前言
因为Transformer在Vision中的应用效果很好,故开始阅读Transformer相关的论文。
论文原文:https://arxiv.org/pdf/1706.03762.pdf
一、摘要和介绍
在序列建模和转换问题中,由于RNN、LSTM和门控循环神经存在各种问题,如RNN难以建立长距离依赖关系,LSTM无法并行化学习等,故论文提出了一种基于attention机制并完全避免循环和卷积的简单的网络架构Transformer。
二、模型结构
模型结构如下图:
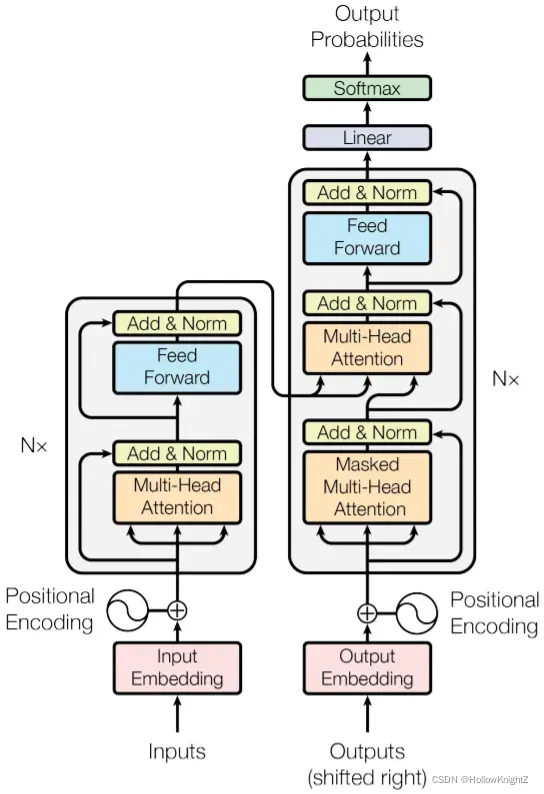
1. 编码器和解码器
编码器结构如下:
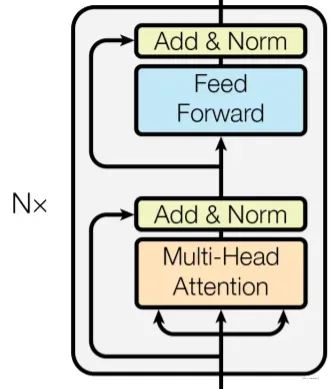
编码器由N = 6 个完全相同的层堆叠而成。每一层都有两个子层。
第一层是一个multi-head self-attention机制。
第二层是一个简单的、基于位置的全连接前馈网络。该前馈网络单独且相同地应用于每个位置。 它由两个线性变换组成,之间有一个ReLU激活。
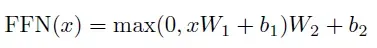
尽管线性变换在不同位置上是相同的,但它们使用层与层之间的不同参数。 它的另一种描述方式是两个内核大小为1的卷积。
对每个子层再采用一个残差连接 ,接着进行层标准化。为了方便这些残差连接,模型中的所有子层以及嵌入层产生的输出维度都为dmodel = 512。
这里的标准化(Normalization)是对同一sample进行标准化。如输入向量为:
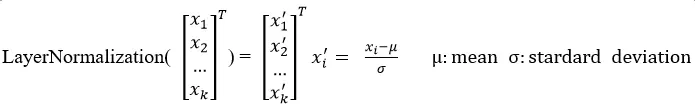
解码器结构如下:
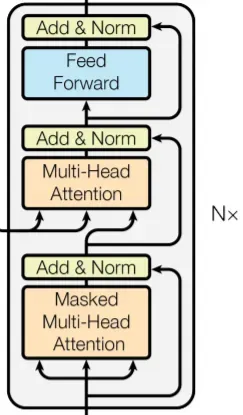
解码器同样由N = 6 个完全相同的层堆叠而成。 除了每个编码器层中的两个子层之外,解码器还插入第三个子层,该层对编码器堆栈的输出执行multi-head attention。 与编码器类似,在每个子层再采用残差连接,然后进行层标准化。同时还修改解码器堆栈中的self-attention子层,以防止位置关注到后面的位置。 这种掩码结合将输出嵌入偏移一个位置,确保对位置的预测 i 只能依赖小于i 的已知输出。
2.Attention
Attention函数可以描述为将query和一组key-value对映射到输出,其中query、key、value和输出都是向量。 输出为value的加权和,其中分配给每个value的权重通过query与相应key的兼容函数来计算。
2.1 Scaled Dot-Product Attention
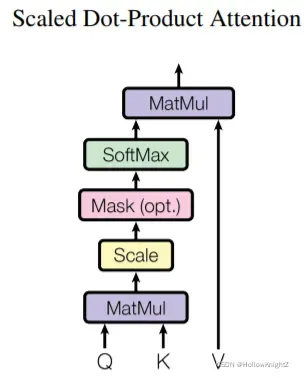
计算过程如下:
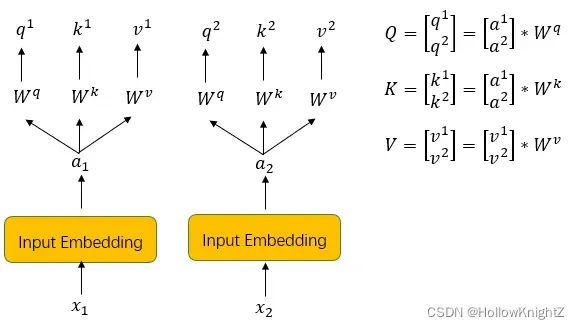
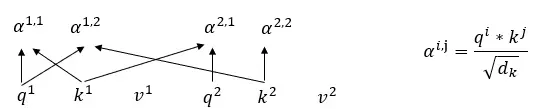
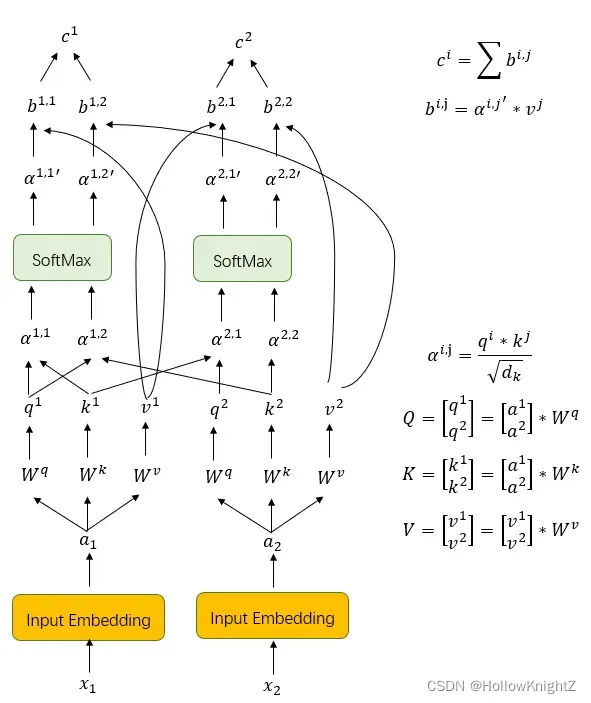
首先,输入X通过Input Embedding完成word2vec,得到向量A,A乘上Wq,Wk,Wv得到Q,K,V。Wq,Wk,Wv为共享参数,由训练得到;A=【a1,……ah】T,Q=【q1,……qh】T,K=【k1,……kh】T,V=【v1,……vh】T,如下图,以两个向量为例:
再将Q,K,V带入Scaled Dot-Product Attention公式计算得到Attention:
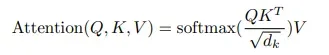
此公式又可拆分成:
(1)q 点乘(dot-product) k再缩小倍,
为k的维度,如例子中的为2。
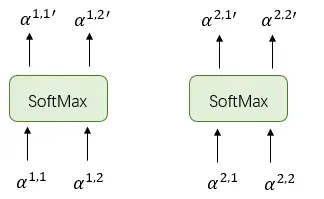
(2)将 以
为一组进行softmax得到
。
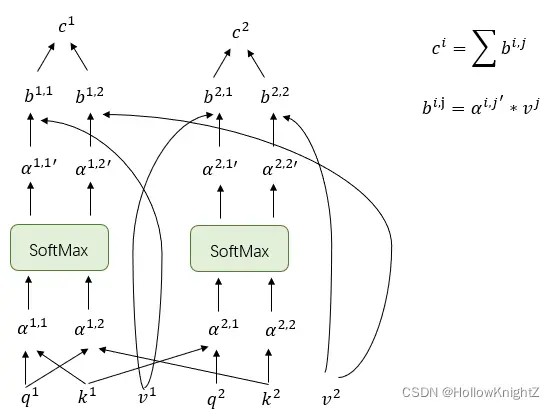
(3)将 点乘
得到
,最后将属于输入
的向量相加得到最终输出
。
完整计算思路如下:
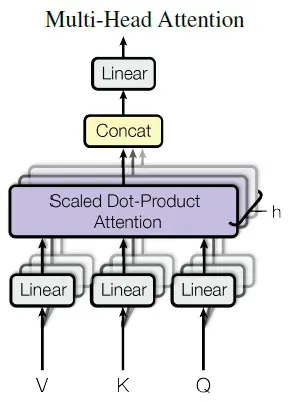
2.2 Multi-Head Attention
将query、key和value分别用不同的、学到的线性映射h倍到、
和
维效果更好,而不是用
维的query、key和value执行单个attention函数。 基于每个映射版本的query、key和value并行执行attention函数,产生
维输出值。 将它们连接并再次映射,产生最终值,如图所示:
计算公式如下:
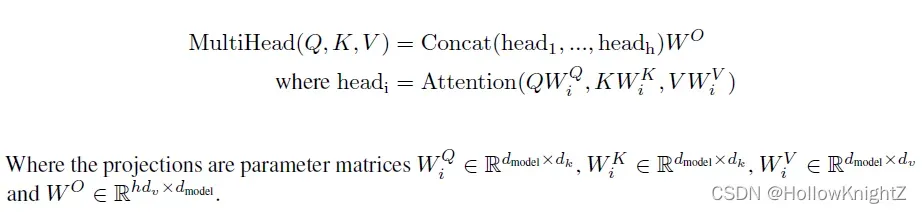
具体计算思路如下(以两个输入向量为例):
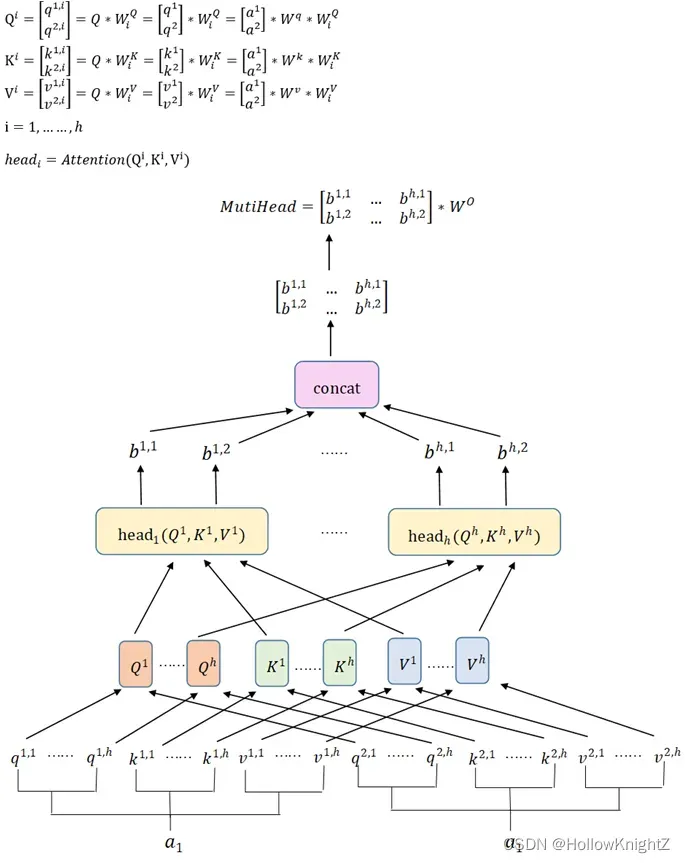
最后乘上是为了将concat之后的每个向量还原到
维。
2.3 Positional Encoding
Multi-Head Attention缺少位置的信息,为了让模型利用序列的顺序,必须注入序列中关于词符相对或者绝对位置的一些信息。
为每一个位置设定一个位置向量并加在embedding后的向量上。
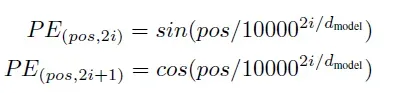
上个公式给出的每一个位置信息编码不是一个数字,而是一个不同频率(sin\cos)分割出来,和文本一样维度的向量。
三、Self-Attention在图像上的应用
Self-Attention是向量,可以将图像通道看成一个向量,将H×W×C的图像看成是H×W个向量,每个向量的维度为C来处理一张图片。
Self-Attention v.s. CNN
如果我们今天使用Self-Attention来处理一张图片,假设一个pixel产生query,其他pixel产生key,这时考虑的不再是图像中一个小范围的特征,而是整张影响的特征。而CNN每一个卷积核只考虑其感受野内的特征。此时,Self-Attention 是一个复杂化的CNN,相当于每一个卷积核的大小不再是人为设定,而是通过query和key的匹配训练学习得到。
版权声明:本文为博主HollowKnightZ原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Z960515/article/details/122546170