SR-LUT是2021年的一篇SISR领域的CVPR论文。SR-LUT以较快的执行速度,可脱离CNN在移动端也能快速实现超分的特点,此外其在重建表现力上也具有一定的能力。因此这篇文章很是有必要阅读一番关于SR-LUT的理论解析部分见我的另一篇超分之SR-LUT(建议先看论文解读部分,再来看源码解析)。
- SR-LUT作者提供了PyTorch实现的源码,点这里。
- 关于常用测试集Set5等,点这里。
- SR-LUT源码中主要分为3个 .py 文件:训练、存表、读表,分别在下图3个文件夹中:
下面我们对这三个部分进行简要分析。
1 训练部分
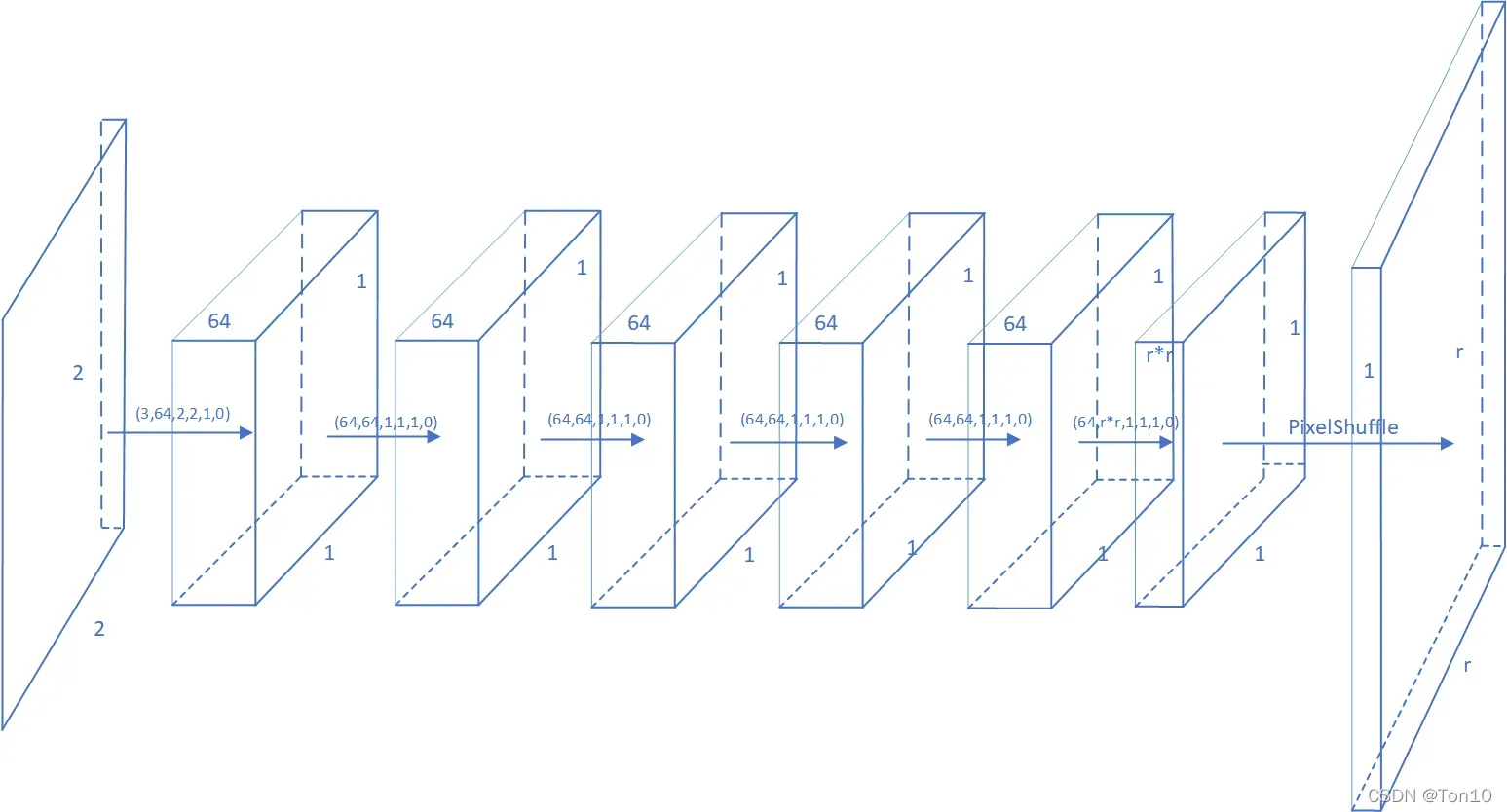
1.1 CNN模型结构
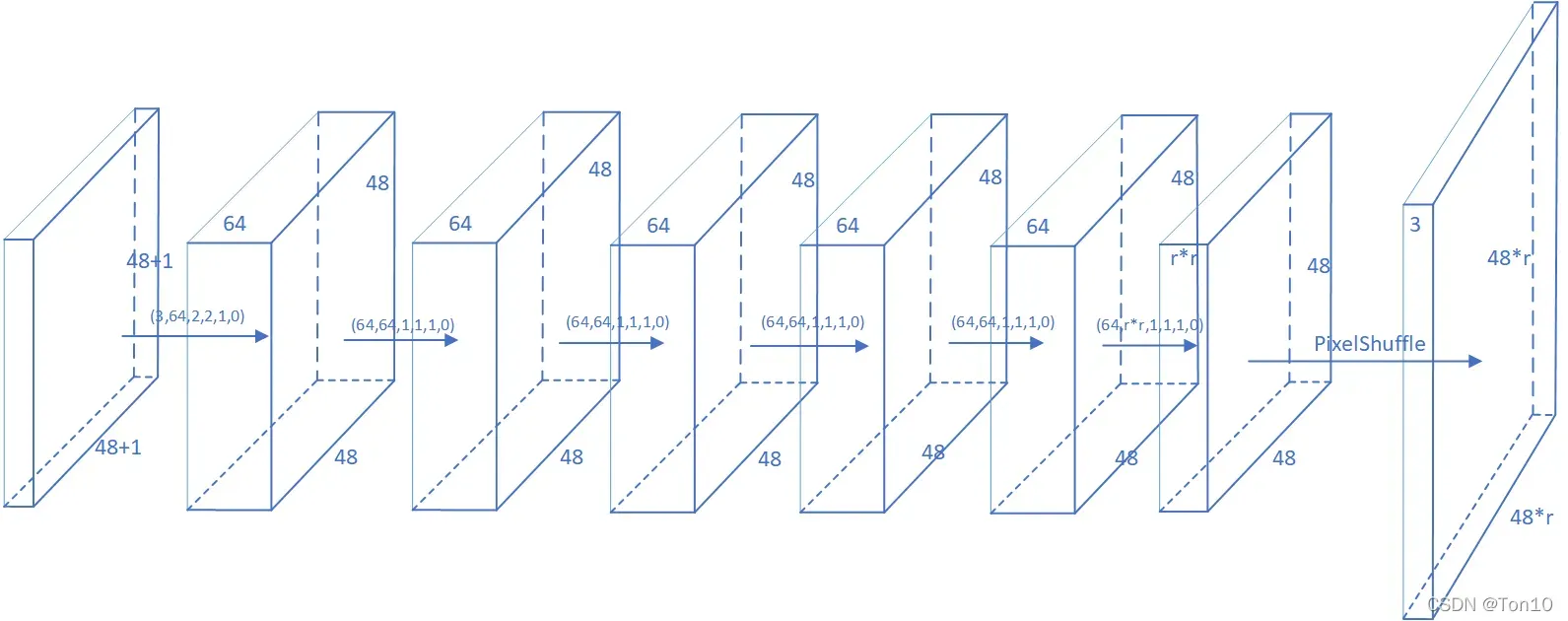
如上图所示是SR-LUT的CNN结构:
- 第0层是输入层:SR-LUT训练部分从DIV2K数据集中抠出
的patch作为网络训练的输入size,输入通道数为3。
- 第1~6层是卷积层:常规的特征提取,其中除了第一层是用
的卷积核提取的,其余几层都是使用了大小为
的滤波器。需要注意的是最后一层卷积层是要输出通道数为
的feature map。
- 第7层是亚像素卷积层:由于上一层输出了
倍的输出feature map:
- 最后一层是输出层。输出图像的格式为
,其中
Note:
- 论文中写的
- 卷积层参数例如(3,64,2,2,1,0)表示输入通道数3,输出通道数64,卷积核
- 输入层
的输入,是为了保持输出为
,使用的是Pytorch的 torch.pad 函数(填充模式是镜像模式)。
- 网络的输入图像被归一化。
1.2 训练过程解析
为了扩大感受野而不增加LUT存储量,作者采用了自集成(self-ensemble),不同于EDSR中将自集成应用于测试中来提高重建表现力,SR-LUT作者将此技巧用于训练中,实验证明该方式确实有助于提升图像整体表现力。
文中采用了4种方式,分别是原图、旋转90°、旋转180°、旋转270°来增强图像,对每一种增强都将输入图像按照先变换
再输入网络再逆变换
成放大后的
图像的顺序去训练。
用一个公式来表达:
然后将自集成的结果与Ground做MSE-Loss,然后梯度下降更新模型参数:
Note:
- 我们再来总结一下这部分的训练:从DIV2K数据集中取出batch张图片,每一张图片都要进行4次的增强操作,并进行pad填充,之后再输入SR-LUT网络,将输出的结果进行之前增强的逆操作输出
图片,将这些图片取平均得到
,然后和Ground Truth(标签)做loss,从而可以更新模型参数,让模型学会如何重建
图片。
- 关于填充,PyTorch采用torch.pad函数来处理,关于这个函数的解析,可参考PyTorch碎片:F.pad的图文透彻理解。
- 关于旋转,PyTorch采用 torch.rot90 函数来处理,关于这个函数的解析,可借鉴我的另一篇PyTorch之rot函数。
综上所述:
- 这一部分只是和之前的SR算法一样,去训练一个可以将
其输入是一张图片或者图片的patch,训练的目的就是找到一个函数,它可以实现
。
- 训练的结果就是得到一个模型,我们保存下来,在下一个环节的表格存储部分使用。
2 存表部分
这部分为了方便讨论,令SR缩放系数。
2.1 表格构建
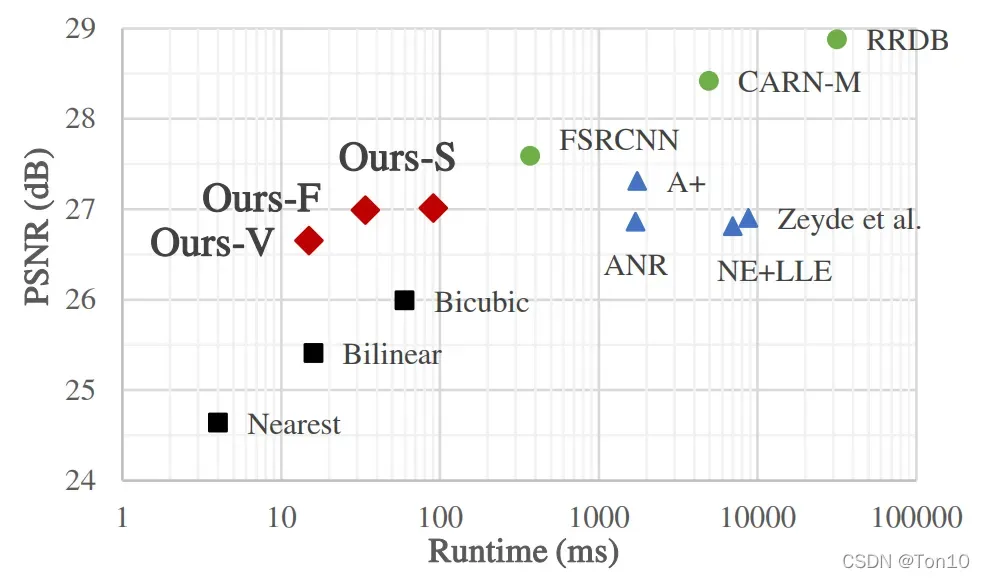
在SR-LUT论文中,作者设置了3个SR-LUT变体:Ours-V、Ours-F、Ours-S,分别代表感受野为2D、3D以及4D时候的SR-LUT。为了方便讨论,接下来我们只讨论4D感受野(即)下的SR-LUT结构。
SR-LUT表格的构建是以输入像素的像素值为索引,以SR-LUT网络输出结果(不做自集成)为内容构建的。
理论情况下,对于感受野,表格的索引一共有
种可能,且每一种可能都需要存
个8bits的值,因此存储量为(
):
这样的存储量是非常大的,当我们在手机端执行的时候,要从这么大的表里去查找
对应的
像素值,显然是不可能的,因此为了减小Full-LUT的存储量,作者引入Sampled-LUT,即我们引入采样间隔
,将
这个区间按采样间隔分开来,这样就只剩下了
种像素值,分别是
。这种思想就类似于直方图统计,对于RGB一共
位的图像,如果统计每个颜色的像素个数,那就完蛋了,因此常用的做法是,规定一个区间,将颜色相近的放到一个区间之内,凡是在同一个区间的都当成是一个颜色来看待,然后进行像素值统计。那么这里也是一样,比如我们将像素值在
之内的像素都当成是一个像素值。因此Sampled-LUT的内存消耗为(
):
那么接下来我们看看源码是如何创建这个表的,接下来的2.2节介绍创建之后,如何存表。
base = torch.arange(0, 257, 2**SAMPLING_INTERVAL) # [0, 16, 32, ..., 255] 1D感受野
base[-1] -= 1
L = base.size(0) # 17
first = base.cuda().unsqueeze(1).repeat(1, L).reshape(-1) # 17*17 0 0 0... |16 16 16... |...|255 255 255...
second = base.cuda().repeat(L) # 17*17 0 16 32 .. 255|0 16 32 ... 255|...|0 16 32 ... 255
onebytwo = torch.stack([first, second], 1) # [17*17, 2] 2D感受野
third = base.cuda().unsqueeze(1).repeat(1, L*L).reshape(-1) # 17*17*17
onebytwo = onebytwo.repeat(L, 1)
onebythree = torch.cat([third.unsqueeze(1), onebytwo], 1) # [17*17*17, 3] 2D感受野
fourth = base.cuda().unsqueeze(1).repeat(1, L*L*L).reshape(-1) # 17*17*17*17
onebythree = onebythree.repeat(L, 1)
onebyfourth = torch.cat([fourth.unsqueeze(1), onebythree], 1) # [17*17*17*17, 4] 4D感受野
其实也很简单,就是先调用torch.arange(),然后创建相同值组成的数组和以为间隔的像素值数组,通过不断堆叠产生1D、2D、3D、4D感受野下的LUT,为了更直观体现这一过程,我画了一张图来可视化,如下图所示:
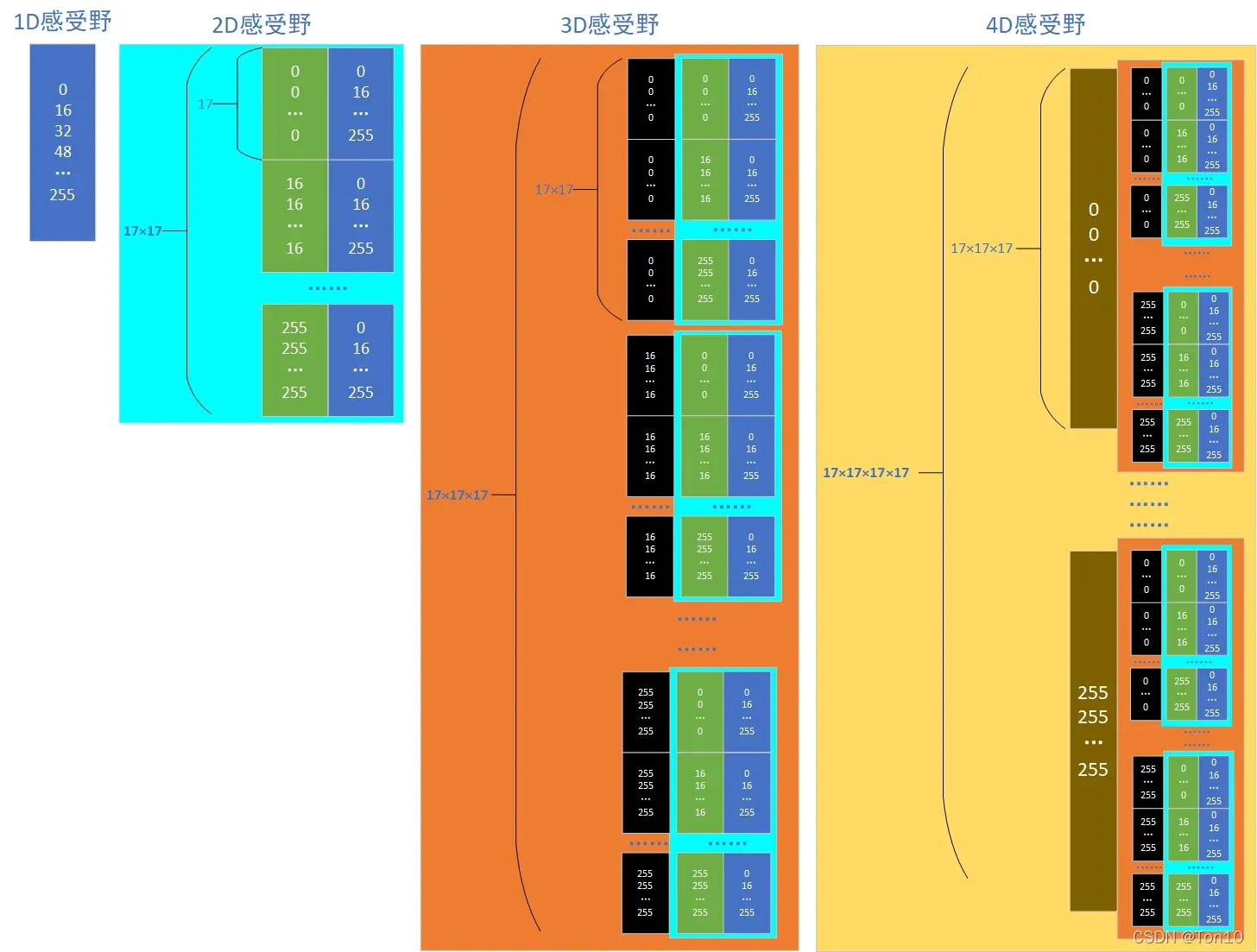
从上图可以看出,我们按顺序列出了像素组合,每种可能性都可以在上图中找到。
2.2 存表过程解析
保存表过程分为三个部分:
- 我们需要将上图reshape成
的图片格式,来表示将83521张size为
- 我们将所有的83521张小图片进行batch=835的划分,然后输入到我们上一节花了一段时间训练好的
SR-LUT网络模型
走到中间,结果就是每张 - 最后将所有batch的输出结果合并并保存起来,这个结果就是我们最终所需要LUT,也就是供给测试用的LUT,它的大小为
,从这个结果可以看出,将每一个
的
对于的每一张小图,经过网络后输出
的
块,其前向如下:
因此,网络的输入输出格式为:
我们将所有batch个堆叠起来存到np.array中,这个数组就是我们的LUT,我们reshape一下格式,故最终的LUT的shape为:
。
3 测试(读表)部分
这部分为了方便讨论,我们只讨论4D感受野(即)下的SR-LUT插值部分,且
。
由于为了节约LUT的存储消耗,作者采用了Sampled-LUT,即缩小图像采样的范围:从一共256个值的全LUT降到以
为采样间隔形成的共17个采样值。这样虽然带来了资源优化,但也使得在测试的时候, 对于
任意一个像素值,可能无法找到相对应的
像素块。因此我们就需要插值来解决这个问题,对于非采样点(即不在17个采样点之中),我们会利用采样点的像素,通过一些插值算法来求得非采样点对应的高分辨率
块。
3.1 插值过程解析
在正式分析之前,我们先处理几个“
- 查找表的一部分
大意
:对于测试集(比如 Set5 )每一张图片,当我遇到了坐标为
处的像素值,我
先遍历一遍以的放大;
同理,遍历每个图像。
- 查表过程的输入是从存表步骤里我们最终获得的sampled-LUT,这个LUT有
行,有
- 关于插值的选用问题,根据论文中的Table 2所示:
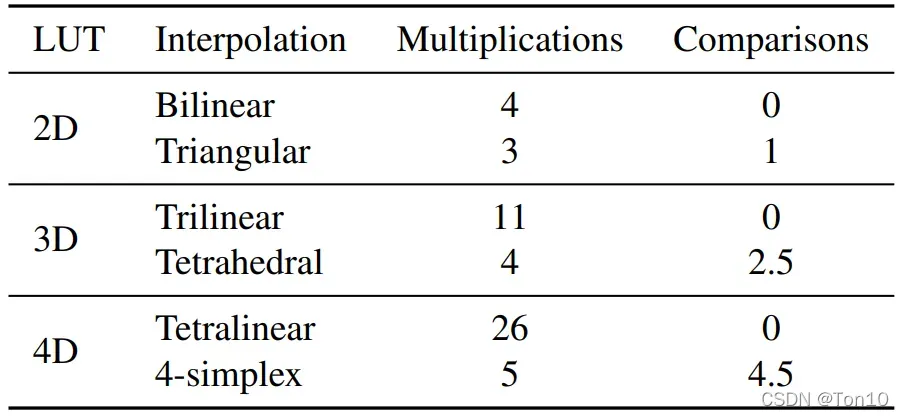
作者在源码中对于2D、3D、4D分别采用了三角插值(三个顶点)、四面体插值(四个顶点)、4-单形插值(需要5个顶点),由于本文只讨论4D的感受野,所以接下来介绍4-simplex插值。 - 关于数据流问题,输入是一整张测试图片,比如 Set5 的第一张就是个小孩子:
 ,这是一张
,这是一张的图片。①我们需要先利用
自我整合
技能,
这里和ESDN做法一样,将self-ensemble用在测试环节提高表现力
,这里和训练部分一样,对每一张图片使用4种自增强旋转操作;
②然后做
pad填充
成,这和SR-LUT模型训练环节是一样的,为的是配合模型在亚像素采样之前保持在
的大小(其他图片也是一样);
③不同于网络前向传输,其次是
单纯形插值
操作(实现
④之后将4种增强的结果进行平均之后就是我们输出的高分辨率图像了。
接下来我们重点分析插值部分,这涉及到三个难点:
- 如何找到
- 如何查找到LUT中对应的
- 单纯形插值的工作原理。
首先是Q1:如何找到一个感受野
让我们看一下源代码:
img_a1 = img_in[:, 0:0+h, 0:0+w] // q
img_b1 = img_in[:, 0:0+h, 1:1+w] // q
img_c1 = img_in[:, 1:1+h, 0:0+w] // q
img_d1 = img_in[:, 1:1+h, 1:1+w] // q
img_in是输入的图像;img_b1、img_c1、img_d1分别是原图img_a1进行平移得到: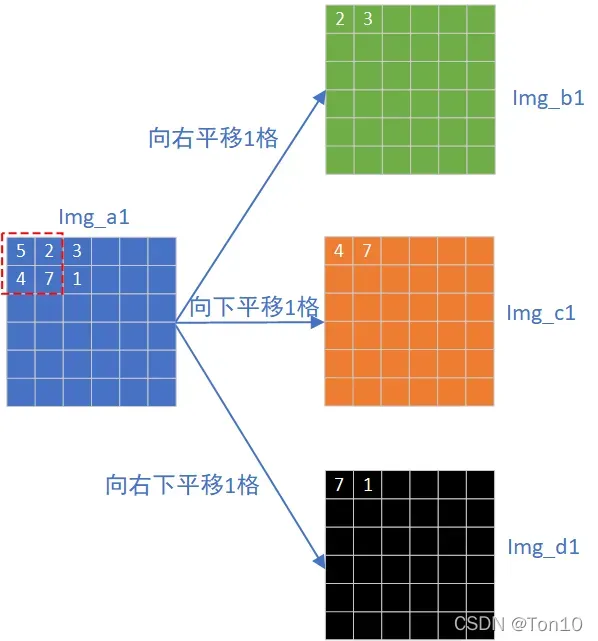
这样做的原因是:
- 我们的LUT是根据输入的一个
- 插值算法中需要知道每一个
鉴于上述原因,我们利用pad的优势得到平移后的3张图像,那么每次只要取4张图像中相同坐标的值,就相当于对原图中一个感受野进行操作了,比如上图中红色虚线框中,我们要对这个框进行查表,只要取出四张表在
处的值(如右边3张图的第0个像素值所示)就行了,因为这就相当于得到了原图中相邻的
像素块。
其次是Q2:如何索引到LUT中的像素块
在测试环节我们拿到的LUT有行,每一行的内容都是经过网络处理过的
像素,那么如何根据输入的
来找到索引,从而
个索引值中取出相应的
块呢?
参照本文2.1节表格构建部分,我们可以通过如下方式取得索引:(设采样间隔且像素都是采样点像素)
对于一张图像中的某一个坐标对,可以通过其余三个平移图像获取
感受野的信息,其对应的LUT索引由输入感受野像素组成:
img_a1[x,y].astype(np.int_)*L*L*L
+ img_b1[x,y].astype(np.int_)*L*L
+ img_c1[x,y].astype(np.int_)*L
+ img_d1[x,y].astype(np.int_) # L=2**(8-4) + 1
简单说明一下,这里每一个像素乘以不同个数的是由像素在
中的位置决定的,因为LUT表中,从左到右的四列经过源码中
input_tensor = onebyfourth.unsqueeze(1).unsqueeze(1).reshape(-1, 1, 2, 2).float() / 255.0
这样的变型之后,会产生一种对应关系:的感受野,左上像素对应于四列中的第0列;右上像素对应于四列中的第1列;左下像素对应于四列中的第2列;右下像素对应于四列中的第3列(这种关系是PyTorch中数组低层存储关系决定的)。因此决定左上像素索引的就是
;决定右上像素像素索引的就是
;决定左下像素索引的就是
;决定右下像素索引的是
。
最后是Q3:单形插值
我们遍历输入图像中每一个像素点,其中
是坐标。对于每一个像素,我们通过插值算法获取其对应的一个
的像素块。遍历完
行
列之后,就获取了
个
块,经过reshape之后,就得到了
的高分辨率图像。
单线插值步骤:
- 提取每个8bits像素的MSB(高4位)和LSB(低4位)。
- 获取顶点(读LUT),对于4D单形插值需要获取5个顶点。
- 获取权值以及找到5个最佳顶点。
- 根据权重和顶点得到最终的插值结果。
下图展示了三角插值的顶点和权重: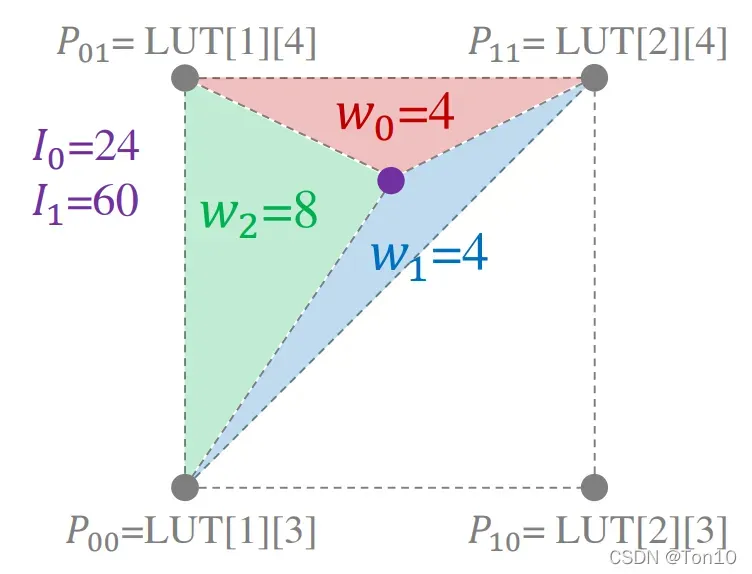
紫点为非采样点,灰点为采样网格点,为权重。
3.1.1 提取MSBs和LSBs
# 获取MSBs
img_a1 = img_in[:, 0:0+h, 0:0+w] // q=W
img_b1 = img_in[:, 0:0+h, 1:1+w] // q
img_c1 = img_in[:, 1:1+h, 0:0+w] // q
img_d1 = img_in[:, 1:1+h, 1:1+w] // q
img_a2 = img_a1 + 1
img_b2 = img_b1 + 1
img_c2 = img_c1 + 1
img_d2 = img_d1 + 1
# 获取LSBs
fa_ = img_in[:, 0:0+h, 0:0+w] % q
fb_ = img_in[:, 0:0+h, 1:1+w] % q
fc_ = img_in[:, 1:1+h, 0:0+w] % q
fd_ = img_in[:, 1:1+h, 1:1+w] % q
Note:
- 对于一个8bits输入数据,前四位取商,后四位取余,相信学过大学C语言课的很熟悉。
- img_a2、img_b2、img_c2、img_d2用于后续求顶点。
3.1.2 查表求顶点

对于一个4D输入,一共由个顶点,但在单形插值中实际只需要5个顶点,至于要哪几个顶点要取决于
中四个像素值LSBs(即步骤一求得的fa_、fb_、fc_、fd_)之间的大小关系。
Note:
- 上图所示就是求16个顶点的源码,规则是如果顶点的下标是二进制0,就采用img_a1、img_b1、img_c1、img_d1;反之为二进制1,就采用img_a1、img_b1、img_c1、img_d1。此外顶点的四位中,从左到右分别代表
- weight就是LUT(np数组),
寻找顶点的过程就是查表的过程。两者是等价的。查表需要 - 顶点就是输入图像中每个点
- 顶点reshape之后的格式为:
。
3.1.3 求权值
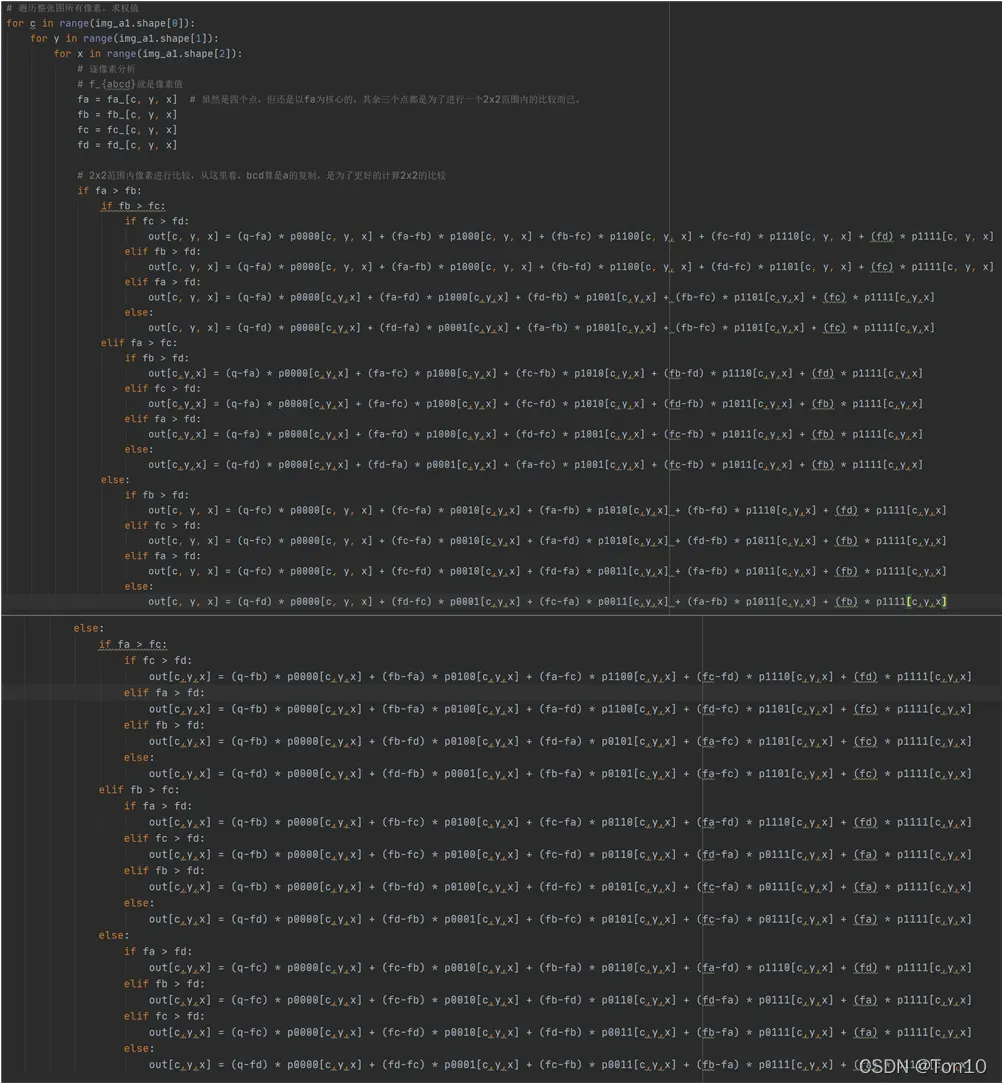
第三步就是求出每个顶点对应的权值,至于权值的大小以及选用哪5个顶点取决于感受野的4个像素值的LSBs,具体实现见上述代码。
Note:
- 最后对于每一个像素
左上像素
.
3.1.4 输出HR图像
根据公式:要得到非采样点对应的高分辨率
块,那么可以对图像的所有像素点使用上式得到整个
图像对应的
图像:
out = np.transpose(out, (0, 1, 3, 2, 4)).reshape((C, H*upscale, img_a1.shape[2]*upscale))
然后进行逆增强就可以输出出去了,一共4次的逆增强求平均之后就是我们最后可以保存下来的缩放倍率的
图像了!!!
文章出处登录后可见!