

原文标题 :Text Classification with BERT in PyTorch
在 PyTorch 中使用 BERT 进行文本分类
如何利用 Hugging Face 的预训练 BERT 模型对新闻文章的文本进行分类


早在 2018 年,谷歌就为 NLP 应用程序开发了一个强大的基于 Transformer 的机器学习模型,该模型在不同的基准数据集中优于以前的语言模型。而这个模型被称为BERT。
在这篇文章中,我们将使用 Hugging Face 的预训练 BERT 模型进行文本分类任务。您可能已经知道,文本分类任务中模型的主要目标是将文本分类为预定义的标签或标签之一。

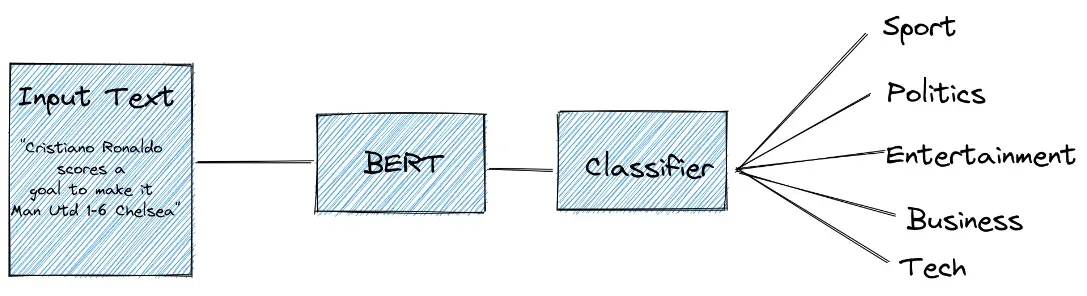
具体来说,很快我们将使用预训练的 BERT 模型来分类新闻文章的文本是否可以归类为体育、政治、商业、娱乐或技术类别。
但在我们深入实施之前,让我们简单谈谈 BERT 背后的概念。
What is BERT?
BERT 是来自 Transformers 的双向编码器表示的首字母缩写词。这个名字本身为我们提供了一些关于 BERT 的线索。
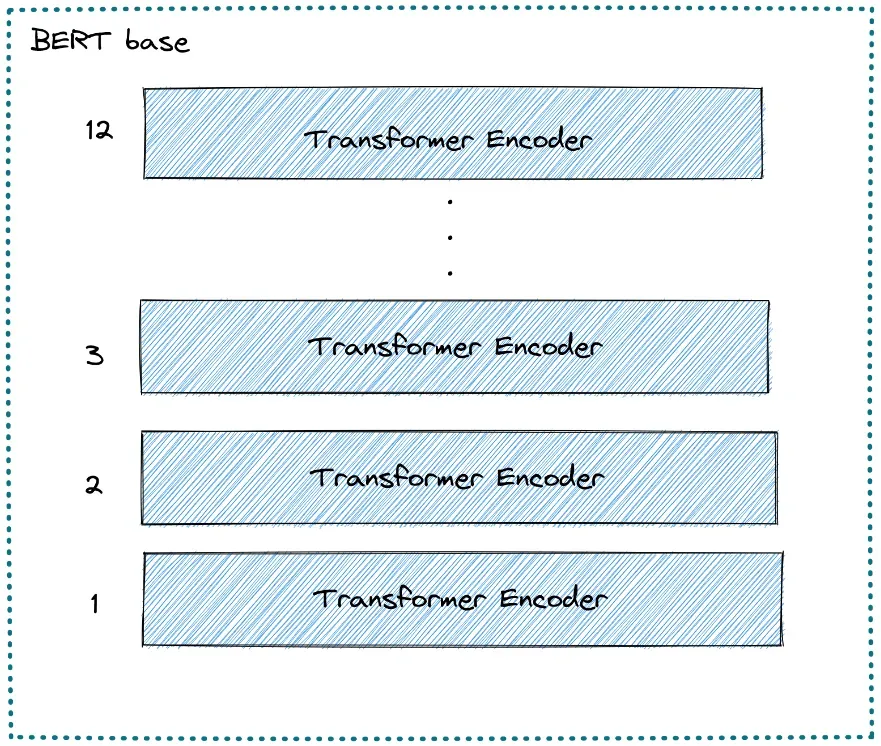
BERT 架构由多个堆叠在一起的 Transformer 编码器组成。每个 Transformer 编码器都封装了两个子层:一个自注意力层和一个前馈层。
有两种不同的 BERT 模型:
- BERT base,这是一个 BERT 模型,由 12 层 Transformer 编码器、12 个注意力头、768 个隐藏大小和 110M 参数组成。
- BERT large,这是一个 BERT 模型,由 24 层 Transformer 编码器、16 个注意力头、1024 个隐藏大小和 340 个参数组成。

BERT 是一个强大的语言模型至少有两个原因:
- 它使用从 BooksCorpus (有 8 亿字)和 Wikipedia(有 2,500 M 字)中提取的未标记数据进行预训练。
- 顾名思义,它是通过利用编码器堆栈的双向特性进行预训练的。这意味着 BERT 不仅从左到右,而且从右到左从单词序列中学习信息。
BERT 输入和输出
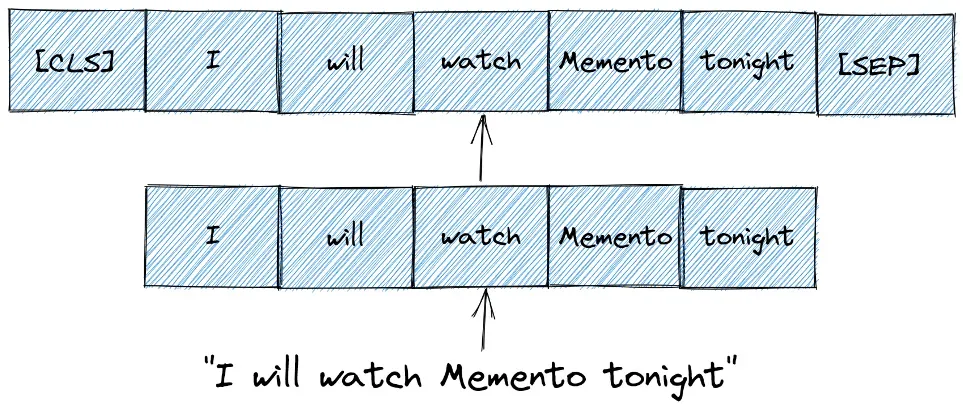
BERT 模型需要一系列标记(单词)作为输入。在每个标记序列中,BERT 期望有两个特殊标记作为输入:
- [CLS]:这是每个序列的第一个token,代表分类token。
- [SEP]:这是让 BERT 知道哪个令牌属于哪个序列的令牌。这个特殊标记主要对下一句预测任务或问答任务很重要。如果我们只有一个序列,那么这个标记将被附加到序列的末尾。
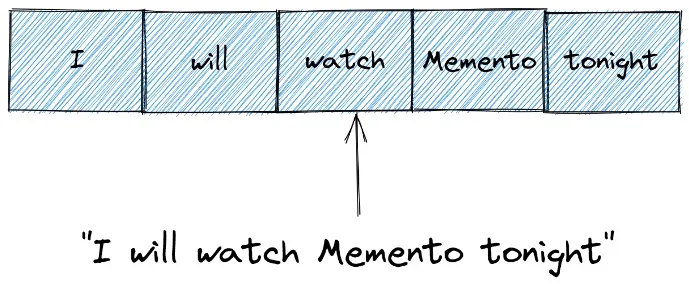
为了更清楚,假设我们有一个包含以下短句的文本:


作为第一步,我们需要将这个句子转换为一系列标记(单词),这个过程称为标记化。

虽然我们已经对输入句子进行了标记,但我们还需要再做一步。在将其用作 BERT 模型的输入之前,我们需要通过添加 [CLS] 和 [SEP] 标记来重新格式化该标记序列。

幸运的是,我们只需要一行代码就可以将输入句子转换为 BERT 期望的标记序列,正如我们在上面看到的那样。我们将使用 BertTokenizer 来执行此操作,稍后您可以看到我们如何执行此操作。
还需要注意的是,可以输入 BERT 模型的最大令牌大小为 512。如果序列中的令牌小于 512,我们可以使用填充来用 [PAD] 令牌填充未使用的令牌槽。如果序列中的标记长于 512,那么我们需要进行截断。
这就是 BERT 期望的所有输入。
然后,BERT 模型将在每个标记中输出一个大小为 768 的嵌入向量。我们可以将这些向量用作不同类型 NLP 应用程序的输入,无论是文本分类、下一句预测、命名实体识别 (NER) 还是问答。
对于文本分类任务,我们将注意力集中在特殊 [CLS] 标记的嵌入向量输出上。这意味着我们将使用来自 [CLS] 标记的大小为 768 的嵌入向量作为分类器的输入,然后它将输出一个大小为分类任务中类数的向量。
下面是 BERT 模型的输入和输出的图解。

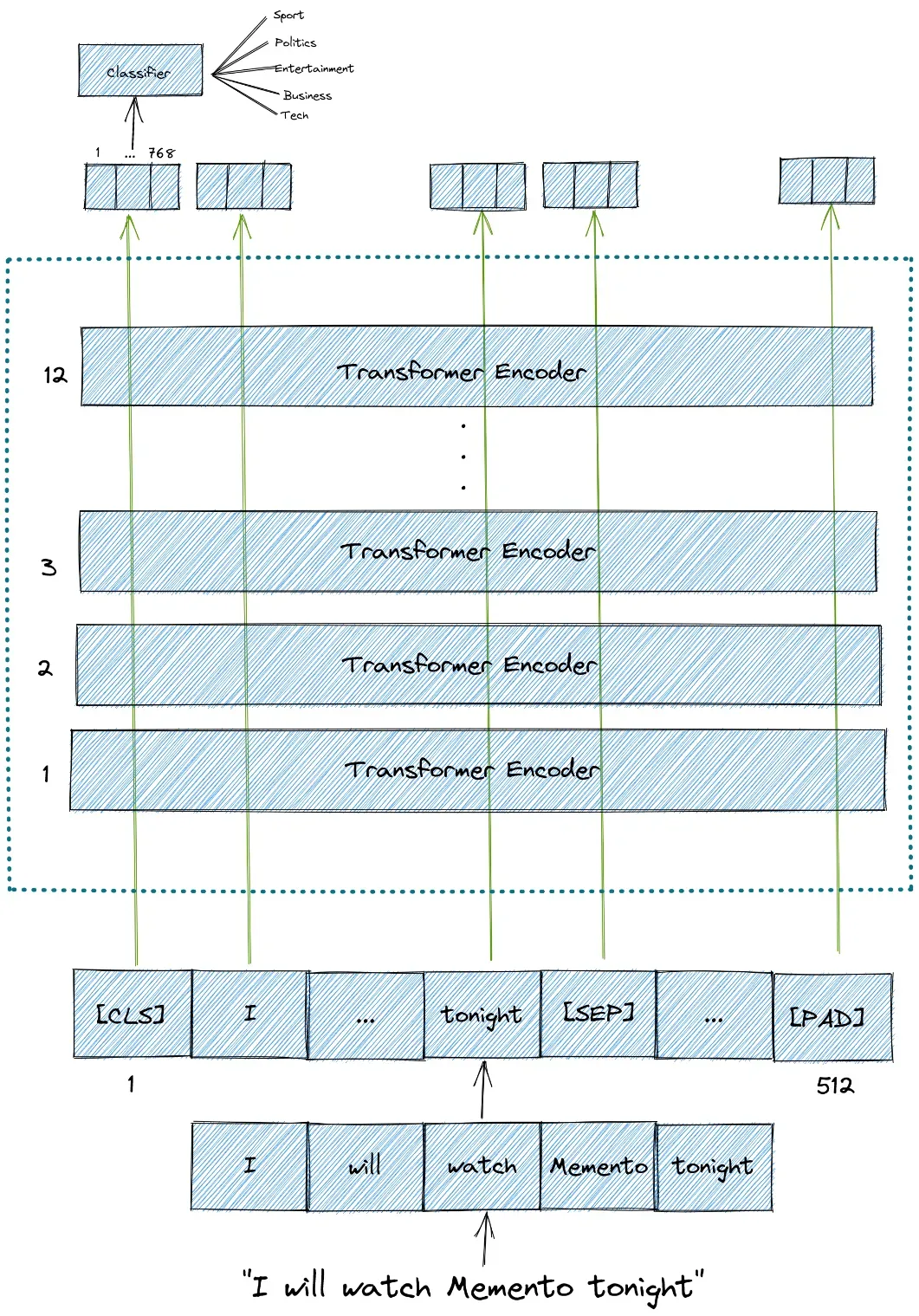
使用 BERT 进行文本分类
现在我们将进入我们的主题,用 BERT 对文本进行分类。在这篇文章中,我们将使用 BBC 新闻分类数据集。如果您想继续学习,可以在 Kaggle 上下载数据集。[0]
这个数据集已经是 CSV 格式,它有 2126 种不同的文本,每一种都标记在 5 个类别中的一个下:娱乐、体育、科技、商业或政治。
让我们看一下数据集的样子。
如您所见,数据框只有两列,类别将作为我们的标签,文本将作为 BERT 的输入数据。
Preprocessing Data
正如您可能已经从上一节中知道的那样,我们需要通过添加 [CLS] 和 [SEP] 标记将我们的文本转换为 BERT 期望的格式。我们可以使用 Hugging Face 中的 BertTokenizer 类轻松完成此操作。
首先,我们需要通过 pip 安装 Transformers 库:
pip install transformers为了让我们更容易理解我们从 BertTokenizer 得到的输出,让我们以一个简短的文本为例。
下面是上面对 BertTokenizer 参数的解释:
- padding :将每个序列填充到您指定的最大长度。
- max_length :每个序列的最大长度。在此示例中,我们使用 10,但对于我们的实际数据集,我们将使用 512,这是 BERT 允许的序列的最大长度。
- truncation :如果为 True,则每个序列中超过最大长度的标记将被截断。
- return_tensors :将返回的张量类型。由于我们使用的是 Pytorch,所以我们使用 pt。如果你使用 Tensorflow,那么你需要使用 tf 。
您从上面的 bert_input 变量中看到的输出对于我们稍后的 BERT 模型是必需的。但是这些输出是什么意思?
- 第一行是 input_ids ,它是每个令牌的 id 表示。我们实际上可以将这些输入 id 解码为实际的令牌,如下所示:
如您所见,BertTokenizer 负责输入文本的所有必要转换,以便准备好用作我们的 BERT 模型的输入。它会自动添加 [CLS]、[SEP] 和 [PAD] 令牌。由于我们指定最大长度为 10,所以最后只有两个 [PAD] 标记。
2. 第二行是 token_type_ids ,它是一个二进制掩码,用于标识令牌属于哪个序列。如果我们只有一个序列,那么所有的标记类型 id 都将为 0。对于文本分类任务,token_type_ids 是我们 BERT 模型的可选输入。
3. 第三行是 attention_mask ,它是一个二进制掩码,用于识别标记是真实单词还是只是填充。如果令牌包含 [CLS]、[SEP] 或任何真实单词,则掩码将为 1。同时,如果令牌只是填充或 [PAD],则掩码将为 0。
正如您可能注意到的,我们使用了来自 bert-base-cased 模型的预训练 BertTokenizer。如果数据集中的文本是英文的,这个预训练的分词器就可以很好地工作。
如果您有来自不同语言的数据集,您可能需要使用 bert-base-multilingual-cases。具体来说,如果您的数据集是德语、荷兰语、中文、日语或芬兰语,您可能需要使用专门针对这些语言进行预训练的分词器。您可以在此处查看相应的预训练标记器的名称。[0]
综上所述,下面是 BertTokenizer 对我们的输入句子所做的说明。

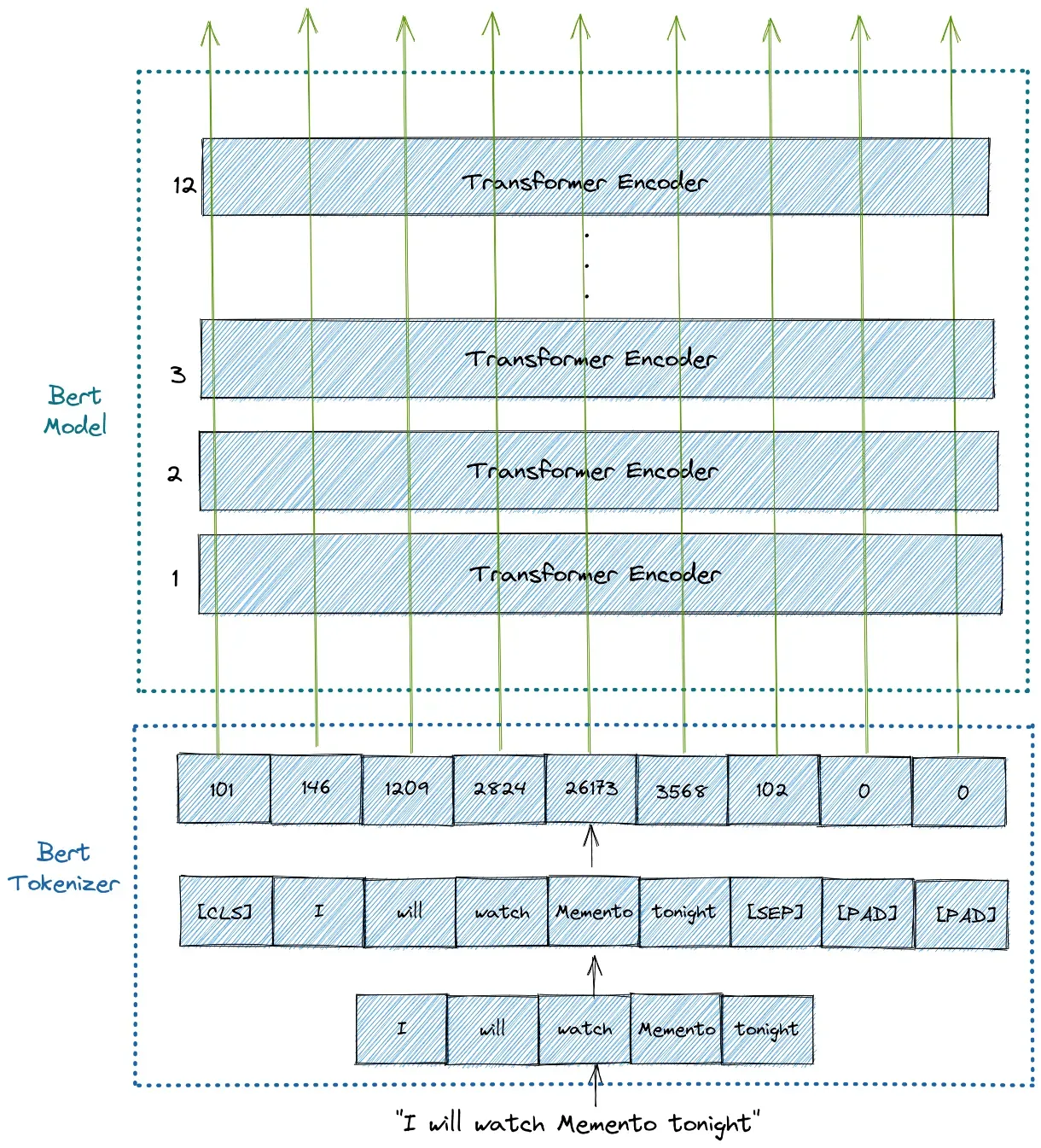
Dataset Class
现在我们知道我们将从 BertTokenizer 获得什么样的输出,让我们为我们的新闻数据集构建一个 Dataset 类,它将作为一个类来生成我们的新闻数据。
import torch
import numpy as np
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
labels = {'business':0,
'entertainment':1,
'sport':2,
'tech':3,
'politics':4
}
class Dataset(torch.utils.data.Dataset):
def __init__(self, df):
self.labels = [labels[label] for label in df['category']]
self.texts = [tokenizer(text,
padding='max_length', max_length = 512, truncation=True,
return_tensors="pt") for text in df['text']]
def classes(self):
return self.labels
def __len__(self):
return len(self.labels)
def get_batch_labels(self, idx):
# Fetch a batch of labels
return np.array(self.labels[idx])
def get_batch_texts(self, idx):
# Fetch a batch of inputs
return self.texts[idx]
def __getitem__(self, idx):
batch_texts = self.get_batch_texts(idx)
batch_y = self.get_batch_labels(idx)
return batch_texts, batch_y在上面的实现中,我们定义了一个名为 labels 的变量,它是一个字典,将数据帧中的类别映射到我们标签的 id 表示中。请注意,我们还在上面的 __init__ 函数中调用了 BertTokenizer 来将我们的输入文本转换为 BERT 期望的格式。
定义数据集类后,让我们将数据框拆分为训练集、验证集和测试集,比例为 80:10:10。
np.random.seed(112)
df_train, df_val, df_test = np.split(df.sample(frac=1, random_state=42),
[int(.8*len(df)), int(.9*len(df))])
print(len(df_train),len(df_val), len(df_test))
>>>1780 222 223
Model Building
到目前为止,我们已经构建了一个数据集类来生成我们的数据。现在让我们使用具有 12 层 Transformer 编码器的预训练 BERT 基础模型构建实际模型。
如果您的数据集不是英文的,最好使用 bert-base-multilingual-cases 模型。如果您的数据是德语、荷兰语、中文、日语或芬兰语,您可以使用专门针对这些语言进行预训练的模型。您可以在此处查看相应预训练模型的名称。[0]
from torch import nn
from transformers import BertModel
class BertClassifier(nn.Module):
def __init__(self, dropout=0.5):
super(BertClassifier, self).__init__()
self.bert = BertModel.from_pretrained('bert-base-cased')
self.dropout = nn.Dropout(dropout)
self.linear = nn.Linear(768, 5)
self.relu = nn.ReLU()
def forward(self, input_id, mask):
_, pooled_output = self.bert(input_ids= input_id, attention_mask=mask,return_dict=False)
dropout_output = self.dropout(pooled_output)
linear_output = self.linear(dropout_output)
final_layer = self.relu(linear_output)
return final_layer从上面的代码可以看出,BERT 模型输出了两个变量:
- 第一个变量,我们在上面的代码中命名为 _,包含序列中所有标记的嵌入向量。
- 第二个变量,我们命名为 pooled_output,包含 [CLS] 标记的嵌入向量。对于文本分类任务,使用这个嵌入作为我们分类器的输入就足够了。
然后,我们将 pooled_output 变量传递到具有 ReLU 激活函数的线性层中。在线性层的末尾,我们有一个大小为 5 的向量,每个向量对应于我们的标签类别(体育、商业、政治、娱乐和科技)。
Training Loop
现在是我们训练模型的时候了。训练循环将是标准的 PyTorch 训练循环。
from torch.optim import Adam
from tqdm import tqdm
def train(model, train_data, val_data, learning_rate, epochs):
train, val = Dataset(train_data), Dataset(val_data)
train_dataloader = torch.utils.data.DataLoader(train, batch_size=2, shuffle=True)
val_dataloader = torch.utils.data.DataLoader(val, batch_size=2)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr= learning_rate)
if use_cuda:
model = model.cuda()
criterion = criterion.cuda()
for epoch_num in range(epochs):
total_acc_train = 0
total_loss_train = 0
for train_input, train_label in tqdm(train_dataloader):
train_label = train_label.to(device)
mask = train_input['attention_mask'].to(device)
input_id = train_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
batch_loss = criterion(output, train_label)
total_loss_train += batch_loss.item()
acc = (output.argmax(dim=1) == train_label).sum().item()
total_acc_train += acc
model.zero_grad()
batch_loss.backward()
optimizer.step()
total_acc_val = 0
total_loss_val = 0
with torch.no_grad():
for val_input, val_label in val_dataloader:
val_label = val_label.to(device)
mask = val_input['attention_mask'].to(device)
input_id = val_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
batch_loss = criterion(output, val_label)
total_loss_val += batch_loss.item()
acc = (output.argmax(dim=1) == val_label).sum().item()
total_acc_val += acc
print(
f'Epochs: {epoch_num + 1} | Train Loss: {total_loss_train / len(train_data): .3f} \
| Train Accuracy: {total_acc_train / len(train_data): .3f} \
| Val Loss: {total_loss_val / len(val_data): .3f} \
| Val Accuracy: {total_acc_val / len(val_data): .3f}')
EPOCHS = 5
model = BertClassifier()
LR = 1e-6
train(model, df_train, df_val, LR, EPOCHS)
我们对模型进行了 5 个 epoch 的训练,我们使用 Adam 作为优化器,而学习率设置为 1e-6。我们还需要使用分类交叉熵作为我们的损失函数,因为我们正在处理多类分类。
建议您使用 GPU 来训练模型,因为 BERT 基础模型包含 1.1 亿个参数。
使用上述配置 5 个 epoch 后,您将获得以下输出作为示例:

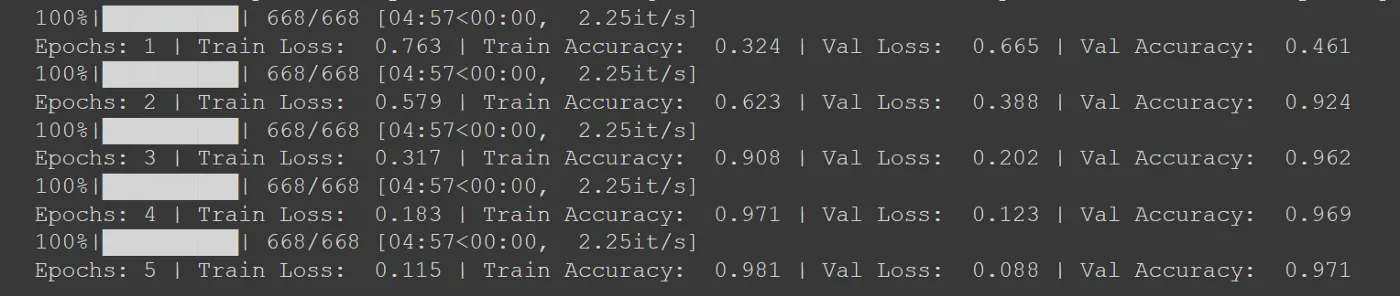
显然,由于训练过程的随机性,您可能不会得到与上面截图类似的损失和准确率值。如果你在 5 个 epoch 之后没有得到好的结果,试着将 epoch 增加到 10 个,或者调整学习率。
在测试数据上评估模型
现在我们已经训练了模型,我们可以使用测试数据来评估模型在未见数据上的性能。下面是评估模型在测试集上的性能的函数。
def evaluate(model, test_data):
test = Dataset(test_data)
test_dataloader = torch.utils.data.DataLoader(test, batch_size=2)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
if use_cuda:
model = model.cuda()
total_acc_test = 0
with torch.no_grad():
for test_input, test_label in test_dataloader:
test_label = test_label.to(device)
mask = test_input['attention_mask'].to(device)
input_id = test_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
acc = (output.argmax(dim=1) == test_label).sum().item()
total_acc_test += acc
print(f'Test Accuracy: {total_acc_test / len(test_data): .3f}')
evaluate(model, df_test)
运行上面的代码后,我从测试数据中得到了 0.994 的准确率。由于训练过程中的随机性,你得到的准确率显然与我的略有不同。
Conclusion
现在您知道了我们如何利用 Hugging Face 的预训练 BERT 模型进行文本分类任务的步骤。我希望这篇文章能帮助你开始使用 BERT。
要记住的一件事是,我们不仅可以使用来自 BERT 的嵌入向量来执行句子或文本分类任务,还可以执行更高级的 NLP 应用程序,例如问答、下一句预测或命名实体识别 (NER)任务。
您可以在此笔记本中找到本文中演示的所有代码片段。[0]
文章出处登录后可见!