论文阅读笔记
1. title:基于文本加权词共现的跨语言文本相似度分析
Zhang Xiaoyu
中国传媒大学
软件指南
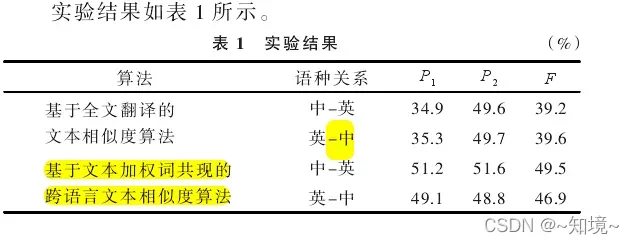
计算跨语言文本相似度的三种方法:
(1)基于全文机器翻译方法:把源语言和目标语言映射到中间语言
(2)基于统计翻译模型方法:建立两种语言之间生成翻译概念词典,因此要大规模对齐语料
(3)CL-ESA算法 explicit semantic analysis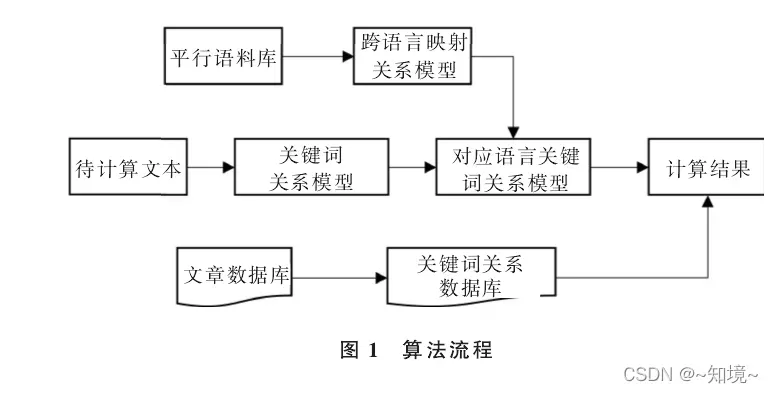
两个阶段:匹配阶段和映射阶段
跨语言映射关系模型
输入:平行语料库
输出:<源语F, 目标语言F’>映射关系


2. 结合预训练模型和语言知识库的文本匹配方法
中文信息学报 2020
哈尔滨工业大学
abstract
本文提出了一种将大规模预训练模型与外部语言知识库相结合的方法
1)在大规模预训练模型
3)文本匹配标注数据进行微调
数据集: MRPC\QQP
基于现有的大规模预训练模型框架集成外部语言知识库
这种外部语言知识库(wordnet、hownet)[5\6\7] — > 这些外部知识库如何使用?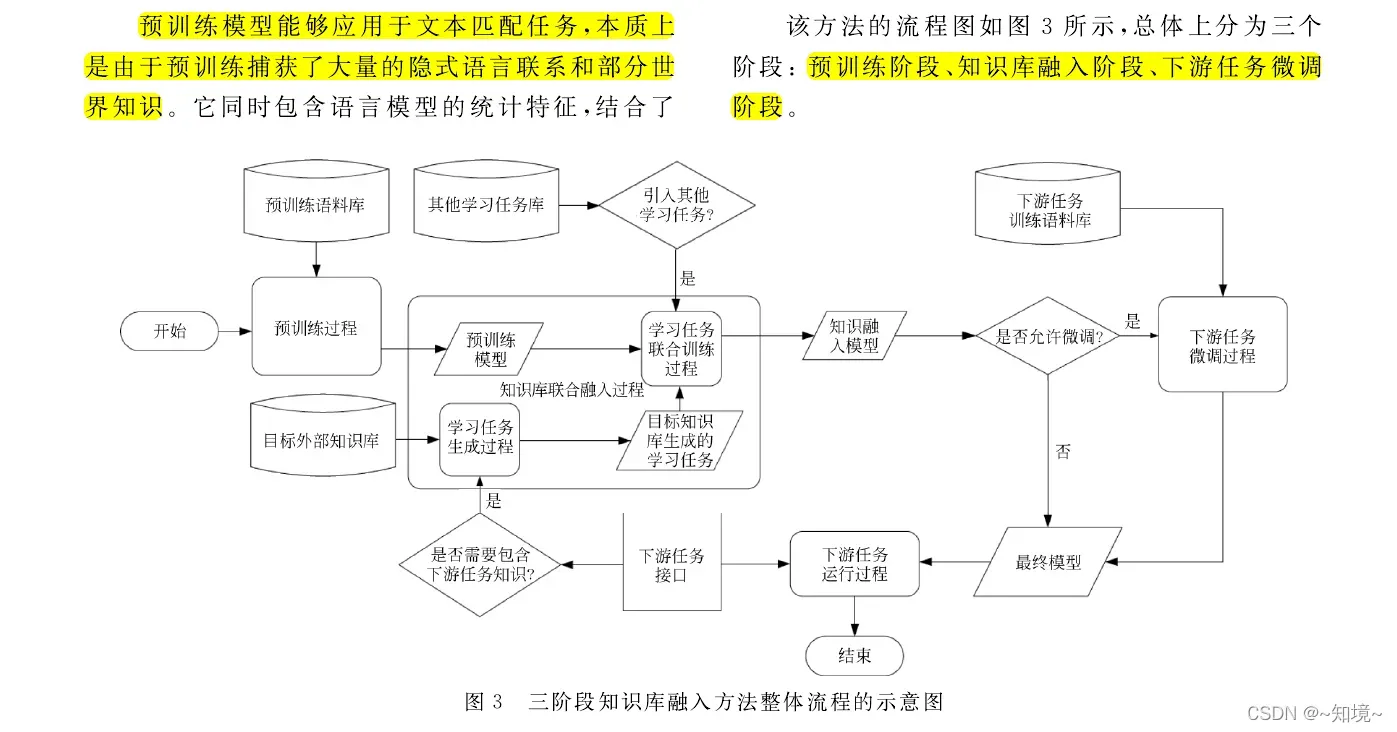
在wordnet找出同义词对、反义词对
短语固定搭配知识学习任务生成
2.4 bert存在的问题: 以token为输入和mask单位,每次mask 15%的词预测以学习语言模型,可能丢失某些固定词组的结构特征和隐式语义,或者需要大大增加捕捉改组合的信息所需的语料量和计算代价。
3. 中文长文本匹配算法研究
Guo Jiale
哈尔滨工业大学
论文
文本匹配任务本质上是判断源文本和目标文本的语义相似度
正确建模文本中包含的语义信息
难点:词句模棱两可,大量引用和遗漏;当文本长度较长时,文本中的单词、短语和句子的语义受复杂文章结果的影响很大
历史研究:
hierarchical structure表示文本,局表句子级别的层次信息; Liu [8]
Smash RNN 孪生多深度注意力机制的层次循环神经网络 Jiang [1]
Supervised Semantic Indexing SSI Bai [8]
Regularized Mapping to Latent Space 把文本表示进行震泽华隐空间映射 [19]
基于主题模型提出 双语主题模型对因空间进行概率建模 Gao[20]
CNTN模型 Qiu[21]
阿里巴巴 三种序列之间对其特征 [22]
Enhanced-RcNN [23] 短文本
分支思想将长文本转为多个关键词的匹配 Liu[24]
研究内容:
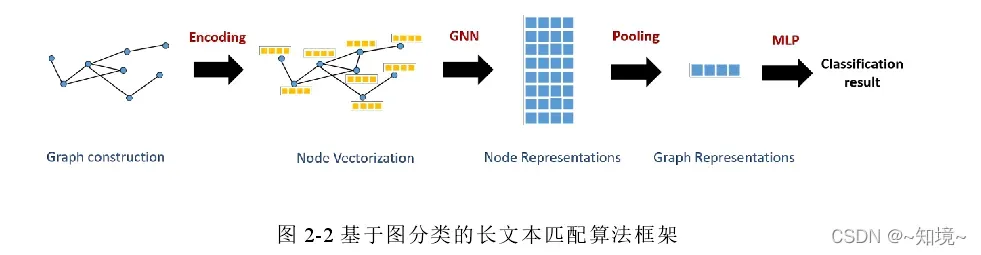
基于图分类框架的长文本匹配算法将长文本匹配任务等价转化为图分类任务,并利用图表示分析范式解决长文本匹配结果。


2.2 realted work
1.长文本表示学习
2
3 图表示学习 deepwalk 模型 + skip-gram ; LINE模型 ; Node2vec
方法介绍
文本对的图表示模型、基于图卷积神经网络的节点特征提取算法、基于注意力机制图神经网络的节点特征提取算法、图分类模型、损失函数
(1)文本对图表示模型
顶点的表示
用TextRank算法抽取文章中的NER和关键词, 因此图结构顶点就是文章中所出现的关键词表示; 把句子分配给相关词最高的关键词,每个句子只隶属于一个顶点。 每个顶点包含一个句子子集 。
原文说明:

(2)顶点的编码
对顶点进行编码,有两种方法第一种DNN、第二种TS(基于词项相似度)
DNN 用cnn或者lstm
(3)边的表示
2.3.2 基于图卷积神经网络的节点特征提取算法
基于自注意力机制的节点图神经网络
1) 基于相似度计算的自注意力机制
2)基于学习的自注意力机制
2.3.4 图分类模块
二分类网络, MLP
数据: CNSE,CNSS
4 using Prior Knowledge to Guide BERT’s Attention in Semantic Textual Matching Tasks
author: Xia
auth: jielin
part3 what has bert already know about semantic textual similarity
数据集: MRPC
(1)data Augmentation study
a. split and swap: 如何做到切分或者交换后 语义不变,那只能改变部分单词的位置?
b. add random word:
c. back translation
d. add high-tfidf word: find the w
e. delte low-tfidf word
f. replace synonyms
(2)Layer-wise Perfomance study、
科学问题:跨语言语义相似度计算
回到如何更好地编码句子向量?
创新的新研究要做:
- 数据预处理:
- 编码:
- 关于相似度计算的问题?
5 机器翻译书籍(肖桐)
part IV 机器翻译前沿
无监督机器翻译
无监督字典归纳:处理不同的语言见词级翻译任务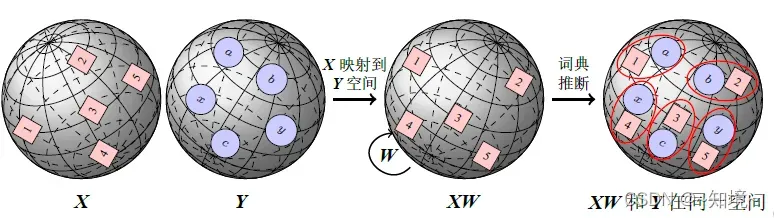

文章出处登录后可见!