



整体思路:先获取数据,把数据分为训练数据和测试数据,然后在不同k值的模型下分别训练和测试,得出不同k值情况下的模型预测准确性,最后把准确性可视化输出进行整体评估。
1.获取数据
from sklearn import datasets
iris=datasets.load_iris()
x=iris.data
y=iris.target2.分离数据
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)test_size=0.3相当于测试数据的占比是0.3,而训练数据的占比是0.7,也可以通过下面代码验证
print(x_train.shape,x_test.shape,y_train.shape,y_test.shape)(105, 4) (45, 4) (105,) (45,)
3.不同k值的模型下分别训练和测试,得出不同k值情况下的模型预测准确性
3.1创建一个1-25的列表
k_range=list(range(1,26))
print(k_range)[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25]
3.2 分别创建训练数据得分准确率空列表和测试数据得分准确率空列表,用于收遍历循环后的数据
train_score=[]
test_score=[]3.3 导入建立模型模块和判断准确率模块
from sklearn.neighbors import KNeighborsClassifierfrom sklearn.metrics import accuracy_score3.4开始不同的k值遍历循环
for k in k_range:
knn=KNeighborsClassifier(n_neighbors=k)
knn.fit(x_train,y_train)
y_train_predict=knn.predict(x_train)
y_test_predict=knn.predict(x_test)
a=accuracy_score(y_train,y_train_predict)
b=accuracy_score(y_test,y_test_predict)
train_score.append(a)
test_score.append(b)3.5因为一个模型的评估主要是针对测试数据进行预测的准确率的高低,所以只提取测试数据准确率
for k in k_range:
print(k,test_score[k-1])1 0.95555555555555562 0.95555555555555563 0.95555555555555564 0.95555555555555565 0.97777777777777776 0.95555555555555567 0.97777777777777778 0.97777777777777779 0.977777777777777710 0.955555555555555611 1.012 1.013 1.014 0.977777777777777715 1.016 1.017 1.018 0.955555555555555619 0.977777777777777720 0.977777777777777721 1.022 0.955555555555555623 0.955555555555555624 0.933333333333333325 0.9555555555555556
4.评估数据图表可视化
4.1导入绘图库模块
import matplotlib.pyplot as plt4.2设置输出结果参数
%matplotlib inline4.3开始输出训练准确率图标
plt.plot(k_range,train_score)
plt.xlabel('k_volue')
plt.ylabel('score')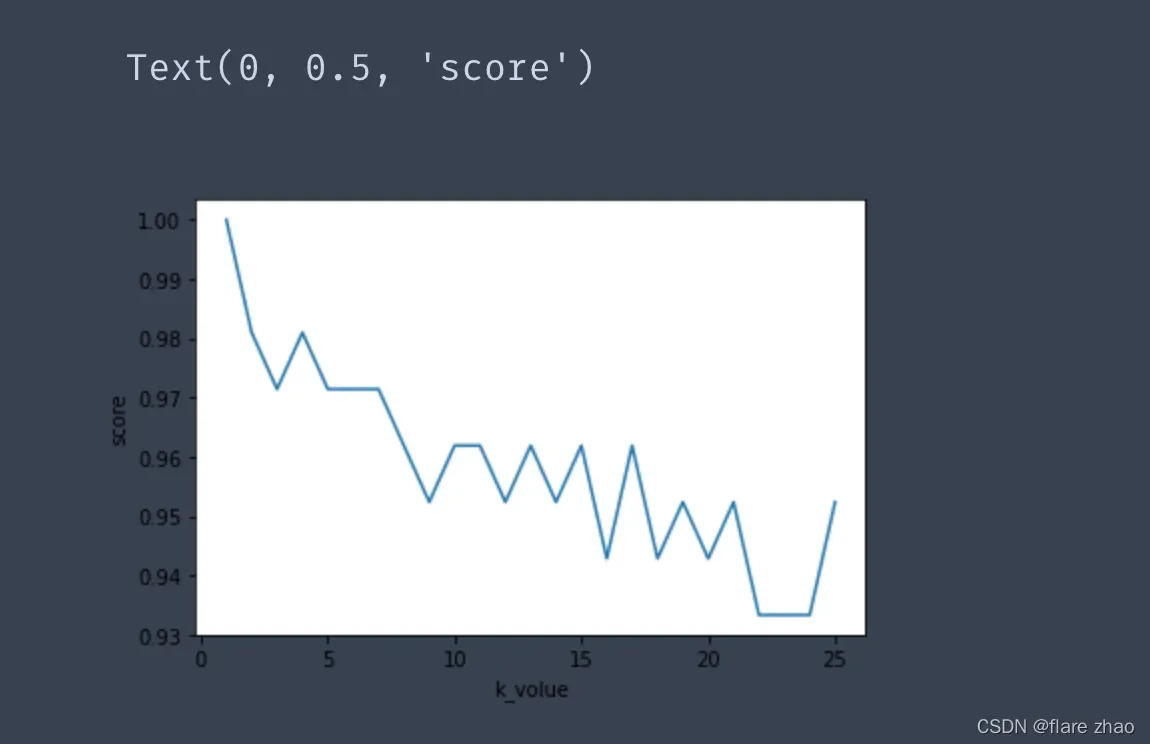
4.4开始输出测试数据准确率
plt.plot(k_range,test_score)
plt.xlabel('k_volue')
plt.ylabel('score')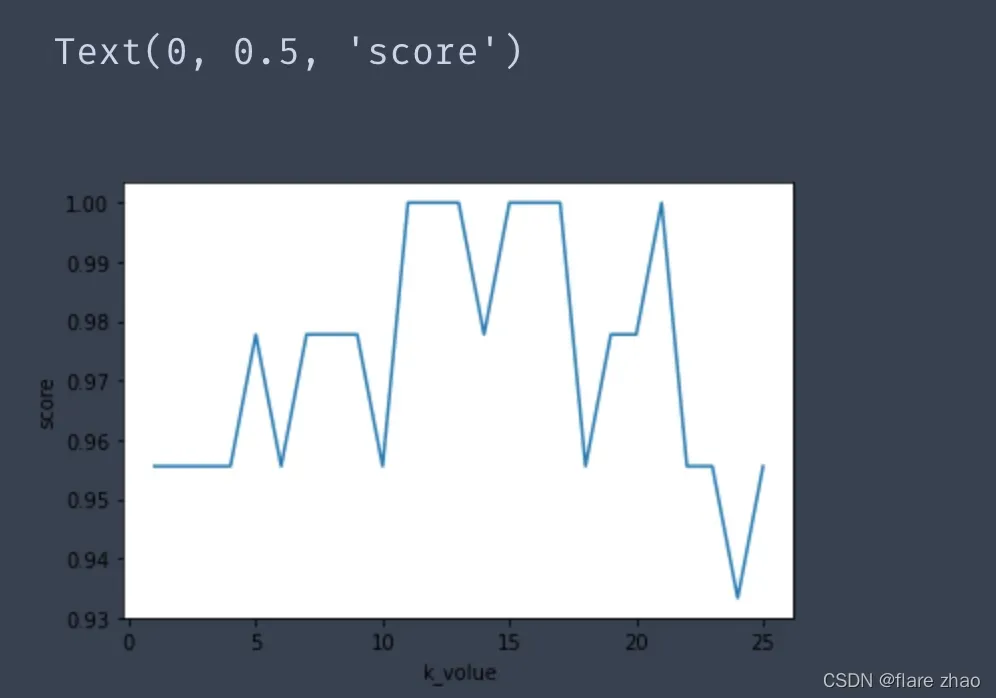

从测试数据得分率看出不是k越小或者越大,准确率越高,几乎是随机的。
k值越小,模型越过于拟合,越复杂
文章出处登录后可见!
已经登录?立即刷新