GRU结构概述
GRU(Gated recurrent unit)是RNN中的一种门机制单元,与LSTM类似,GRU有一个遗忘门(forget gate),但其没有输出门(output gate)。GRU在音乐模型、语音信号模型和NLP模型中的性能与LSTM类似,而且在一些小样本数据集表现出更有的性能。
GRU结构
GRU的结构如下图所示:
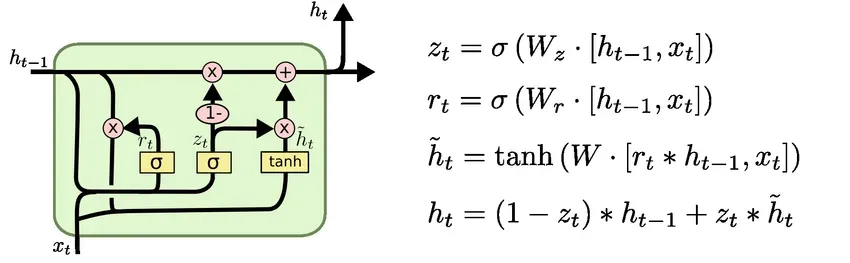
它只有两个门,对应输出更新门(update gate)向量:和重置门(reset gate)向量:
,更新门负责控制上一时刻状态信息
对当前时刻状态的影响,更新门的值越大说明上一时刻的状态信息
带入越多。而重置门负责控制忽略前一时刻的状态信息
的程度,重置门的值越小说明忽略的越多。注意前两个,更新门和重置门的表达式,
表示两个向量连接,
表示矩阵相乘,
表示sigmoid函数。
接下来,“重置”之后的重置门向量 与前一时刻状态
卷积
,再将
与输入
进行拼接,再通过激活函数tanh来将数据放缩到-1~1的范围内。这里包含了输入数据
,并且将上一时刻状态的卷积结果添加到当前的隐藏状态,通过此方法来记忆当前时刻的状态。
最后一个步骤是更新记忆阶段,此阶段同时进遗忘和记忆两个步骤,使用同一个门控同时进行遗忘和选择记忆(LSTM是多个门控制)
:对隐藏的原状态,选择性地遗忘。
:对当前节点信息,进行选择性的记忆。
GRU单元的tensorflow 实现
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
X=tf.reshape(X,[-1,W_xh.shape[0]])
Z = tf.sigmoid(tf.matmul(X, W_xz) + tf.matmul(H, W_hz) + b_z)
R = tf.sigmoid(tf.matmul(X, W_xr) + tf.matmul(H, W_hr) + b_r)
H_tilda = tf.tanh(tf.matmul(X, W_xh) + tf.matmul(R * H, W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = tf.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,)
版权声明:本文为博主I_belong_to_jesus原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/fangfanglovezhou/article/details/122560797