内容
重构子网
判别子网
模拟异常生成
表面异常定位和检测
近年来的表面异常检测方法依赖于生成模型来精确重构正常区域。这些方法只对无异常的图像进行训练,通常需要手工制作后处理步骤来定位异常,这妨碍了优化特征提取以获得最大的检测能力。除了重构方法外,作者将表面异常检测主要视为一个判别问题,并提出了一个判别训练的重构异常嵌入模型(DRÆM)。该方法学习异常图像的联合表示及其无异常重构,同时学习正常和异常样本的决策界。该方法可以直接进行异常定位,而不需要对网络输出进行额外的复杂后处理,并且可以使用简单和一般的异常模拟进行训练。在极具挑战性的MVTec异常检测数据集上,DRÆM大大优于目前最先进的无监督方法,甚至在广泛使用的DAGM表面缺陷检测数据集上,其检测性能接近完全监督方法,同时在定位精度上显著优于它们。
作者提出的鉴别关节重建正常嵌入方法(DRÆM)由一个重建子网络和一个鉴别子网络组成如图所示。重构子网络训练为隐式检测和重构具有语义上合理的无异常内容的异常,同时保持输入图像的非异常区域不变。同时,判别子网络学习联合重构异常嵌入,并根据级联重构和原始外观生成准确的异常分割图。异常训练示例由一个概念简单的过程创建,该过程在无异常图像上模拟异常。这种异常生成方法提供了任意数量的异常样本以及像素完美的异常分割图,可以在没有真实异常样本的情况下用于训练所提出的方法。
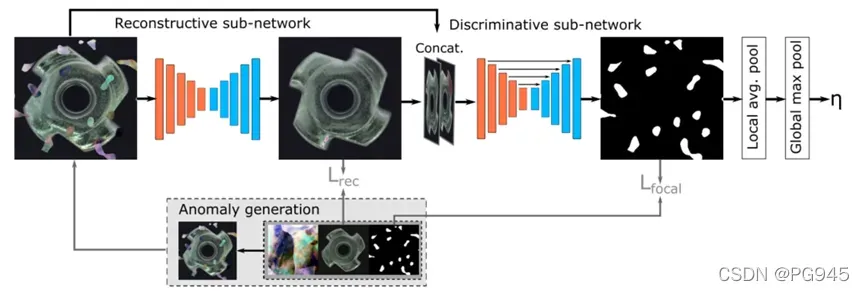
首先,利用 Lrec 训练的重构子网络隐式检测和修复异常区域。重构子网络的输出和输入图像随后被连接并馈送到判别子网络。分割网络使用焦点损失 Lfocal 进行训练,定位异常区域并生成异常图。从异常评分图中获取图像级异常评分η。
重构子网
重构子网络被看作是一种编译码器结构,它将输入图像的局部模式转换为更接近正态样本分布的模式。对网络进行训练,以从模拟器获得的人工损坏版本 Ia 去重构原始图像 I 。 l2 损失通常用于基于重构的异常检测方法 , 但这假设相邻像素之间是独立的,因而额外使用基于 patch 的SSIM损失:
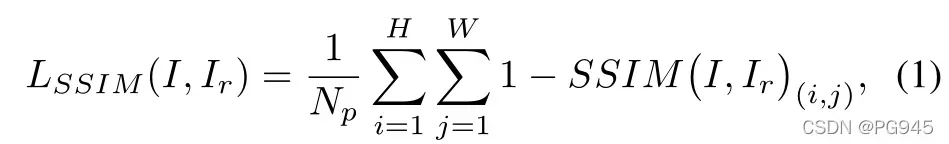
其中 H 和 W 分别为原图像 I 的高度和宽度。 Np 为原图像像素的个数, Ir 是网络输出的重构图像。 SSIM (I, Ir)(i, j) 为 I 和 Ir 的 patch 里面的 SSIM 值,以图像坐标 (i, j) 为中心,因此重构损失为
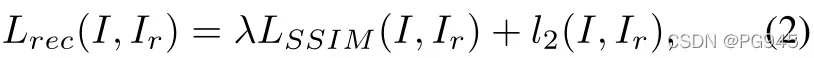
λ 是损失平衡超参数。
判别子网
判别子网络采用类似于 U-Net 的架构,这个子网络输入 Ic 被定义为重构子网络输出 Ic 和输入图像 I 的通道级联。由于重构子网络的正态恢复特性,在异常图像中, I 和 Ir 的联合形态存在显著差异,这为异常分割提供了必要的信息。在基于重构的异常检测方法中,利用 SSIM 等相似函数获得异常图,将原始图像与重构图像进行比较,然而,表面异常检测的特定相似性度量是很难手工制作的。而判别子网络则学习合适的距离自动的测量。网络输出与原始图像 I 大小相同的异常分数图 Mo 。将焦点损失 Focal Loss ( Lseg ) 应用于判别子网络的输出,以提高困难示例精确分割的鲁棒性。考虑到两个子网络的分割和重构目标,在训练DRÆM时,总损耗为
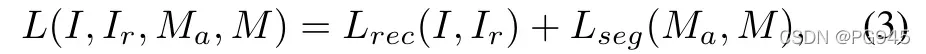
其中 Ma 和 M 分别为 ground truth 和输出的异常分割掩模。
模拟异常生成
DRÆM不需要模拟真实地反映目标域中真实的异常情况,而是生成 just-out- distribution 现象,这允许学习适当的距离函数,通过异常偏离正态来识别异常。提出的异常模拟器遵循这个范例。噪声图像是由柏林噪声生成的,以捕捉各种异常形状(图 P ),并通过随机均匀采样的阈值进行二值化,生成异常图( Ma )。从一个与输入图像分布无关的异常源图像数据集上采样异常纹理源图像 A 。

模拟异常生产过程
随机增加采样,从集合 { 色调分离,清晰度,曝光,均衡,亮度改变,颜色改变,自动对比度 } 中抽样 3 个随机增加函数。将增广纹理图像 A 与异常图 Ma 进行掩膜,并与原图像 I 进行混合,生成 just-out-of-distribution 的异常,从而有助于在训练后的网络中加强决策边界。因此将增强训练图像 Ia 定义为
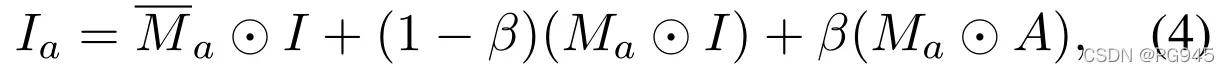 这里
这里![]() 是 Ma 的颠倒,
是 Ma 的颠倒,![]() 是逐元乘法运算,β是混合时的不透明度参数。该参数从一个间隔内均匀采样即β∈ [0.1, 1.0] 。随机混合和增强可以从单个纹理生成不同的异常图像 ( 见图 ) 。 原始异常源图像 ( 左 ) 可以被多次放大 ( 中 ) 来生成各种各样的模拟异常区域 ( 右 ) 。
是逐元乘法运算,β是混合时的不透明度参数。该参数从一个间隔内均匀采样即β∈ [0.1, 1.0] 。随机混合和增强可以从单个纹理生成不同的异常图像 ( 见图 ) 。 原始异常源图像 ( 左 ) 可以被多次放大 ( 中 ) 来生成各种各样的模拟异常区域 ( 右 ) 。
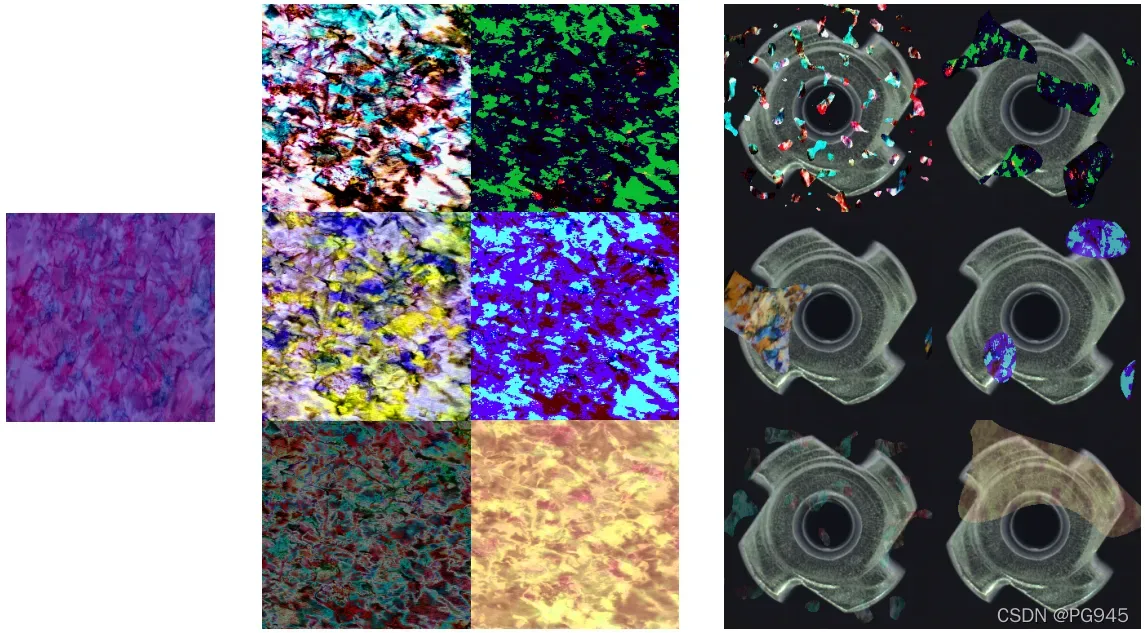
因此,上述的模拟器生成包含原始无异常图像的训练样本三组,包含模拟异常 Ia 和像素完美异常掩模 Ma 的增强图像。
表面异常定位和检测
判别子网络的输出是一个像素级异常检测掩膜 Mo ,可以直接被解释为图像级异常得分估计,即图像中是否存在异常。首先,利用均值滤波卷积层对 Mo 进行平滑处理,聚合局部异常响应信息 ; 对平滑后的异常分数图取最大值,计算最终的图像级异常分数η :
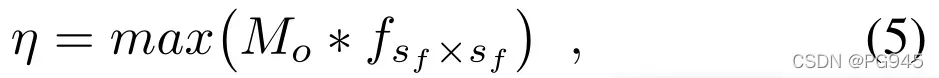
其中fsf ×sf是大小为 sf ×sf的平均过滤器,∗是卷积运算。在一项初步研究中,作者训练了一个分类网络用于图像级异常分类,但没有观察到直接评分估计方法的改进。
部分训练代码展示:
import torch
from data_loader import MVTecDRAEMTrainDataset
from torch.utils.data import DataLoader
from torch import optim
from tensorboard_visualizer import TensorboardVisualizer
from model_unet import ReconstructiveSubNetwork, DiscriminativeSubNetwork
from loss import FocalLoss, SSIM
import os
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
def train_on_device(obj_names, args):
if not os.path.exists(args.checkpoint_path):
os.makedirs(args.checkpoint_path)
if not os.path.exists(args.log_path):
os.makedirs(args.log_path)
for obj_name in obj_names:
run_name = 'DRAEM_test_'+str(args.lr)+'_'+str(args.epochs)+'_bs'+str(args.bs)+"_"+obj_name+'_'
visualizer = TensorboardVisualizer(log_dir=os.path.join(args.log_path, run_name+"/"))
model = ReconstructiveSubNetwork(in_channels=3, out_channels=3)
model.cuda()
model.apply(weights_init)
model_seg = DiscriminativeSubNetwork(in_channels=6, out_channels=2)
model_seg.cuda()
model_seg.apply(weights_init)
optimizer = torch.optim.Adam([
{"params": model.parameters(), "lr": args.lr},
{"params": model_seg.parameters(), "lr": args.lr}])
scheduler = optim.lr_scheduler.MultiStepLR(optimizer,[args.epochs*0.8,args.epochs*0.9],gamma=0.2, last_epoch=-1)
loss_l2 = torch.nn.modules.loss.MSELoss()
loss_ssim = SSIM()
loss_focal = FocalLoss()
# dataset = MVTecDRAEMTrainDataset(args.data_path + obj_name + "/train/good/", args.anomaly_source_path, resize_shape=[256, 256])
dataset = MVTecDRAEMTrainDataset(args.data_path + obj_name + "D:/CODE/DRAEM-main/dataset/good", args.anomaly_source_path,resize_shape=[256, 256])
# dataloader = DataLoader(dataset, batch_size=args.bs,
# shuffle=True, num_workers=16)
dataloader = DataLoader(dataset, batch_size=args.bs,
shuffle=False, num_workers=16)
n_iter = 0
for epoch in range(args.epochs):
print("Epoch: "+str(epoch))
for i_batch, sample_batched in enumerate(dataloader):
gray_batch = sample_batched["image"].cuda()
aug_gray_batch = sample_batched["augmented_image"].cuda()
anomaly_mask = sample_batched["anomaly_mask"].cuda()
gray_rec = model(aug_gray_batch)
joined_in = torch.cat((gray_rec, aug_gray_batch), dim=1)
out_mask = model_seg(joined_in)
out_mask_sm = torch.softmax(out_mask, dim=1)
l2_loss = loss_l2(gray_rec,gray_batch)
ssim_loss = loss_ssim(gray_rec, gray_batch)
segment_loss = loss_focal(out_mask_sm, anomaly_mask)
loss = l2_loss + ssim_loss + segment_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
if args.visualize and n_iter % 200 == 0:
visualizer.plot_loss(l2_loss, n_iter, loss_name='l2_loss')
visualizer.plot_loss(ssim_loss, n_iter, loss_name='ssim_loss')
visualizer.plot_loss(segment_loss, n_iter, loss_name='segment_loss')
if args.visualize and n_iter % 400 == 0:
t_mask = out_mask_sm[:, 1:, :, :]
visualizer.visualize_image_batch(aug_gray_batch, n_iter, image_name='batch_augmented')
visualizer.visualize_image_batch(gray_batch, n_iter, image_name='batch_recon_target')
visualizer.visualize_image_batch(gray_rec, n_iter, image_name='batch_recon_out')
visualizer.visualize_image_batch(anomaly_mask, n_iter, image_name='mask_target')
visualizer.visualize_image_batch(t_mask, n_iter, image_name='mask_out')
n_iter +=1
scheduler.step()
torch.save(model.state_dict(), os.path.join(args.checkpoint_path, run_name+".pckl"))
torch.save(model_seg.state_dict(), os.path.join(args.checkpoint_path, run_name+"_seg.pckl"))
if __name__=="__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--obj_id', action='store', type=int, required=True)
parser.add_argument('--bs', action='store', type=int, required=True)
parser.add_argument('--lr', action='store', type=float, required=True)
parser.add_argument('--epochs', action='store', type=int, required=True)
parser.add_argument('--gpu_id', action='store', type=int, default=0, required=False)
parser.add_argument('--data_path', action='store', type=str, required=True)
parser.add_argument('--anomaly_source_path', action='store', type=str, required=True)
parser.add_argument('--checkpoint_path', action='store', type=str, required=True)
parser.add_argument('--log_path', action='store', type=str, required=True)
parser.add_argument('--visualize', action='store_true')
args = parser.parse_args()
obj_batch = [['capsule'],
['bottle'],
['carpet'],
['leather'],
['pill'],
['transistor'],
['tile'],
['cable'],
['zipper'],
['toothbrush'],
['metal_nut'],
['hazelnut'],
['screw'],
['grid'],
['wood']
]
if int(args.obj_id) == -1:
obj_list = ['capsule',
'bottle',
'carpet',
'leather',
'pill',
'transistor',
'tile',
'cable',
'zipper',
'toothbrush',
'metal_nut',
'hazelnut',
'screw',
'grid',
'wood'
]
picked_classes = obj_list
else:
picked_classes = obj_batch[int(args.obj_id)]
with torch.cuda.device(args.gpu_id):
train_on_device(picked_classes, args)
文章出处登录后可见!