像这样的模型网络都是通过线性层串联连接的,称为全连接层,其中上一层的输出参与下一层的输入。可以看出这样的网络只适合处理线性问题,不适合处理图像问题
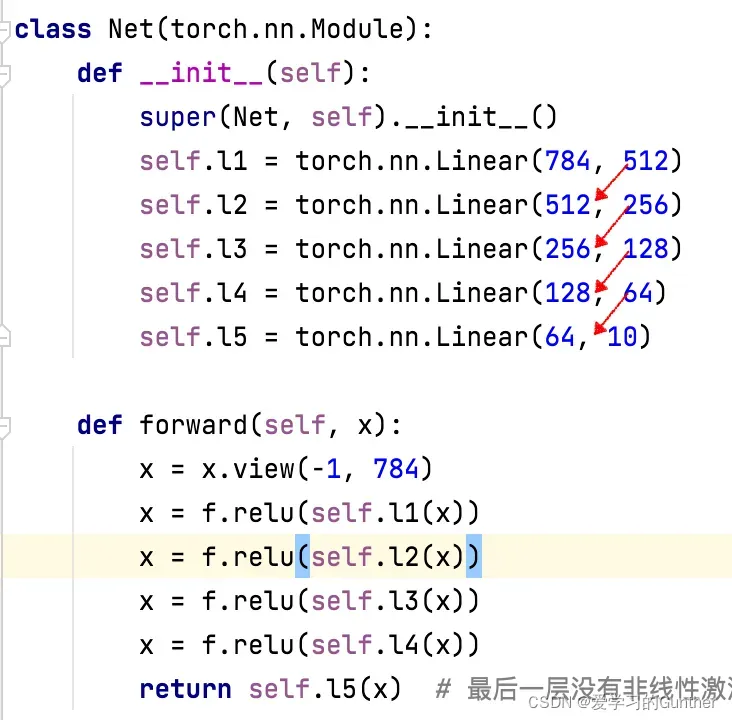
如果使用全连接神经网络处理大规模图像,存在三个明显的缺点:
- 先将图像展开成向量会丢失空间信息;
- 其次,参数过多,效率低下,难以训练;
- 同时大量的参数会很快导致网络过拟合
使用卷积神经网络可以很好的解决这三个问题
CNN卷积神经
与常规神经网络不同,卷积神经网络的各层中的神经元是3维排列的:宽度、高度和深度(维度)。其中的宽度和高度是很好理解的,因为本身卷积就是一个二维模板,但是在卷积神经网络中的深度指的是激活数据体的第三个维度,而不是整个网络的深度,整个网络的深度指的是网络的层数。举个例子来理解什么是宽度,高度和深度,假如做一个猫狗图像识别,使用这个小猫图像作为卷积神经网络的输入

一张栅格化的RGB图片是有红,绿,蓝三个底色组成的
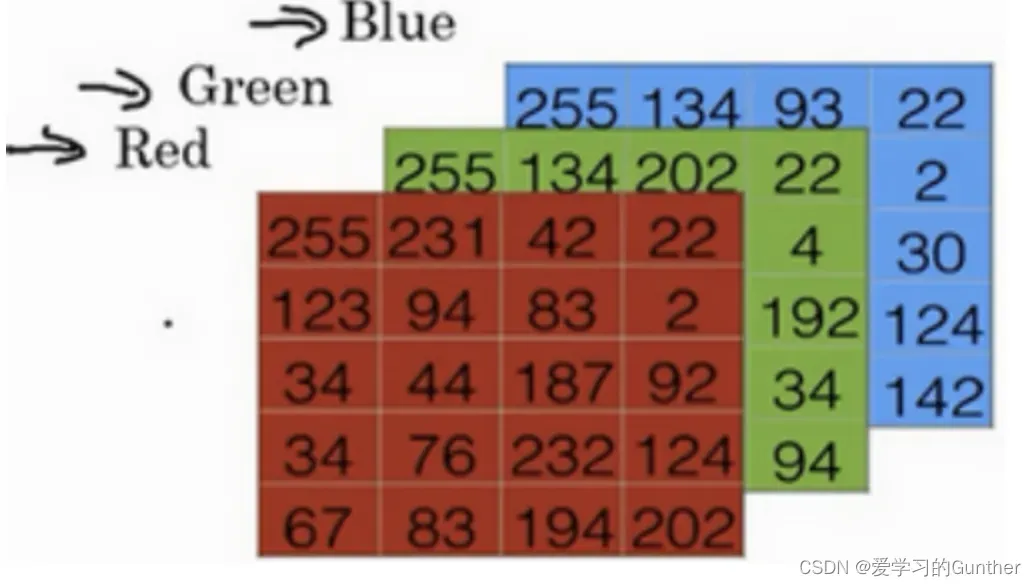
需要保存红,绿,蓝三个颜色通道,所以一张RGB图片由三个序列组成,如果图片尺寸为64*64,那么就会有3个规模为64*64的矩阵,该输入数据体的维度就会是64*64*3(宽度,高度和深度(维度))。我们将看到,层中的神经元将只与前一层中的一小块区域连接,而不是采取全连接方式。对于用来分类猫狗数据集中的图像的卷积网络,其最后的输出层的维度是1*1*2,因为在卷积神经网络结构的最后部分将会把全尺寸的图像压缩为包含分类评分的一个向量,向量是在深度方向排列的。
构建卷积神经网络的各个层
卷积神经网络主要由这些类型的层组成:输入层、卷积层、激活层、池化层,最后是全连接层。通过将这些层叠加起来,就可以构建一个完整的卷积神经网络,所以卷积层也需要经过卷积操作之后的激活函数。在我看来,卷积层和池化层操作是一种特征提取器,浓缩特征,放大有用特征,减少数据杂质,减少数据量,减少操作的需要。
卷积层CONV
卷积层的作用:经过卷积层后,仍然保留了图像的空间特征和空间结构,但是数据量会减少。通过卷积层数据,仍然会得到一个三维张量,但深度(维度)、高度和宽度会发生变化。
构建卷积层时要记住的事情是:
第一点要明确输入数据的维度,输出矩阵的维度,卷积核的维度要和输入矩阵的维度一致
第二点,想要卷积神经网络正常运行,要注意每一层之间张量变化的选择
卷积核:
卷积核一般是一个N*N的方阵组成的,它的作用是和矩阵做数乘,得到一个新的矩阵
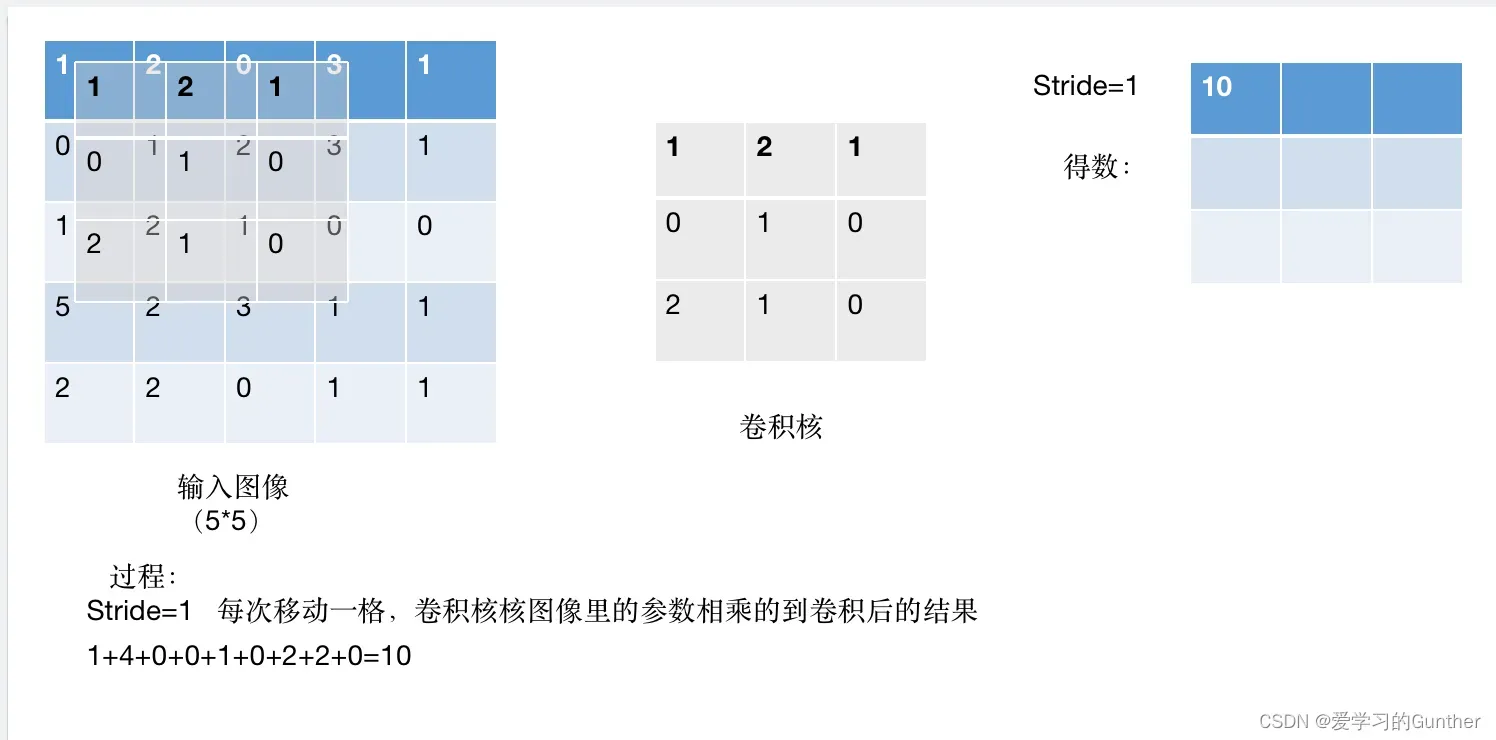
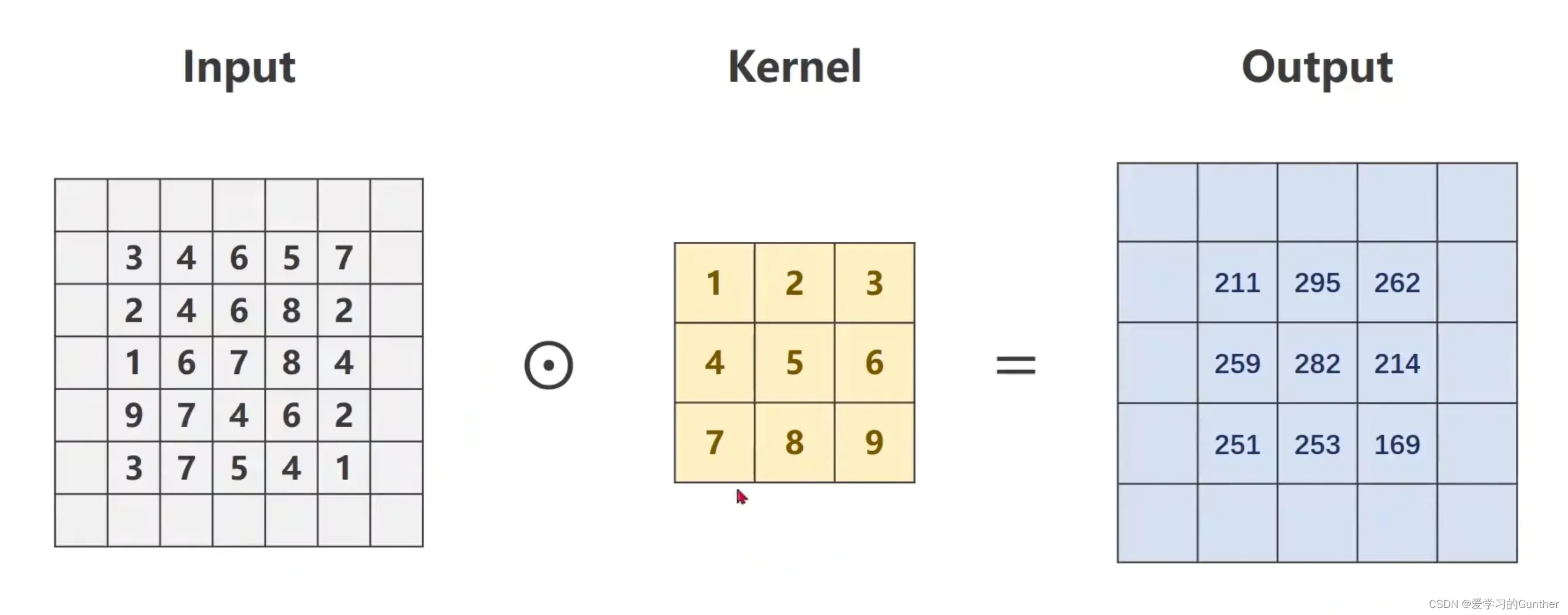
卷积实现过程:
输入的数据是5*5*1,卷积和是3*3的数据,stride(移动的步长为1)=1卷积核在从左上角开始做数乘,依次往右移动做数乘,达到边界自动往下降一层,直至最后一个数,下面是过程演示:
第一的
第二招:
第三招:
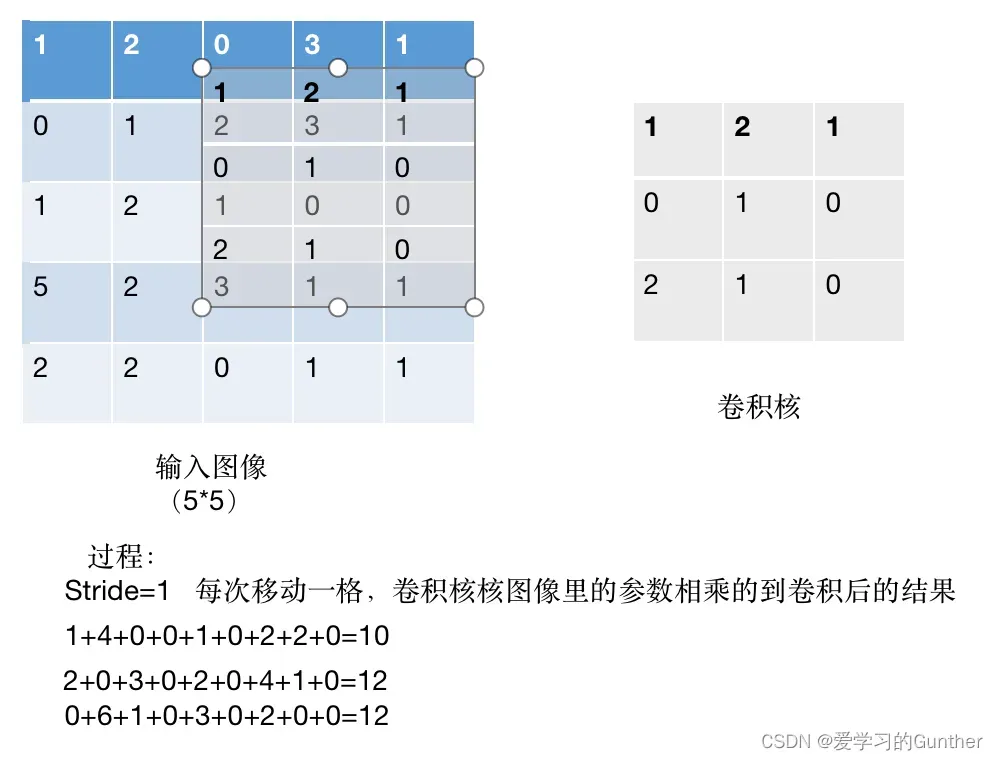
第四步
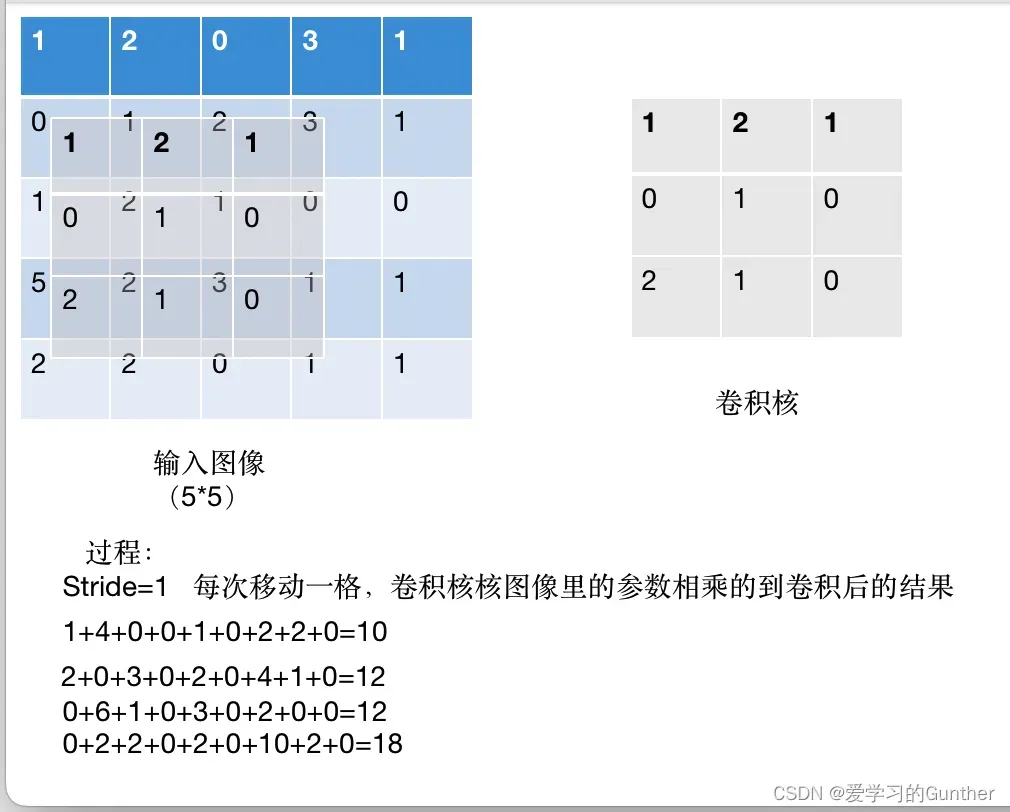
移动的次数取决于图像中卷积核的比例,
最后结果:
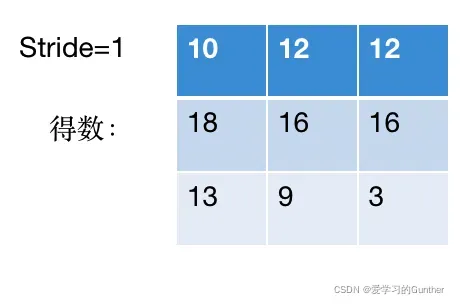
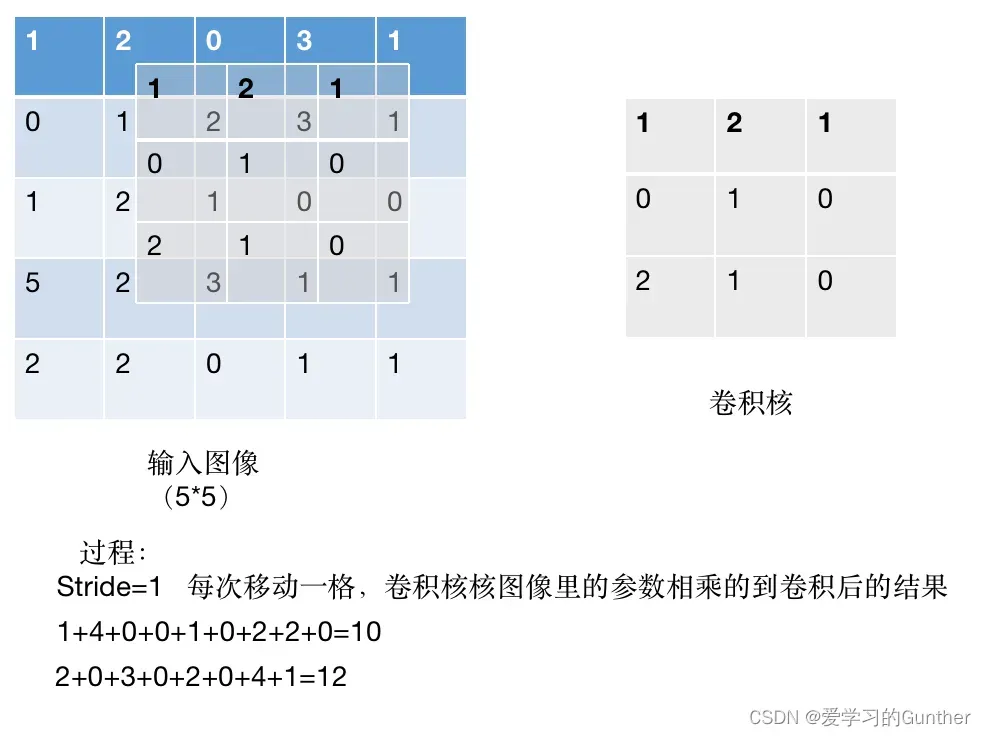
上面的演示只是一个一维矩阵
多维计算:
如果是多维(多通道)矩阵,那么矩阵的每一维都必须乘以一个卷积核,然后将每一维的卷积结果矩阵逐位相加。
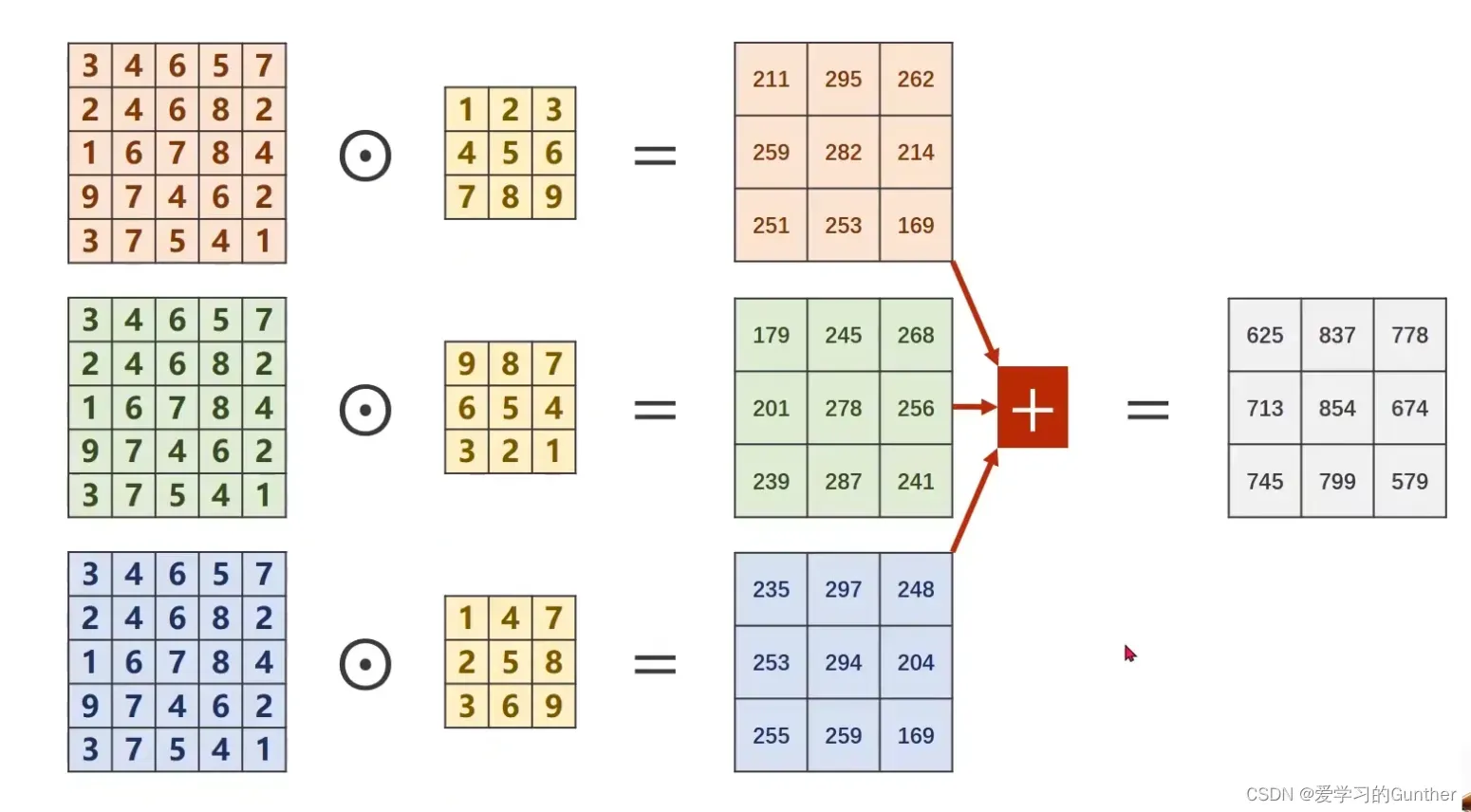
按位加法,因为它的空间结构被保留
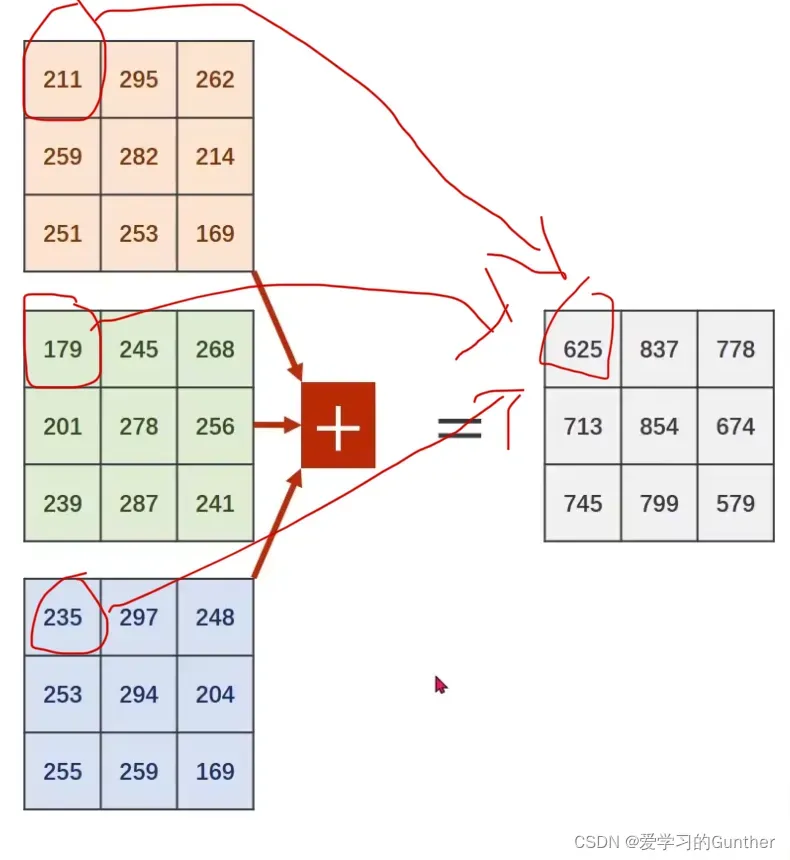
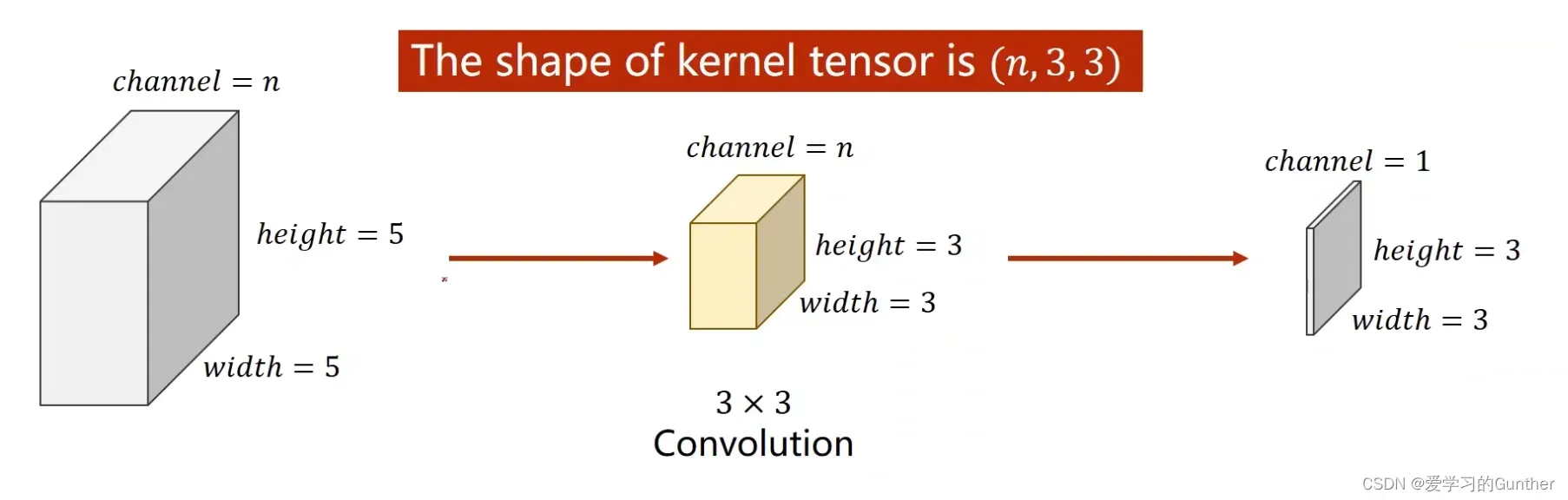 输入矩阵的维度为n,卷积核的维度也要是n,但是最后输出的矩阵是一维的。如果想输出m维的矩阵,那就要和m的卷积核和做运算,最后输出的结果按顺序排列起来就得到m维的矩阵
输入矩阵的维度为n,卷积核的维度也要是n,但是最后输出的矩阵是一维的。如果想输出m维的矩阵,那就要和m的卷积核和做运算,最后输出的结果按顺序排列起来就得到m维的矩阵
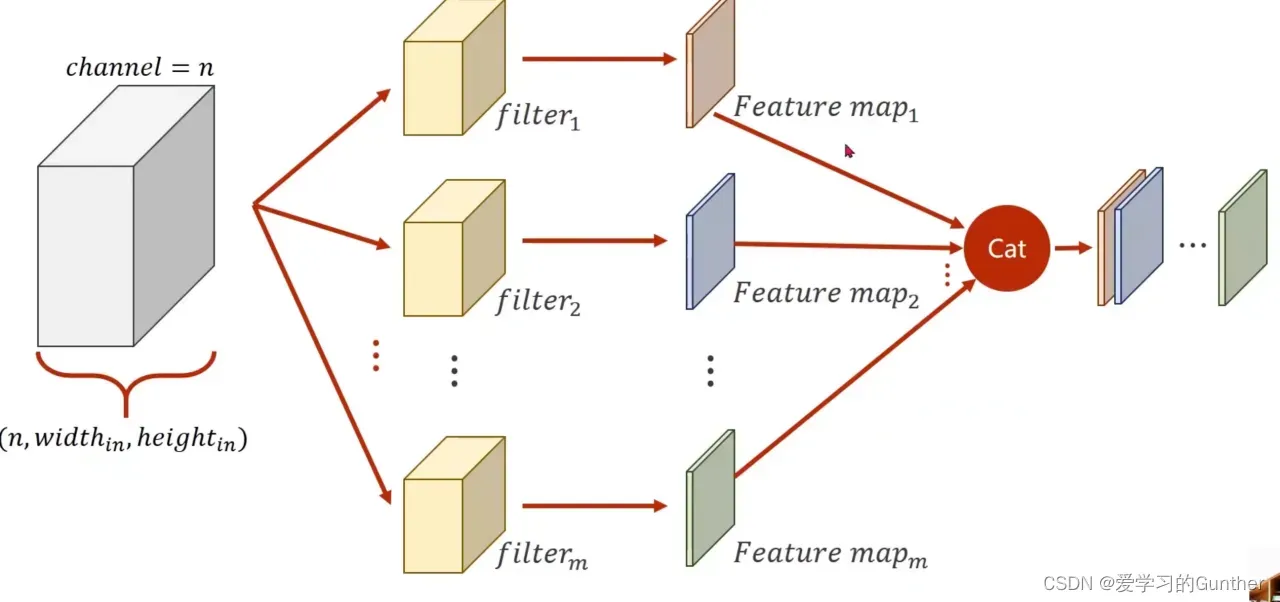
总结:卷积层的权重是四维的,也就是说构造卷积层需要四维参数,第一个输入的矩阵维数,第二个输出矩阵的维数,宽度第三个卷积核和第四维。卷积核的高度:

代码:
import torch
in_channels,out_channels = 5,10#定义输出输入的数据的通道数
width,height = 100,100
kernel_size = 3 #定义卷积核的大小
bath_size = 1
input = torch.randn(bath_size,
in_channels,
width,height)#用torch随机定义一个输入矩阵
conv_layer = torch.nn.Conv2d(in_channels,out_channels,
kernel_size=kernel_size)
#构建卷积层需要四个数据(输入的通道数,输出的通道数,卷积核的宽,卷积核的高)
# 构建卷积层的输入的通道数一定要和需要卷积的矩阵的输入通道数一致
output = conv_layer(input)
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)输出:

可以看出输入的矩阵高和宽是100*100,做卷积后输出的高和宽变成98*98,如果想要输出的数据的高和宽保持和原始高和宽怎么做?
Padding
conv内提供的一个参数,加上这个参数会临时改变输入的矩阵的高和宽,前面的得知一个5*5的矩阵和一个3*3的卷积核做数乘会得到一个3*3的矩阵,如果padding=1,原本5*5的矩阵变成6*6,再和3*3的卷积核做数乘得到的矩阵会是5*5的。
向外一层的填充默认是0
代码:
import torch
input = [3,4,6,5,7,2,4,6,8,2,1,6,7,8,4,9,7,4,6,2,3,7,5,4,1]#一维1*25的数据
input = torch.Tensor(input).view(1,1,5,5)#用Tensor.view函数来转换数据的形状(B,C,W,H)
copy_layer = torch.nn.Conv2d(1,1,kernel_size=3,bias=False) #
conv_layer_p = torch.nn.Conv2d(1,1,kernel_size=4,padding=1,bias=False)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3)#自己定义个卷积核矩阵
conv_layer_p.weight.data = kernel.data#对卷积层的权重做一个初始化
copy_layer.weight.data = kernel.data
output = copy_layer(input)
output_p = conv_layer_p(input)
#对比
print(output)
print('形状=',output.shape)
print(output_p)
print('形状=',output_p.shape)结果:
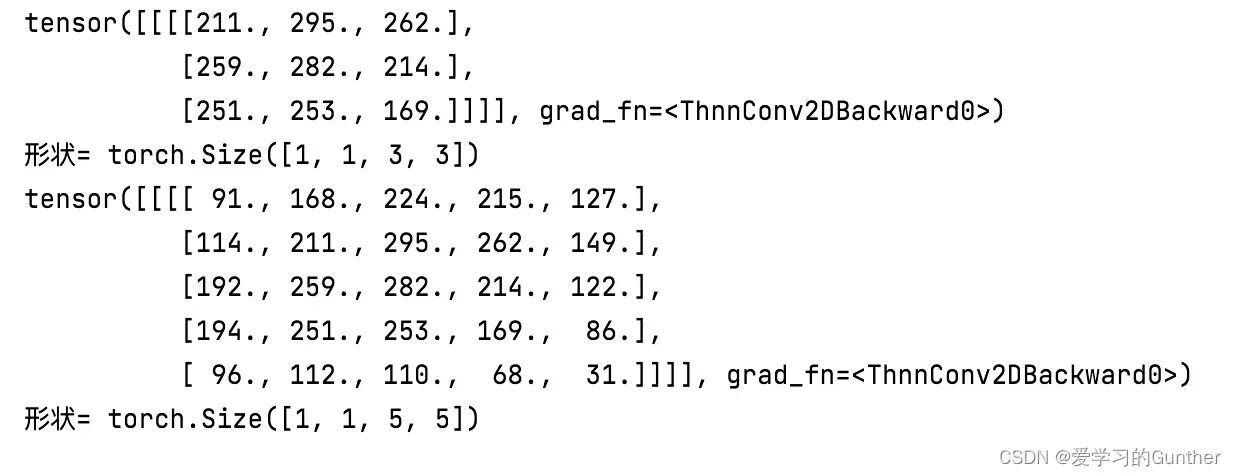
池化层MaxPooling
最大池化层,作用是减少数据的数据量,降低运算的需求,按照卷积核的形状在输入的矩阵范围内找最大值,用这些最大值组成新的矩阵,默认strdie(步长)为2,MaxPooling对维度没有要求,只会改变原始矩阵的高和宽维度不会发生改变。
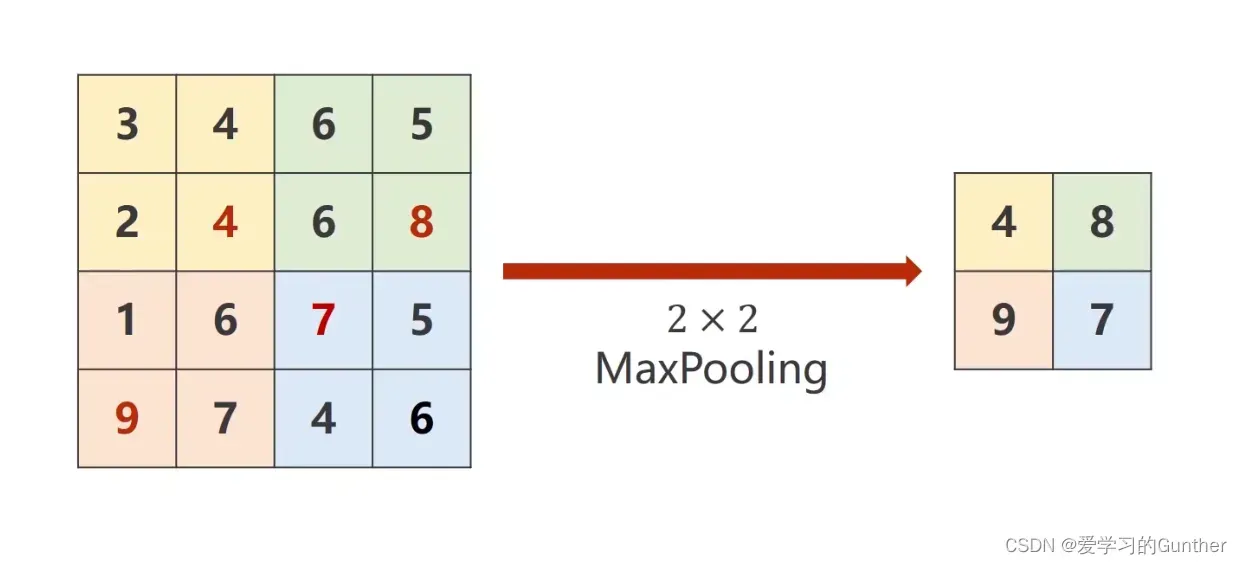
代码:
import torch
input_M =[3,4,6,5,2,4,6,8,2,6,7,8,9,7,4,6]
input_M = torch.Tensor(input_M).view(1,1,4,4)
maxpooling = torch.nn.MaxPool2d(kernel_size=2)
output = maxpooling(input_M)
print(output)结果:

实现构建一个简单的卷积神经网络
构建第一个大致规划模型如图:
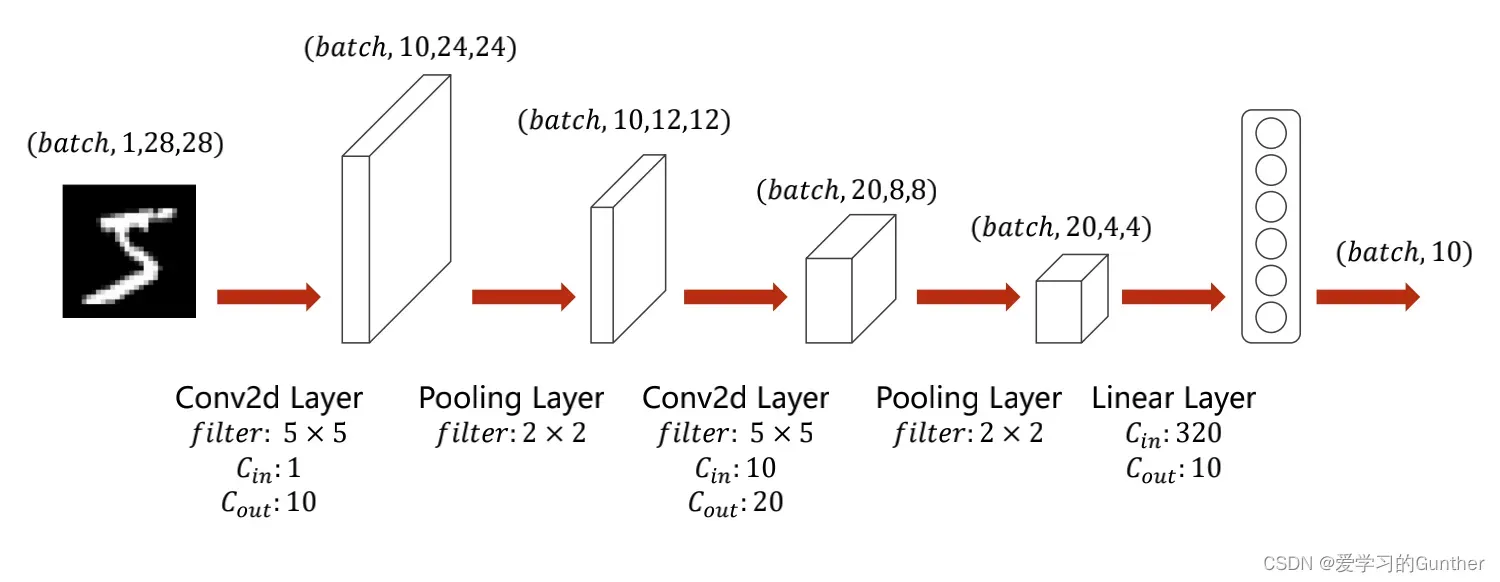
我拿MNIST数据来做预测,MMNIST需要10个分类,所以最后我们需要输出 10 个数据,卷积层的搭建操作很简单就是在设计模型的时候堆上卷积层和池化层就可以了,只要注意第一点就是层与层之间的维度是能对上的,就能保证卷积神经的正常运行。
数据通过卷积神经网络后,还需要全连接。执行完全连接非常重要。它需要线性数据,而且要知道要接收的数据量,也就是说数据是卷积的。对于层后得到的矩阵,我们需要对数据进行线性变化来计算数据量,然后将数据量告诉全连接层,这样全连接才能正常运行。如何解决这个问题呢?
1、设计好模型手算出来
2、同样设计好模型,定义一个和MNIST图片大一样的矩阵,拿这个矩阵放进设计好的卷积层里跑一跑,让电脑帮我们算。
例子:
'''次代码用于测试通过卷积后得到的张量数量'''
import torch
import torch.nn.functional as f
input_MO = torch.randn(1,1,28,28)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2 = torch.nn.Conv2d(10,20,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
def forward(self, x):
batch_size = x.size(0)
x = self.pooling(f.relu(self.conv1(x)))
x = self.pooling(f.relu(self.conv2(x)))
return x
model= Net()
output=model(input_MO)
print(output.shape)结果:
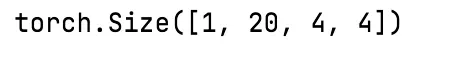
算出的是通道20高4宽4的矩阵,总共20*4*4=320个数据点,所以,全连接层需要接收320个数据量。
完整型号:
数据➡️卷积层➡️ReLU激活层➡️池化层➡️卷积层➡️激活层➡️池化层➡️全连接➡️
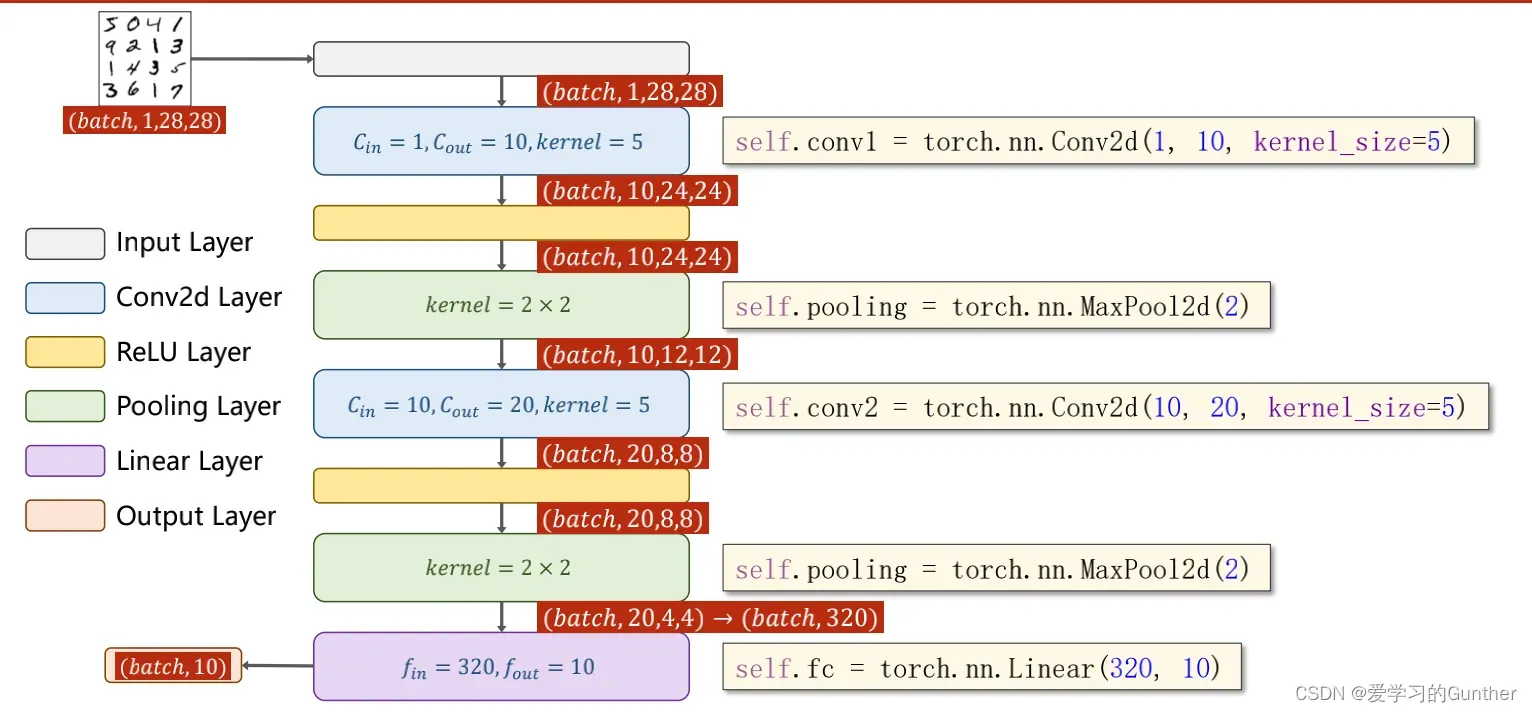
完整型号代码:
'''2、制作模型'''
'''模型里加入特征提取层(卷积层,下采样层),提高精确度'''
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)#卷积
self.conv2 = torch.nn.Conv2d(10,20,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)#最大池化
self.linear1 = torch.nn.Linear(320,160)
self.linear2 = torch.nn.Linear(160,10)
def forward(self, x):
batch_size = x.size(0)
x = self.pooling(f.relu(self.conv1(x)))
x = self.pooling(f.relu(self.conv2(x)))
x = x.view(batch_size,-1)#把数据张开变成向量
x = self.linear1(x)
return self.linear2(x)
model = Net()用此模型做MNIST分类预测精度可以达到 98%

提升了1%,已经很棒了
文章出处登录后可见!