摘要
随着神经网络的深度变深,网络会更加难以学习,作者提出了一种残差连接的网络,使得在模型变深的时候依旧能够学习。网络是在ImageNet上学习的,总共有152层的深度,是VGG的8倍,即便深度增加了这么多,ResNet仍旧获得了很好的结果。
1 引言
深度网络将高中低等级的特征组合在一起,使用端到端的多层结构来分类,并且可以通过增加深度来增加特征。
但是问题也随之而来:深度的增加会出现梯度消失、梯度爆炸的问题,同时,当网络深度增加,可以发现精度会先饱和,然后迅速下降,而这样的下降却不是由过拟合导致的,因为训练误差也在同步增加(如果是过拟合导致的,那么训练误差不会增加)。
可以看到下图中,56层的网络并没有20层的网络表现得好。
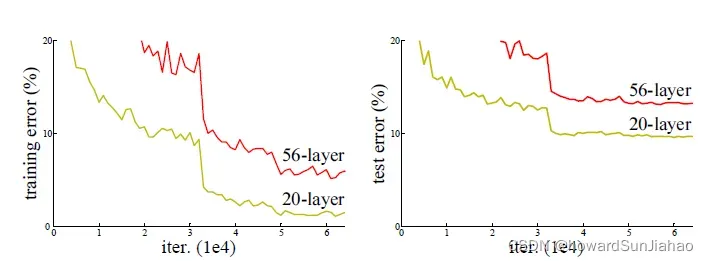
但是,如果我们做这样一个假设:当浅层的网络效果比较好的时候,深度网络训练会逐渐向浅层的网络进行学习。比如我们在一个浅层的网络上加一系列的恒等映射f(x)=x,那么看上去深度增加了,但是实际效果是不会变的,如果深度网络能够逐渐学习到这样的一个恒等映射,那么是不是就不会变差呢?但是,SGD的优化方法容易让学习陷入一个局部最优,所以无法学习到这样的一个恒等映射,于是深度的网络可能会比浅层的更差。
3 残差网络
为了使得深度的网络至少不会比一个对应的浅层网络要差,引入了残差的结构:
假设我们希望网络学习到的是一个的映射,那么本来的浅层网络输出一个
,后面加的层假设是
,我们希望这些加的层学到的是
,也就是残差。那么换一种写法也就是
。极端情况下,如果恒等映射是最优的,那么就更容易将残差部分变成0。同时,这样的恒等映射不会增加计算的复杂度。
具体实现而言就是引入了一个shortcut,可以理解为一个捷径,可以跳过中间的层,直接作用于输出上,如下图所示:
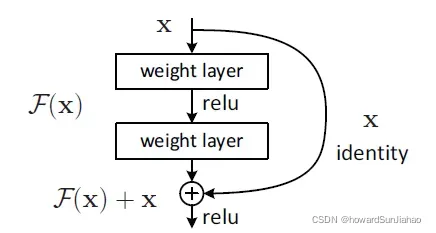
shortcut的思想很久之前就被提出来了,并不是这篇文章提出来的,同时,但是的一些研究,如highway network,和residual的思想差不多,但是highway的shortcut connection是有参数的,所以可能这样的参数会变成0,于是就变成了没有残差的网络。
3.2 恒等映射
当然,还有个问题要解决,如何保证和
可以加呢,也就是说,要保证这两个的维度是相同的。
如果对输入
有维度上的改变,那么我们也需要在shortcut的
上做一些映射,使得维度匹配,也就是:
![]()
3.3 网络架构
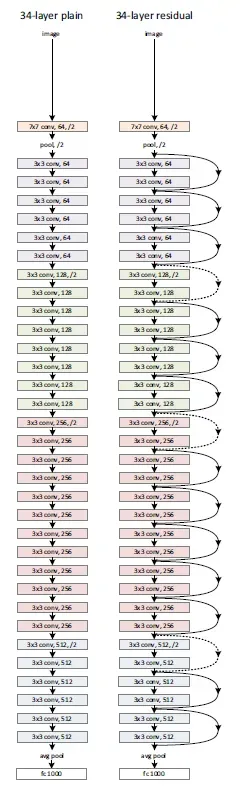
一个34层的ResNet架构如下(右),其中实线是中间的卷积层没有改变输入的维度,虚线则是有维度的改变,这里维度的改变就是通道数的改变。
保证维度相等的方式有两种:
- 使用零进行填充
- 使用1×1的卷积核来改变维度。
3.4 实现
实现中,参考了Alexnet,但是又有些不同,将图片的短边随机变成256-480的数值,作为数据增强,然后随机裁出224×224的,也包括了它们的水平镜像,同时减去了均值做中心化。
同时,使用了批量归一化BN层在每一个卷积层之后和激活之前。训练的批量大小batch-size=256,learning-rate开始0.1,当误差稳定(plateau)的时候,就除以10。
和AlexNet意义,也用了权重衰减,但是衰减率是0.0001,还有动量梯度下降,动量为0.9。
测试的时候也和AlexNet一样,裁出10个224×224的然后取平均。
4 实验
实验中尝试了18、34、50、101、152层的不同网络结构。
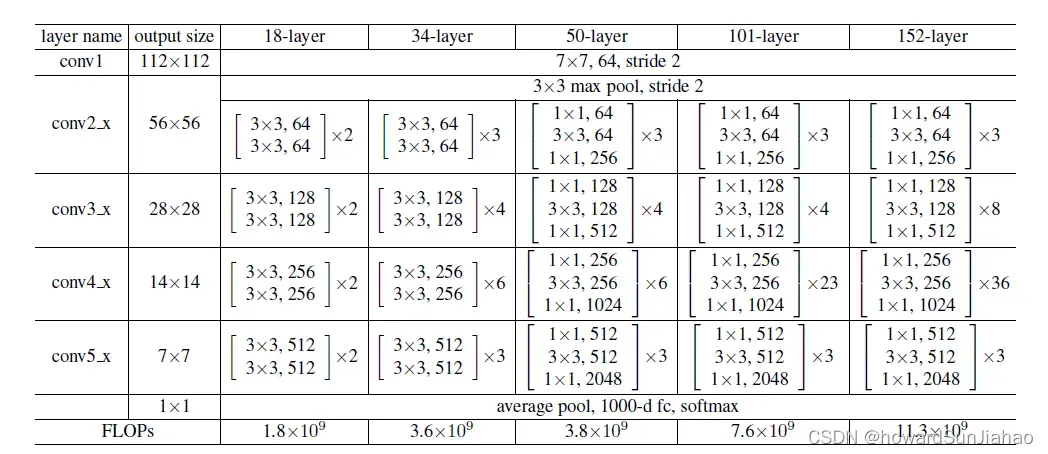
采用这种架构的起因是,由于网络更加深了,于是输入通道数变得更多了,如果还想和本来保持差不多的复杂度,那么先使用1×1的卷积层把通道数降低,然后中间3×3和之前一样,最后再用1×1的卷积层映射回去,保证输入输出的通道数是一样的。中间的那个3×3的卷积被称为bottleneck。
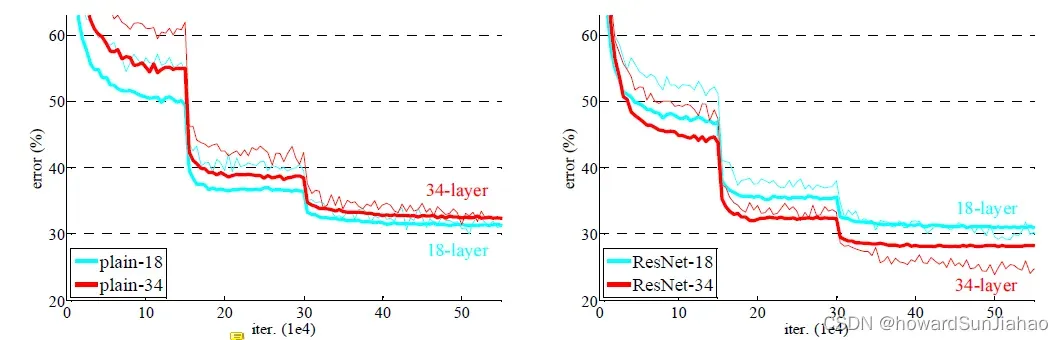
对比18层和34层的网络,细的是训练误差,粗的是验证误差,一开始可以看到验证的误差反而要低,这是因为用了数据增强,所以训练的时候会有许多的噪音。在使用了残差连接之后,深层的网络比浅层的网络效果要好:
文章出处登录后可见!