

原文标题 :Top Deep Learning Papers of 2021
2021 年顶级深度学习论文
我们都讨厌对文章进行冗长无意义的介绍,所以我会直奔主题。以下是一些我认为 2021 年最有趣和最有前途的深度学习论文。
我们的想法是简短地解释它们,并结合非常简单/非常困难的措辞,这样这篇文章对初学者和知识渊博的人可能会有一些帮助。话虽如此,正如每个意大利水管工都会说的那样,我们开始吧!


⚠️ Caution!
主题的选择是个人的且非常有偏见的,所以不幸的是,它们将涵盖更多的计算机视觉主题而不是 NLP,更少的 GAN 等等……你仍然感兴趣吗?好的!
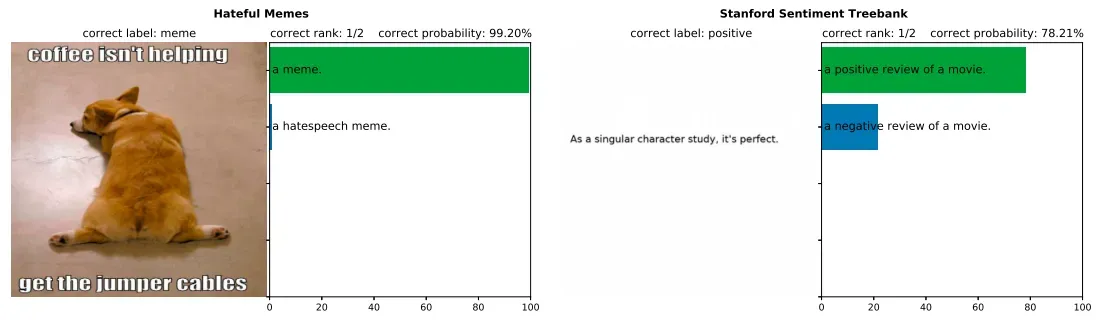
剪辑(https://arxiv.org/pdf/2103.00020.pdf)[0]
视觉+语言学习很流行📈!主要负责的是一篇 OpenIA 论文,它使得图像识别任务的缩放变得更容易,因为它不需要耗时的 ImageNet 手动标记。它从原始文本而不是手动确定的标签中学习,归档 State Of The Art 结果产生了几个著名的数据集。
这是一个新的学习理念吗?不,但这是迄今为止最雄心勃勃的一个。他们收集了一个包含 4 亿个图像+文本对的数据集来训练最先进的模型:用于文本编码的修改过的 Transformer 架构和用于图像编码的几个 ResNet-50、ResNet-101、EfficientNet 和 Vision Transformer(全部修改)。表现最好的是Vision Transformer ViT-L/14。
它是如何工作的?简单的。对比学习。一种众所周知的零样本和自我监督学习技术。给定一对带有文本描述的图像,让它们靠得更近。给定一对带有错误文本描述的图像,将它们放在远处。这样,当用句子查询图像时,越接近的就是“更正确”的那个。
N 个带有 N 个文本描述的图像分别用图像和文本编码器进行编码,因此它们被映射到较低维的特征空间。接下来,使用另一个映射,即从这些特征空间到称为多模态嵌入空间的混合特征空间的简单线性投影映射,在该空间中,使用正负对的对比学习,通过余弦相似度(越相似)对它们进行比较。

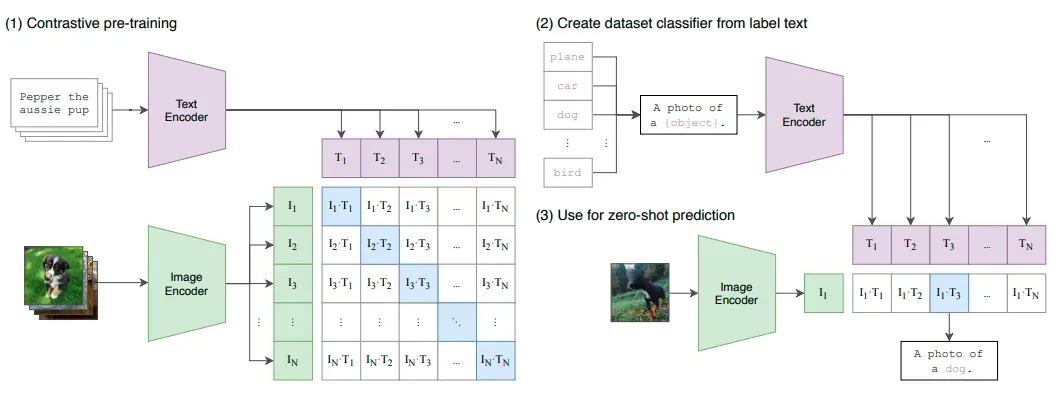
CLIP 能够解决对同一图像使用多个文本表示的问题,多义性并且在一些最著名的数据集(如 ImageNet、CIFAR 和 Pascal VOC)上的表现优于现有技术(而在其他数据集(如 MNIST、 Flowers102,KITTI 距离)。此外,由于它使用对比学习,它是一个零样本学习器,并且可以比以前的零样本模型更好地泛化到看不见的对象类别。

扩散模型(许多实现)
让我们在这里真实一点,我们都讨厌 GAN。他们的学习非常不稳定,需要花费大量时间进行微调,而该死的 NVIDIA 在 GitHub 中实现的 StyleGAN 使用起来简直令人发指。既然我们都承认了我们的秘密,我们几乎可以肯定地说,如果听到 GAN 不再是图像生成和翻译的最先进技术,没有人会哭泣。
您是在谈论 VQ-VAE 吗?没有。生成流?宁。我说的是扩散博士或:我如何学会停止担心并爱上噪音。


我们可以拍摄一张可爱狗的图像并为其添加一些噪声,我们仍然可以完美地看到狗,所以让我们添加更多、更多、更多,直到最初的狗图像无法识别并且你看到的只是随机噪声。好吧,如果一个非常有艺术感的人正在目睹逐步添加噪音的所有过程,那么艺术家将能够在每个时间步恢复该过程,以便可以再次恢复最初的狗。耶,狗哥回来了! 🐶。
给定一个数据分布,我们可以定义一个正向马尔可夫扩散过程,它在时间 t 添加高斯噪声,直到 t 足够大以至于图像几乎是各向同性的高斯分布,因此我们可以在神经网络的帮助下逐步反转该过程用于初始数据的分布近似(https://arxiv.org/pdf/2102.09672.pdf)。在每个时间步长,预测的图像噪声稍小。在 OpenAI 的 DDM 使用具有全局注意力的 UNet 架构和嵌入到每个残差块中的时间步长投影的情况下。[0][1]
是的,高质量的图像生成很酷,但是,可以调节输出吗?那么,Python 程序员可以不尖叫地学习 Java 吗?好吧,不……但是,是的,它可以被调节……谷歌的 SR3 模型通过学习使用这一系列细化步骤将标准正态分布转换为经验数据分布,将非常低分辨率的图像转换为清晰的高清图像。该过程的想法与上面解释的类似,但也考虑到去噪过程中的初始低分辨率图像作为与当前时间步长噪声图像的通道合并。该过程完成了 2000 次,并且还使用 UNet 架构进行了训练,并进行了一些花哨的修改。[0]


为了锦上添花,谷歌在这个问题上的最新工作:调色板。它不仅在几个图像到图像的翻译任务上生成最先进的结果,它也不需要特定于任务的超参数调整、架构定制或辅助损失(吸 GAN!)。与之前工作的主要变化是对 UNet 架构的更多修改和无类调节(仅图像调节)。[0]




____Mixers (many implementations)
计算机视觉的人讨厌像英国人和苏格兰人这样的 NLP 人!或者威尔士人和苏格兰人!或者日本人和苏格兰人!或苏格兰人和其他苏格兰人!该死的NLP!他们毁了 NeurIPS!
自注意力的变形金刚开始留在 NLP 领域。他们在每项语言任务上都表现得非常出色,并且可以轻松扩展到大型数据集。但是当有人想出将这个概念引入计算机视觉的想法时,和平被打破了。我们都说“不可能进行逐像素注意!”、“这行不通!”、“内存太密集了!”直到同一个人使用 16×16 补丁执行注意力并优于几个图像分类 SOTA。计算机视觉人员,我们为这次入侵感到震惊“诺姆乔姆斯基是对的……智能来自语言……”。这一切似乎都消失了,每篇 CV 论文都使用了一些自注意力机制,从自我监督到图像到图像(甚至去噪!我从没想过我们会失去去噪……)。突然间,如果你没有 NASA 计算机和整个谷歌作为数据集,你就出局了。
但后来它来了。就像夏天的微风在你耳边低语:“MLP-Mixers……”。对 NLP 仇恨者的救赎以不太出乎意料的个人的形式出现,即这场游戏中的棋子:感知器。因为没有人忘记感知器 WRIGHT 的重要性和力量?突然间,一切都变得有意义了,Vision Transformers 的表现完全来自于混合补丁!好的!一些每个补丁的线性嵌入、混合层、全局平均池……等等,可以与 Vision Transformers 竞争(尚未超越)的出色结果。仅使用多层感知器。[0]
MLP-Mixers 不依赖于输入数据,更容易训练并且不需要位置编码(这在技术上使它们对排列敏感)。
计算机视觉的人很满意,嗯,差不多。 MLP-Mixers 很好,但它缺少一些东西……唯一可以满足计算机视觉的东西:卷积!因此,ConvMixers 诞生了。真是个新生儿……它仍在双盲审查中,并且仅使用标准卷积的性能已经超过了 ResNets、Vision Transformers 和 MLP-Mixers。[0]

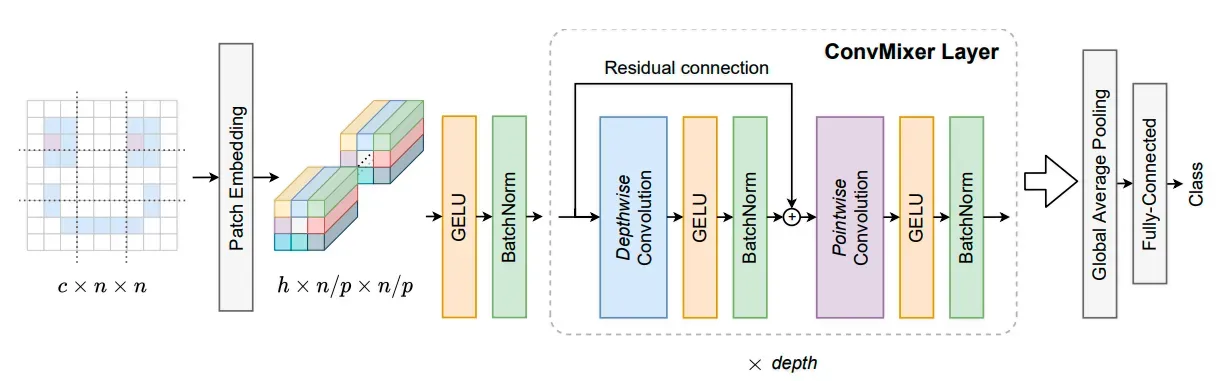
该架构模仿了 MLP-Mixers 的理念,即 Vision Transformer 的真正性能来自基于补丁的表示,而不是 Transformer 架构本身。 ConvMixers 在补丁上运行,在所有层中保持分辨率和大小,不会产生瓶颈,进行通道混合,整个架构适合 Tweet。突然之间,拥有普通深度学习 PC 的人可以再次使用 SOTA 技术,为人民带来力量!
没有对比对的自我监督学习 (https://arxiv.org/pdf/2102.06810.pdf)[0]
在 CLIP 部分,我们讨论了对比学习以及它如何通过最小化/最大化对之间的距离来学习嵌入。 CLIP 使用负对和正对来学习嵌入,但是像 BYOL 或 SimSiam 这样的方法不需要正+负数据对,只需使用 BYOL 进入连体神经网络(用于比较实体的模型)的同一图像的两个增强视图具有动量编码器和 SimSiam,在其分支之一中使用停止梯度操作。两者的想法是一个分支(预测器分支)与另一个分支(在线分支)学习相同,因此存在一种平衡,以确保在线和目标表示之间的任何匹配都不会仅归因于预测器权重。权重衰减和停止梯度有助于这种平衡。它们都更高效、更简单,并且需要更低的批量大小,同时还保持 SOTA。

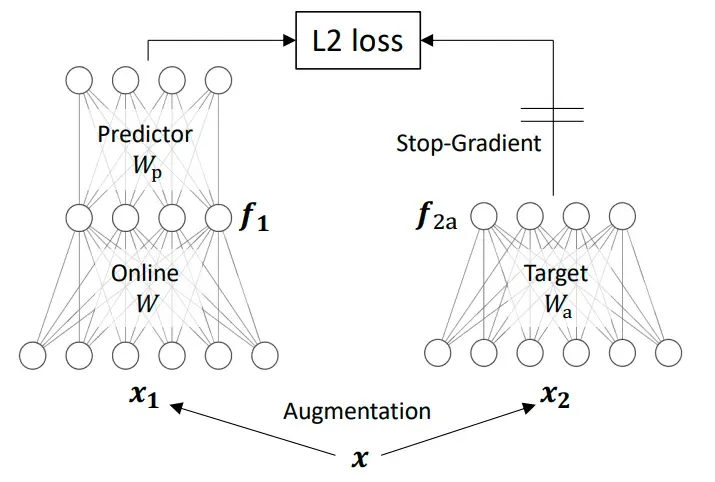
链接在章节标题上的论文解释了这些方法背后的魔力。事实证明这是数学,数学中无聊的部分。他们通过简化导致一些观察结果的动力学来调试模型的数学:更大的权重衰减有助于崩溃,因为在线网络需要沿着预测器增长,因此权重衰减会减慢预测器的速度,同时还能正确地模拟增强的不变性;较大的预测器学习率可以与较大的权重衰减相同。
还引入了 DirectPred 作为预测器,它通过估计预测器输入的相关矩阵并将其权重设置为此函数来避免使用梯度下降。该相关矩阵是通过预测变量的权重和相关矩阵之间的特征空间对齐以及使用权重衰减收敛到不变抛物线来计算的。
呼……太浓了。
Honorable Mentions
在完成一些我认为今年有一定规模的惊人想法之前我想提一下(但不必在今年诞生)并且将在不久的将来出现在 IA 中:
- 如何在神经网络中表示部分整体层次结构。我将引用 Yannic Kilcher 的一个非常好的描述,我认为它比我以往任何时候都更好地描述了这篇论文:自动编码器和 RNN。 GLOM 将图像分解为对象及其部分的解析树。然而,与以前的系统不同,解析树是针对每个输入动态构建的,并且是不同的,而无需更改底层神经网络。这是通过多步共识算法完成的,该算法同时在图像的每个位置运行不同的抽象级别。 GLOM 目前只是一个想法,但它提出了一种全新的 AI 视觉场景理解方法。”[0][1]
- 知识蒸馏。神经网络变得越来越大,每年都需要更多的计算资源。将知识转移到较小的网络同时保持其准确性的一种方法是使用所谓的知识蒸馏。最初由 Hinton 定义(他无处不在)基本上是由学生-教师学习方法定义的,该方法将最重要的信息从一个巨大的网络提取到一个较小的网络。我认为这篇论文非常广泛地解释了 SOTA 和 KD 的新前景。[0]
- 自我/零/无监督学习。深度学习社区已经开发出令人惊叹的架构,这些架构可以真正受益于海量数据的训练。现在瓶颈在于数据收集和标记,这需要数小时的人工工作,这当然是非常低效的。这篇论文(专注于自监督学习)非常巧妙地解释了让网络生成自己的标签的优缺点,以及它如何改变网络的数据内部表示。[0]
- 胶囊网络。欣顿?,欣顿!我们在 GLOM 中提到了它,这个概念距离 2021 年还很遥远,但有件事告诉我,未来几年它的规模将会增长。主要思想是以观察概率及其姿势的形式向标准 CNN 添加更多结构。这样,图像识别获得了额外的空间鲁棒性,即图像上的排列。也拒绝将其与敌基督者(从生物学上讲)进行比较的池化的想法。[0]
- 生成流。无监督学习、强化学习、图像生成……你能想到的!标准化基于流量的分布模型将于今年夏天进入您的城市,并且会持续一段时间。 Amazon Alexa 的声音是使用这些生成的。这是一个容易理解的概念吗?不完全是?我应该放弃学习正常化流程的梦想吗?永不放弃!这是一种直接建模数据似然性的惊人方法,与 SOTA 图像和音频生成相比,它产生了惊人的结果,但是这个数学很强大,但是这样想:它只是需要更多的时间来获得其他概念的总体思路,你有这个![0]
我认为明年会有更多的东西我想包括,比如 Lambda 网络或深度黎曼流形学习,但一切都必须结束,我们已经到了我们的阶段。[0][1]
太棒了……这几乎是我今年在深度学习方面的经历。我希望我做得足够好,可以接受深度学习书呆子的批评。我不擅长告别,所以我会给你留下一段奶奶使用语音到文本识别键盘的视频。新年快乐!
在 LinkedIn 上关注我,在 GitHub 上查看我的项目!你喜欢这个故事吗?在下面发表评论并在您的社交媒体上分享![0][1]
PD:对于 NLP 与 CV 的笑话感到抱歉,我知道我们相处得很好❤️。也非常欢迎对任何缺失或不正确的任何评论。深度学习社区万岁🤖!
文章出处登录后可见!