LETR: Line Segment Detection Using Transformers without Edges
基于vision-transformer/DETR 提取wireframe的网络框架,截止日前实现了sota性能。
论文:https://arxiv.org/abs/2101.01909
代码:https://github.com/mlpc-ucsd/LETR
这部分是论文的解读:
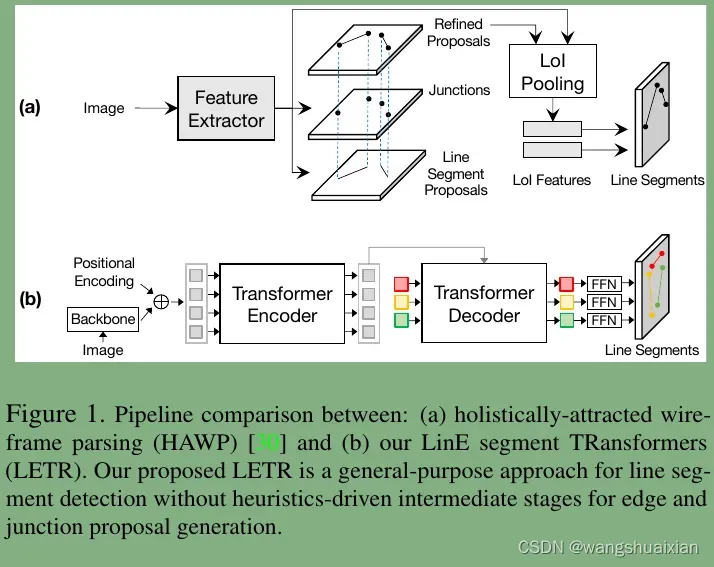
该论文是DETR在wireframe 数据集任务上的变体迁移,也是vision transformer在wirefame上的成功尝试,实现了wreframe 检测任务的sota性能,DETR论文及代码的介绍参考
【vision transformer】DETR原理及代码详解(一)_wangshuaixian的博客-CSDN博客_detr代码详解
【vision transformer】DETR原理及代码详解(三)_wangshuaixian的博客-CSDN博客
【vision transformer】DETR原理及代码详解(四)_wangshuaixian的博客-CSDN博客
LETR论文:
(1)摘要
本文提出了一种利用transformer 机制的端到端的全局线段提取网络。它不需要后处理以及中间的启发式引导。LETR取自LinE segment TRansformers,利用DETR中的三个高明之处即集成化编码和解码的tokenized查询,自注意力和联合查询,解决了该领域的三个问题:边缘元素检测,感知聚合和全局推断。
transformer通过分层的注意力机制逐步细化线段,省略了之前线段提取中的启发式设计。我们设计的transformer 配备有多尺度的encoder和decoder,直接利用端点距离损失训练—这尤其适用于实体(例如边界框无法方便表示的线段),最终实现细粒度的线段提取。
LETR在wireframe和YorkUrban数据集上显示了sota性能,也为联合端到端的通用实体检测(没法用标准物体检测框表示)指明了方向。
(2) 创新点
LETR 跳过了传统的边缘/连接/区域检测+proposals+感知分组pipline,设计了一个通用的全局端到端线段分割的目标检测算法。LETR论文灵感来自于:transformer框架中的具有集成编码和解码功能的标记化查询,自注意力机制,匈牙利匹配算法的隐式覆盖了线段检测中的(信息检测、感知分组和整体评估)的重要内容。
(3)主要贡献
除以上提到的两点外, 本文针对DETR框架的创新:
LETR在DETR 中引进了两个新的算法,
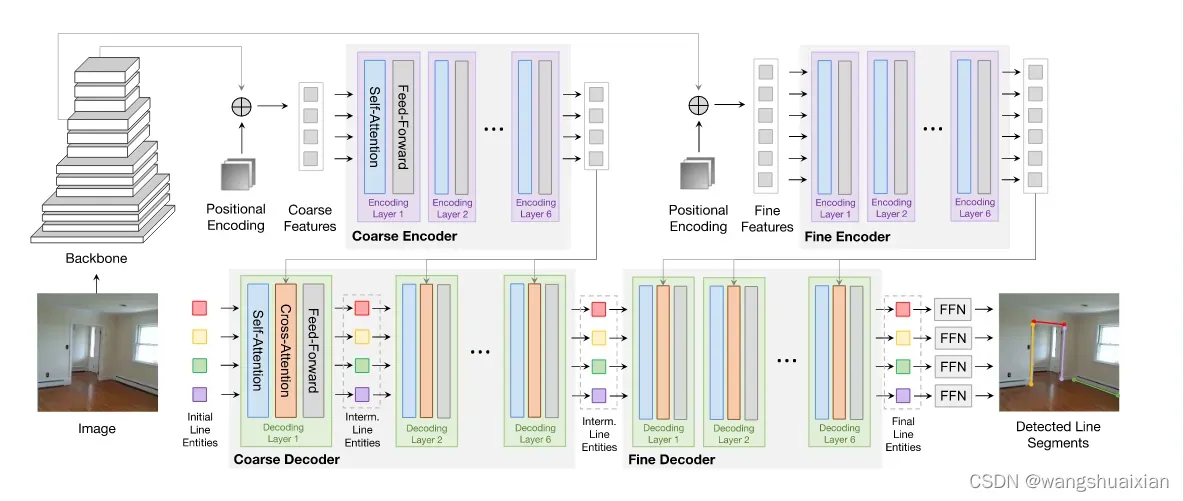
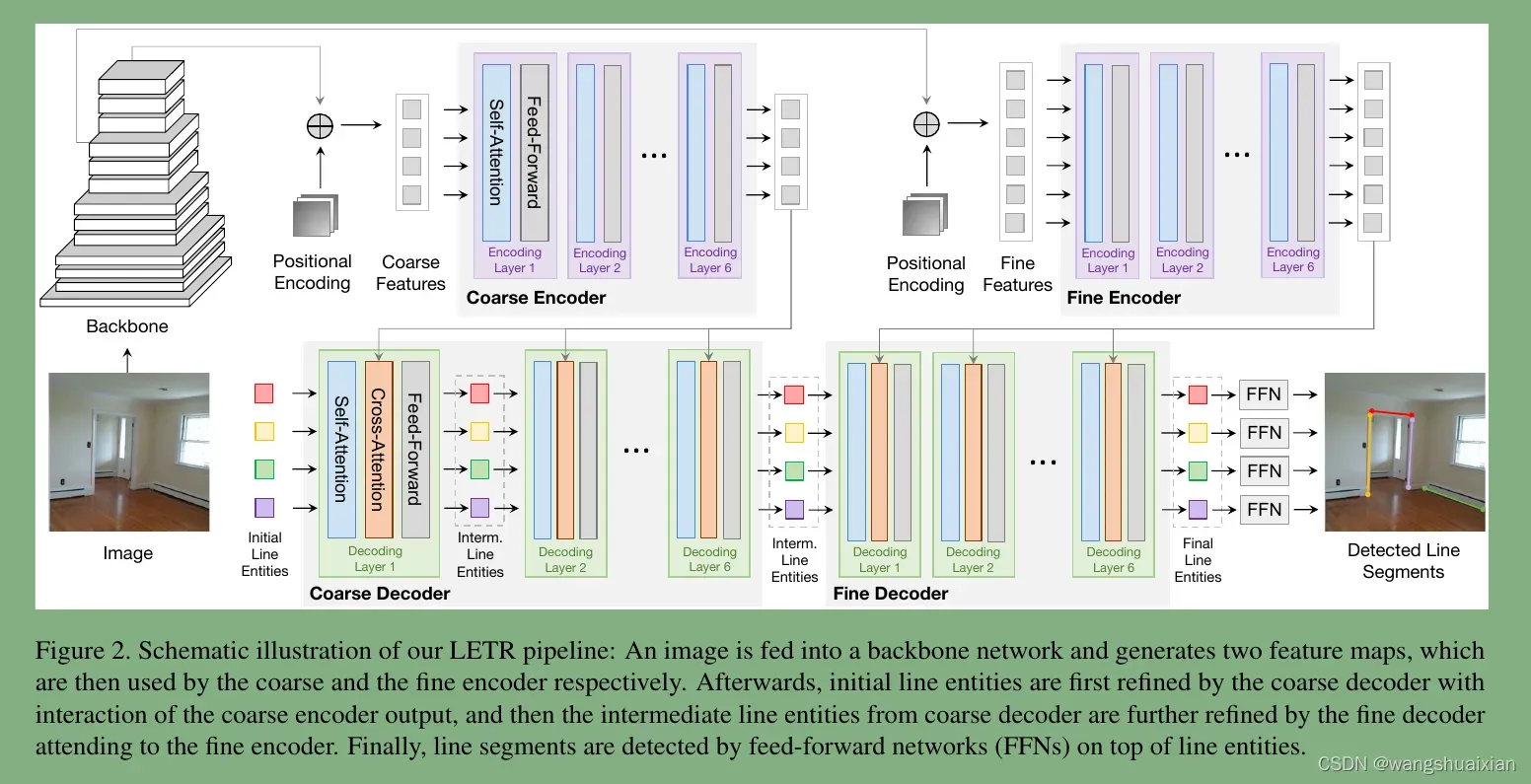
第一:多尺度的编码器/解码器,如下图所示,多尺度的encoder/decoder分阶段处理再融合,提高线段检测的精度;
第二:训练时直接用端点距离作为损失函数,解决了像线一样无法用标准bbox 表示特征的实体利用transformer框架检测的障碍。
(4)LETR流程
(1)Image feature extraction:
输入一张图像,通过cnn backbone 降维获得图像深度特征map :(h×w×c)
(2)Image feature encoding:
图像深度特征map flattened后维度为:(hw×c),然后通过多头注意力机制encode为
(hw×c),然后喂入FFN层。
(3)Line segment detection:
在transformer 解码阶段,N可学习的线段候选(N×C)通过交叉注意力机制与encoder 的输出交互。
( 4)Line segment prediction:
在transformer decoder 的顶层用两个预测头实现线段预测。线坐标通过多层感知机MLP预测,置信度通过线性层打分。
(5)挖掘点
self-attention and cross-attention(自注意力和交叉注意力)
Transformer encoder
Transformer decoer
Coarse-to-Fine Strategy (由粗到细的策略)
Biparttite Matching
(6)损失函数: Line segment losses
classification loss: binary cross-entropy loss
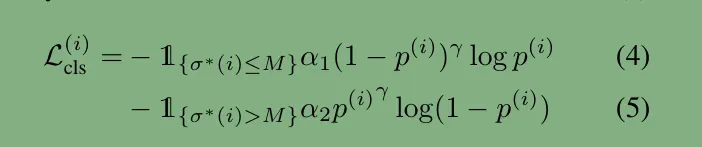
distance loss:L1 loss 用来回归线段的端点
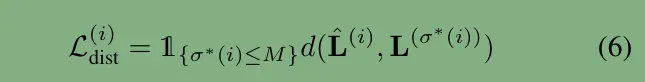
LERT最后删除了DETR 中的GIOU损失,因为GIOU是针对bbox的,采用损失为:
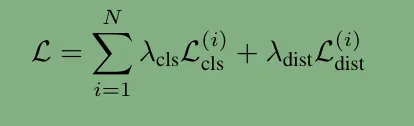
(5)LETR的实验结果:

文章出处登录后可见!