Statsmodel线性回归模型总结的简单解释
Statsmodel库模型总结说明

Introduction
回归分析是许多统计学家和数据科学家的生计。我们出于预测的目的执行简单和多元线性回归,并且总是希望获得一个没有任何偏差的稳健模型。在本文中,我将使用一个简单的示例讨论 python 的 statsmodel 库的摘要输出,并解释一下这些值如何反映模型性能。
典型机型汇总
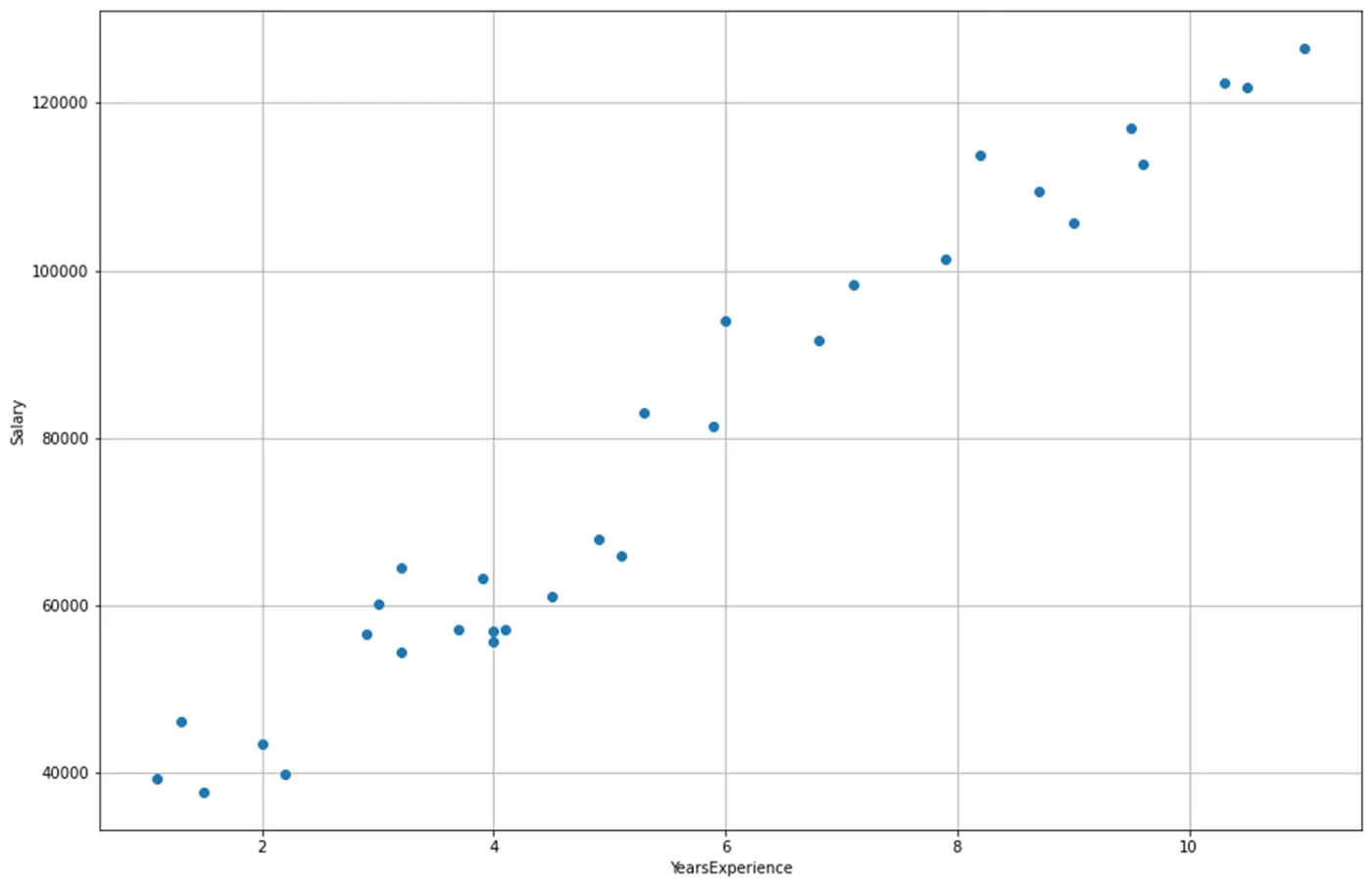
出于演示的目的,我将使用 kaggle 的 Salary 数据集(Apache 2.0 开源许可)。该数据集有两列:年经验和薪水。我还有两个两列:Projects 和 People_managing。[0][1]
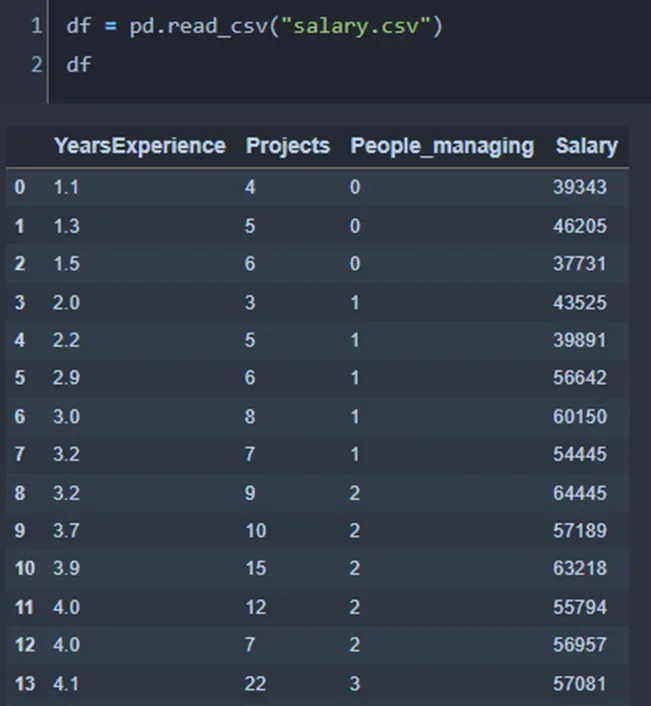
当我们使用 statsmodel 使用所有三个变量来预测 Salary 时,我们得到以下汇总结果。
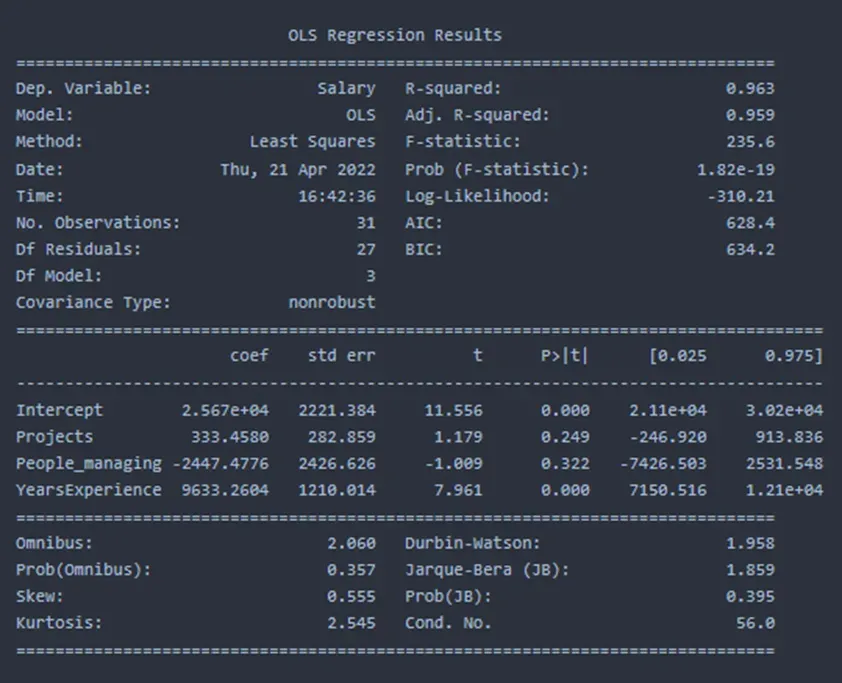
我将在下面的摘要中解释所有这些参数。
深度变量
“薪水”是数据中唯一的因变量。
模型与方法
OLS 代表普通最小二乘。该模型试图找出数据集的线性表达式,以最小化残差平方和。
DF残差和DF模型
我们总共有 30 个观察和 4 个特征。在 4 个特征中,3 个特征是独立的。因此 DF 模型为 3。DF 残差是根据总观察值 -DF 模型 1 计算的,在我们的例子中为 30-3-1 = 26。
协方差类型
协方差类型通常是非稳健的,这意味着没有消除数据来计算特征之间的协方差。协方差显示两个变量如何相对于彼此移动。如果该值大于 0,则两者都沿相同方向移动,如果该值小于 0,则变量以相反方向运行。协方差是与相关性的差异。协方差不提供关系的强度,仅提供运动的方向,而相关值是标准化的,范围在 -1 到 +1 之间,相关性提供关系的强度。如果我们想获得稳健的协方差,我们可以声明 cov_type=HC0/HC1/HC2/HC3。但是,statsmodel 文档并不能解释所有这些。 HC 代表异方差一致,HC0 实现了最简单的版本。
R-squared
R平方值是确定系数,表示如果数据由所选自变量解释,则可变性百分比。
调整。 R平方
随着我们向模型中添加越来越多的自变量,R 平方值会增加,但实际上,这些变量不一定对解释因变量有任何贡献。因此,添加每个不必要的变量需要某种惩罚。当包含多个变量时,会调整原始 R 平方值。本质上,我们应该在执行多元线性回归时始终寻找调整后的 R 平方值。对于单个自变量,R 平方和调整后的 R 平方值相同。
在转向 F 统计量之前,我们需要先了解 t 统计量。下表提供了 T 统计量。
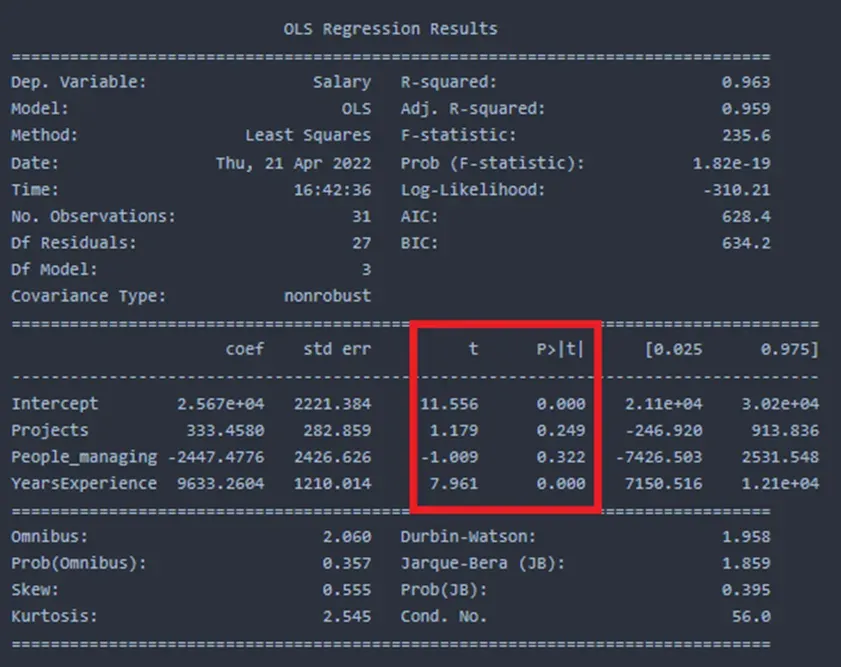
coef 和 std 错误
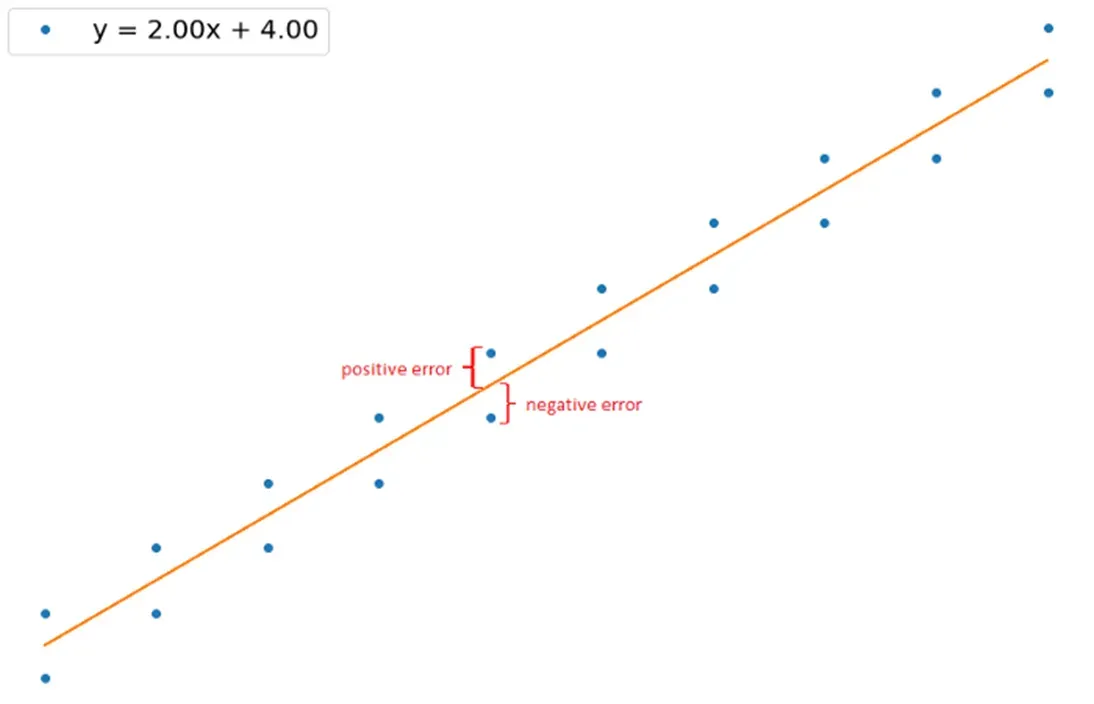
coef 列表示每个自变量的系数以及截距值。 Std err 是所有数据点对应变量系数的标准差。当只使用一个预测变量时,可以从这个二维空间中得到标准误差,如下所示
t 值和 P>|t|
t 列提供对应于每个自变量的 t 值。例如,这里的 Projects、People_managing 和 Salary 都具有不同的 t 值以及与每个变量相关联的不同 p 值。 T 统计量用于计算 p 值。通常,当 p 值小于 0.05 时,它表明有强有力的证据反对零假设,即相应的自变量对因变量没有影响。 Projects 的 P 值 0.249 表明,Projects 变量有 24.9% 的可能性对薪水没有影响。 YearsExperience 的 p 值似乎为 0,表明 YearsExperience 的数据具有统计显着性,因为它小于临界限值 (0.05)。在这种情况下,我们可以拒绝原假设,并说 YearsExperience 数据显着控制了 Salary。
F-statistics
F检验提供了一种方法来检查所有自变量,如果其中任何一个与因变量相关。如果 Prob(F-statistic) 大于 0.05,则没有证据表明任何自变量与输出之间存在关系。如果小于 0.05,我们可以说至少有一个变量与输出显着相关。在我们的示例中,p 值小于 0.05,因此,一个或多个自变量与输出变量 Salary 相关。我们之前已经看到 YearsExperience 与 Salary 显着相关,但其他则不然。因此,F 检验数据支持 t 检验结果。但是,在某些情况下,prob(F-statistic) 可能大于 0.05,但其中一个自变量显示出强相关性。这是因为每个 t 检验都是使用不同的数据集进行的,而 F 检验检查包括全局所有变量的组合效应。
Log-likelihood
对数似然值是模型与给定数据拟合的度量。当我们比较两个或多个模型时,它很有用。对数似然值越高,模型越适合给定数据。它的范围可以从负无穷到正无穷。
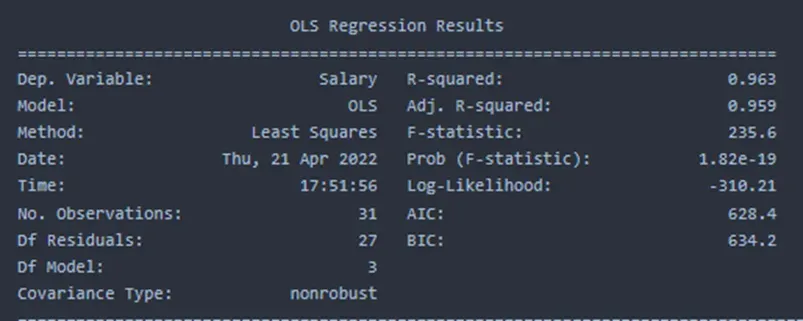
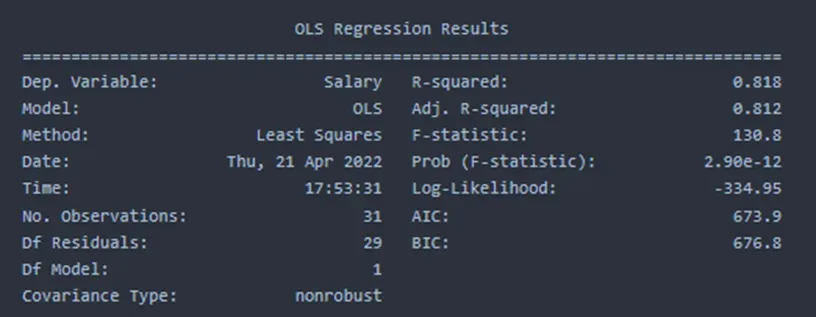
当模型中包含所有三个自变量时,对数似然值为 -310.21,高于仅包含 Projects 数据时的 -334.95。这意味着第一个模型更适合数据。如上所示,它还与 R 平方值密切相关。
AIC 和 BIC
AIC(代表日本统计学家 Hirotugo Akaike 开发的 Akaike 信息标准)和 BIC(代表贝叶斯信息标准)也被用作模型稳健性的标准。目标是最小化这些值以获得更好的模型。我有另一篇文章讨论了这些主题。
综合和概率(综合)
部署模型后,综合测试会检查残差的正态性。如果该值为零,则表示残差完全正常。在这里,在示例中 prob(Omnibus) 为 0.357,表明残差有 35.7% 的机会呈正态分布。为了使模型具有鲁棒性,除了检查 R 平方和其他量规之外,还要求残差分布在理想情况下是正态的。换句话说,当根据拟合值绘制残差时,残差不应遵循任何模式。
偏斜和峰度
偏度值告诉我们残差分布的偏度。正态分布变量的偏斜值为 0。峰度是与正态分布相比的轻尾或重尾分布的量度。峰度高表示分布太窄,峰度低表示分布太平。 -2 和 +2 之间的峰度值可以很好地证明常态。
Durbin-Watson
Durbin-Watson 统计量提供残差中的自相关度量。如果残差值是自相关的,则模型会出现偏差并且不是预期的。这仅仅意味着一个值不应依赖于任何先前的值。此测试的理想值范围为 0 到 4。
Jarque-Bera (JB) 和 Prob(JB)
Jarque-Bera (JB) 和 Prob(JB) 类似于测量残差正态性的 Omni 检验。
条件编号
高条件数表示数据集中可能存在多重共线性。如果仅使用一个变量作为预测变量,则该值较低,可以忽略。我们可以像逐步回归一样进行,看看在包含其他变量时是否添加了任何多重共线性。
Conclusion
我们已经讨论了来自 statsmodel 输出的所有摘要参数。这对于有兴趣检查所有量规以获得稳健模型的读者很有用。大多数时候,我们寻找 R 平方值以确保模型解释了大部分可变性,但我们已经看到有很多比那更多的。
谢谢阅读
Github页面[0]
优酷频道[0]
文章出处登录后可见!