文章来源 |恒源云社区
原文地址 |用于视频的可变形Transformer
原作者 |冬冬
hi,大家好啊!窗外的树🌲 绿了,楼下的桃花🌺 开了,春天,就这么滴的过去了……
小编已经居家办公(不能下楼)3个礼拜啦!敬请期待疯掉的小编~
啊啊啊,我的春游彻底没救了! ! !
说那么多有啥用呢?还不是得乖乖搬运社区文章!毕竟社区伙伴们发帖是那么的勤快!Respect!
正文开始
概括
- 引入主题:在视频分类领域,视频Transformer最近作为一种有效的卷积网络替代品出现。
- 现存问题:大多数以前的视频Transformer采用全局时空注意或利用手动定义的策略来比较帧内和帧间的patch。这些固定注意力方案不仅计算成本高,而且通过比较预定位置的patch,忽略了视频中的运动动力学。
- 解决方案:该论文介绍了可变形视频Transformer(DVT),它根据运动信息动态预测每个查询位置的一小部分视频Patch,从而允许模型根据帧间的对应关系来决定在视频中查看的位置。关键的是,这些基于运动的对应关系是从以压缩格式存储的视频信息中以零成本获得的。
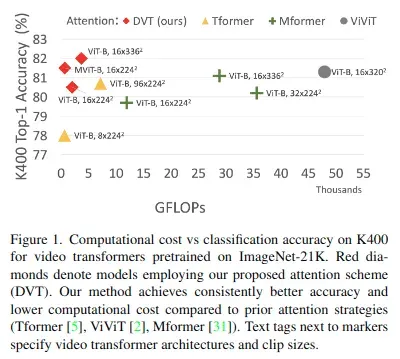
- 实验结果:在四个大型视频基准(Kinetics-400、Something-Something-V2、EPIC-KITCHENS和Diving-48)上的实验表明,该论文模型在相同或更低的计算成本下实现了更高的精度,并在这四个数据集上获得了最优结果。
算法
视频TRANSFORMER
视频数据的输入大小一般可以表示为,T表示帧数,3表示每一帧是RGB图像
因为使用的是Transformer架构,所以首先需要将输入数据转换为一个tokens,S表示每一帧中的patch个数,每个token可以表示为
。整个过程可以表示如下:
- 将每一帧图像进行非重叠分割,生成S个patch。
- 将每个patch投影到D个通道维度上。
- 添加空间位置码
和时间码
终于得到
然后通过多头自注意力,layer norm(LN)和MLP计算,可以表示如下: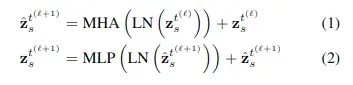
具体的self-attention可以表示如下(为了简化说明使用单头)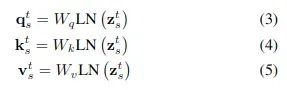
根据以往的视频Transformer算法,自注意力机制可以分为Global space-time attention和Divided space-time attention
Global space-time attention
简单来说就是结合空间和时间进行attention计算,公式如下: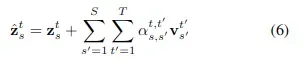
计算注意力权重的公式如下: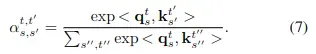
整个计算过程的计算复杂度为,最大的问题是计算量大。
Divided space-time attention
顾名思义,就是将时间和空间的注意力分开,减少计算量。
空间注意力的计算公式如下: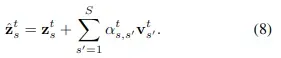
的计算复杂度对应的时间注意力的计算公式如下:
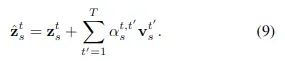
计算复杂度为
需要注意的是,时间注意力只在不同时间帧的相同空间位置上执行注意力计算!这是它最大的问题,因为它没有考虑对象在帧之间的移动。
可变形视频TRANSFORMER
主要分为以下三个部分(创新点)
Deformable Space-time Attention(D-ST-A)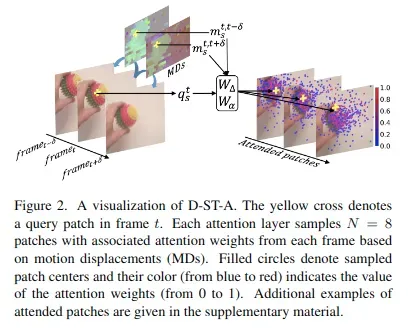
这个注意力机制和上文Divided space-time attention中的时间注意力机制很相似,但是有两个主要不同点:
- 对于每个查询
,使用不同帧上的N个空间位置
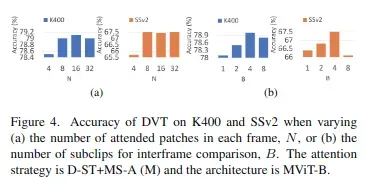
进行相似度计算,而不是一个固定位置,这虽然带来相对较大的计算量,但会获取更大空间上的特征信息,性能会提高很多。文中使用N=8。
- 这N个位置是数据驱动的,而不是人为定义的,这在后面进行细说。
这种注意力机制的数学表达式如下: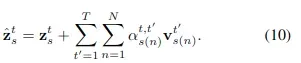
其中每一帧上的N个空间位置是如何计算的呢?
——根据查询点特征与运动嵌入特征的投影产生的相对偏移量计算得出。公式如下:![]()
![]()
其中运动嵌入是根据存储在压缩视频中的运动位移和RGB residuals确定的,详细步骤可以查看论文。
相似度矩阵不同于前面的计算方法,而是根据查询点特征和运动嵌入特征计算得到的。公式如下:
![]()
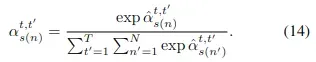
Deformable Multi-Scale Attention (D-MS-A)
上述D-ST-A是一个时间上的注意力机制,而D-MS-A是一个空间上的注意力机制,用于编码同一帧上的注意力。
但对于每一帧图像,这里引入了多尺度注意力——计算F个不同分辨率下的空间信息,不同分辨率图像中采样个patch进行注意力计算,多分辨率可以通过不同步长的3D卷积层来实现,数学表达式如下:
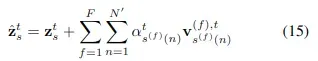
其中不同分辨率图像中的patch采样也是通过根据其中对应查询点特征计算偏置得到的,计算公式如下:![]()
Attention Fusion
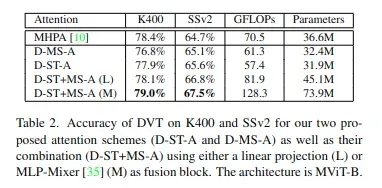
可以仅使用可变形时空注意(D-ST-A)、仅使用可变形多尺度注意(D-MS-A)以及两者的组合(D-ST+MS-A)。
在最后一种情况下,将由这两种注意策略独立计算出的两个token和
馈送到一个注意力融合层u()进行信息融合,
。
论文给出了两种形式的注意力融合方式,一种基于简单的线性投影,另一种基于MLP-Mixer模型。
实验
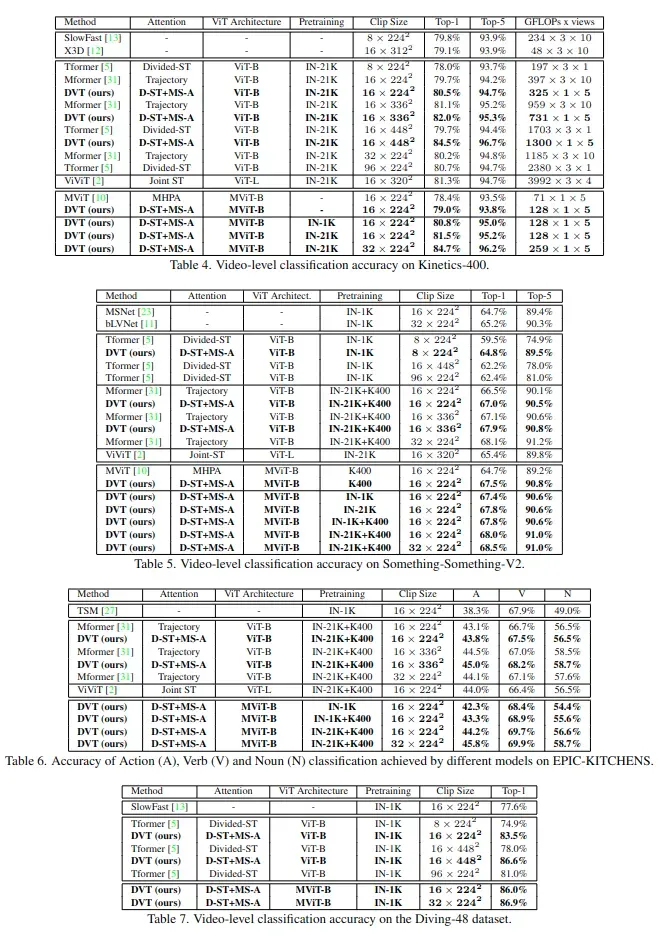
在四个标准视频分类基准上评估DVT:Kinetics-400(K400)、Something-Something-V2(SSv2)、EPIC-KITCHENS-100(EK100)和Diving-48(D48)
消融实验
Choice of motion cues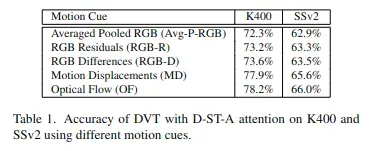
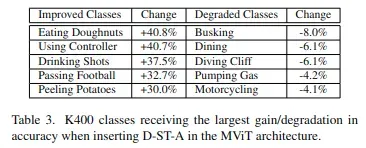
COMPARISON TO THE STATE-OF-THE-ART
文章出处登录后可见!