

原文标题 :Focal Loss: A better alternative for Cross-Entropy
焦点损失:交叉熵的更好选择
据说在许多情况下,焦点损失比交叉熵损失表现更好。但是为什么 Cross-Entropy loss 会失败,以及 Focal loss 如何解决这些问题,让我们在这篇文章中找出答案


损失函数是计算预测与实际值的偏差程度的数学方程。较高的损失值表明模型出现了重大错误,而较低的损失值意味着预测相当准确。目标是尽可能减少损失函数。模型使用损失函数来学习可训练的参数,例如权重和偏差。由于参数的权重更新方程具有损失函数关于权重或偏差的一阶导数,因此该函数的行为将对梯度下降过程产生重大影响。

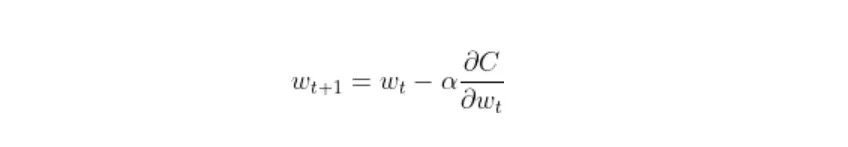
现在有许多损失函数可用。他们每个人都有不同的数学方程式和惩罚模型错误的不同方法。每个都有优点和缺点,在决定使用最佳功能之前,我们必须权衡。
现在我们已经定义了损失函数,让我们回顾一下分类交叉熵损失导致的问题以及焦点损失如何解决这些问题。
分类交叉熵损失
分类交叉熵损失传统上用于分类任务。顾名思义,它的基础是熵。在统计学中,熵是指系统的无序程度。它量化了模型对变量的预测值的不确定程度。所有概率估计的熵之和就是交叉熵。

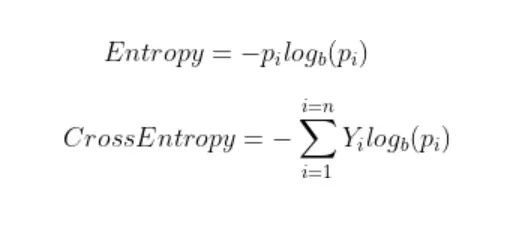
其中 Y 是真实标签,p 是预测概率。
注意:上面显示的公式适用于离散变量。在连续变量的情况下,求和应该代替积分。
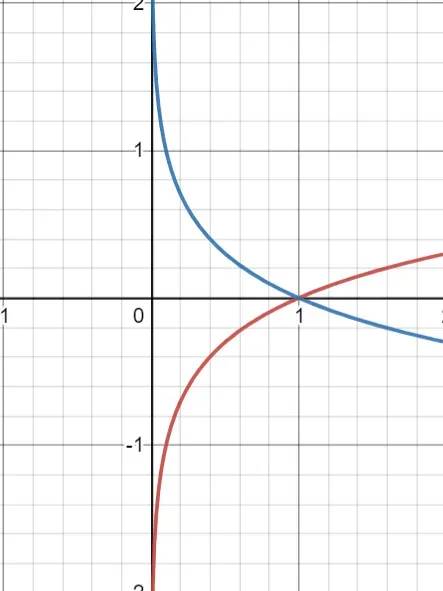
对数图清楚地表明求和将是负数,因为概率范围从 0 到 1。因此,我们添加了一个减号来反转求和项的符号。 log(x) 和 -log(x) 的图如下 (x) 所示。

交叉熵损失表现不佳的情况
- 类别不平衡在此过程中继承了偏见。多数类示例将主导损失函数和梯度下降,导致权重在模型方向上更新,对预测多数类变得更有信心,而对少数类的重视程度较低。平衡交叉熵损失处理了这个问题。
- 无法区分困难的例子和简单的例子。困难的例子是模型反复犯大错误的例子,而简单的例子是容易分类的例子。因此,Cross-Entropy loss 未能更多地关注难例。
平衡交叉熵损失
Balanced Cross-Entropy loss 为每个类增加了一个权重因子,由希腊字母 alpha [0, 1] 表示。 Alpha 可以是反类频率或由交叉验证确定的超参数。 alpha 参数替换了交叉熵方程中的实际标签项。

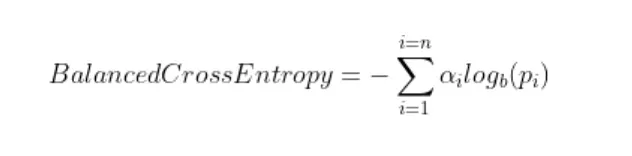
尽管这个损失函数解决了类不平衡的问题,但它不能区分困难的例子和简单的例子。通过焦点损失解决了这个问题。
Focal Loss
焦点损失集中在模型出错的例子上,而不是它可以自信地预测的例子上,确保对困难例子的预测随着时间的推移而改进,而不是对简单的例子过于自信。
这究竟是如何完成的?焦点损失通过一种称为向下加权的方法来实现这一点。降低权重是一种减少简单示例对损失函数的影响的技术,从而导致对困难示例的更多关注。该技术可以通过向交叉熵损失添加调制因子来实现。

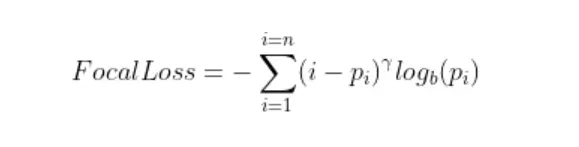
其中 γ (Gamma) 是要使用交叉验证调整的聚焦参数。下图显示了 Focal Loss 在不同 γ 值下的表现。

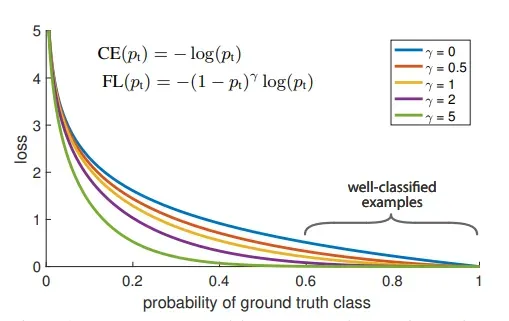
伽玛参数如何工作?
- 在错误分类样本的情况下,pi 很小,使得调制因子近似或非常接近 1。这使损失函数不受影响。结果,它表现为交叉熵损失。
- 随着模型置信度的增加,即 pi → 1,调制因子将趋于 0,从而降低分类良好示例的损失值的权重。聚焦参数 γ ≥ 1 将重新调整调制因子,使得简单示例的权重低于困难示例,从而减少它们对损失函数的影响。例如,假设预测概率为 0.9 和 0.6。考虑到 γ = 2,针对 0.9 计算的损失值为 4.5e-4 并被向下加权 100 倍,对于 0.6 为 3.5e-2 被向下加权 6.25 倍。从实验来看,γ = 2 对 Focal Loss 论文的作者来说效果最好。
- 当 γ = 0 时,Focal Loss 相当于 Cross Entropy。
在实践中,我们使用了焦点损失的 α 平衡变体,它继承了权重因子 α 和聚焦参数 γ 的特性,比非平衡形式的精度略高。

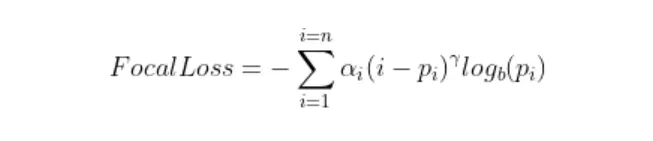
Focal Loss 自然地解决了类别不平衡的问题,因为来自多数类别的示例通常很容易预测,而来自少数类别的示例由于缺乏数据或来自多数类别的示例主导损失和梯度过程而难以预测。由于这种相似性,Focal Loss 可能能够解决这两个问题。
感谢您阅读文章😃。祝你今天过得愉快。
文章出处登录后可见!