深度学习知识点总结
专栏链接:
深度学习知识点总结_Mr.小梅的博客-CSDN博客本专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章介绍了各种损失函数。
内容
2.3 损失函数
2.3.1 L1Loss
2.3.2 MSELoss
2.3.3 CrossEntropyLoss
2.3.4 NLLLoss
2.3.5 BCELoss
2.3.6 BCEWithLogitsLoss
2.3.7 MultiMarginLoss
2.3.8 MultiLabelMarginLoss
2.3.9 SmoothL1Loss
2.3.10 Focal loss
2.3.11 IoU Loss
2.3.12 GIoU Loss
2.3.13 DIoU Loss
2.3.14 CIoU Loss
2.3.15 CTCLoss
2.3损失函数
深度学习中主要包含三类任务,分类、回归和分割,不同的任务需使用不同的损失函数。例如,分类任务中不能使用平方损失、L1Loss等。
2.3.1 L1Loss
可用于坐标回归,但目前很少使用。

import torch.nn as nn
import torch
l1loss = nn.L1Loss()
pred = torch.ones((4,5))
gt = torch.zeros((4,5))
loss = l1loss(pred,gt)
print(loss) # tensor(1.)2.3.2 MSELoss
可用于坐标回归。

# MSELOSS
loss = nn.MSELoss()
pred = torch.ones((4,5)) * 2
gt = torch.zeros((4,5))
out = loss(pred,gt)
print(out) # tensor(4.)2.3.3 CrossEntropyLoss
用于单标签多分类任务。

# CrossEntropyLoss
loss = nn.CrossEntropyLoss()
pred = torch.Tensor([[0.8, 0.1, 0.4],
[0.1, 0.9, 0.2],
[0.5, 0.4, 0.6]])
gt = torch.LongTensor([0,
1,
2])
out = loss(pred, gt)
print(out) # tensor(0.8137)
'''
s1 = exp(0.8) + exp(0.1) + exp(0.4) = 4.822536544209386
s2 = exp(0.1) + exp(0.9) + exp(0.2) = 4.786176787392767
s3 = exp(0.5) + exp(0.7) + exp(0.6) = 4.962664768731908
l1 = -ln(exp(0.8) / s1) = 0.7733000436247918
l2 = -ln(exp(0.9) / s2) = 0.6657319272479286
l3 = -ln(exp(0.6) / s3) = 1.0019428482292443
loss = (l1 + l2 + l3) / 3 = 0.8136582730339882
'''2.3.4 NLLLoss
单标签多分类任务的负对数似然损失。

# NLLLoss
loss = nn.NLLLoss()
pred = torch.Tensor([[0.1, 0.8, 0.2],
[0.4, 0.5, 0.6]])
gt = torch.tensor([1, 2])
out = loss(pred, gt)
print(out) # tensor(-0.7000)
'''
out = -(0.8 + 0.6) / 2 = -0.7
'''
# 实际运用中需要使用LogSoftmax
m = nn.LogSoftmax(dim=1)
# input is of size N x C = 3 x 5
input = torch.randn(3, 5, requires_grad=True)
# each element in target has to have 0 <= value < C
target = torch.tensor([1, 0, 4])
output = loss(m(input), target)2.3.5 BCELoss
用于多标签分类任务。

# BCELoss
loss = nn.BCELoss()
pred = torch.Tensor([[0.1, 0.9, 0.8],
[0, 1, 0]])
gt = torch.Tensor([[0, 1, 1],
[0, 1, 0]])
out = loss(pred, gt)
print(out) # tensor(0.0723)
'''
out11 = -(0 * log(0.1) + (1 - 0) * log(1-0.1)) = 0.10536051565782628
out12 = -(1 * log(0.9) + (1 - 1) * log(1-0.9)) = 0.10536051565782628
out13 = -(0 * log(0.8) + (1 - 1) * log(1-0.8)) = 0.2231435513142097
out1 = (out11 + out12 + out13) / 3 = 0.14462152754328741
out2 = 0
out = (out1 + out2 ) / 2 = 0.07231076377164371
'''
# 实际运用中需要使用sigmoid
m = nn.Sigmoid()
loss = nn.BCELoss()
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
output = loss(m(input), target)2.3.6 BCEWithLogitsLoss
与BCELoss一样,用于多标签分类任务,只是集成了sigmoid在函数中,不需要自己计算sigmoid。

loss = nn.BCEWithLogitsLoss()
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
output = loss(input, target)
output.backward()2.3.7 MultiMarginLoss
用于单标签多分类任务。

# MultiMarginLoss
loss = nn.MultiMarginLoss() # margin默认为1
x = torch.FloatTensor([[0.1, 0.2, 0.4, 0.8]])
y = torch.LongTensor([3])
out = loss(x,y)
print(out) # tensor(0.3250)
# ((1-0.8+0.1)+(1-0.8+0.2)+(1-0.8+0.4))/4/1=0.3252.3.8 MultiLabelMarginLoss
用于多标签多分类任务,计算方式与MultiMarginLoss类似。
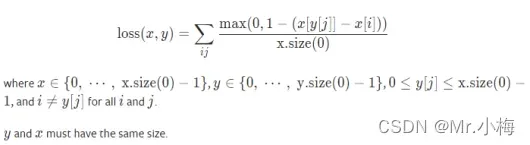
# MultiLabelMarginLoss
loss = nn.MultiLabelMarginLoss()
x = torch.FloatTensor([[0.1, 0.2, 0.4, 0.8]])
# for target y, only consider labels 3 and 0, not after label -1
# y = torch.LongTensor([[3, 0, -1, 1]])
# 0.25 * ((1-(0.8-0.2)) + (1-(0.8-0.4)) + (1-(0.1-0.2)) + (1-(0.1-0.4))) = 0.85
# y = torch.LongTensor([[3, 0, 0, 0]])
# 0.25 * ((1-(0.8-0.2)) + (1-(0.8-0.4)) + \
# (1-(0.1-0.2)) + (1-(0.1-0.4)) +\
# (1-(0.1-0.2)) + (1-(0.1-0.4))+\
# (1-(0.1-0.2)) + (1-(0.1-0.4)))
y = torch.LongTensor([[3, -1, 0, 0]])
# 0.25 * ((1-(0.8-0.2)) + (1-(0.8-0.4))+(1-(0.8-0.1))) =0.325
out = loss(x, y)
print(out)2.3.9 SmoothL1Loss
用于坐标回归。

# SmoothL1Loss
loss = nn.SmoothL1Loss()
pred = torch.FloatTensor([0.8, 0.1])
gt = torch.Tensor([1, 1])
out = loss(pred, gt)
print(out) # tensor(0.2125)
# beta=1 |0.8-1|<1 |0.1-1|>1
# (0.5*(0.8-1)**2+abs(0.1-1)-0.5*1)/2=0.2102.3.10 Focal loss
用于单标签多分类任务。
![]()
![]()
默认γ = 2, α = 0.25
# FocalLoss
loss_v1 = FocalLossV1(alpha=0.25, gamma=2.0, logits=True)
pred = torch.Tensor([[-0.1, 0.9, 0.23],
[-0.12, -0.34, 0.6]])
# F.sigmoid(pred)
#tensor([[0.4750, 0.7109, 0.5572],
# [0.4700, 0.4158, 0.6457]])
gtv1 = torch.Tensor([[0, 1, 0],
[0, 0, 1]])
outv1 = loss_v1(pred, gtv1)
''' 计算过程
l11 = -(1-0.25)*0.4750**2*log(1-0.4750)=0.10903728886733216
l12 = -0.25*(1-0.7109)**2*log(0.7109)=0.007129763644852741
l13 = -(1-0.25)*0.5572**2*log(1-0.5572)=0.1896914044385448
l1 = l11+l12+l13=0.30585845695072966
l21 = -(1-0.25)*0.4700**2*log(1-0.4700)=0.10518345778582924
l22 = -(1-0.25)*0.4158**2*log(1-0.4158)=0.06969767774239252
l23 = -0.25*(1-0.6457)**2*log(0.6457)=0.013727176790536994
l2 = l21+l22+l23=0.18860831231875877
l = (l1+l2)/3/2=0.0824111282115814
'''Focal Loss可以解决类别分类不均衡和难/易样本平衡的问题。
如何通过公式解决:
α决定了正样本和负样本的重要性。 α越大,关注的正样本越多,可以根据训练数据中正负样本的比例调整α值,或者需要更加关注正负样本。
分析α
gt = [[0,1]]
pred_sigmoid = [[0.2,0.9]]
alpha=0.25,gamma=2
l11 = -(1-0.25)*0.2**2*log(1-0.2)=0.006694306539426292
l12 = -(0.25)*(1-0.9)**2*log(0.9)=0.00026340128914456557
alpha=0.75,gamma=2
l11 = -(1-0.75)*0.2**2*log(1-0.2)=0.0022314355131420973
l12 = -(0.75)*(1-0.9)**2*log(0.9)=0.0007902038674336968
alpha=1,gamma=2
l11 = -(1-1)*0.2**2*log(1-0.2)=0.0
l12 = -(1)*(1-0.9)**2*log(0.9)=0.0010536051565782623
alpha=0,gamma=2
l11 = -(1-0)*0.2**2*log(1-0.2)=0.00892574205256839
l12 = -(0)*(1-0.9)**2*log(0.9)=0.0
可以看到当alpha值变大时,正样本的loss比重变大。
极端假设alpha=1时,负样本的loss为0,alpha=0时,正样本的loss为0。
所以alpha越大,越关注正样本;alpha越小,越关注负样本。(1-p)^γ决定难易分样本重要度。
首先了解下难易样本怎么区分,设定预测概率0-1,难分样本:对于gt是0(或者1)的样本,预测值越趋近与1(或者0),往往越是难分样本;易分样本:对于gt是0(或者1)的样本,预测值越趋近与0(或者1),往往越是易分样本。
对于正样本,当p越大(易分样本)时, (1-p)越小, (1-p)^γ越小;当p越小(难分样本)时,(1-p)越大, (1-p)^γ越大。相当于越关注难分样本。
alpha=0.25,gamma=2
pred_sigmoid = [[0.2,0.9]]
l11 = -(1-0.25)*0.2**2*log(1-0.2)=0.006694306539426292
l12 = -(0.25)*(1-0.9)**2*log(0.9)=0.00026340128914456557
l11/l12=25.41485867881299
pred_sigmoid = [[0.4,0.5]]
l11 = -(1-0.25)*0.4**2*log(1-0.4)=0.0612990748519189
l12 = -(0.25)*(1-0.5)**2*log(0.5)=0.04332169878499658
l11/l12=1.4149739407991162
alpha=0.25,gamma=1
pred_sigmoid = [[0.2,0.9]]
l11 = -(1-0.25)*0.2**1*log(1-0.2)=0.03347153269713146
l12 = -(0.25)*(1-0.9)**1*log(0.9)=0.0026340128914456563
l11/l12=12.707429339406493
pred_sigmoid = [[0.4,0.5]]
l11 = -(1-0.25)*0.4**1*log(1-0.4)= 0.15324768712979725
l12 = -(0.25)*(1-0.5)**1*log(0.5)=0.08664339756999316
l11/l12=1.7687174259988954
alpha=0.25,gamma=0
pred_sigmoid = [[0.2,0.9]]
l11 = -(1-0.25)*0.2**0*log(1-0.2)=0.16735766348565728
l12 = -(0.25)*(1-0.9)**0*log(0.9)=0.02634012891445657
l11/l12=6.353714669703243
pred_sigmoid = [[0.4,0.5]]
l11 = -(1-0.25)*0.4**0*log(1-0.4)=0.38311921782449304
l12 = -(0.25)*(1-0.5)**0*log(0.5)=0.17328679513998632
l11/l12=2.2108967824986188
从上面计算过程,可以看到,gamma越大,易分样本loss的比重越小,难分样本loss的比重越大。
从上面计算结果可以看出,随着γ值变小,对于易分样本(这里指pred_sigmoid = [[0.2,0.9]],对应的loss越小,对于难分样本(这里指pred_sigmoid = [[0.4,0.5]]),对应的loss越大。当γ等于0时就变成了交叉熵损失。
2.3.11 IoU Loss
2.3.12 GIoU Loss
2.3.13 DIoU Loss
2.3.14 CIoU Loss
2.3.15 CTCLoss
文章出处登录后可见!