content
regression error[0]
交叉熵 CE[0]
BCE[0]
CE[0]
Focal Loss[0]
Dice Loss[0]
Lovasz-Softmax Loss[0]
更多可见计算机视觉-Paper&Code – 知乎[0]
本文主要希望总结下目前学术与业界常用到的Loss函数以及其对应的优缺点
regression error
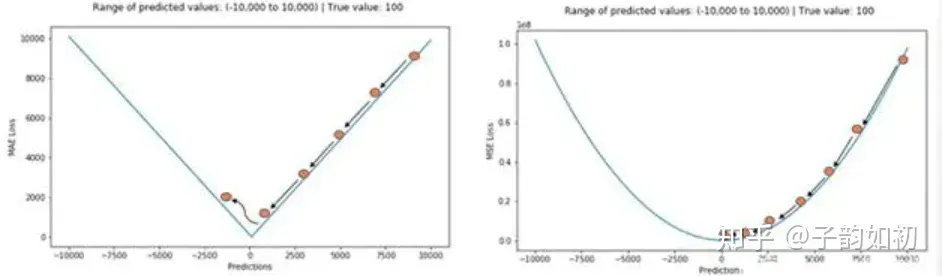
两种loss不同位置的梯度情况
MAE mean average error(L1损失)主要用于机器学习,回归问题中。均方误差对于异常值相对不敏感,但是由于他的梯度是一直不变的,即使loss很小梯度都非常大
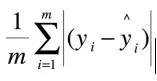
MSE mean square error(L2损失)主要用于机器学习,回归问题中。均方误差对于异常值特别敏感,因为影响是2次方
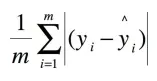
交叉熵 CE
BCE
因为需要保持输入输出都在0-1之间。BCE+sigmoid一般会同时出现。yi如果为0,那么就要求zi越接近为0才能保持loss更小。因为log(1-q(zi))总是小于0的
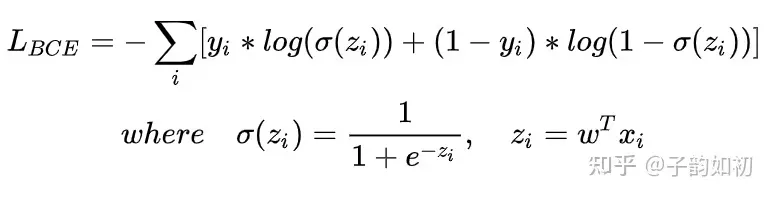
yi是GT值,zi是预测值
CE
ce主要用于多分类,其中yi是one hot编码。softmax主要作用就是将结果加和为1,且都是非负数,表示为该类的概率。一般来说为了解决正负样本不平衡的问题,通常也会在CE前添加权重
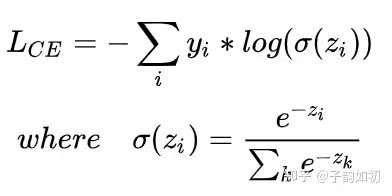
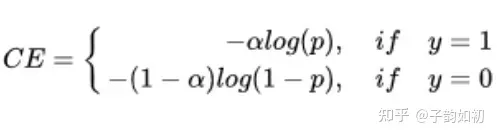
举个例子,加入target=[1,0],pred1=[-2,1],pred2=[-1,1]
y1 = exp(x1) = exp(-2) = 0.13
y2 = exp(x2) = exp(1) = 2.71
z1 = y1/(y1+y2) = 0.13/(0.13+2.71) = 0.045
z2 = y2/(y1+y2) = 4.48/(0.13+2.71) = 0.955
exp(-1)=0.36 -> 0.117 / 0.883
那么,可知pred2 loss更小

pred1=[-2,1]
# 如果是3张图片一起算,需要添加for循环单行计算
exp_res=np.exp(pred1)/np.sum(np.exp(pred1))
loss=-np.sum(target*exp_res)Focal Loss
子韵如初:Paper Reading – Loss系列 – Focal Loss for Dense Object Detection[0]
Dice Loss
语义分割中一般用ce来做损失函数,但评价的时候都主要看IOU指标,因此为什么不直接拿类IOU的损失函数来进行优化呢?Dice loss出现
Jaccard 系数大家都不陌生,可用于衡量相似度,不过更关注共同具有的特征是否一致。而dice系数表示两个物体相交的面积占总面积的比值,也用于比较两个样本的相似度。相当于分子分母都加了一个xy交集
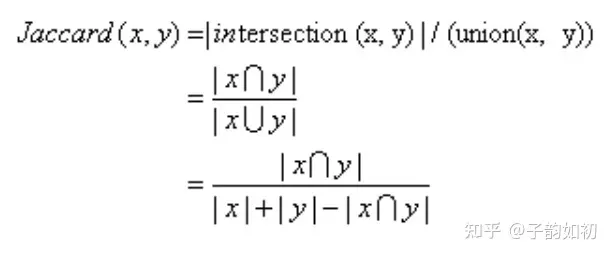
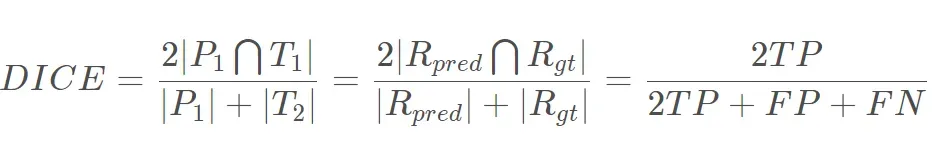
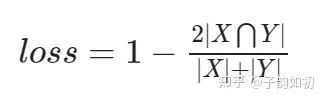
当然dice loss也是有缺点的
- 梯度形式更优,当x和y的为负样本值都非常小时,由于梯度计算中都需要进行平方,计算得到的梯度值可能会非常大。通常情况下,导致训练很不稳定。因此建议可以配合类ce为主loss进行训练,也可以通过设置class_weight对于样本更少的类别赋予给高的weight
- 类IoUloss中当前像素的loss不光和当前像素的预测值相关,和其他点的值也相关。可以理解为mask操作,固定大小的正样本的区域计算的loss是一样的,对网络起到的监督贡献也是一样的。训练更倾向于挖掘前景区域,所以当正样本为小目标时loss会产生严重的震荡。一旦有部分像素预测错误,那么就会导致loss值大幅度的变动。而对于ce loss,loss的值是总体求平均的,更多会依赖负样本的地方。

Lovasz-Softmax Loss
kaggle神奇,但是原理比较复杂,也基于IOU的loss
文章出处登录后可见!