



提示:文章写完后,可以自动生成目录。生成方法请参考右侧帮助文档
EDTER:Edge Detection with Transformer
基于transform的边缘检测论文解读
一、Abstract
该论文提出了一种基于Transform的边缘检测器,利用完整的图像上下文信息和详细的局部特征,提取出清晰的目标边界和有意义的边缘。
EDTER主要分两个stage:
stage1: 使用transform在coarse-grained image patches 上获取long-range 全局上下文信息。
stage2: 使用transform在fine-grained image patches 上获取lshort-range 局部上下文信息。
每个transform encoder后面设计一个双向多级聚合解码器(Bi-directional Multi-Level Aggregation decoder),最后,通过Feature Fusion Module将全局和局部特征结合起来,输入到决策头进行边缘预测。
代码
纸
二、Introduction
边缘检测是计算机视觉中最基本的问题之一,具有广泛的应用。边缘检测的目的是提取准确的对象边界和视觉上显着的边缘。边缘检测与上下文和图像语义信息密切相关。
传统方法主要使用基于颜色和纹理的低级局部线索来获取边缘。
CNN在边缘检测取得了显著的进展,但是CNN的特点是随着感受野的扩大,可以获取到全局的语义信息,不可避免得丢失了必不可少的细节。
vision Transform具有modeling long-range上下文信息的能力。该论文提出了为边缘检测tailor transformers。但是面临两个挑战。(1)出于计算方面的考虑,transformers一般应用于大尺寸的patches,而coarse-grained patches不利于准确边缘的提取。不增加计算负担的情况下,perform self-attention 在fine-grained patches是重要滴。(2)从相交和thin objects提取准确的边缘是困难滴。有必要设计出一种有效的decoder 来生成边缘感知的高分辨率features。
为了解决上述问题,提出了一种两阶段的框架,EDTER,提取全局上下文信息和局部区域的fine-grained cues。阶段1中,将图像分割成coarse-grained patches并且run一个全局transformer编码器来获取long-range的上下文信息。然后,develop BiMLA解码器生成高分辨率的representations用于边缘检测。阶段2中,首先通过不重叠的滑动窗口将整个图像分割成多个fine-grained patches序列,然后一个局部transformer作用于每个序列来提取short-range局部 cues。然后将局部cues输入到局部BiMLA解码器获取像素级特征图。最后通过FFM融合两个阶段的信息然后输入到决策头进行最终的边缘预测。
三、Related Work
作为计算机视觉的一项基本任务,边缘检测多年来得到了广泛的研究。下面重点介绍与本文相关的一些工作。
Edge Detection: 早期的边缘检测器,如Sobel、Canny主要是对图像进行梯度分析,提取边缘。这些方法提供了基本的底层cues,广泛应用于计算机视觉领域。基于Learning-based的方法整合不同的低层特征训练分类器得到边界和边缘,这些方法基于手工制作的特征,限制了检测语义边界和有意义的边缘的能力。DeepEdge、HED、RCF、BDCN、PiDiNet(主要阐述了前人做的工作,见原文)。
Vision transformer: DETR、ViT、SETR,这些工作证明了transformer在获取远程依赖关系和全局上下文信息的有效性。
阐述该论文的创新点:第一个将transformer应用于边缘检测。
全局和局部图像上下文信息是通过两阶段框架学习的。
融合了全局和局部cues。
四、Edge Detection with Transformer
4.1 Overview
EDTER分两阶段提取整幅图像的上下文信息和fine-grained cues。阶段1中,将图像分割成coarse-grained patches并且run一个全局transformer编码器来获取long-range的上下文信息。然后,develop BiMLA解码器生成高分辨率的representations用于边缘检测。阶段2中,首先通过不重叠的滑动窗口将整个图像分割成多个fine-grained patches序列,然后一个局部transformer作用于每个序列来提取short-range局部 cues。然后将局部cues输入到局部BiMLA解码器获取像素级特征图。最后通过FFM融合两个阶段的信息然后输入到决策头进行最终的边缘预测。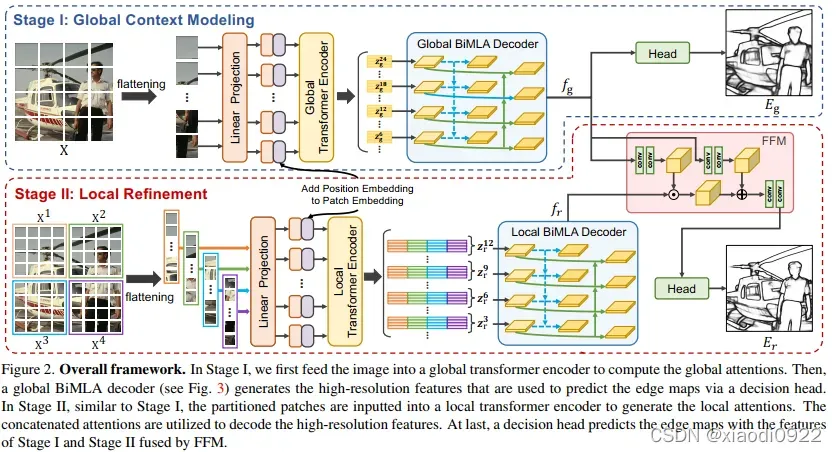

4.2 Review Vision Transformer
本文采用的transformer encoders遵循ViT。
Image Partition:ViT的第一步是将2D图像X(H×W×3)转换为1D的图像patches序列。也就是将X分割成尺寸为P×P的flattened image patches,产生H/P×W/P的vision tokens。然后,通过learnable linear projection将序列投影到一个隐藏的embedding space。为了保留位置信息,在patch embeddings中加入标准的可学习的1D position embeddings。最后,将组合好的embedding输入到transformer encoder。
Transformer Encoder:标准的transformer encoder 是由L个transformer blocks组成。每个块有多头自注意力 操作(MSA)、一个多层感知机(MLP)、和两个Layernorm,此外,每个块应用一个残差连接。MSA并行执行M自注意力并输出他们的concat结果。
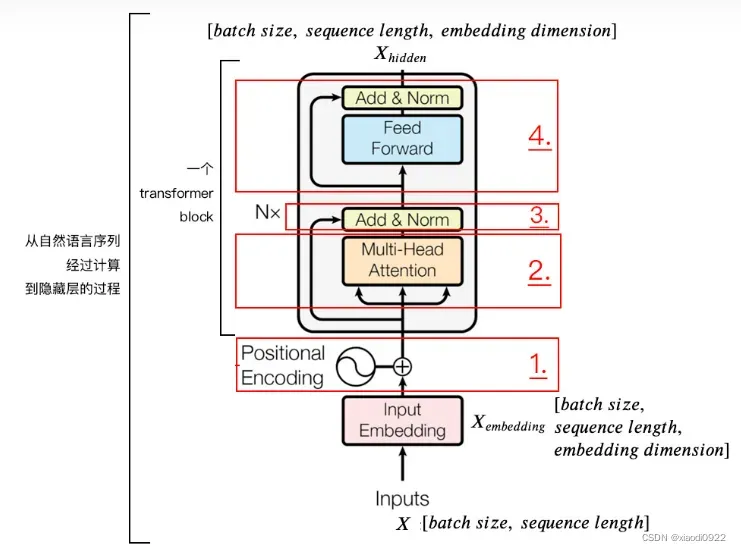
tramformer详解


4.3 Stage I: Global Context Modeling
在第一个阶段,通过全局tranformer encoder Ge和全局解码器Gd来提取coarse-grained patches全局上下文特征。
首先,将输入图像分成一系列尺寸为16×16的 coarse-grained patches,然后生成embedding (Zg0)作为编码器的输入。下一步全局tranformer encoder 作用于embedding(Zg0)计算全局的注意力。得到全局上下文特征Zg序列被全局解码器Gd上采样到高分辨率特征进行合并。
BiMLA Decoder: 生成边缘感知的像素级表示对于精确的边缘检测至关重要。受多级特征融合的影响,提出了双向多级聚合解码器(BiMLA)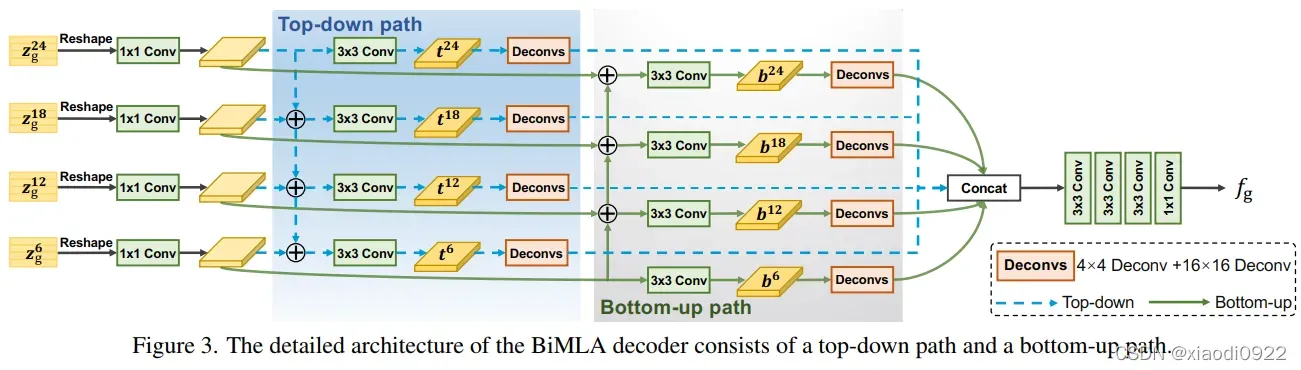
BiMLA包括一个自顶向下和自底向上的路径来增强信息的流通在transformer encoder。首先,将Lg个transformer blocks分成四组,从每组的最后一个block中拿出embedding features(Zg6,Zg12,Zg18,Zg24) 作为输入。然后将他们reshape成3D特征图(H/16×W/16×C)。对于自顶向下的路径,分配相同的设计(一个1×1卷积和3×3卷积层)作用于reshaped feature得到四个输出features(t6,t12,t18,t24),遵循SETR-MLA的方法。同样地,自底向上的路径从最底层逐步到顶层,分配3×3卷积层到多级特征上,最后产生另外四个输出features(b6,b12,b18,b24)。每个聚合特征通过一个反卷积block,包含4×4和16×16两个反卷积层。每个反卷积之后加入BN和ReLU。双路径来的八个特征图进行concat操作得到一个tensor。BIMLA使用额外的卷积层来平滑features,包括三层3×3卷积层和一个1×1卷积层+BN+ReLU。


4.4 Stage II: Local Refinement
因为16×16的patches不利于提取 thin edges,将像素作为tokens是一种直接的方法,但是,这将导致计算负担很大,在实际应用中不可行。作者的解决方法是用一个不重叠的滑动窗口进行采样,然后计算采样区域中的attentions。由于窗口中的patches的数量是固定的,计算复杂度和图像大小成线性关系。
采用H/2×W/2的滑动窗口,将输入图像分成{X1,X2,X3,X4}的序列。对于每个窗口,分割成8*8的fine-grained patches,通过局部tranformer编码器Re,计算attentions。然后,将所有窗口的attentions进行concat得到Zr={Zr1,···,ZrLr}。为了进一步节省计算资源,将Lr=12,也就意味着局部tranformer编码器由12个transformer blocks组成。与全局BiMLA类似,选择{Zr3,Zr6,Zr9,Zr12}输入到局部BiMLA Rd生成局部高分辨率特征。
Feature Fusion Module:通过一个特征融合模块整合了来自于两个levels的上下文cues,并利用局部决策头来预测边缘。FFM将全局上下文作为先验知识并对局部上下文进行modulates(调节),生成包含全局上下文和细粒度局部细节的融合特征。FFM由空间特征transform block和两个3×3卷积层组成,然后进行BN和ReLU。前者用于调节,后者用于平滑。然后将融合特征输入局部决策头Rh,预测出边缘图Er。


4.5 Network Training
训练方法:首先优化阶段1生成的全局特征,然后对参数进行修正并训练阶段2生成边缘图。
损失函数的设计:
Training Stage I:通过最小化每个边缘图和ground truth之间的损失优化阶段1。
Training Stage II:阶段1训练完之后,确定其参数然后进入阶段2。



5 实验结果
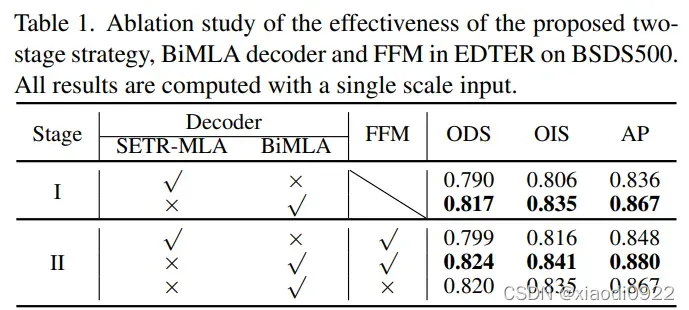
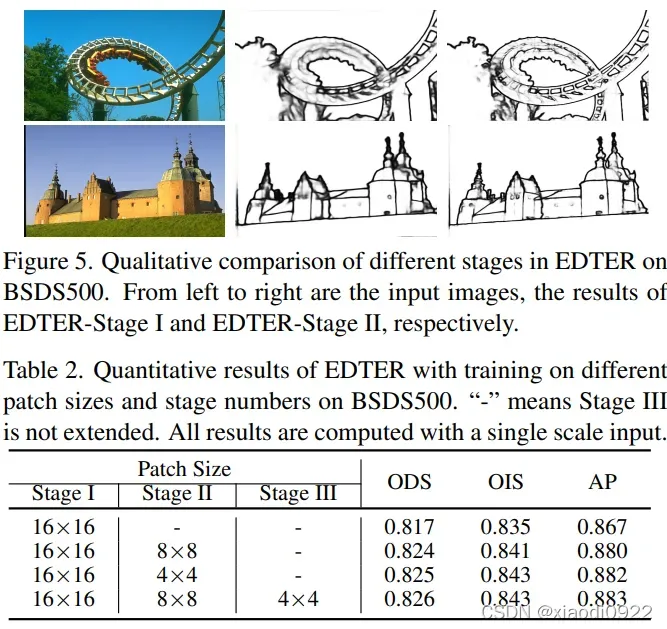
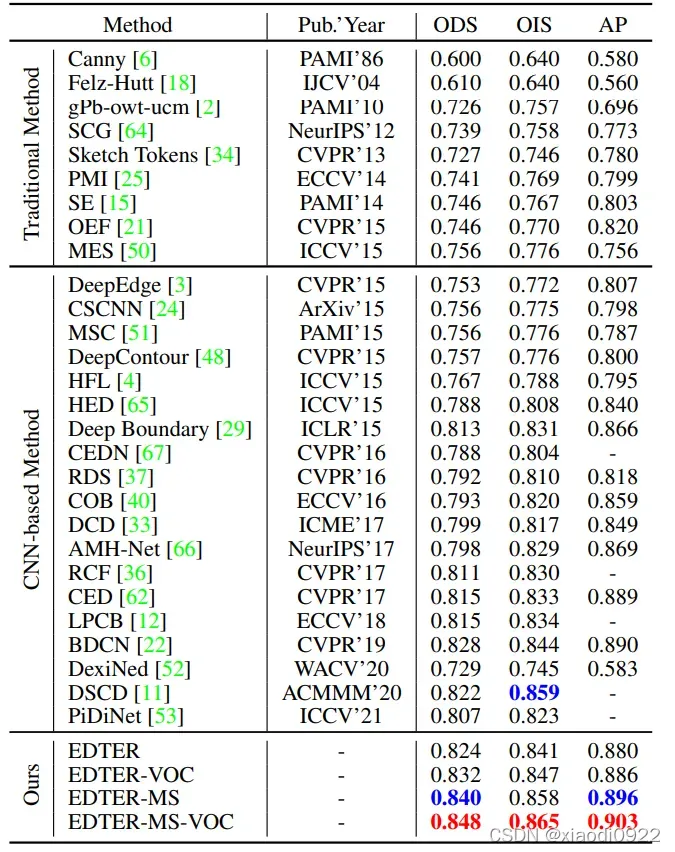
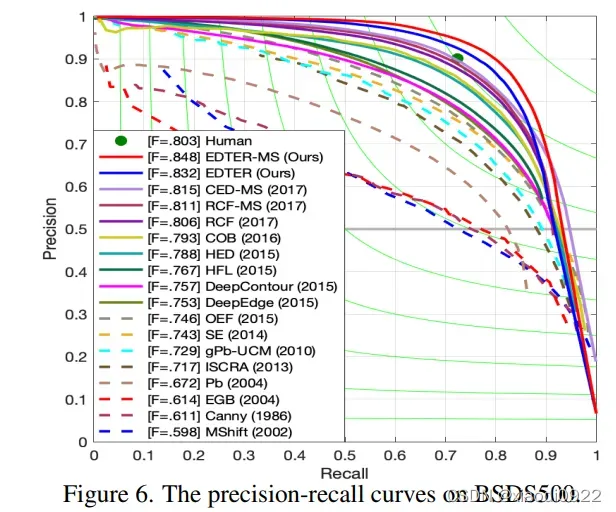
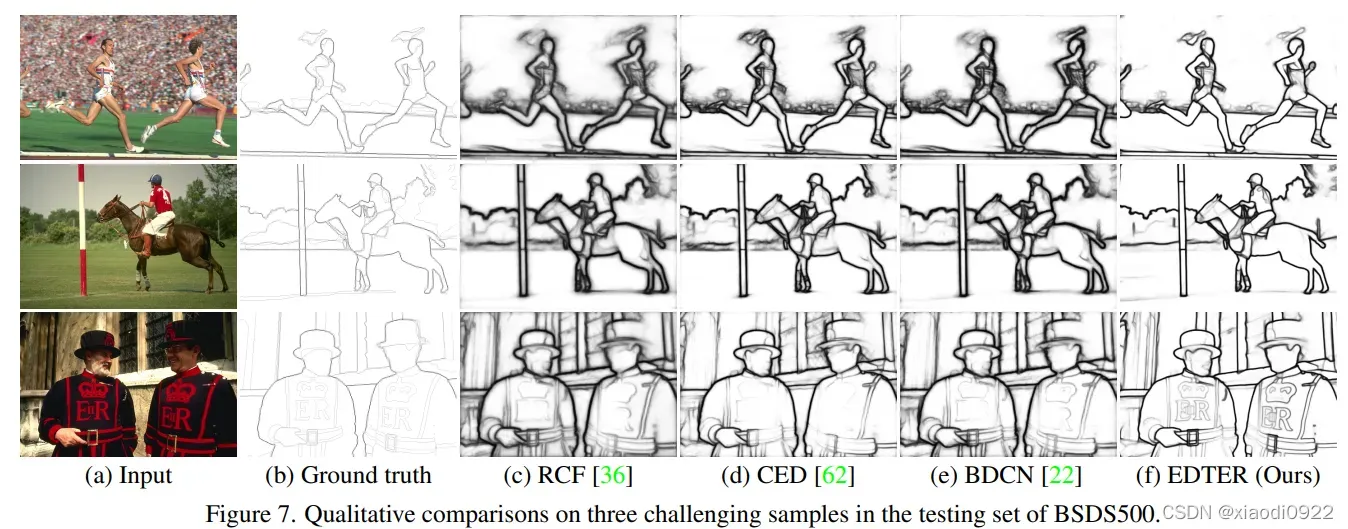
主要以图片的形式展示,这里就不过多解释了。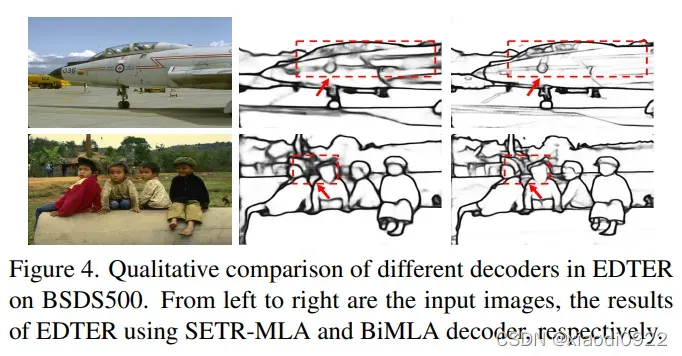






6 Limitation
该算法提取的边缘宽度占据多个像素,与理想的边缘宽度存在差距,在不进行任何预处理的情况下,生成清晰和thin的边缘是努力的方向。
文章出处登录后可见!