0:介绍
- 数据集来自kaggle五种车辆目标检测
- 本文适合深度学习新手,希望尽快完成对自己数据的目标检测模型的训练。
- 本文利用paddle与paddlex框架实现。
- 文中重结果实现,无yolov3原理解释,可以看作黑盒操作。
- Dataset private chat
- 帮我助力一下!!!~ https://aistudio.baidu.com/aistudio/newbie?invitation=1&sharedUserId=130404&sharedUserName=%E4%B8%8B%E6%AC%A1V%E5%8F%91%E7%BB%99%E4%B8%8D
0.1:原始数据集

- Images-所有的图片
- test.csv-测试集的名称
- train.csv-训练集的名称(图1)
- train_boxes.csv-训练集标注数据,共有5钟标签(图2)
图1
图2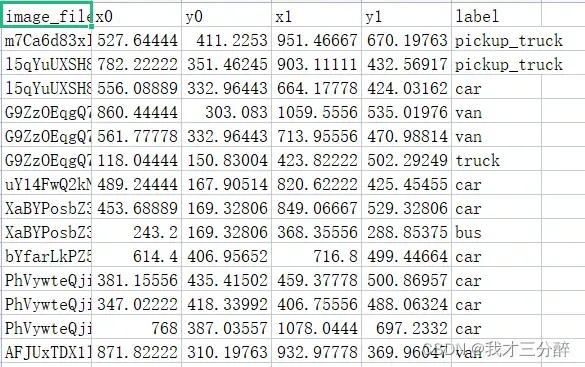
Dataset visualization:
0.2:改造数据集
0.2.0:VOC格式介绍
VOC格式是一种图片的标注规范,很多目标检测或者目标分割的算法都会遵循VOC标注规范的数据集,因此我们要先把数据集改造为标准的VOC格式。并把数据放在car_det目录下:
0.2.1:labels,train_list,val_list文件
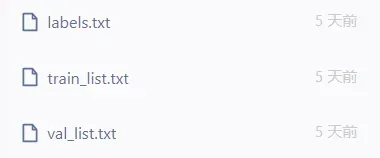
- labels.txt存放标签名称
- train_list.txt存放训练数据名称
- val_list.txt存放验证数据名称
不要将最后一行留空!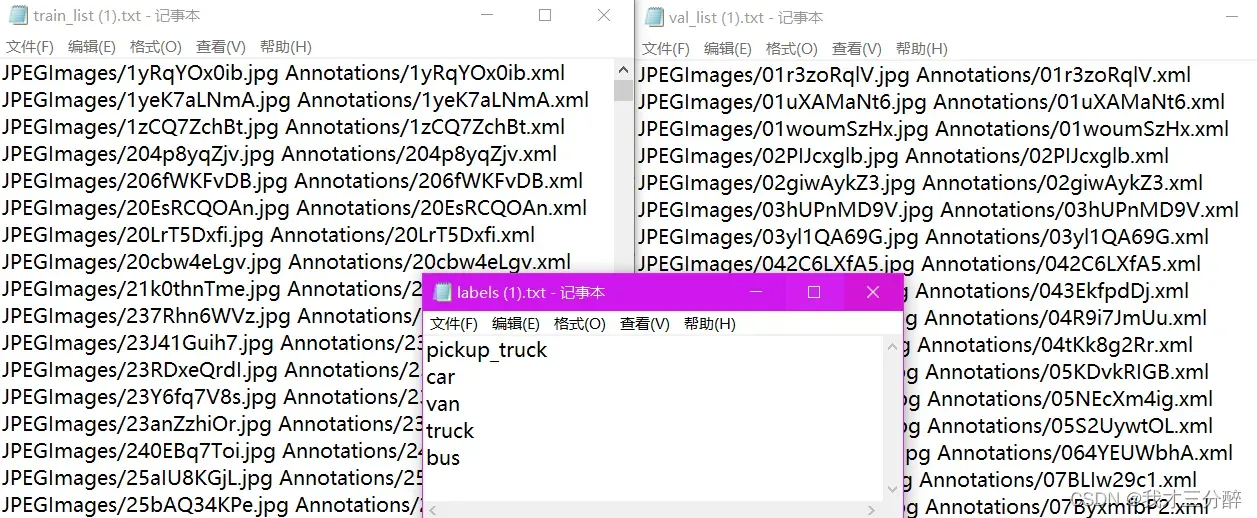
0.2.2JPEGImage文件夹
直接将images文件夹改名即可,文件下存放所有的图片
0.2.3Annotations文件夹
存放每张图片的标注信息,名称和图片名称相同。如:0AG5D38CPE.xml
#图片路径信息
JPEGImages
0AG5D38CPE.jpg
Unknown
#图片大小信息
1280
720
3
0
将train_box.csv转换问annotation文件夹脚本如下:
import pandas as pd
import numpy as np
import os
from PIL import Image
data=pd.read_csv('train_boxes.csv')
gg=data.groupby('image_filename')
ll=gg.size().index#存储名字
for i in ll:
im = Image.open('JPEGImages/'+i)
img_path = 'JPEGImages/'+i
img_root_path = os.path.abspath(img_path)
im = Image.open(img_path)
img=i[:-4]
width, height = im.size
xml_file = open(('Annotations' + '/' + img + '.xml'), 'w')
xml_file.write('\n')
xml_file.write('\tJPEGImages \n')
xml_file.write('\t' + str(img) + '.jpg' + ' \n')
# xml_file.write('\t' + img_root_path + ' \n')
xml_file.write('\t\n')
xml_file.write('\t\t' + 'Unknown' + ' \n')
xml_file.write('\t\n')
xml_file.write('\t\n')
xml_file.write('\t\t' + str(width) + ' \n')
xml_file.write('\t\t' + str(height) + ' \n')
xml_file.write('\t\t3 \n')
xml_file.write('\t \n')
xml_file.write('\t0 \n')
dd=gg.get_group(i)
labels=dd['label'].tolist()
x1s=dd['x0'].tolist()
x2s=dd['x1'].tolist()
y1s=dd['y0'].tolist()
y2s=dd['y1'].tolist()
for j in range(dd.shape[0]):
label=labels[j]
x1=x1s[j]
x2=x2s[j]
y1=y1s[j]
y2=y2s[j]
xml_file.write('\t\n')
xml_file.write(' ')
0.3:检查
****如果car_det目录下的内容如下,那么目标检测任务已经完成50%了!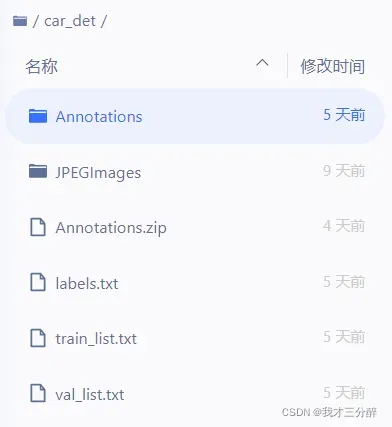
———————————Body dividing line————- ————————————————– ————————-
1、导入需要的包
import matplotlib
matplotlib.use('Agg')
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import paddlex as pdx
注:paddlex安装
!pip install paddlex==1.3.11 -i https://mirror.baidu.com/pypi/simple
paddle的安装参考官网:https://www.paddlepaddle.org.cn/install/quick
2、数据预处理流程
直接使用内置模块,一键数据预处理
from paddlex.det import transforms
#训练集预处理流程
train_transforms = transforms.Compose([
transforms.Resize(target_size=608, interp='RANDOM'),#转化为统一的尺寸
transforms.Normalize(),#归一化
])
#验证集预处理流程
eval_transforms = transforms.Compose([
transforms.Resize(target_size=608, interp='CUBIC'),
transforms.Normalize(),
])
3、加载为数据集
#此处如果报错检测car_det内文件格式与命名是否正确
train_dataset = pdx.datasets.VOCDetection(
data_dir='car_det',
file_list='car_det/train_list.txt',
label_list='car_det/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='car_det',
file_list='car_det/val_list.txt',
label_list='car_det/labels.txt',
transforms=eval_transforms)
4、开始训练
调谐器开始工作——你可以尝试不同的参数
num_classes = len(train_dataset.labels)
model = pdx.det.YOLOv3(num_classes=num_classes, backbone='DarkNet53')
model.train(
num_epochs=270,
train_dataset=train_dataset,
train_batch_size=30,
eval_dataset=eval_dataset,
learning_rate=0.000125*3,
lr_decay_epochs=[210, 240],
save_interval_epochs=20,
pretrain_weights=None,
save_dir='output/yolov3_darknet53',
use_vdl=False)
5、结果预测
加载训练好的模型
model = pdx.load_model('output2/ppyolo_ResNet50_vd_ssld/best_model')
label=['pickup_truck','car','van','truck','bus']
#i为图片名
xx='car_det/JPEGImages/'+str(i)#路径
result = model.predict(xx)#预测

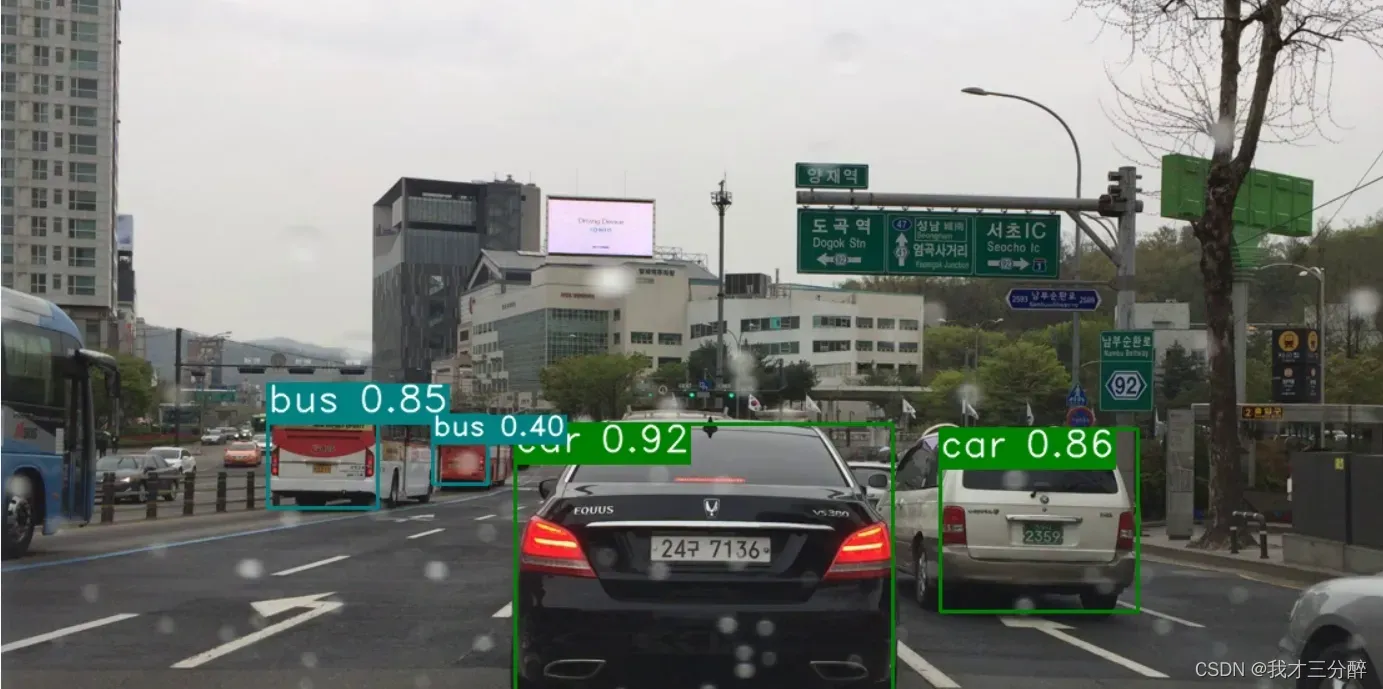
Result visualization:
Model optimization
- data augmentation
- pretrained model
- 集群锚框大小
- label_smooth
appendix
non-maximum suppression
def nms(bounding_boxes, Nt):#非极大值抑制
if len(bounding_boxes) == 0:
return [], []
bboxes = np.array(bounding_boxes)
# 计算 n 个候选框的面积大小
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
scores = bboxes[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
# 对置信度进行排序, 获取排序后的下标序号, argsort 默认从小到大排序\
order = np.argsort(scores)
picked_boxes = [] # 返回值
while order.size > 0:
# 将当前置信度最大的框加入返回值列表中
index = order[-1]
picked_boxes.append(bounding_boxes[index])
# 获取当前置信度最大的候选框与其他任意候选框的相交面积
x11 = np.maximum(x1[index], x1[order[:-1]])
y11 = np.maximum(y1[index], y1[order[:-1]])
x22 = np.minimum(x2[index], x2[order[:-1]])
y22 = np.minimum(y2[index], y2[order[:-1]])
w = np.maximum(0.0, x22 - x11 + 1)
h = np.maximum(0.0, y22 - y11 + 1)
intersection = w * h
# 利用相交的面积和两个框自身的面积计算框的交并比, 将交并比大于阈值的框删除
ious = intersection / (areas[index] + areas[order[:-1]] - intersection)
left = np.where(ious < Nt)
order = order[left]
return picked_boxes
Coordinate transformation
def con(box):
xm,ym,w,h=box[0],box[1],box[2],box[3]
x0=xm
x1=x0+w
y0=ym
y1=ym+h
return x0,y0,x1,y1
文章出处登录后可见!
已经登录?立即刷新