

原文标题 :The Best Deep Learning Models for Time Series Forecasting
时间序列预测的最佳深度学习模型
关于时间序列和深度学习你需要知道的一切


请务必在此处订阅,以免错过有关数据科学主题、项目、指南等的另一篇文章![0]
Preliminaries
时间序列预测的格局在两年内发生了巨大变化。
Makridakis M 竞赛系列的第四和第五场(分别称为 M4 和 M5 竞赛)发生在 2018 年和 2020 年。对于那些不知道的人来说,这些 M 竞赛本质上是时间序列的现状生态系统,提供指导预测理论和实践的经验和客观证据。
2018 年 M4 竞赛的结果表明,纯粹的“ML”方法在很大程度上优于传统的统计方法。这是出乎意料的,因为深度学习已经在计算机视觉和 NLP 等其他领域留下了不可磨灭的印记。然而,在两年后的 M5 竞赛[1] 中,由于数据集更具创意,排名靠前的参赛作品仅包含“ML”方法。更准确地说,所有 50 种表现最好的方法都是基于 ML 的。这场比赛见证了多功能 LightGBM(用于时间序列预测)的兴起以及亚马逊的 DeepAR[2] 和 N-BEATS[3] 的首次亮相。 2020 年发布的 N-BEATS 模型比 M4 比赛的获胜者高出 3%!
最近的呼吸机压力预测 Kaggle 竞赛展示了使用深度学习方法解决真实案例时间序列挑战的重要性。具体来说,比赛的目标是在给定控制输入的时间序列的情况下预测机械肺内压力的时间序列。每个训练实例本质上都是它自己的时间序列,因此任务是一个多时间序列问题。获胜团队提交了一个多层次的深度架构,其中包括 LSTM 网络和 Transformer 块等。[0][1]
在过去几年中,已经发布了许多著名的架构,例如多水平分位数循环预报器 (MQRNN) 和深空状态模型 (DSSM)。所有这些模型都利用深度学习为时间序列预测领域贡献了许多新奇事物。除了赢得 Kaggle 比赛之外,还有其他因素在起作用,例如:
- 多功能性:将模型用于不同任务的能力。
- MLOps:在生产中使用模型的能力。
- 可解释性和可解释性:黑盒模型不再那么流行了。
本文讨论了 4 种专门用于时间序列预测的新型深度学习架构。具体来说,这些是:
- N-BEATS (ElementAI)
- DeepAR (Amazon)
- Spacetimeformer [4]
- 时间融合变压器或 TFT(谷歌)[5]
前两个经过了更多的实战测试,并已在许多部署中使用。 Spacetimeformer 和 TFT 也是出色的模型,并提出了许多新颖性。他们能够利用超越时间序列背景的新动态。
N-BEATS
这个模型直接来自(不幸的是)短命的 ElementAI,这是一家由 Yoshua Bengio 共同创立的公司。顶层架构及其主要组件如图 1 所示:[0]

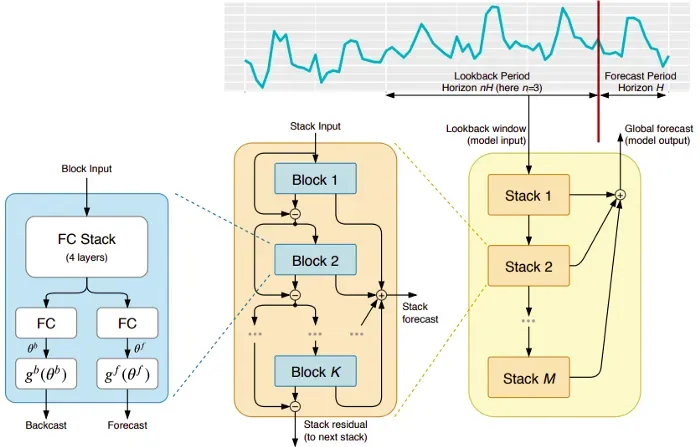
从本质上讲,N-BEATS 是一种纯深度学习架构,基于集成前馈网络的深度堆栈,这些网络也通过互连回溯和预测链接进行堆叠。
每个连续的块仅对由于从前一个块的回溯重建而产生的残差进行建模,然后根据该误差更新预测。此过程在拟合 ARIMA 模型时模仿 Box-Jenkins 方法。
这些是该模型的主要优势:
富有表现力且易于使用:该模型易于理解并且具有模块化结构(块和堆栈)。此外,它被设计为需要最少的时间序列特征工程并且不需要输入缩放。
多个时间序列:该模型具有泛化多个时间序列的能力。换句话说,可以使用分布略有不同的不同时间序列作为输入。在 N-BEATS 实现中,这是通过元学习来实现的。具体来说,元学习过程包括两个过程:内部学习过程和外部学习过程。内部学习过程发生在块内,帮助模型捕捉局部时间特征。另一方面,外部学习过程发生在堆栈内部,帮助模型学习所有时间序列的全局特征。
双残差堆叠:残差连接和堆叠的想法非常出色,几乎用于所有类型的深度神经网络,例如深度卷积网络和变压器。 N-BEATS 实现中应用了相同的原理,但有一些额外的修改:每个块有两个残差分支,一个通过回溯窗口(称为回溯),另一个通过预测窗口(称为预测)。
每个连续的块仅对由于从前一个块的回溯重建而产生的残差进行建模,然后根据该误差更新预测。这有助于模型更好地逼近有用的回溯信号,同时,最终的堆栈预测预测被建模为所有部分预测的分层总和。有趣的是,这个过程在拟合 ARIMA 模型时模仿了 Box-Jenkins 方法。
可解释性:该模型有两种变体,通用的和可解释的。在一般变体中,每个块的全连接层中的最终权重由网络任意学习。在可解释的变体中,每个块的最后一层被删除。然后,反向预测和预测分支乘以模拟趋势(单调函数)和季节性(周期性循环函数)的特定矩阵。
注意:原始的 N-BEATS 实现仅适用于单变量时间序列。
DeepAR
一种新颖的时间序列模型,它结合了深度学习和自回归特征。 DeepAR 的顶层视图如图 2 所示:

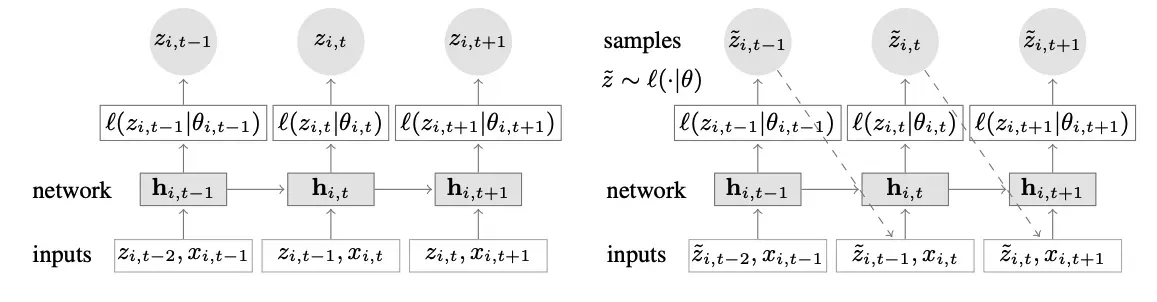
这些是该模型的主要优势:
多个时间序列:DeepAR 非常适用于多个时间序列:通过使用分布略有不同的多个时间序列来构建全局模型。此外,此属性在许多现实世界场景中都有应用。例如,一家电力公司可能希望为其每个客户推出电力预测服务。几乎可以肯定,每个客户都会有不同的消费模式(这意味着不同的分布)。
丰富的输入集:除了历史数据,DeepAR 还允许使用已知的未来时间序列(自回归模型的一个特征)和序列的额外静态属性。在上述电力需求预测场景中,额外的时间变量可能是月份(作为整数,值在 1-12 之间)。显然,假设每个客户都与一个测量功耗的传感器相关联,那么额外的静态变量将类似于 sensor_id 或 customer_id 。
自动缩放:如果您熟悉使用 MLP 和 RNN 等神经网络架构进行时间序列预测,那么一个关键的预处理步骤是使用归一化或标准化技术来缩放时间序列。在 DeepAR 中,不需要手动执行此操作,因为引擎盖下的模型使用缩放因子 v_i 缩放每个时间序列 i 的自回归输入 z,这只是该时间序列的平均值。具体来说,论文基准中使用的比例因子方程如下:

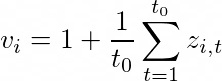
然而,在实践中,如果目标时间序列的大小差异很大,那么在预处理期间也应用我们自己的缩放可能会有所帮助。例如,在能源需求预测场景中,数据集可以包含中压电力客户(例如小型工厂,以兆瓦为单位的用电)和低压客户(例如,家庭,以千瓦为单位的用电)。
概率预测:DeepAR 进行概率预测,而不是直接输出未来值。这是以蒙特卡洛样本的形式完成的。此外,这些预测用于通过使用分位数损失函数来计算分位数预测。对于不熟悉此类损失的人,分位数损失不仅用于计算估计值,还用于计算围绕该值的预测区间。
Spacetimeformer
在单变量时间序列的上下文中,时间依赖性是最重要的。然而,在多时间序列场景中,事情就没有这么简单了。例如,假设我们有一个天气预报任务,我们想要预测五个城市的温度。另外,让我们假设这些城市属于一个国家。鉴于我们目前所见,我们可以使用 DeepAR 并将每个城市建模为外部静态协变量。
换句话说,该模型将考虑时间和空间关系。这就是 Spacetimeformer 的核心思想。
我们还可以更进一步,使用一种模型,利用这些城市/位置之间的空间关系来学习更多有用的依赖关系。换句话说,该模型将考虑时间和空间关系。这就是 Spacetimeformer 的核心思想。
深入研究时空序列
顾名思义,该模型在引擎盖下使用了基于变压器的结构。在使用基于转换器的模型进行时间序列预测时,一种产生时间感知嵌入的流行技术是将输入通过 Time2Vec [6] 嵌入层(提醒一下,对于 NLP 任务,使用位置编码向量而不是 Time2vec产生上下文感知嵌入)。虽然这种技术对于单变量时间序列非常有效,但对于多变量时间输入没有任何意义。在语言建模中,一个句子的每个单词都用一个embedding来表示,一个单词本质上是一个概念,是一个词汇表的一部分。
在多变量时间序列上下文中,在给定的时间步 t 处,输入的形式为 x_1,t , x_2,t , x_m,t 其中 x_i,t 是特征 i 的数值,m 是特征/序列的总数.如果我们通过 Time2Vec 层传递输入,将产生一个时间嵌入向量。在那种情况下,这个嵌入真正代表什么?答案是它将整个输入集表示为单个实体(令牌)。因此,模型将只学习时间步长之间的时间动态,但会错过特征/变量之间的空间关系。
Spacetimeformer 通过将输入扁平化为单个大向量(称为时空序列)来解决此问题。如果输入由 N 个变量组成,组织成 T 个时间步长,则生成的时空序列将具有 (NxT) 个标记。这在图 3 中得到了更好的展示:

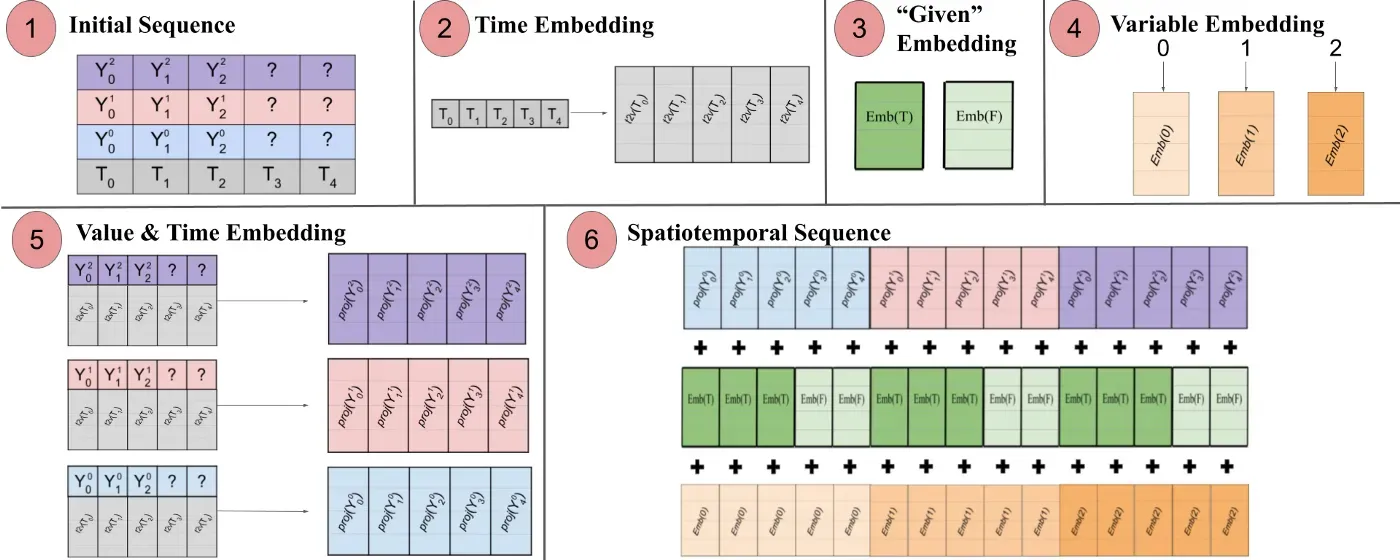
换句话说,最终序列编码了一个统一的嵌入,由时间、空间和上下文信息组成。
然而,这种方法的一个缺点是序列可能变得太长,从而导致资源的二次增加。这是因为根据注意力机制,每个令牌/实体都会相互检查。作者使用了一种更有效的架构,适用于更大的序列,称为 Performer attention 机制。有关更多技术细节,请查看项目在 Github 上的 repo。[0][1]
Temporal Fusion Transformer
时间融合变换器(TFT)是谷歌发布的基于变换器的时间序列预测模型。如果您想对这个很棒的模型进行更全面的分析,请查看这篇文章。[0]
TFT 比以前的型号更通用。例如,DeepAR 不适用于直到现在才知道的与时间相关的特征。

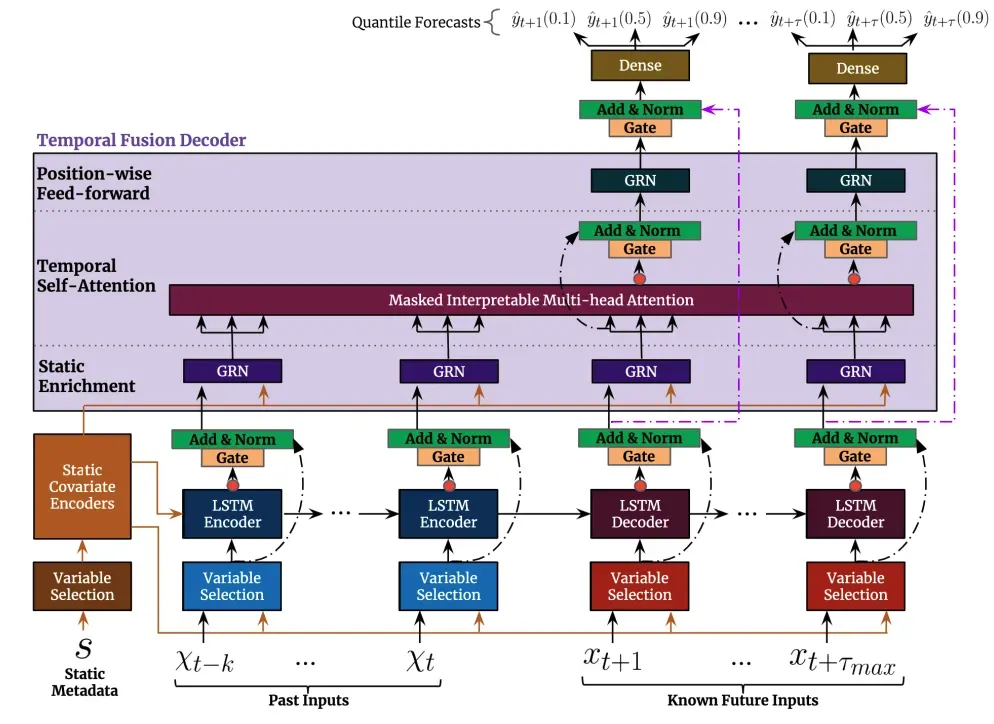
TFT 的顶层架构如图 4 所示。这些是该模型的主要优势:
- 多个时间序列:与上述模型一样,TFT 支持在多个异构时间序列上构建模型。
- 丰富的特征:TFT 支持 3 种类型的特征:i) 具有已知输入到未来的时间相关数据 ii) 仅知道当前的时间相关数据和 iii) 分类/静态变量,也称为时不变特征。因此,TFT 比以前的型号更通用。例如,DeepAR 不适用于直到现在才知道的与时间相关的特征。在上述电力需求预测场景中,我们希望将湿度水平用作与时间相关的特征,直到现在才知道这一点。这在 TFT 中是可行的,但在 DeepAR 中是不可行的。
图 5 显示了如何使用所有这些功能的示例:


- 可解释性:TFT 非常强调可解释性。具体来说,通过利用变量选择组件(如图 4 所示),该模型可以成功地衡量每个特征的影响。结果,模型学习了特征的重要性。
另一方面,TFT 提出了一种新颖的可解释的多头注意力机制:该层的注意力权重可以揭示回顾期间哪些时间步长是最重要的。因此,这些权重的可视化可以揭示整个数据集中最突出的季节性模式。 - 预测区间:与 DeepAR 类似,TFT 通过使用分位数回归输出预测区间以及预测值。
Closing Remarks
考虑到上述所有因素,深度学习无疑彻底改变了时间序列预测的格局。除了无与伦比的性能之外,所有上述模型都有一个共同点:它们充分利用了多个、多变量的时间数据,同时它们以一种和谐的方式使用外生信息,将预测性能提升到前所未有的水平。
感谢您的阅读!
References
[1] Makridakis 等人,M5 精度竞赛:结果、发现和结论,(2020 年)[0]
[2] D. Salinas 等人,DeepAR:使用自回归循环网络进行概率预测,国际预测杂志(2019 年)。[0]
[3] Boris N. 等人,N-BEATS:可解释时间序列预测的神经基础扩展分析,ICLR (2020)[0]
[4] Jake Grigsby 等人,用于动态时空预测的远程变压器,[0]
[5] Bryan Lim 等人,用于可解释多地平线时间序列预测的时间融合变压器,国际预测杂志 2020 年 9 月[0]
[6] Seyed Mehran Kazemi 等人,Time2Vec:学习时间的向量表示,2019 年 7 月[0]
文章出处登录后可见!