




title
Cartoon-Stylegan : Fine-Tuning stylegan2 for cartoon face generation
author
Jihye Back
Link
论文地址:here
Code:here


Abstract
最近的研究表明,在无监督图像到图像转换方面取得了显著的成功。然而,由于数据的不平衡,学习各个领域的联合分布仍然具有很大的挑战性。尽管现有模型可以生成逼真的目标图像,但很难保持源图像的结构。另外,在多个领域的大数据上训练生成模型需要大量的时间和计算机资源。为了解决这些限制,我提出了一种新颖的图像到图像转换方法,该方法通过微调 stylegan2 预训练模型来生成目标域的图像。 stylegan2 模型适用于不平衡数据集上的无监督图像到图像翻译;它非常稳定,可以生成逼真的图像,甚至在使用简单的微调技术时可以从有限的数据中正确学习。因此,在这个项目中,我提出了新的方法来保留源图像的结构并在目标域中生成逼真的图像。
背景介绍等
本文通过finetune Stylegan2模型,完成图像到图像的翻译,为了使源图像和目标图像相似,例如制作成对图像,提出了两种方法:
(1)FreezeSG (冻结style向量和generator的初始blocks)。这个很简单,并且可以令目标图像遵循源图像的结构。
(2)Structure Loss(减小源generator和目标generator之间初始block的距离)。在这种loss训练下的模型加入层交换,效果也十分显著。
Method
Baseline : StyleGAN2-ADA + FreezeD
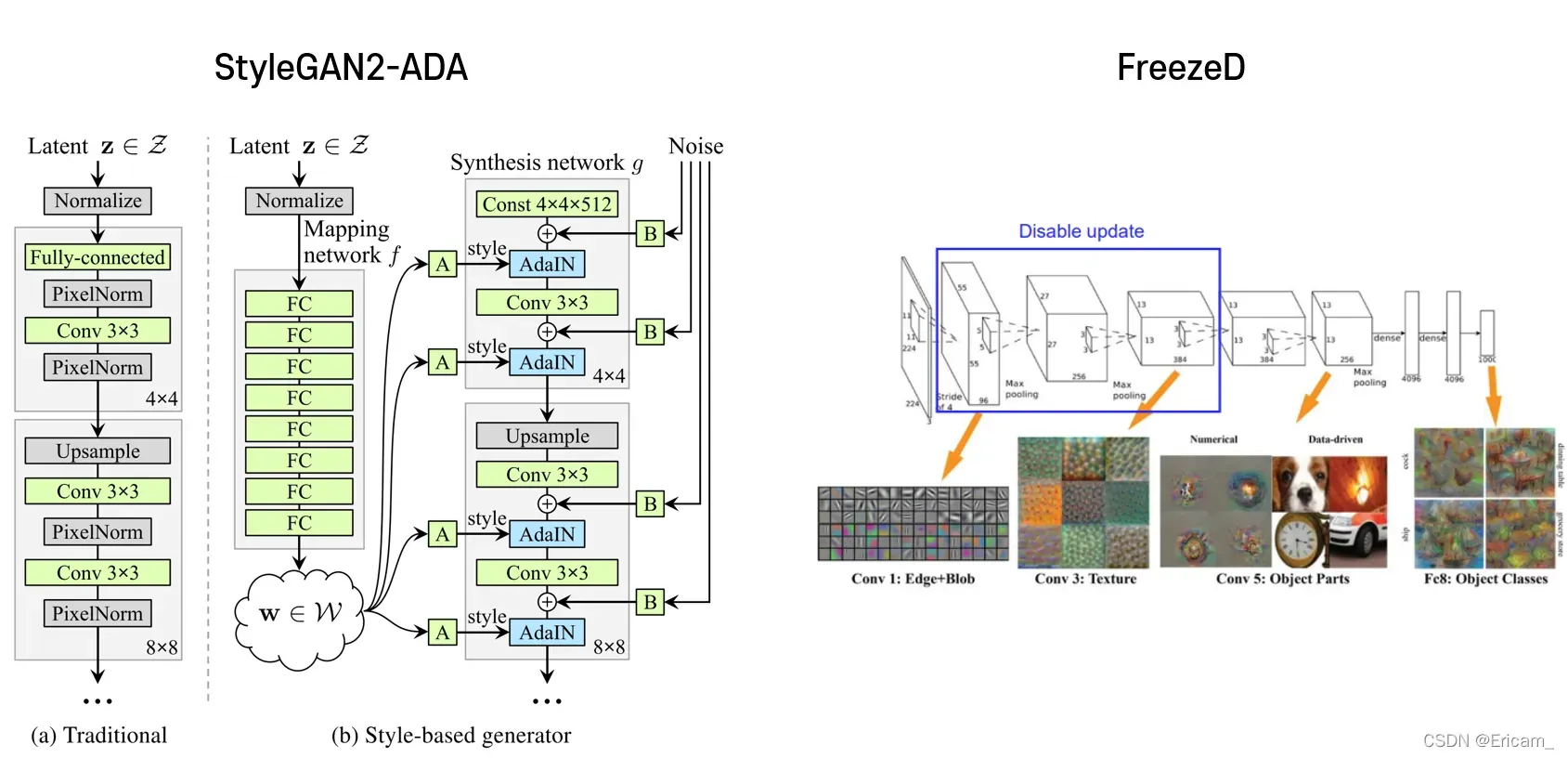

这种结构可以生成逼真的图像,但不能保留源域的结构。
Ours : FreezeSG (Freeze Style vector and Generator)


FreezeG 可以有效地保持源图像的结构。(冻结生成器的参数)
通过各种实验的结果,我发现除了生成器的初始层外,样式向量的初始层对于保留结构也很重要。所以我冻结了生成器和样式向量的低分辨率层。
上图是通过相加style vector不同层,得到的实验结果。在Stylegan2中,style vector为n * 18 * 512,上图可以发现保留4层后,源图的结构也能大致留下。所以这也是作者想要冻结style vector低分辨率层的原因。
Freeze Style vector and Generator
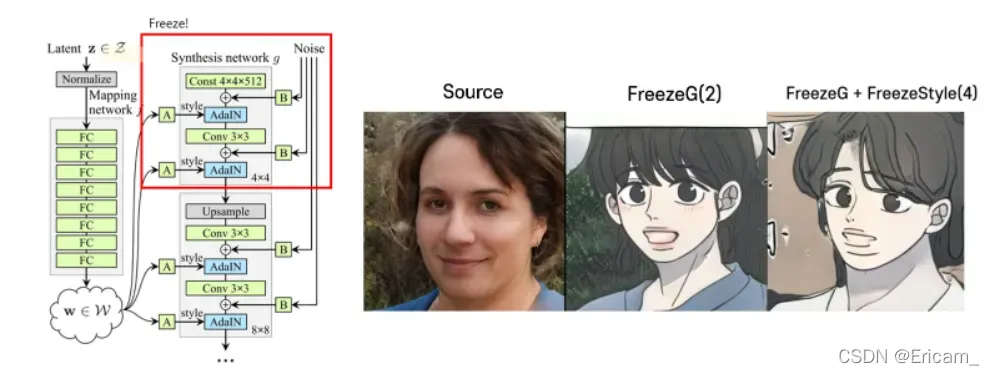

with Layer Swapping
应用 LS 时,FreezeSG 生成的图像与源图像的相似度高于使用 FreezeG 或Baseline(FreezeD + ADA)时的相似度。 然而,由于固定了生成器的低分辨率层的权重,因此在低分辨率层上进行层交换时很难获得有意义的结果。
关于层交换,作者描述的不多,但是是借鉴于https://arxiv.org/abs/2010.05334这篇文章。原文中的介绍如下:
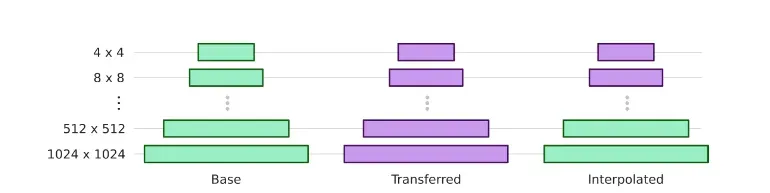



可以理解为,交换原generator和新generator低分辨率层的权重。(但目前存在的疑问在:如果通过其他pretrained模型进行fintune,冻结了低分辨率层,不也是相当于作了层交换…此处存疑)
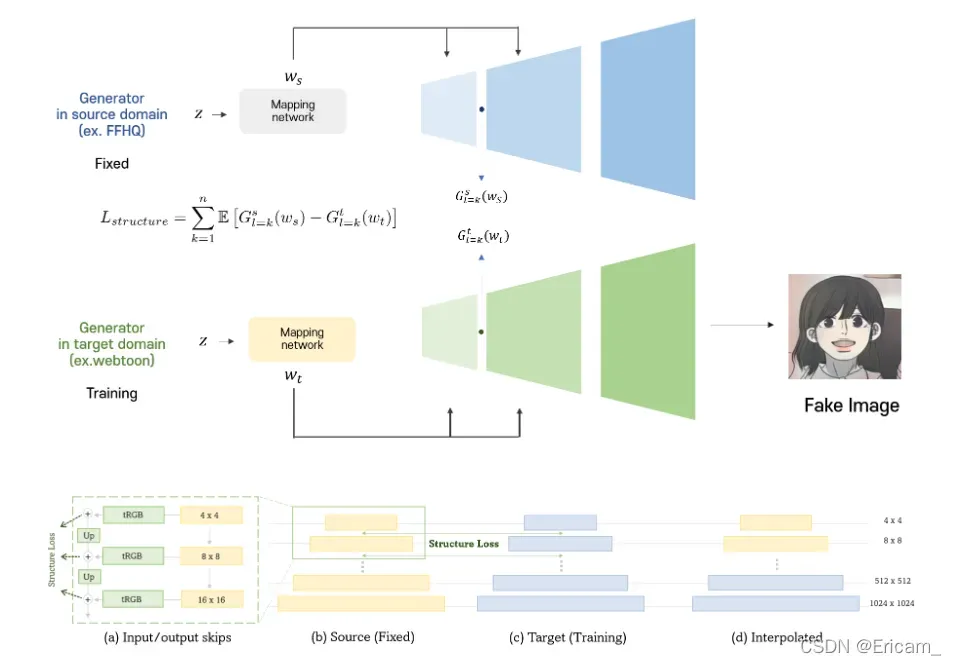
Ours : Structure Loss
由于低分辨率层下优先确定图像结构,我将Structure Loss应用于低分辨率层的值,以便生成的图像与源域中的图像相似。 Structure Loss使得源生成器的 RGB 输出在训练期间被微调到与目标生成器的 RGB 输出具有相似的值。

Results
下面来看一看CartoonGAN生成的效果。




作者还描述了一些利用CartoonGAN做一些应用的表现,比如配合StyleCLIP做人脸编辑,又或者在样式混合阶段的表现,此处就不多描述了。
总结
这篇文章更像是作者的实验笔记,验证了实验过程中记录的经验。
- 作者在前人的基础上,加入了冻结style vector的想法,试验效果良好
- 加入了structure loss,控制新generator生成的图像更贴近源generator生成的图像(更相似)
- 加入了Layer swap(合并其他的项目)

文章出处登录后可见!