

原文标题 :Building a Convolutional VAE in PyTorch
在 PyTorch 中构建卷积 VAE
用神经网络生成新图像?
深度学习在计算机视觉中的应用已经从图像分类等简单任务扩展到自动驾驶等高级任务——神经网络揭示的最迷人的领域之一是图像生成。
随着生成对抗网络 (GAN) 在内容生成方面的能力和成功,我们经常忽略另一种类型的生成网络:变分自动编码器 (VAE)。本文讨论了 VAE 的基本概念,包括架构和损失设计背后的直觉,并提供了一个基于 PyTorch 的简单卷积 VAE 实现,用于基于 MNIST 数据集生成图像。
什么是 VAE?
Autoencoder
为了理解 VAE 的概念,我们首先描述一个传统的自动编码器及其应用。

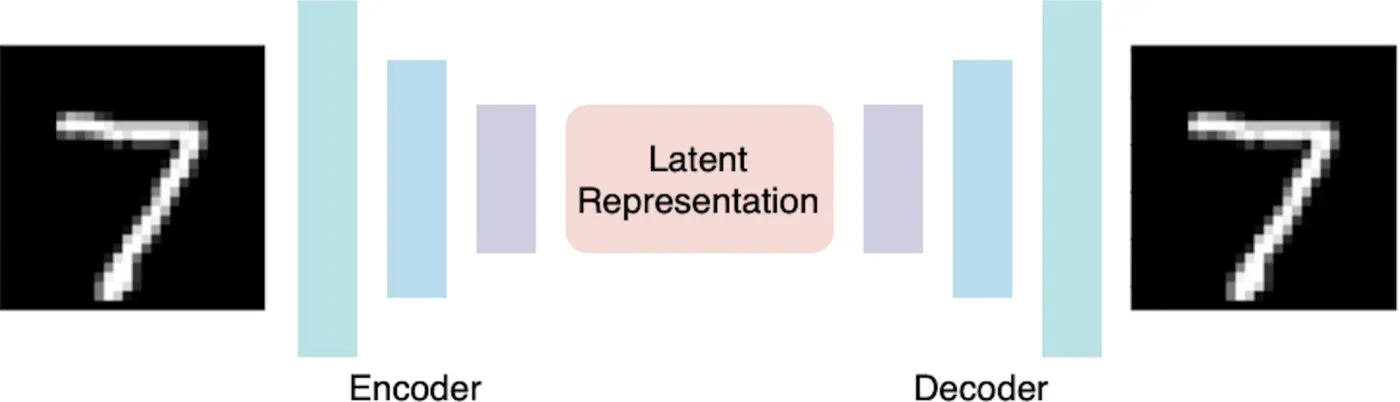
在传统的计算机科学中,我们一直在尝试找到将某个文件(无论是图像还是文档)压缩成更小的表示形式的最佳方法。自编码器是一种特殊类型的神经网络,具有瓶颈层,即潜在表示,用于降维:


其中 x 是原始输入,z 是潜在表示,x’ 是重构输入,函数 f 和 g 分别是编码器和解码器。目的是最小化重建输出 g(f(x)) 和原始 x 之间的差异,以便我们知道较小尺寸的潜在表示 f(x) 实际上保留了足够的特征用于重建。
除了满足降维的需要之外,自动编码器还可以用于去噪等目的,即将扰动的 x 输入自动编码器,让潜在表示学习只检索图像本身而不是噪声。当使用深度网络构建去噪自动编码器时,我们称之为堆叠去噪自动编码器。
用简单的词添加“变化”
在对自动编码器进行简短描述之后,人们可能会质疑如何改变这种网络设计以生成内容——这就是“变化”概念发生的地方。
当我们对自动编码器进行正则化,使其潜在表示不会过度拟合到单个数据点而是整个数据分布(有关防止过度拟合的技术,请参阅本文),我们可以从潜在空间执行随机抽样,从而生成看不见的来自分布的图像,使我们的自动编码器“变分”。为此,我们在损失函数设计中加入了 KL 散度的思想(有关 KL 散度的更多详细信息,请参阅本文)。以下部分深入探讨了使用 PyTorch 从头开始构建 VAE 的确切过程。[0][1]
Computing Environment
Libraries
整个程序仅通过 PyTorch 库(包括 torchvision)构建。在评估结果时,我们还使用 Matplotlib 和 NumPy 库进行数据可视化。可以按以下方式导入库:
Dataset
为简化演示,我们从最简单的视觉数据集 MNIST 训练了整个 VAE。 MNIST 包含 60000 张训练图像和 10000 张测试图像,显示从 0 到 9 的手写数字字符。
Hardware Requirements
由于 MNIST 是一个相当小的数据集,因此可以纯粹在 CPU 上训练和评估网络。不过,在其他更大的数据集上使用时,建议使用 GPU 进行计算。要确定是否使用 GPU 进行训练,我们可以首先根据可用性创建可变设备 CPU/GPU:
Network Architecture

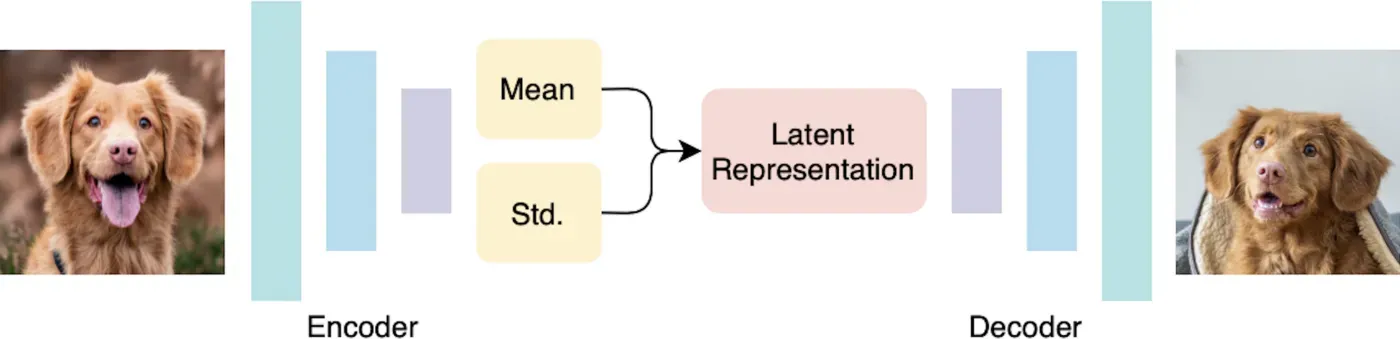
我们的 VAE 结构如上图所示,它包括一个编码器、解码器,以及在它们之间重新参数化的潜在表示。
编码器——编码器由两个卷积层组成,后面是两个分离的全连接层,它们都将卷积特征图作为输入。两个全连接层在我们预期的潜在空间的维度上输出两个向量,其中一个是均值,另一个是方差。这是 VAE 与传统自动编码器之间的主要结构差异。
重新参数化——通过计算均值和方差,我们随机抽取一个可能在给定分布中发生的点,该点将用作输入解码阶段的潜在表示。
解码器——解码器类似于传统的自动编码器,有一个全连接层,后跟两个卷积层,根据给定的潜在表示重建图像。
我们可以使用 PyTorch 构建上述 VAE 结构的组件,如下所示:
Training Procedure
Loss Function
VAE 的核心概念之一是其设计的损失函数。简而言之,我们试图设计损失,使其能够根据给定的图像很好地重建,但也属于整个分布,而不是仅对图像本身过度拟合。因此,VAE 损失是 的组合:
二元交叉熵 (BCE) 损失——计算重建图像与原始图像的像素间差异,以最大化重建的相似性。 BCE 损失计算如下:


其中 xᵢ 和 x’ᵢ 分别表示原始和重建的图像像素(总共 n 个像素)。
KL-Divergence Loss — KL 散度衡量两个分布的相似性。在这种情况下,我们假设分布是正态的,因此损失设计如下:

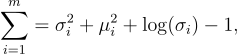
这是通过我们对潜在向量(大小 m)中每个值的预测均值和 sigma 计算得出的。
Training
以下代码显示了训练过程。我们将批量大小设置为 128,学习率设置为 1e-3,将 epoch 总数设置为 10。
请注意,为简单起见,我们在这里只进行了纯训练。但是,建议在每个 epoch 之后,我们都会在测试集上计算验证,以防止在训练期间出现任何过度拟合。当验证损失达到最低点时,也应该保存检查点。


Visualisation
训练后,我们可以使用以下代码可视化结果:

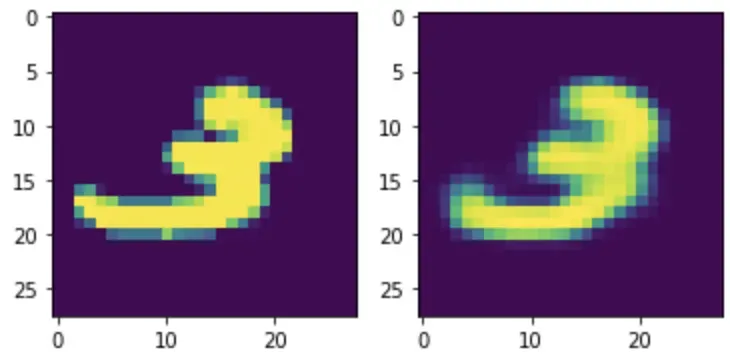
从可视化中我们可以看出,我们已经成功地在原始数字的基础上生成了数字数字,略有不同,这最终是VAE试图实现的!
Conclusion
所以你有它!希望本文为您提供有关如何从头开始构建您的第一个 VAE 的基本概述和指导。完整的实现可以在以下 Github 存储库中找到:
谢谢你能走到这一步🙏!我将在计算机视觉/深度学习的不同领域发布更多信息。请务必查看我关于一次性学习的另一篇文章!
文章出处登录后可见!