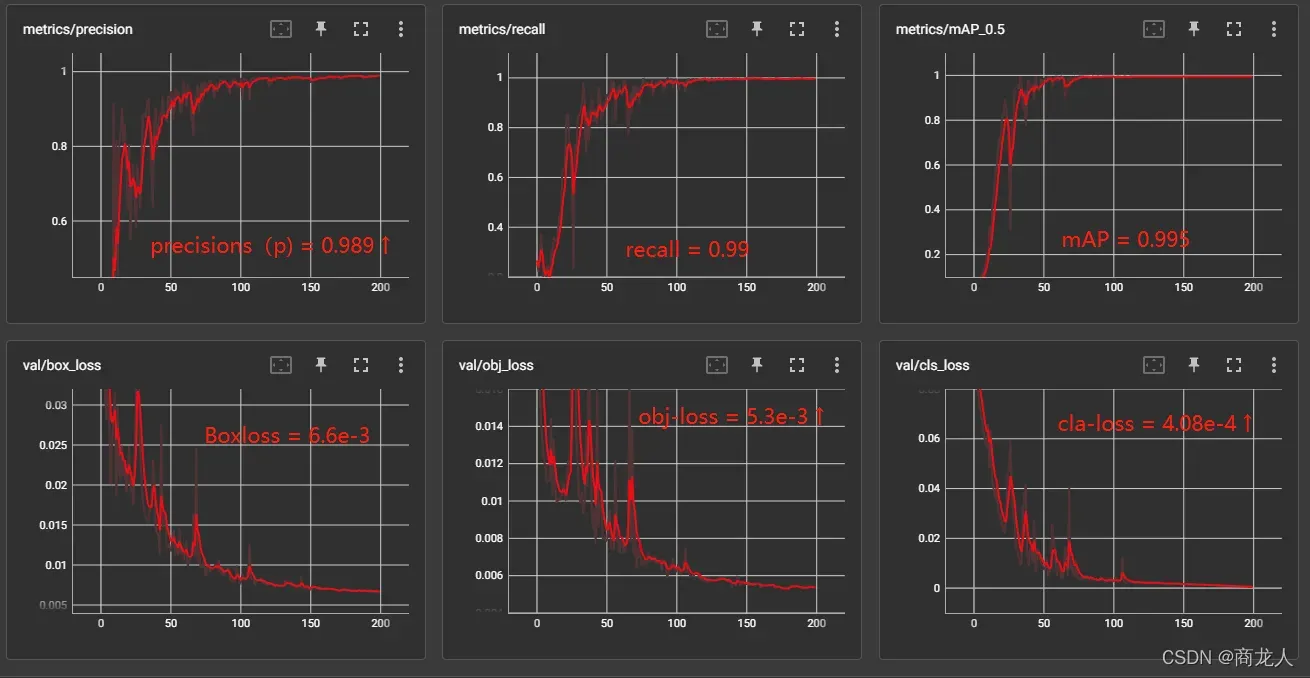

yolov5_6.1各项参数:
mAP = 0.995, recall = 0.99 , precisions(p) = 0.989 ↑ ,
cla-loss = 4.08e-4 ↑, Boxloss = 6.6e-3 , obj-loss = 5.3e-3 ↑。
yolov5_3.0参数对比:
(mAP = 0.995, recall = 1.0 , precisions(p) = 0.713 ,
cla-loss = 7.2e-4 , Boxloss = 5.5e-3 , obj-loss = 6.2e-3。)
对比之下,在召回率相同的的情况下,大大提升30%精准度。损失值也降低1-3个点。
2.exp2_原始基础上新增cos-lr(退火余弦学习率迭代)(黄线)
代码如下(后面会默认开启):
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler',
default=True)
这里唯一的区别是由于动态学习率的不同迭代!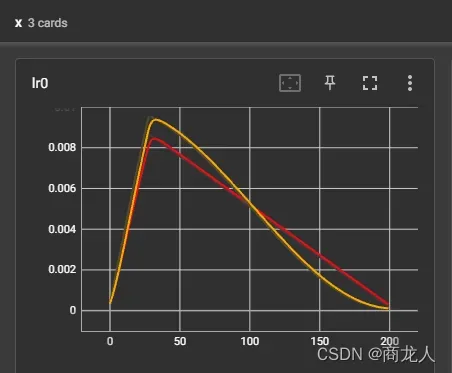

虽然在最终可视化上稍微好一点,但在混淆矩阵上效果很好: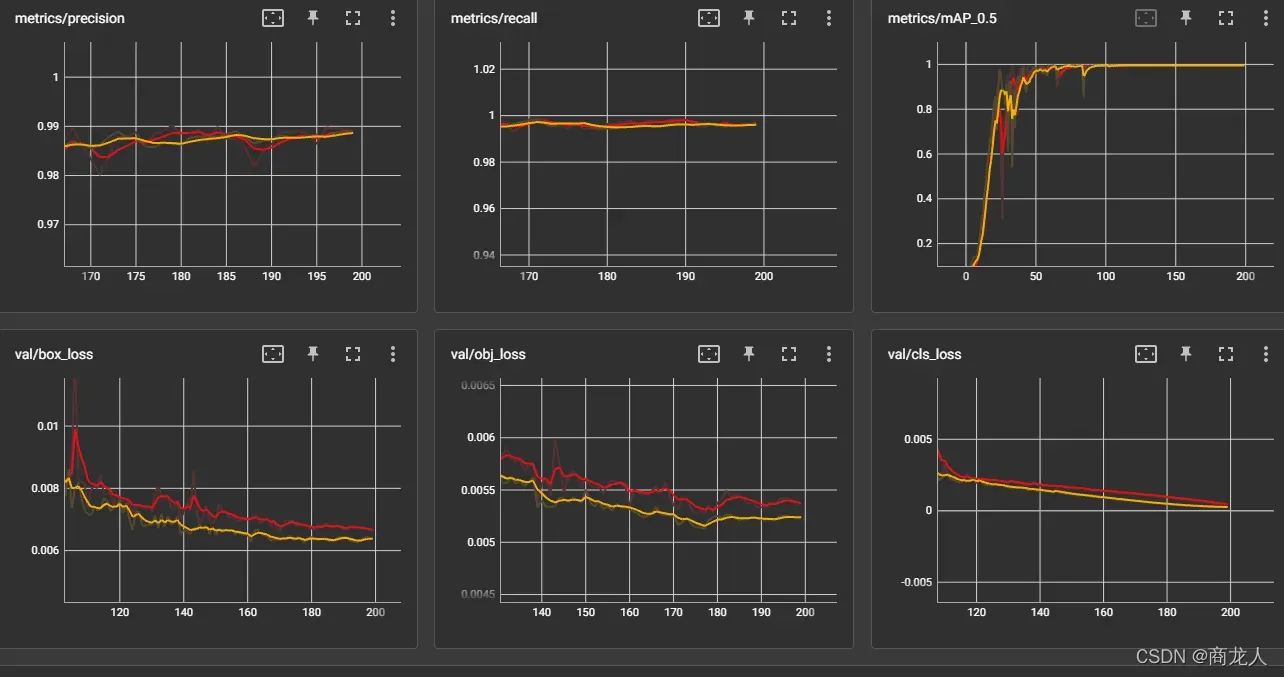

混淆矩阵效果对比:(图一为关闭 cos-lr scheduler )仍然会有样本混淆。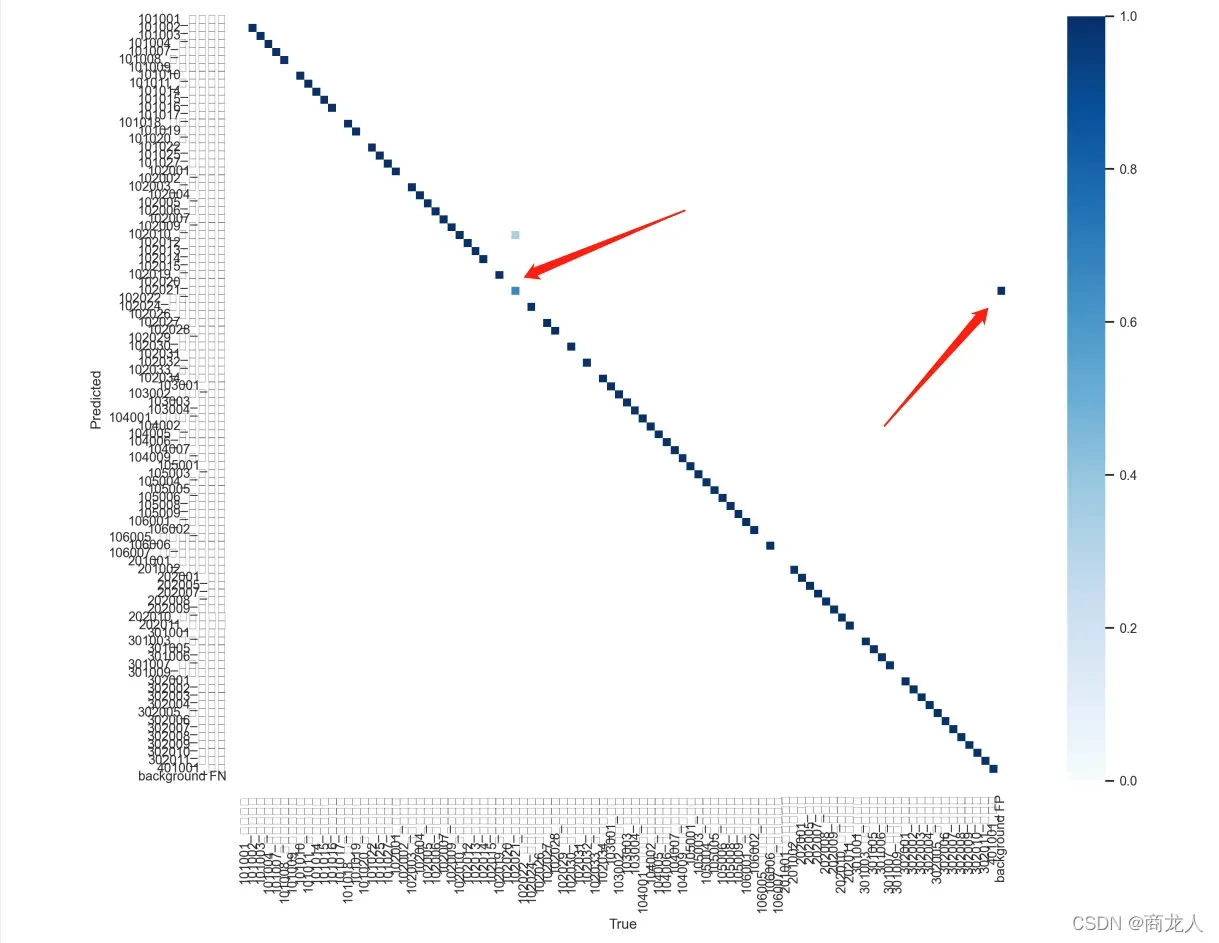

(图二为打开 cos-lr scheduler )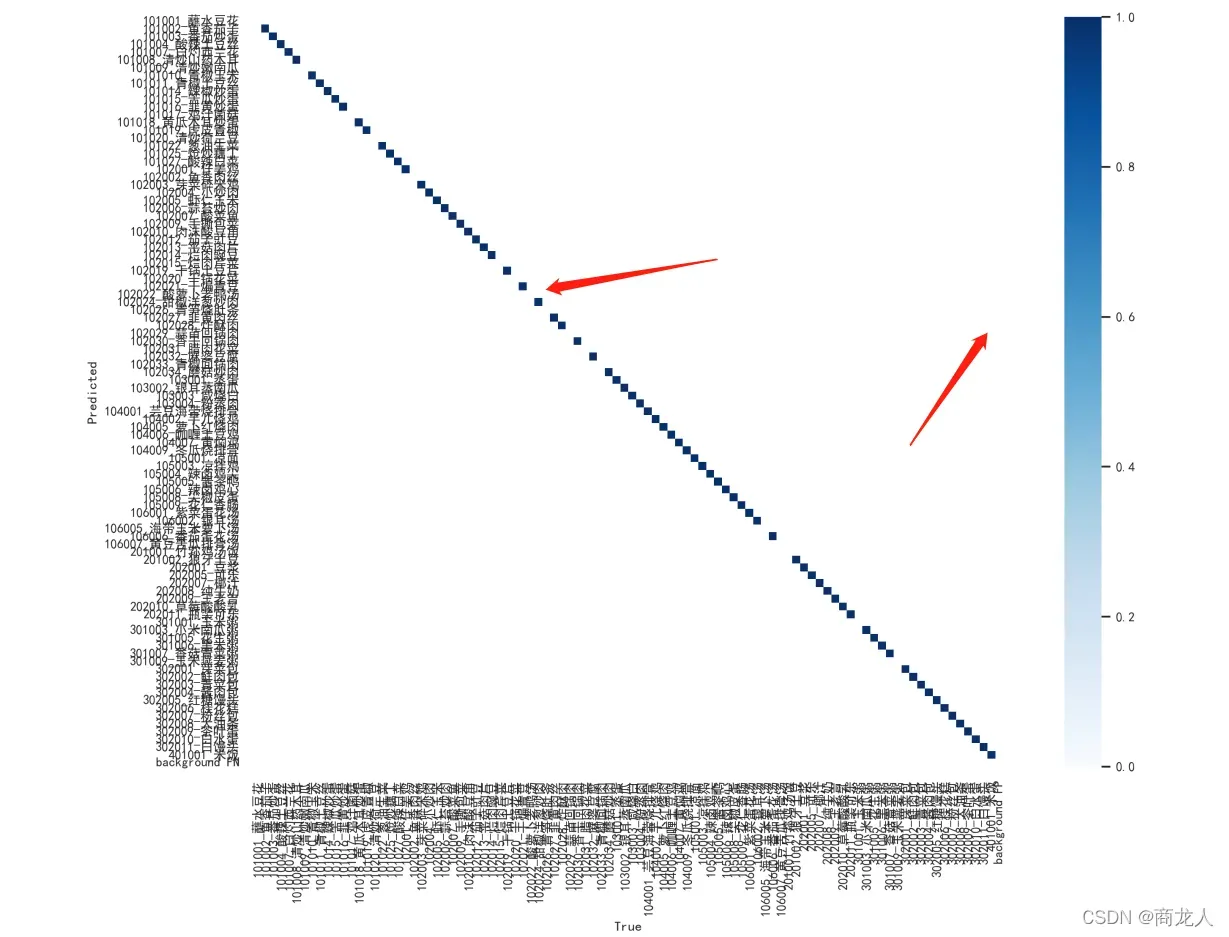

3.exp3_打开冻结主干网络(绿线),降低学利率初始值(橙线)
为了更有效的展示,同时总结了冻结和降低学费的两个实验。
方法一:冻结主代码如下(后面会默认开启):
parser.add_argument('--freeze', nargs='+', type=int, default=[10], help='Freeze layers: backbone=10, first3=0 1 2')
方法二:将lr = 0.01,lrf = 0.01,调整为lr = 0.001 ,lrf = 0.2。目的:将学路率调小,避免过程震荡。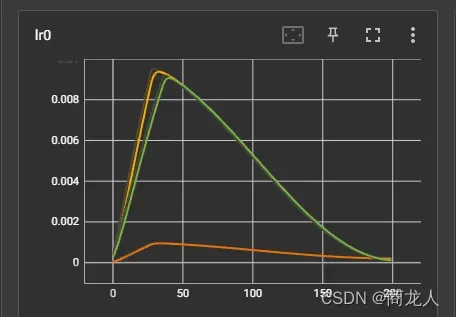

最后再来看看渲染效果:(如果表现平平就不强调了,各提各的优缺点)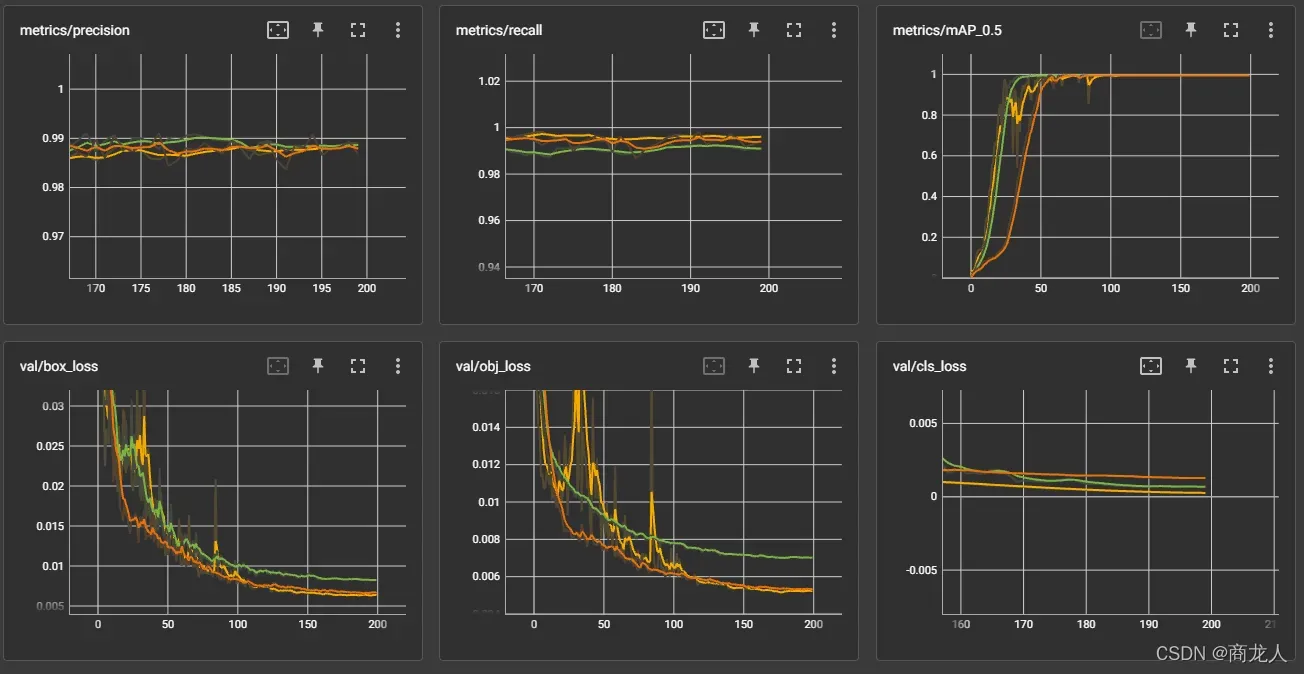

在loss曲线可以看出,最有解让仍为第二种方法(黄色),最差的为(绿色)冻结主干网络,
总结:冻结网络绿色可以避免曲线动荡,但是对于大幅度加快网络训练并没有体现,200epoch只*快了0.005h*,效果并不好,但是可以降低GPU耗能,节省GPU寿命,从混淆矩阵看,易混淆的类别增多。
对于将lr调小以后(橙色),迭代速度变慢,但是曲线稳定,最终结果并不比较大的动态学习率效果好。
4.exp4_更改yolo新推出的优化器AdamW(蓝线)
最后我们尝试一下新推出的AdamW优化器的性能如何
python train.py --optim=AdamW
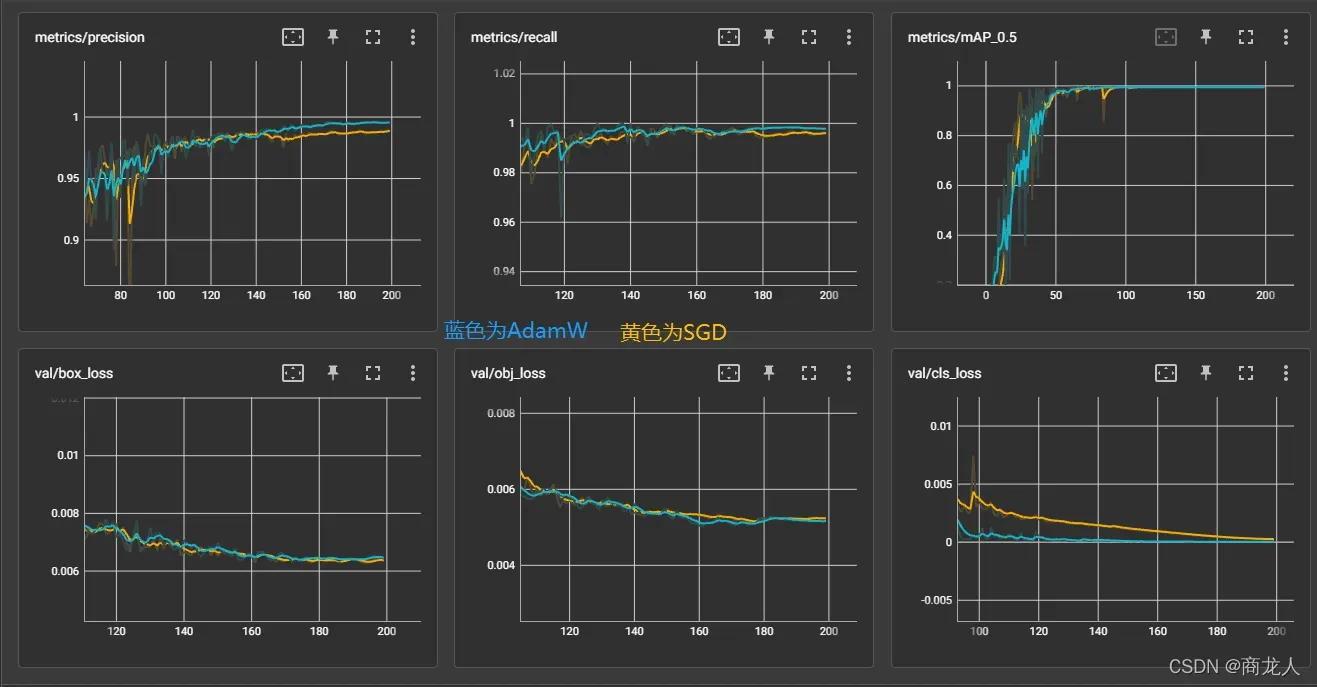
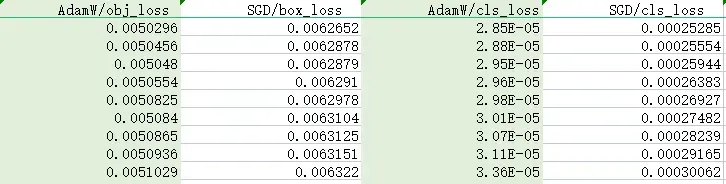
AdamW 相比于 SGD,recall 提升0.1%,precisions 提升 1%,cls_loss 提升10倍。
在results.csv文件看对应指数,最终结果仍然是AdamW能取得最优解。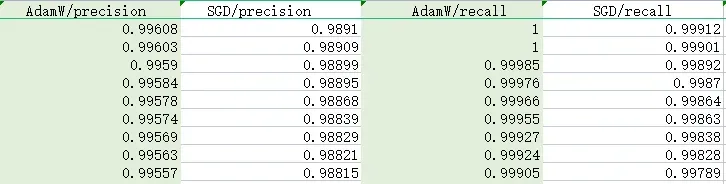
以下是实际应用效果:



总结
以上就是今天要讲的内容,本文仅仅简单介绍了yolov5-6.1版本的性能,以及简单的optimizer,scheduler的性能对比,性能指标仅对此次数据具有参考价值,后续仍需佐证此观点,在此再次陈述一下上文的观点。
1.选择return cosine learning rate迭代,性能会更好,但时间会稍微延长,可以忽略;
二、使用AdamW优化器取代SGD优化器在最终结果时,略优于SGD;
3、在整个训练过程中使用动态学习率(学习率从大到小),可以有效提高迭代速度,也可以使模型达到最优解;
四、环境允许的情况下,freeze冻结网络并不能在性能持平的情况下加快训练速度。
文章出处登录后可见!