



本文章主要介绍如何使用Darknet在windows下训练自己的数据集,其中模型使用的是yolov4-tiny,数据集使用的是自己垃圾分类数据集(需要的自取:在我上传的资源中有)
PS:这是我的第一篇博客,如果不足之处请多多指正,谢谢!
知识概要:
YOLO是什么?
目标检测算法主要是由卷积层+全连接层组成
卷积层是由卷积神经网络构成,作用是对图片进行特征提取
全连接层是由目标检测特有的网络构成,如yolo系列使用的就是yolo算法来实现全连接层
值得注意的是,yolo系列的目标检测可以将卷积层进行替换其他卷积网络以实现不同的效果。yolo原作者使用的卷积层就叫Darknet。
YOLO-TINY是什么?
对于yolo大家应该很熟悉了。那么为什么要加上一个tiny后缀呢?
主要是由于深度学习的算法研究的最终目的是为了解决社会中的问题,但是由于yolo等一系列模型算法的参数太大,即使识别效果十分好但一旦部署到移动端或是嵌入式设备中进行工业的运用的话,由于硬件资源限制,导致运行速度十分缓慢甚至无法运行。所以业界为解决这一问题研究出了tiny系列的算法(仅针对于yolo模型而言,其他模型不一定是以tiny来表示轻量级优化),对yolo系列进行了轻量级的优化,在模型参数下降2/3的前提下,只降低了10%以内的准确度。
甚至不止2/3。。。。。。。。。
ok,废话不多说,我们直接进入主题。
Darknet在Windows下的安装:
这一步内容比较多,如果要详细讲的话还需要再写一篇博客。
附上yolov4官方github网站链接 和 一个b站教学视频链接,如果英文好的小伙伴可以直接看GitHub的说明进行安装,稍差的跟着up安装就可以啦。
在windows下进行Darknet安装的b站教学视频
yolov4官方GitHub
如何训练?
第一步:收集数据
1.通过爬虫收集数据集,但是要进行人工清理
2.网上寻找资源,推荐网站:和鲸社区、AI studio社区
3.自己制作数据集
ps:对于不同的深度学习框架和模型算法,需要的数据集格式也不尽相同。
本文采用的是VOC格式数据集,是适用于Darknet训练的
第二步:制作数据集
VOC格式的数据集共有三个文件夹![]()




数据集的标注,可以使用labelimg软件进行标注。
通过cmd进入命令提示界面,输入:


pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple进行下载,pip是python的包管理器,所以前提是要安装好python(推荐python3.7版本,比较稳定) 这里的-i https://pypi.tuna.tsinghua.edu.cn/simple表明让pip在国内的清华源资源内部进行下载
下载速度会快很多。
下载好之后,在命令提示界面输入labelimg即可打开。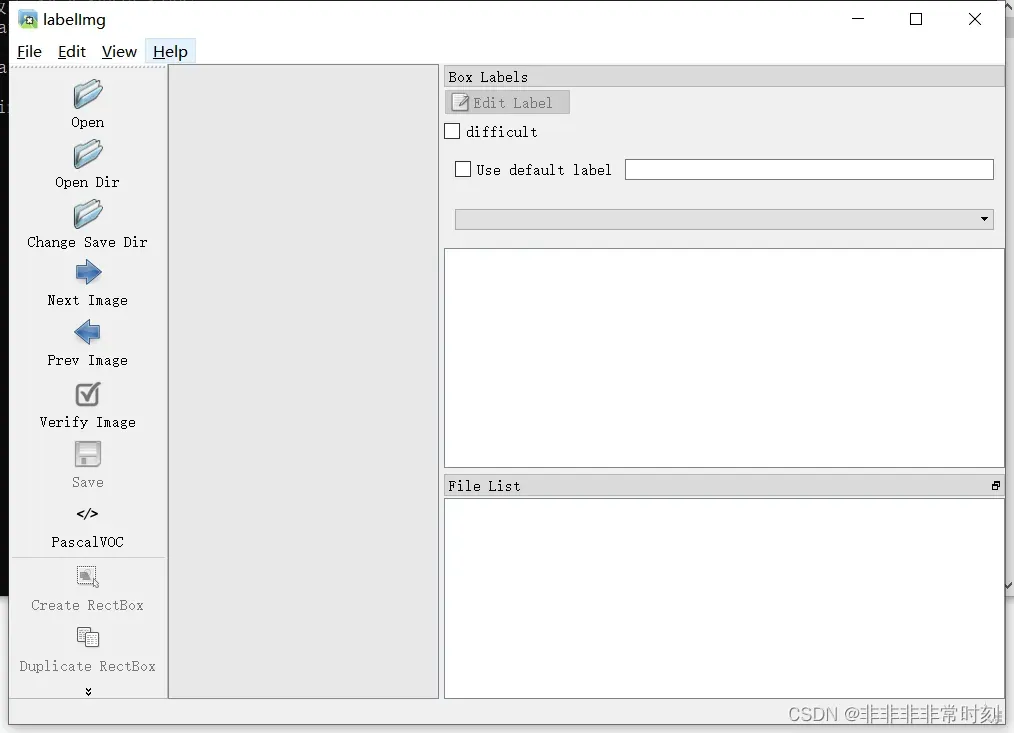


两个文件都选好之后
如果标注量十分大。可以勾选Use default label,并输入标签即可自动确认标签名称。
接下来就可以进行枯燥且乏味的标注过程了 QAQ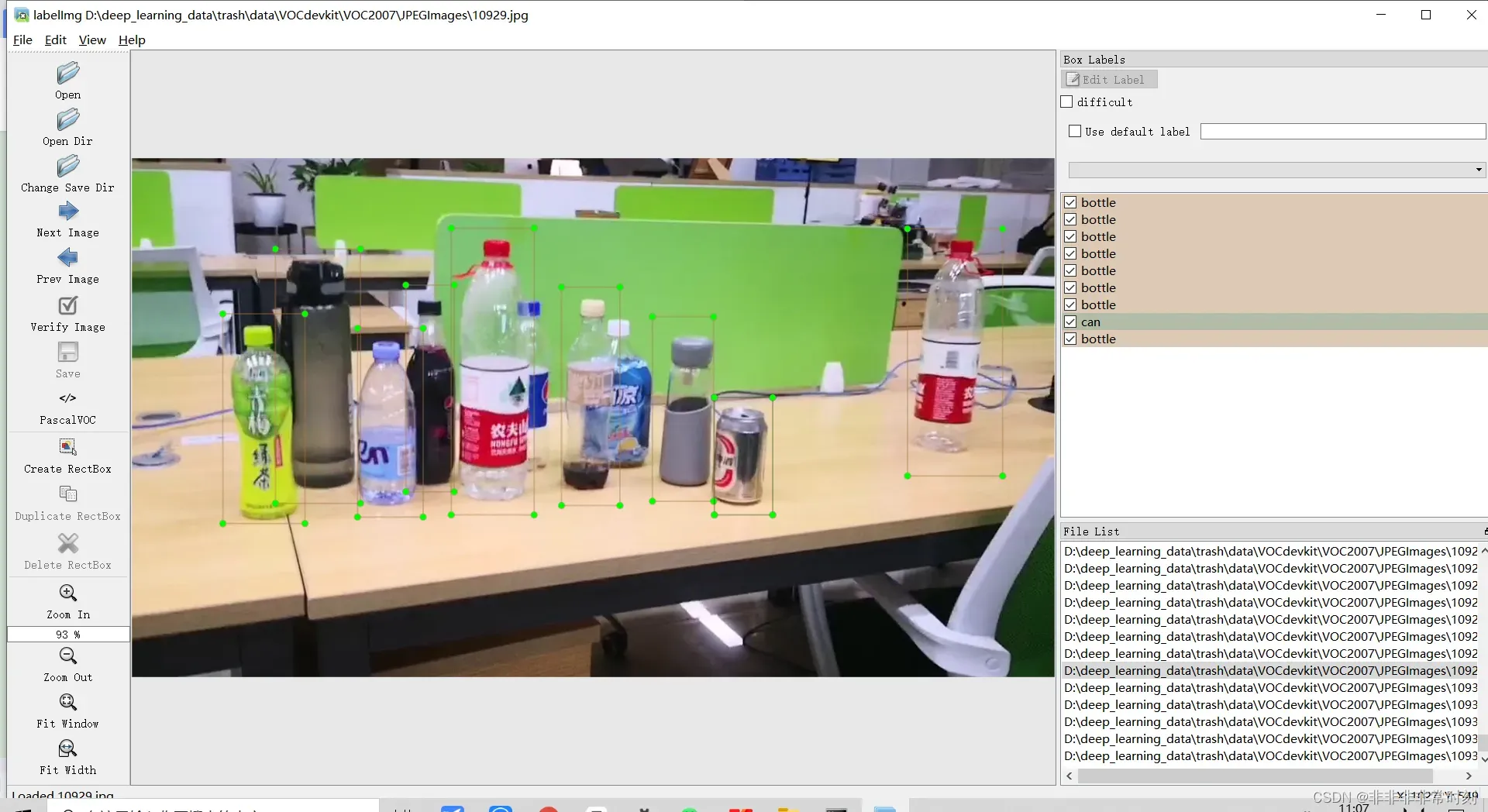



第三步:转换数据集格式
在数据集标注完之后,会得到JPEGImages文件夹和Annotations文件夹,此时还要创建
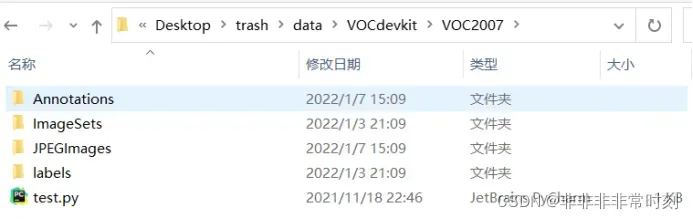
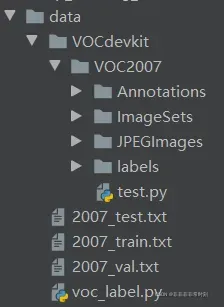
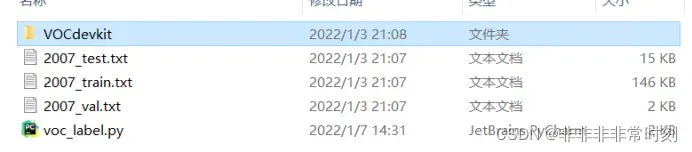
其中除了Annotations、JPEGImages、ImageSets、VOC2007、VOCdevkit以外都是Darknet自带的或通过代码自动生成的
进入darknet文件夹的build中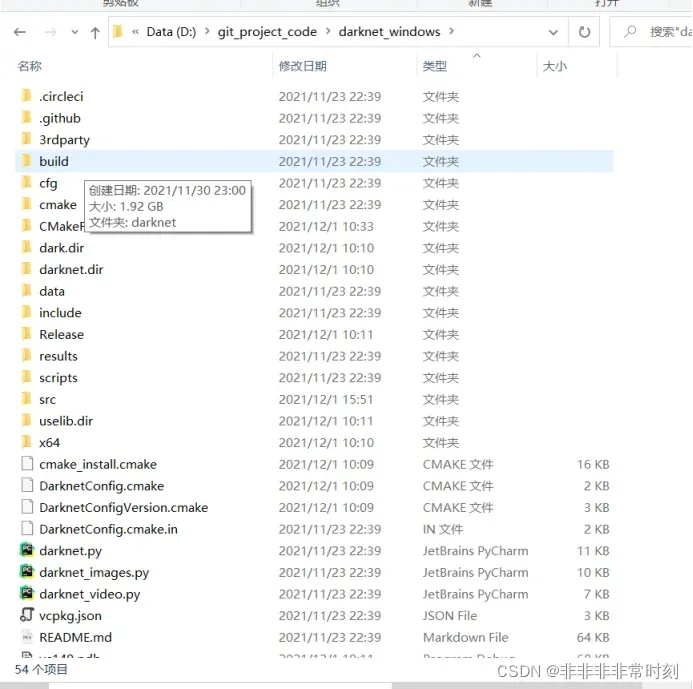
进入darknet
进入x64
进入data
将VOCdevkit文件放进data中
首先运行VOC2007目录下的test.py文件(不需要修改),将数据集分成,测试、验证、训练三类
test.py完整代码(Darknet里自带)








import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()然后编辑data目录下的voc_label.py文件
sets=[ ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["can","pen","box","mask","battery","medicine","paper","bottle"]将classes中改成自己的标签种类,(注意,顺序要和.names文件(后面再提)中的顺序一致),将darknet原本有的sets修改成上图所示的值。
voc_label.py完整代码
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[ ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["can","pen","box","mask","battery","medicine","paper","bottle"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id),'rb')
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
再运行voc_label.py(如果数据集大的话要等比较久时间)运行过程中,如果有报错,有可能是数据集的命名出错了,需要从0开始,一个不漏的增加数字,xml文件同理。也有可能是图片出错了,图片不能是以gif动态图帧的形式存在。
第四步:准备训练配置文件
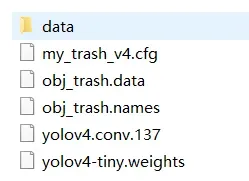
.cfg文件
.cfg文件是算法配置文件(一般darknet的cfg文件夹下自带许多热门配置文件,也可以自己设计或者下载没有的配置文件),里面需要修改以下参数

【net】一栏是可以修改的超参数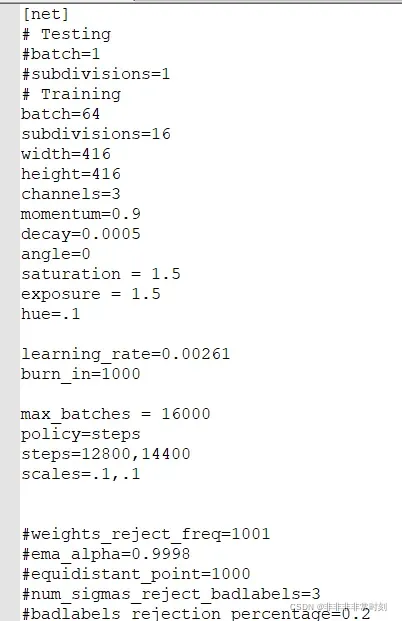
batch为一次可训练的图片数量
subdivision是分割一次训练数量的值(使用该参数可以让显卡较差的电脑也能够使用高batch进行训练)。其两者的关系就是batch÷subdivision=实际上一次训练图片数量
width和height是输入图片的尺寸,这个无需改变,只要是16的倍数即可
max_batches是总共训练的轮数(官方推荐是:种类量*2000,但最少6000。即如果你训练一个种类。则填6000,若训练4个种类则填8000)
steps的值设置为0.6*max_batches和0.8*max_batches即可
其他无需修改

【convolutional】一栏是算法的配置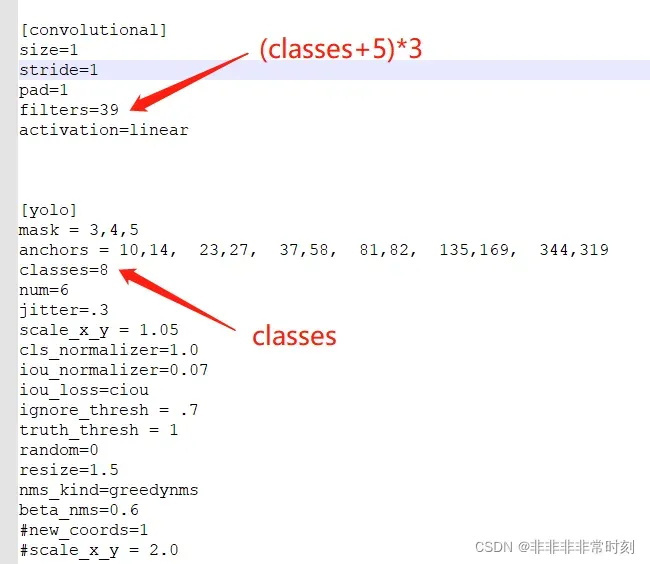
主要修改,如上图所示的【convolutional】和【yolo】组(在yolo-tiny算法中共两组,yolo算法中三组)
修改filters为:(种类数+5)*3,即种类数8,(8+5)*3=39
修改classes为种类数

.data文件
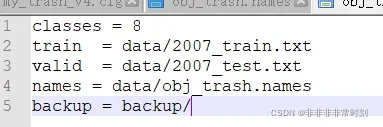

编辑为以上格式的代码
2007_train.txt和2007_test.txt在执行test.py和voc_label.py后会自动生成
backup是训练生成的模型存放地址
classes是数据集有的种类数量
names等等介绍(见下)
.names文件
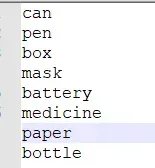
为以上代码,可根据自己数据集种类更改

预训练权重文件和权重文件
conv.xx文件和.weights文件是预训练权重文件
可以在yolo官方github上找到,两者有一即可(要根据自己cfg文件找)
文件制作完后,将.cfg和.data文件放到cfg文件夹下,.names文件放到data文件夹下,.weights或conv.xx文件放到x64文件夹下即可
至此,数据集的配置基本结束!!!!
接下来进行激动人心的训练过程啦![]()
在x64目录下输入cmd


darknet.exe detector train cfg/obj_trash.data cfg/my_trash_v4.cfg my_trash_v4_final.weights即可开始训练(注意,最后一项my_trash_v4_final.weights要放在x64目录下)

训练过程大概需要5~6个小时(根据数据集量的大小和训练次数而定)本文训练的是1w张数据,迭代了1.6w次,速度还是很快滴,前提是用GPU训练。
训练结束后会在backup文件夹下(根据.data中的设置)生成若干个.weight权重文件和一张训练曲线图

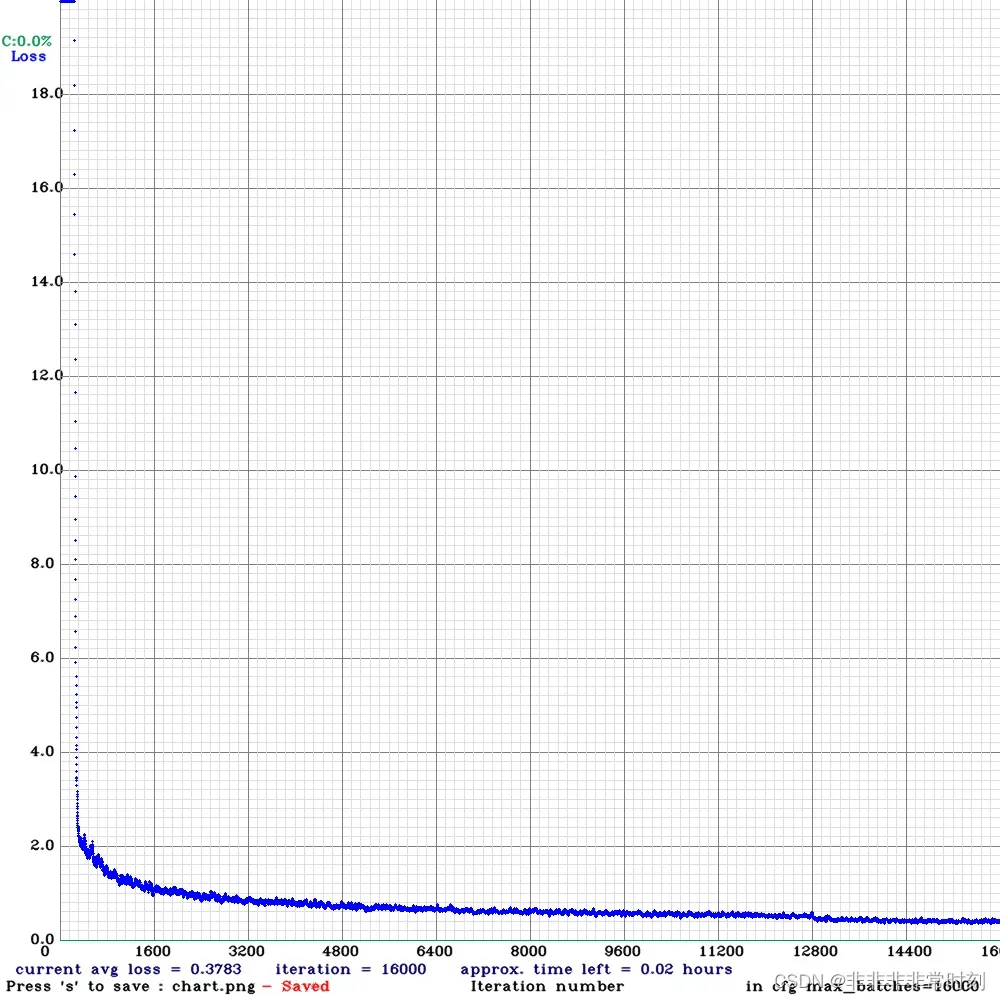

可以看到效果还是可以的
如何使用?
和训练同样,在x64目录下输入cmd进入命令提示界面
进行实时检测的话,输入
darknet.exe detector demo cfg/obj_trash.data cfg/my_trash_v4.cfg my_trash_v4_final.weights -c 0detector表示进行目标检测
demo表示实时监测
第三个参数是.data的相对地址
第四个参数是.cfg的相对地址
第五个参数是.weights的相对地址
-c 0 表示使用摄像头0号
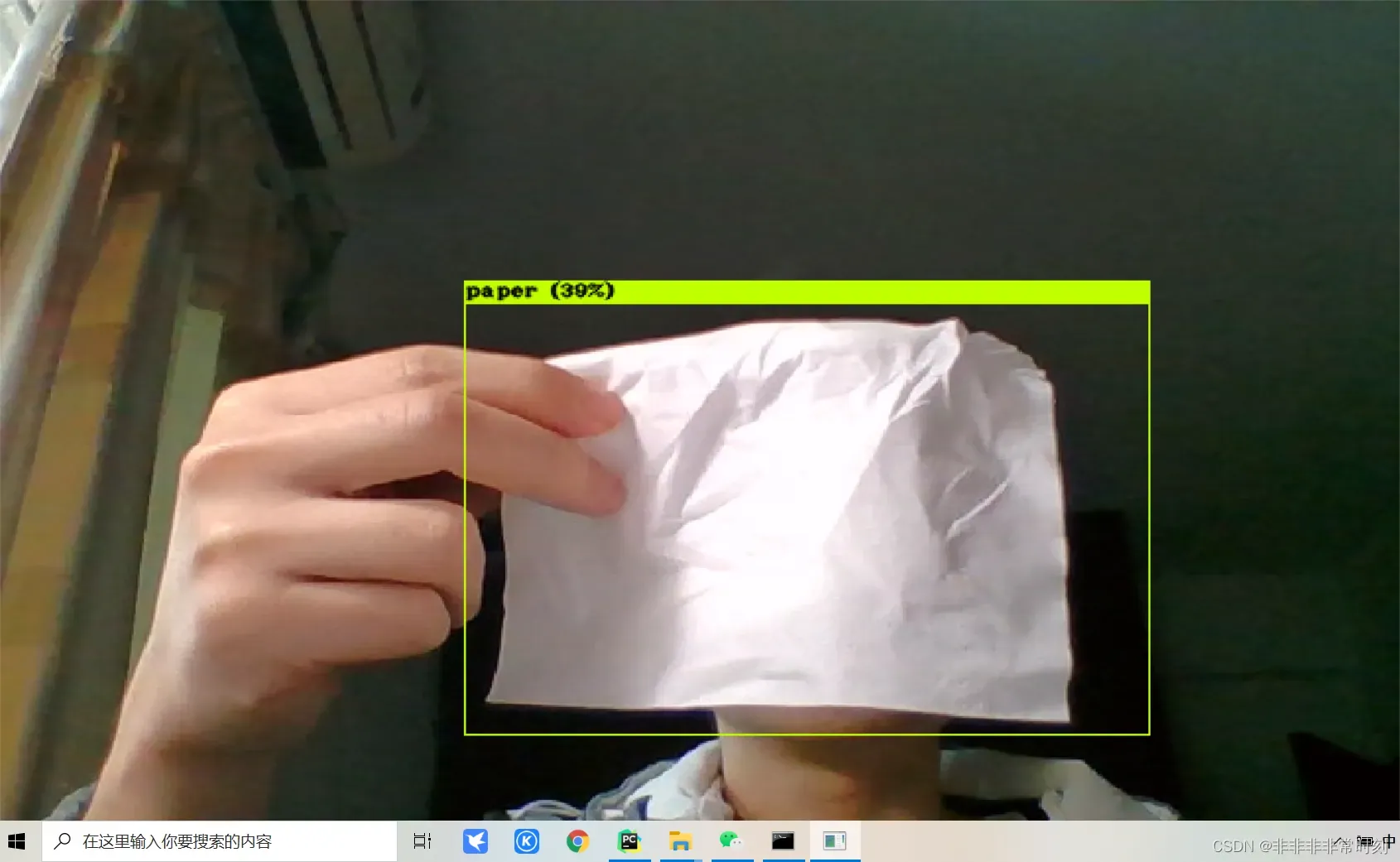


进行单张图片检测的话,输入
darknet.exe detector test cfg/obj_trash.data cfg/my_trash_v4.cfg my_trash_v4_final.weights bottle.webp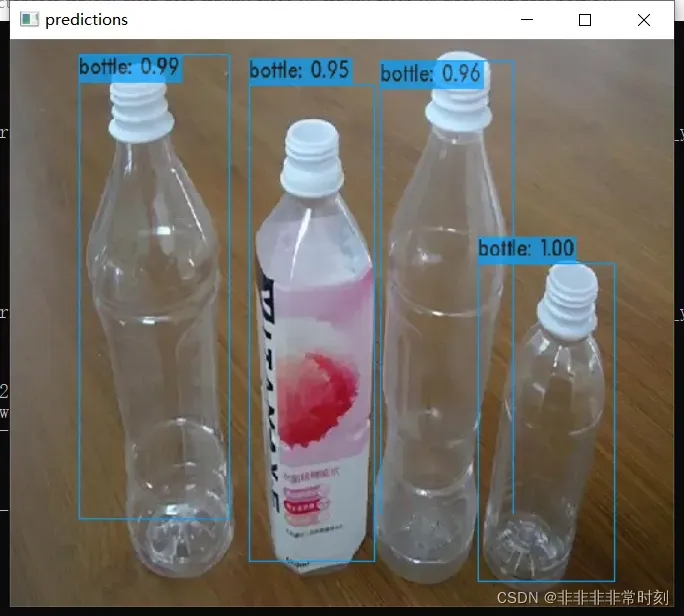

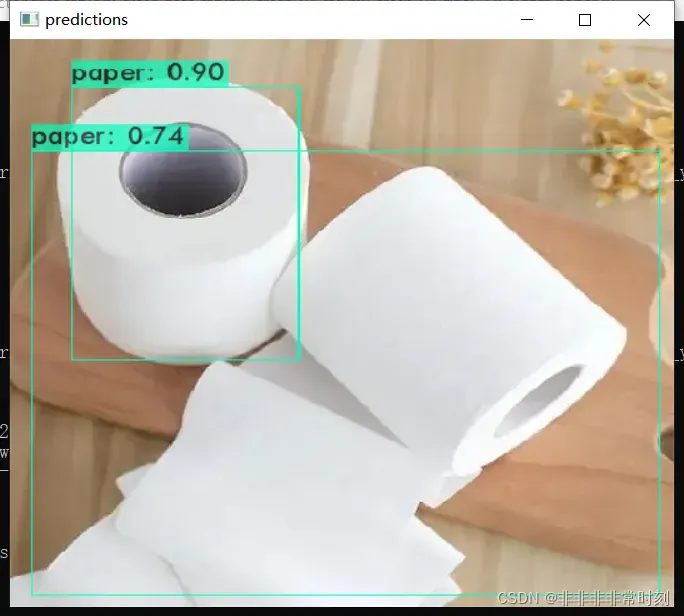
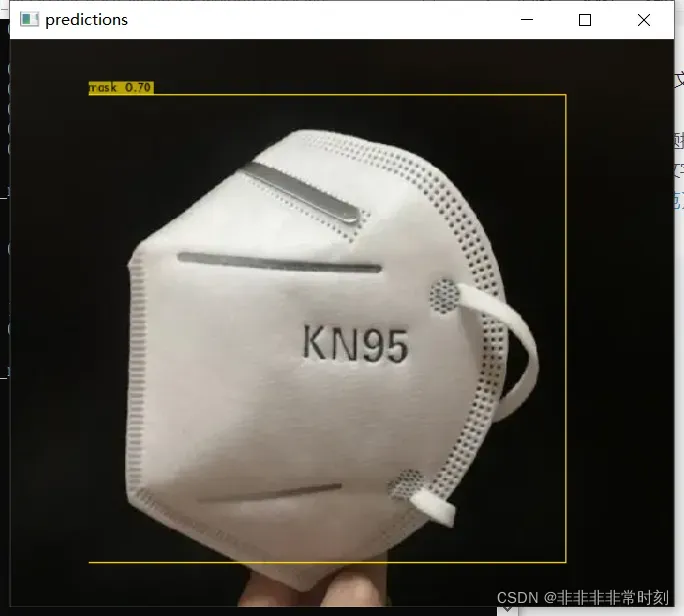
效果还是可以的。
OK,本文的Darknet训练自己的数据集介绍到这就结束了,喜欢本文且觉得对你有帮助的可以点个赞或收藏支持一下,感谢啦!
本文所用到的数据集我上传到CSDN了,需要的自取哈!
版权声明:本文为博主非非非非常时刻原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_52939176/article/details/122554179