



1.概述
对性能变异进行人为的根本原因分析是一件极其耗费时间的事情,因为这要依赖人类专家和数据增长的大小。尽管出现了许多有监督机器学习方法可以自动诊断出HPC系统中的异常,但是它们主要的缺点是:需要人类的操作员理解异常的根本原因以及去标注异常。有监督方法的一个共同缺点就是:需要有大量有标签数据进行训练。在真实环境中却没有很多的有标签的数据。
文章提出了一种半监督的框架Proctor,可以使用少量的、有限的有标签数据对HPC系统进行故障诊断。
2.Proctor框架
说了这么多,Proctor长什么样子呀,直接上图~
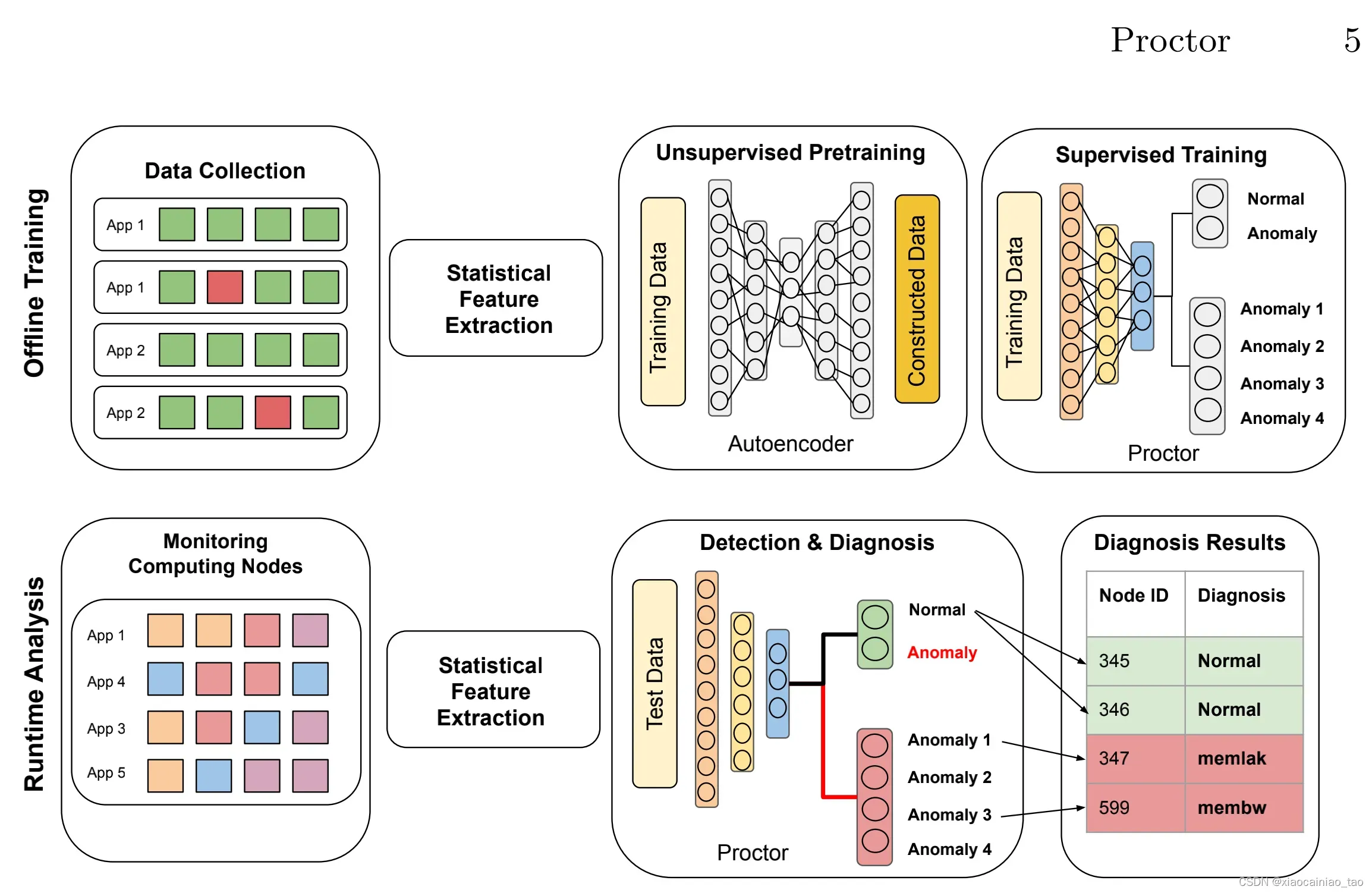
Statistical Feature Extraction:
文章使用Tuncer et al.’s easy-to-compute statistical features [40]将多元时间序列转换成适合proctor的数据格式。Statistical Feature Extraction方法独立于monitoring framework之外。
Unsupervised Pretraining
训练autoencoder提取原始时间序列的特征,让autoencoder以无监督的方式去学习正常样本和异常样本的表示。训练autoencoder的目标是学习X和X‘尽可能相似的权重。
Supervised Training
实施了两种不同的监督训练模型来诊断异常类型并选择表现最佳的一种进行评估。
一种模型是:fine-tuning。冻结预训练中autoencoder中的权重,在encoder之后添加全连接层,重新训练网络对异常的类型进行分类。
第二种模型是:直接将编码特征输入到传统的机器学习模型中,如逻辑回归,RF,SVM。只用编码数据训练有监督模型。
Detection and Diagnosis at Runtime
在运行时,Proctor 有两层分类过程。第一层:Proctor决定一个样本是正常的 还是异常的。如果是异常的样本,将之送到第二层进行诊断,查出故障类型。(个人感觉这就是一个多分类,不过这里分了两步进行多分类,可能这样做有助于提高效率)
3.实验
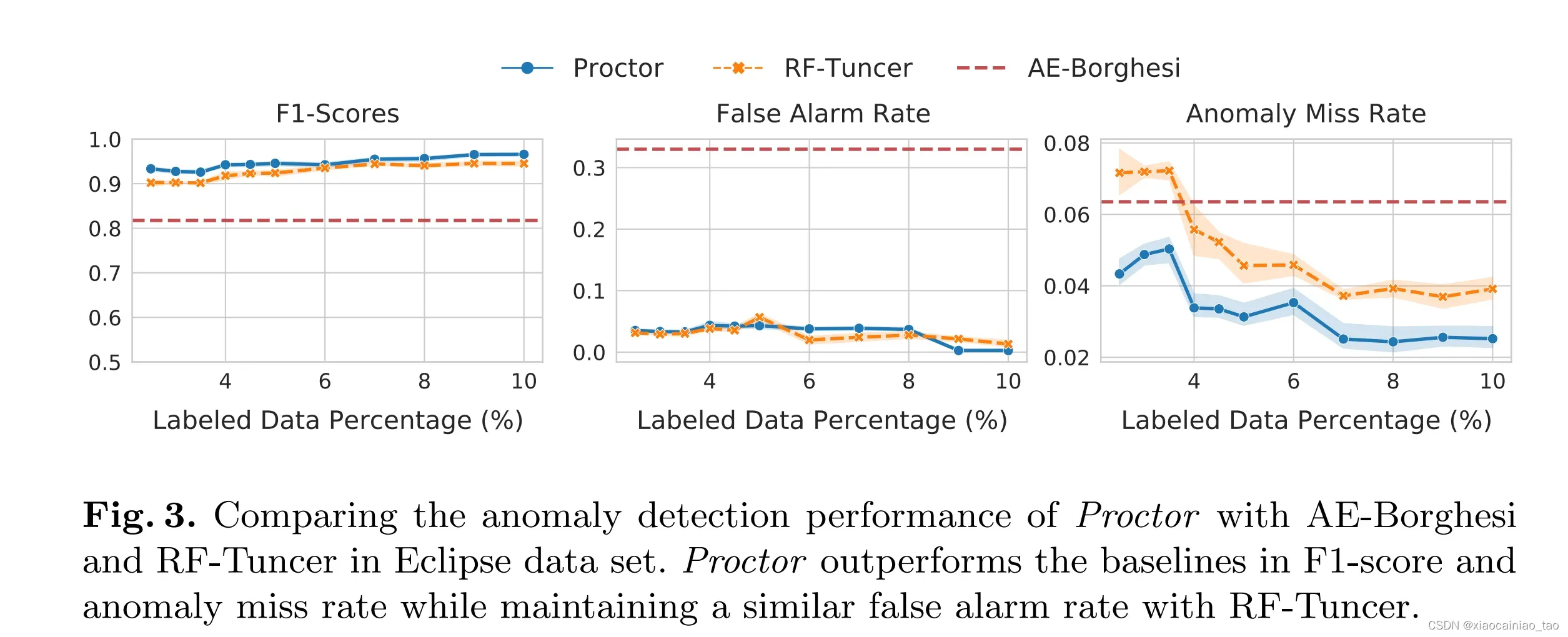
两个baselines:
First:Tuncer 等人提出的框架也被称为RF-Tuncer[41],使用了statistical feature extraction和特征选择策略,将这些与RF分类器相结合去诊断异常的类型。
Second:Borghesi等人提出的基于自编码器的异常检测方法(也被爱称为AE-Borghesi),只用正常样本训练自编码器,根据数理统计的阈值来检测异常。在运行时,当一个样本的重构误差高于阈值,则被认为是异常。
本文提出的Proctor,看上图,个人感觉其实就是把人家First baseline 和 Second baseline的想法结合有扩展了一下下~
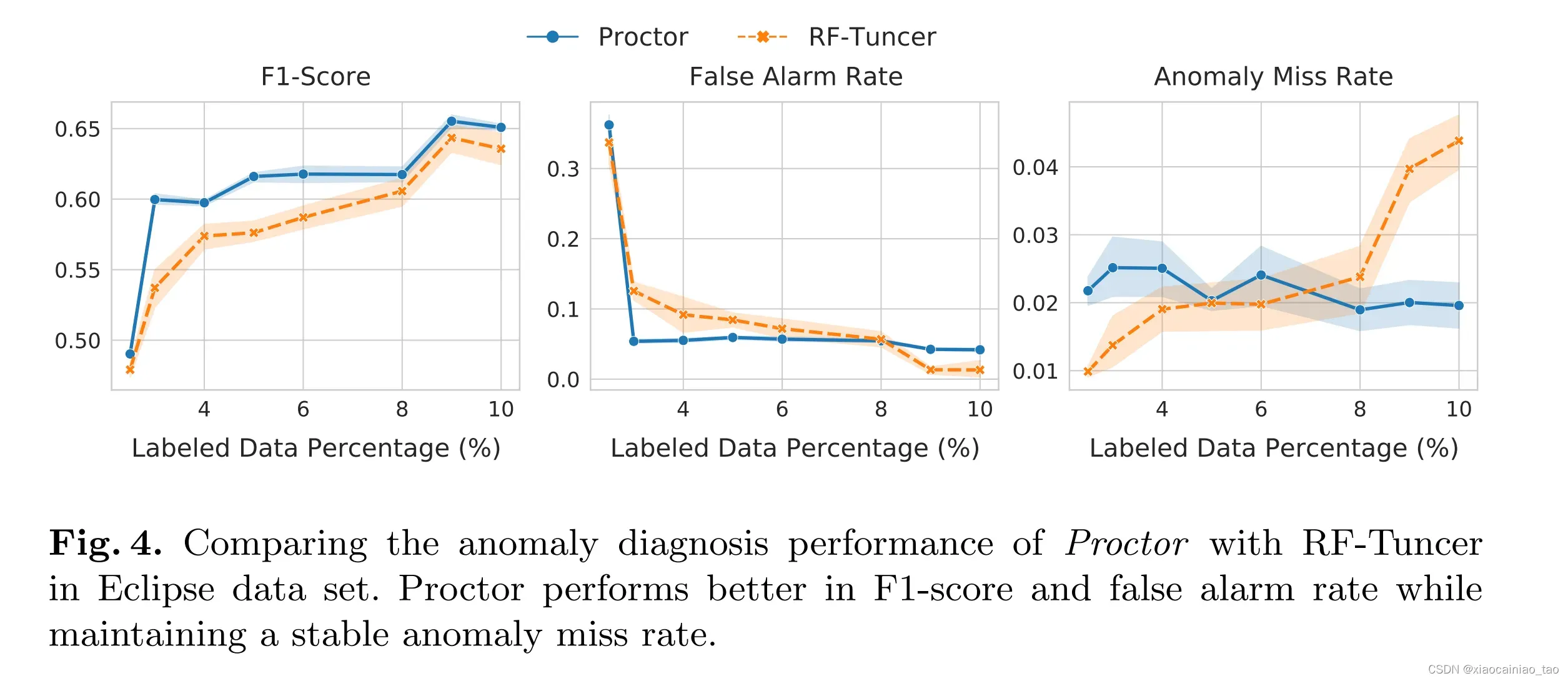
评测结果直接看图片。


4.结语
这只是我的简单理解,如果有什么不对的地方请指教~
这是文章中的两个参考文献,两个baseline
40. Tuncer, O., Ates, E., Zhang, Y., et al.: Diagnosing performance variations in hpc
applications using machine learning. In: Intl. Supercomputing Conference. pp. 355–
373. Springer (2017)
41. Tuncer, O., Ates, E., Zhang, Y., et al.: Online diagnosis of performance varia
tion in hpc systems using machine learning. IEEE Transactions on Parallel and
Distributed Systems 30(4), 883–896 (2018)
文章出处登录后可见!