免费获得回归神经网络中的不确定性估计
给定正确的损失函数,标准神经网络也可以输出不确定性
每当我们构建机器学习模型时,我们通常会设计成输出一个数字作为预测。 scikit-learn 中的大多数模型都是这样工作的:基于树的模型、线性模型、最近邻算法等等。 XGBoost 和其他增强算法以及深度学习框架(如 Tensorflow 或 PyTorch)也是如此。[0][1][2][3]
虽然这通常很好,但最好也围绕这个点估计来衡量不确定性。这是因为“我们将销售 1000±50 辆汽车”和“我们将销售 1000±5000 辆汽车”之间的差异是巨大的:从第一个陈述中,您可以得出结论,该公司将销售大约 1000 辆汽车,给予或接受,而第二个陈述告诉你模型根本没有线索。
注意:较低的不确定性并不意味着模型是正确的。作为人,它也可能对完全错误的事情非常固执己见。因此,像往常一样,评估模型的质量是必不可少的,在这种情况下也是如此。
贝叶斯推理
如果您阅读了我关于贝叶斯推理的文章(谢谢!),您已经知道如何创建不仅输出单点,而且输出完整目标分布的模型。
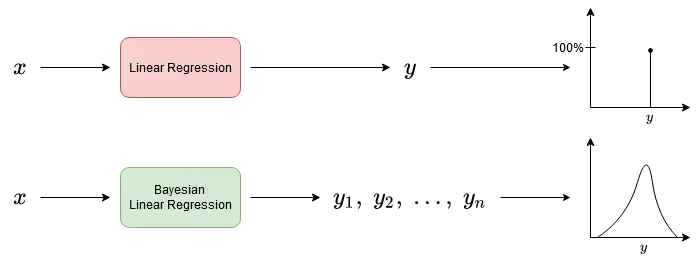
正因为如此,我们可以通过查看预测分布或一些派生数字(例如标准差)来了解模型何时不确定。分布越窄(标准差越小),模型越确定。
但是,这次我们不会在这里使用贝叶斯。虽然贝叶斯推理是一个你应该在某个时候学习的好领域,但它有几个缺点:
- 它在计算上比神经网络更复杂
- 在数学上更难理解,并且
- 你必须了解新的图书馆。
因此,本文适用于了解他们的深度学习框架并希望轻松包含一些不确定性估计的人。但是,如果您想在某个时候进入完全贝叶斯神经网络的领域,请尝试使用 Tensorflow Probability 或 Pyro for PyTorch 等库。[0][1]
让神经网络揭示它们的不确定性
免责声明:同样,我不知道以下方法是否在任何论文或书籍中提出。它刚刚浮现在我的脑海,我想写下它。如果您知道任何来源,请在评论中给我提示,我将其添加到文章中。谢谢!
从现在开始,让我们继续使用我们最喜欢的面包和黄油神经网络。我将在本文中使用 TensorFlow 代码,但您也可以轻松地将所有内容调整为 PyTorch 或其他框架。我们将在这里考虑回归问题,但也可以为分类任务提出类似的论点。
推导均方误差
为了了解如何获得不确定性估计,我们必须先了解如何获得点估计。然后,我们将以一种简单的方式概括这个想法。因此,简要回顾一下,以下是均方误差 (MSE) 损失函数:
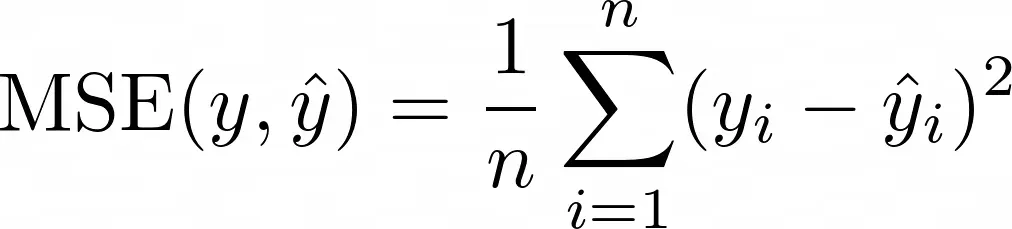
直观地说:某个真实值 yᵢ 与模型的预测 ŷᵢ 之间的差距越大,损失就越高。但是,当用指数中的 4 替换 2 时,我们可以以同样的方式争论。或删除 2 并使用绝对值 |yᵢ – ŷᵢ|相反(平均绝对误差,MAE)。[0]
那么,MSE有什么特别之处呢?有哪些假设?让我们来了解一下。 ⚠️危险:数学超前。如果这太多,只需跳到实施部分。结果很容易应用,即使你还不能遵循理论。⚠️
假设如下:
给定输入特征 x,真实标签 y 根据均值 μ(x) 和标准差 σ 的正态分布分布,即 y~N(μ(x), σ²)。这意味着观察到的标签来自某个真实值 μ(x),但由于标准偏差为 σ 的某些错误而被破坏。此错误也称为噪声。请注意,我们经常写 ŷ 而不是 μ(x)。
神经网络(和大多数其他模型)的任务是在给定 x 的情况下预测这个 μ(x)。这使得预测平均而言是正确的,这是我们能做的最好的事情,因为我们无法预测噪声。现在,表达式 y~N(μ(x), σ²) 仅表示以下含义:
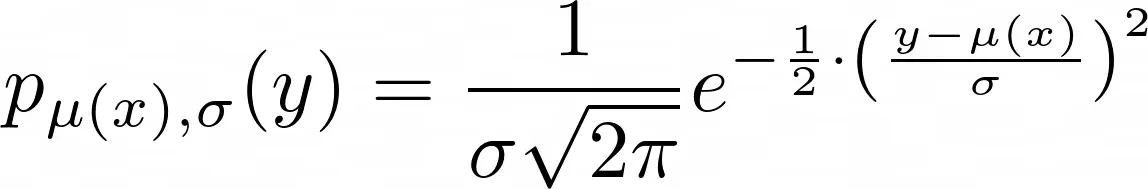
这只是正态分布的密度函数,其均值 ŷ=μ(x) 和标准差 σ 描述了单个标签 y 的分布。现在,我们没有一个观测值 y 及其对应的预测值 ŷ,而是几个,比如说 n。假设所有观察都是随机独立的,我们得到
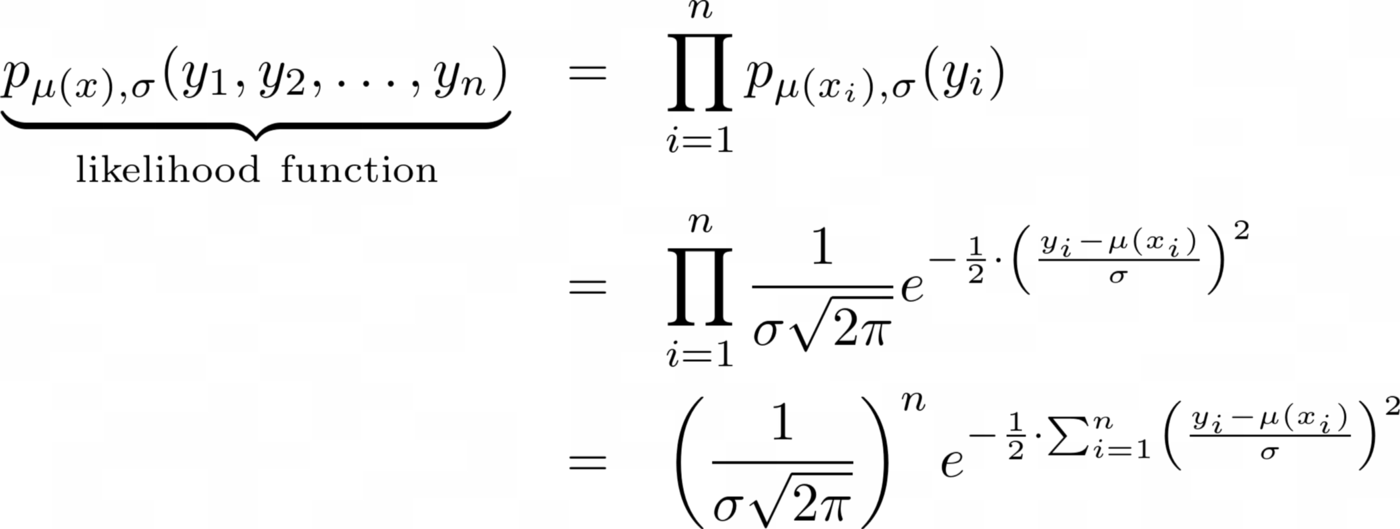
现在训练神经网络基本上意味着统计学家称之为最大似然估计的东西。这是一种奇特的说法,即我们想要最大化上述密度函数,也称为似然函数。
现在,我们可以将最大似然估计与 MSE 最小化联系起来,如下所示:
- 最大化似然函数
- 意味着最大化最右边的项
- 意味着最大化 e 的指数
- 意味着最小化指数中的总和,
- 意味着最小化 MSE(除以 n 不会改变最优参数)。
或作为图片:
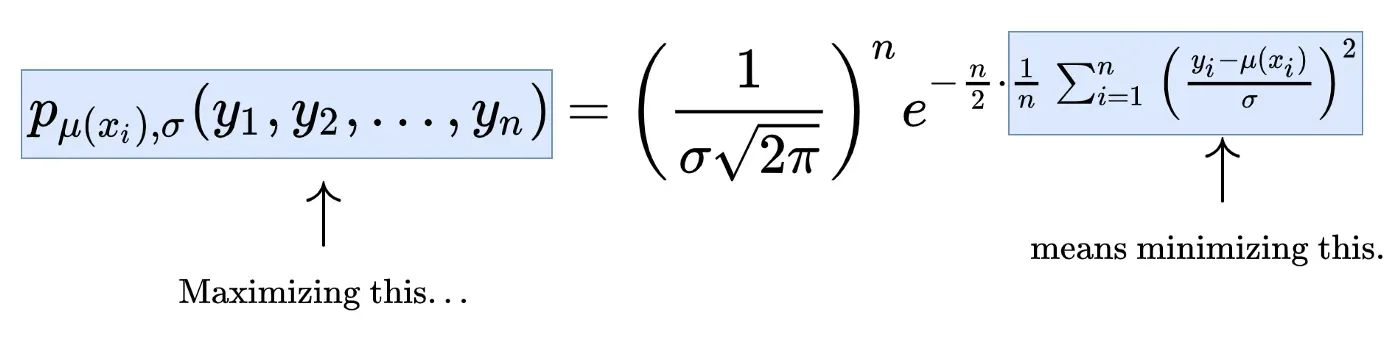
推广 MSE 损失
如果你在最后一节中幸存下来,那么恭喜你,你已经走得很远,你几乎达到了你的目标!我们只需要做一个简单的观察:
我们将 σ 视为一个常数,并且在进行最大似然法时基本上忽略了它。
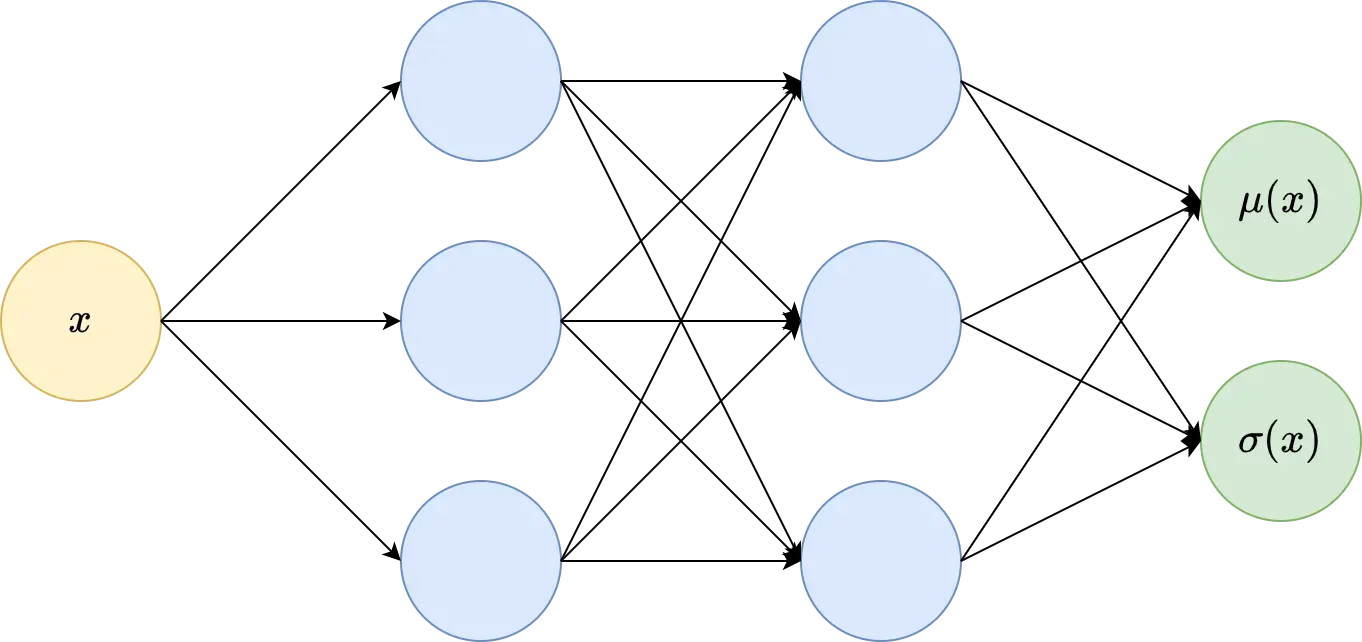
但是 σ 也正是我们想要估计的!这是因为它根据定义捕获了预测中的不确定性。那么,我们让我们的模型在 μ(x) 之外输出一个值 σ(x) 怎么样?这意味着即使对于简单的回归,模型也将有两个输出:一个是对真值 μ(x) 的估计,另一个是给定 x 的不确定性估计 σ(x)。
现在,我们可以将上述方程中的所有 σ 替换为 σ(xᵢ),我们最终得到以下语句:最大化似然函数意味着最大化项
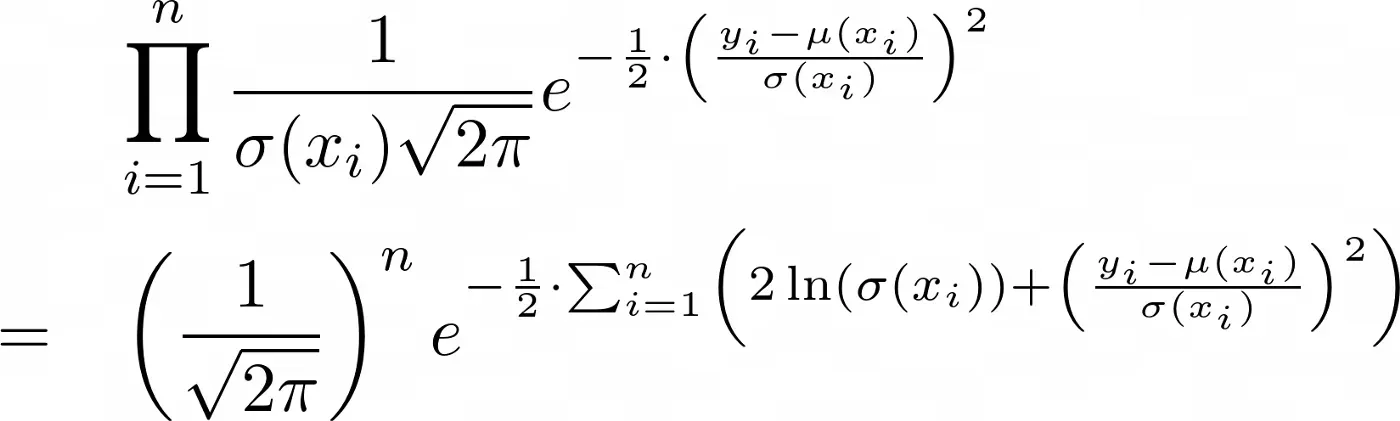
这反过来意味着最小化指数中的巨额总和,这是我们新推导出的损失函数(没有醒目的名称,请在评论中发表建议😉):
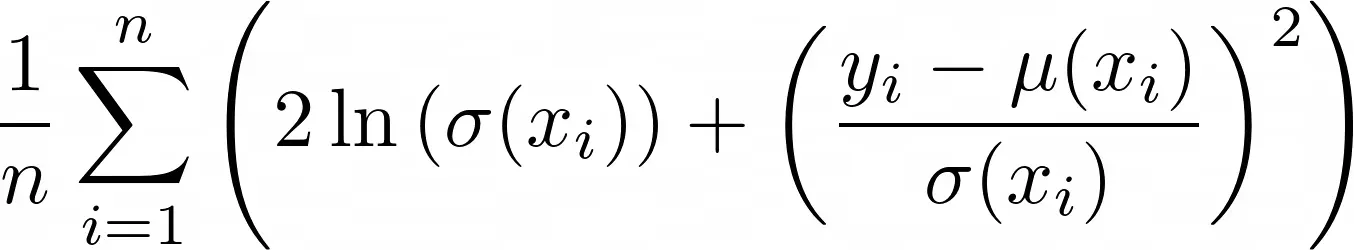
请注意,我偷运了一个 1/n,但这不会改变最佳解决方案,就像 MSE 的情况一样。
注意:这种损失有一些有趣的特性。首先,它仍然包含 MSE 位 (yᵢ – μ(xᵢ))²。此外,还有两项涉及 σ:ln(σ(x)) 以及 1/σ(x)。
为了保持低损失,模型不能输出非常大的 σ(x) 值,因为随着 σ(x) 的增长,ln(σ(x)) 也会增加。该模型也不能输出非常小的接近零的值,因为 1/σ(x) 项会变大。因此,模型被迫输出对 σ(x) 的合理猜测,以平衡这两项的惩罚。
只有当 (yᵢ — μ(xᵢ))² 很小,即预测值非常接近真实值时,模型才能输出一个小的标准偏差 σ(x)。在这种情况下,模型对其预测非常肯定。
好了,理论说完了。我们现在应该得到一些编码!
TensorFlow 中的实现
好的,所以我们已经了解到,我们需要两件事来使标准神经网络输出不确定性:
- 第二个输出节点包含预测的标准偏差(=不确定性)和
- 如上所述的自定义损失函数。
在您选择的任何深度学习框架中实现这两件事都应该很容易。我们将在 TensorFlow 中进行,因为上次我已经选择了 PyTorch 来解释可解释的神经网络。 😎
让我们从一个简单的例子开始。
恒定噪声
首先,我们将创建一个由 1000 个具有恒定噪声的点组成的玩具数据集,通过
import tensorflow as tftf.random.set_seed(0)X = tf.random.uniform(minval=-1, maxval=7, shape=(1000,))
y = tf.sin(X) + tf.random.normal(mean=0, stddev=0.3, shape=(1000,))
我们可以可视化这个数据集:
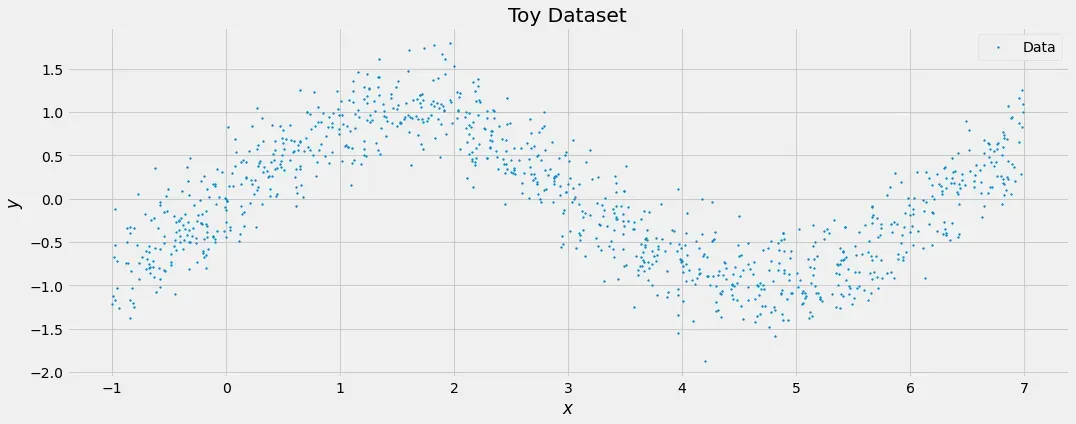
好的,所以它只是一个添加了 N(0, 0.3²) 分布噪声的正弦波。在最好的情况下,模型的实际预测遵循正弦波,而每个不确定性估计值约为 0.3。我们通过以下方式构建一个简单的前馈网络
model = tf.keras.Sequential([
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(2) # Output = (μ, ln(σ))
])好的,所以我们已经通过定义具有两个输出的神经网络来处理第一个要素。
为了简化计算,我们假设第二个输出不是直接的 σ(xᵢ),而是 ln(σ(xᵢ))。我们这样做是因为最后一层的两个神经元可以输出任意实数值,尤其是小于零的值,这对标准偏差没有意义。但是标准差的对数可以是任何实数,因此域匹配。无论如何,我们在损失函数中需要 ln(σ(xᵢ)),所以让我们开始吧。说到损失函数,我们可以通过
def loss(y_true, y_pred):
mu = y_pred[:, :1] # first output neuron
log_sig = y_pred[:, 1:] # second output neuron
sig = tf.exp(log_sig) # undo the log
return tf.reduce_mean(2*log_sig + ((y_true-mu)/sig)**2)其余的一切照旧。您使用此损失函数编译模型并进行拟合。
model.compile(loss=loss)model.fit(
tf.reshape(X, shape=(1000, 1)),
tf.reshape(y, shape=(1000, 1)),
batch_size=32,
epochs=100
)
让我们检查模型学习的不确定性估计:
print(tf.exp(model(X)[:20, 1]))# Output:
# tf.Tensor(
# [0.29860803 0.27371496 0.32216415 0.32288837 0.31084406 0.30166912
# 0.32059005 0.3331769 0.31244662 0.31863096 0.30940703 0.32042852
# 0.3231969 0.29584357 0.31141806 0.32493973 0.3169802 0.32060665
# 0.30542135 0.31733593], shape=(20,), dtype=float32)
对我来说看上去很好!该模型了解到噪声的标准偏差约为 0.3。这是模型所学内容的可视化:
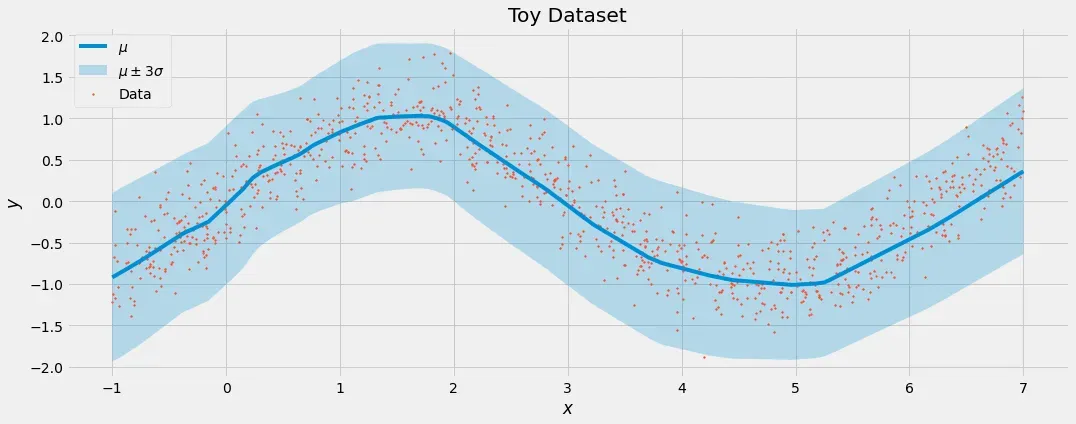
这就是我们喜欢它的方式。实际预测 μ 跟随数据,而不确定性 σ 刚好高到足以捕获标签 y 中的噪声。
变化的噪音
现在,我们通过引入非常量噪声(统计学家称之为异方差性)来使事情变得更有趣。看看这个:
tf.random.set_seed(0)X = tf.random.uniform(minval=-1, maxval=7, shape=(1000,))sig = 0.1*(X+1)
y = tf.sin(X) + tf.random.normal(mean=0, stddev=sig, shape=(1000,))
这将创建一个特征 X 中噪声增加的数据集。
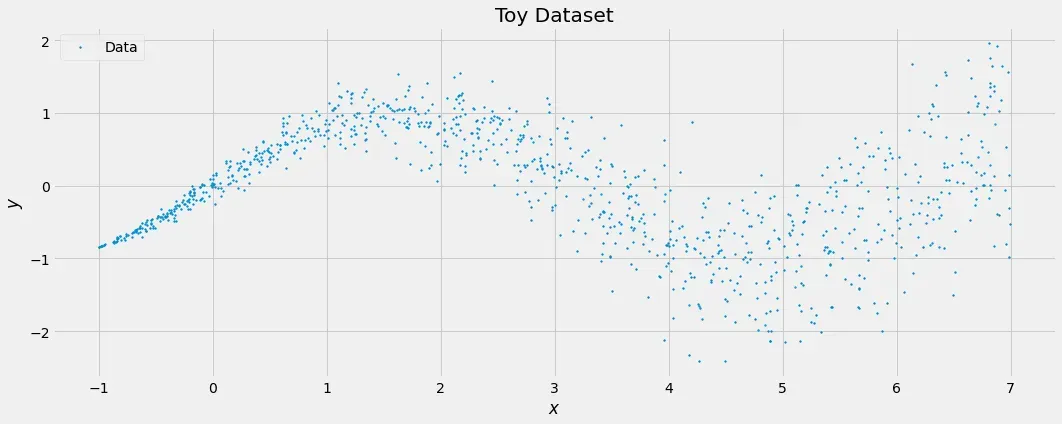
基本事实仍然是一样的:它是一个正弦波,模型应该能够捕捉到这一点。但是,模型还应该知道,X 值越高意味着不确定性越高。
剧透:如果您在新数据集上重新训练与上述相同的模型,这正是您将看到的。
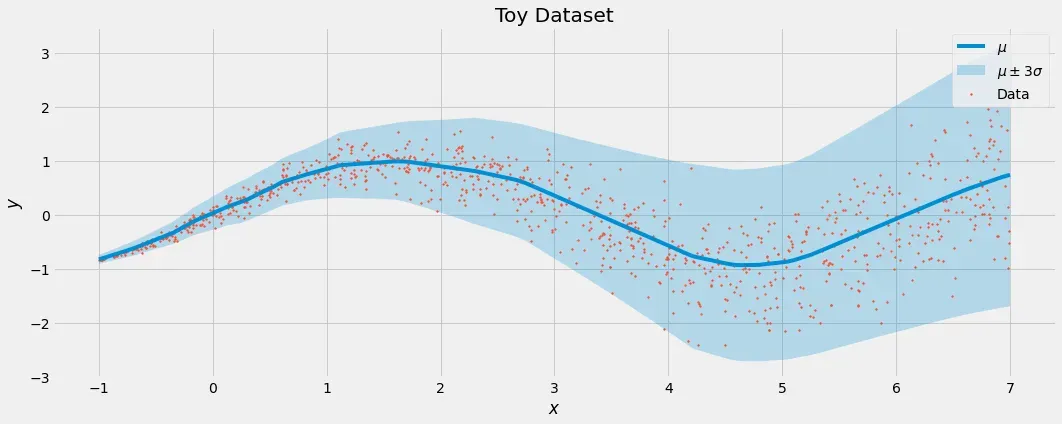
在我看来相当甜蜜。
Conclusion
在本文中,您学习了如何调整神经网络,以便它可以输出不确定性的估计值及其实际预测。它所需要的只是一个额外的输出神经元和一个仅比 MSE 稍微复杂一点的损失函数。
不确定性估计的好处在于,它们可以让你评估模型对其预测的信心——你知道你是否可以相信模型的预测。它们还允许您报告估计的下限或上限,这在计算最佳或最坏情况时非常有价值。
另一种获得不确定性估计的流行方法是使用贝叶斯推理。但是,数学涉及更多,并且比我在此处提供给您的解决方案要慢得多。此外,我发现目前用于(深度)贝叶斯学习的软件包不像 Tensorflow 或 PyTorch 那样容易使用,尽管当贝叶斯方法获得更多牵引力时,这可能会改变。不过,我喜欢这个话题,所以也看看吧! 😉
我在这里给你的是一个简单的工具,它可以让你避开贝叶斯的麻烦,不需要你在日常行为中做出太大的改变,同时还能让你从贝叶斯世界中受益匪浅。
我希望你今天学到了一些新的、有趣的和有用的东西。谢谢阅读!
最后一点,如果你
- 想支持我写更多关于机器学习和
- 无论如何都计划获得中等订阅,
为什么不通过这个链接呢?这对我有很大帮助! 😊[0]
为了透明,你的价格没有改变,但大约一半的订阅费直接给我。
非常感谢,如果你考虑支持我!
如果您有任何问题,请在 LinkedIn 上写信给我![0]
文章出处登录后可见!