1 摘要
卷积块注意力模块是一种简单有效的前馈卷积神经网络。给定其中间一个映射,模块沿两个独立维度(通道和空间)顺序推断注意映射,然后讲注意映射乘以输入特征映射以进行自适应特征细化。
2 Introduction
contribution
①简单有效的注意模块,用于提高CNN表征能力
②通过广泛消融实验证明我的注意力机制有效性
③插入CBAM在多个基准上有很大的提高
3 Related work
从网络工程和注意力机制两方面论述
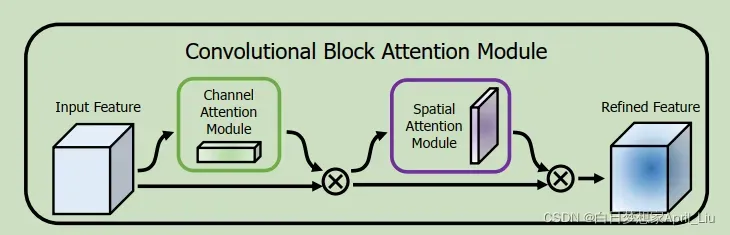
4 CBAM模型分析
(input)——>intermediate feature map——>(infer)1D channel attention map+2D spatial attention map
F1 = Mc(F) ⊗ F;
F2= Ms(F1) ⊗ F0;
其中:⊗按元素乘法,相应广播/复刻
4.1 通道注意力机制(CAM)
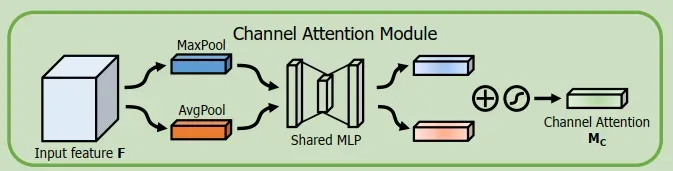
通道子模块利用共享网络的最大池化输出和平均池化输出。
4.2 空间注意力机制(SAM)
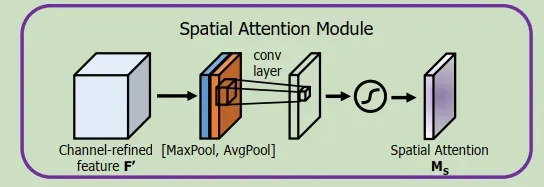
空间子模块利用沿信道轴汇集的两个类似输出,并将他们forward到卷积层。
首先使用平均池化和最大池化聚合特征映射的空间信息,生成两个不同的空间上下描述符。共享网络由多层感知机(MLP)和一个隐藏层组成,为了减少参数开销,将隐藏层激活大小设置为RC/R11.其中R是缩减率。将共享网络应用于每个描述符后,我们使用元素求合并输出特征向量。
通道注意力计算
Mc(F) = σ(MLP (AvgP ool(F)) + MLP (MaxP ool(F)))
= σ(W1(W0(Fc avg)) + W1(W0(Fc max)));
我们利用特征的通道间关系生成通道注意图。由于特征图的每个通道都被视为特征检测器,通道注意力集中在给定输入图像的“什么”是有意义的。为了有效地计算通道注意,我们压缩了输入特征映射的空间维度。为了聚合空间信息,到目前为止通常采用平均池。除了之前的工作,我们认为最大池收集了另一个关于不同对象特征的重要线索,以推断更精细的通道注意。因此,我们同时使用平均池和最大池特征。
空间注意力模块
利用特征间的空间关系生成空间注意图。与通道注意不同的是,空间注意侧重于“何处”是信息部分,与通道注意是互补的。为了计算空间注意,我们首先沿通道轴应用平均池和最大池操作,并将它们连接起来以生成有效的特征描述符。沿通道轴应用池操作可以有效地突出显示信息区域。
模块安排
给定一幅输入图像,通道和空间两个注意模块计算互补注意,分别关注“什么”和“哪里”。考虑到这一点,两个模块可以并行或顺序放置。我们发现顺序排列比平行排列效果更好。
总结
1.网络越深越宽,结构越复杂,注意力机制对网络影响越小。
2.在网络中加上CBAM不一定带来性能上的提升,对性能影响因素有数据集、网络自身、注意力所在位置。
3.建议在网络中加入SE系列,大部分有提升。
版权声明:本文为博主白日梦想家April_Liu原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_47345849/article/details/122542477