PyTorch-04基础(基本数据类型、创建Tensor、对Tensor索引与切片、Tensor维度变换、Broadcast自动扩展)
一、基本数据类型
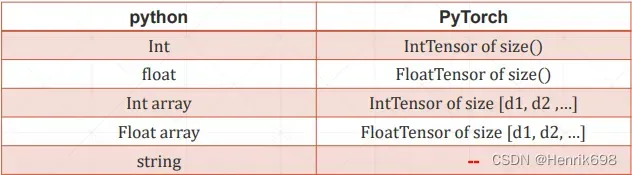
**对于python的string类型,在pytorch没有内键支持string的,pytorch不是一个完备的语言库,是一个面向数据计算的GPU加速库。**那么如何表达string呢?需要使用编码的方式。
有两种方法:独热编码(弊端是会使得矩阵很稀疏)、Embedding。
数据类型:
及时的同一个数据,放在不同位置其数据类型也是不一样。(即:CPU Tensor和GPU Tensor数据类型是不一样的,GPU数据类型相比于CPU都与需要在中间加一个cuda)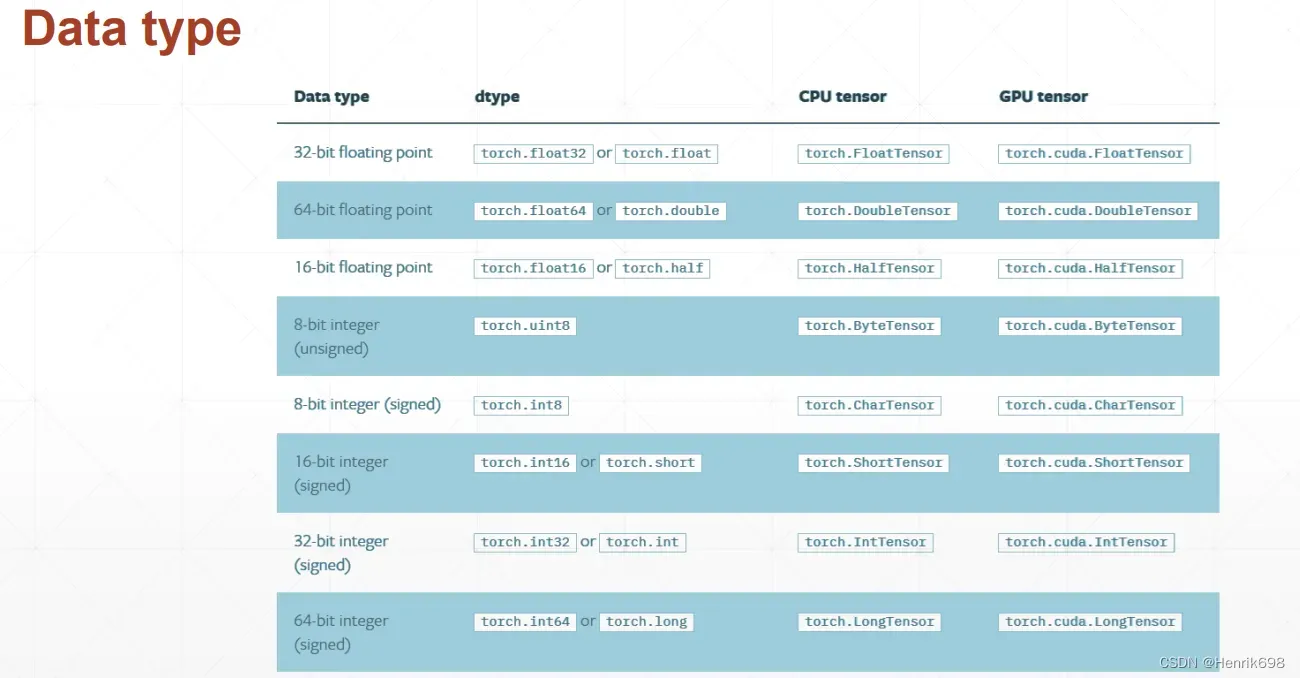
数据类型比较Type check:
import torch
a = torch.randn(2,3)
print(a)
#torch.randn(2,3)生成两行三列的矩阵,且数值是随机的正态分布上的数值来初始化的(正态分布:均值是0,方差是1)
#可以通过print打印出a.type(),通过print范式可以查看数据类型。
a_type1 = a.type()
print(a_type1)
#如果使用python自带的方法type(a),只能查看到基本的数据类型,没有提供额外的信息。不推荐。
a_type2 = type(a)
print(a_type2)
#判别数据是否为某一个类型,可以通过isinstance(要判别的数据,数据类型),该方法返回布尔值,如果要判别的数据是参数2的数据类型,则返回True。
print(isinstance(a,torch.FloatTensor))
#这里需要特别注意,一开始的a是部署在cpu上的,如果使用gpu的类型来判断,数据类型返回的是False。
print(isinstance(a,torch.cuda.FloatTensor))
#如果将一个数据部署在gpu上,用gpu对应的数据类型来判断,就会返回True。
b = a.cuda() #.cuda()将原本的部署在cpu上的数据搬运到gpu上
print(b)
print(isinstance(b,torch.cuda.FloatTensor))
Dim 0 / rank 0 标量(Dimension 0 / rank 0):
维度为0的标量,一般用于loss计算后的损失函数的均值。
import torch
#dimension为0的标量
a = torch.tensor(1.2)
print(a)
print(a.dim()) #查看维数
print(a.shape) #查看尺寸,.shape直接是一个成员,可以直接使用。
print(len(a.shape)) #查看shape的长度
print(a.size()) #查看形状,.size()是一个成员函数需要小括号。
print(a.type())
Dim 1 / rank 1 向量(vector):
维度为1的张量,一般用于Bias偏执中,以及拉伸后变成1维的Linear Input。
import numpy as np
import torch
#在pytorch中vector向量始终都称为张量
#张量可以是n长度的
#方法1:
#torch.tensor([具体的数据])这个是需要填入具体的数据。
a1 = torch.tensor([1.1])
print(a1)
a2 = torch.tensor([1.1,1.2])
print(a2)
#方法2:
#torch.FloatTensor(长度)这里需要填入具体张量的长度,且已经指定了类型。
a3 = torch.FloatTensor(1)
print(a3)
a4 = torch.FloatTensor(3)
print(a4)
#方法3:
#np.ones()函数返回给定形状和数据类型的新数组。
array = np.ones((2, 5), dtype=int)
print(array)
a5 = np.ones(6)
print(a5)
a6 = torch.from_numpy(a5)
print(a6)
#查看其张量长度:
print(a6.shape)
print(a6.size())
#查看其维度:
print(a6.dim())
Dim 2
维度为2的主要使用在Linear Input batch中,这里主要涉及一次输入多张图片。
import numpy as np
import torch
#方法1:
a = torch.randn(2,3) #.randn()表示随机的正太分布
print(a)
#方法2:
b = torch.FloatTensor(2,3)
print(b)
print(a.shape)
print(a.shape[0])
print(a.shape[1])
print(a.size())
print(a.size(0))
print(a.size(1))
Dim 3
维度为3的主要用于RNN Input Batch中,用于文字处理。
import numpy as np
import torch
a1 = torch.rand(2,2,3) #随机均匀分布,在0到1范围均匀给出一些值,要与randn()区分开,randn()是随机正太分布,正太函数是均值为0,方差为1。
print(a1)
print(a1.shape)
#通过list()可以将torch.Size()类型转为列表
print(list(a1.shape))
print(a1[0]) #取出了通道0所对应的矩阵
print(a1[0].shape) #矩阵的大小为2行3列
Dim 4
维度为4用于CNN卷积神经网络中。
import numpy as np
import torch
a1 = torch.rand(2,3,28,28)
#2表示两张图片batch,3表示三个通道channel,28表示行height\row,28表示列width\column。
print(a1)
print(a1.shape)
Replenish
import numpy as np
import torch
a1 = torch.rand(2,3,28,28)
#2表示两张图片batch,3表示三个通道channel,28表示行height\row,28表示列width\column。
print(a1)
print(a1.shape)
#.shape可以获得数据的形状;
# .numel()可以获得Tensor数据的大小(number of elements),即2*3*28*28=4704。
print(a1.numel())
#.dim()返回数据维度,这里返回的是4,表示4维。
print(a1.dim())
二、创建Tensor
从numpy和list来创建Tensor:
import torch
import numpy as np
#方法1:
#从numpy中引入数据1:
a1 = np.array([2,3.4])
#这里导进来的类型都是不变的,如果numpy时是int类型,导入后也是torch.int32类型。
print(torch.from_numpy(a1))
#从numpy中引入数据2:
a2 = np.ones([2,3]) #np.ones()传入矩阵的行列
print(a2)
print(torch.from_numpy(a2))
print('==================')
#方法2:
#从list中导入数据:
#导入一个非常小的数据集是不需要使用numpy作为载体。
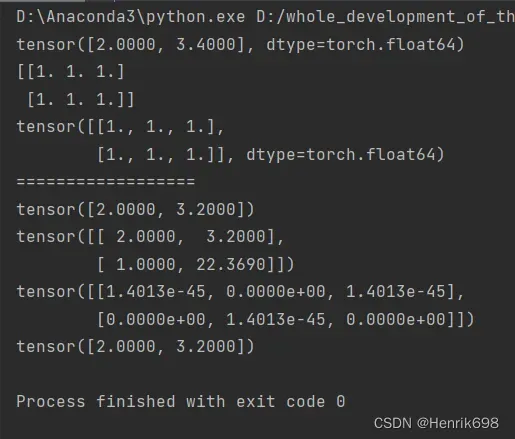
a3 = torch.tensor([2.,3.2])
print(a3)
a4 = torch.tensor([[2.,3.2],[1.,22.369]])
print(a4)
a5 = torch.Tensor(2,3) #传入的是数据的维度
print(a5)
a6 = torch.FloatTensor([2.,3.2]) #不推荐这样创建
print(a6)
#(重要)这里需要特别注意一下:
#torch.tensor()小写的tensor所接受的参数是现成的数据,要么是numpy要么就是list。
#torch.Tensor()和torch.FloatTensor(d1,d2,d3)大写的Tensor所接受的参数是shape,指定一个数据的维度,大写Tensor也可以直接接受数据,但不推荐这样使用,容易混淆。
生成未初始化的数据uninitialized
#未初始化的数据
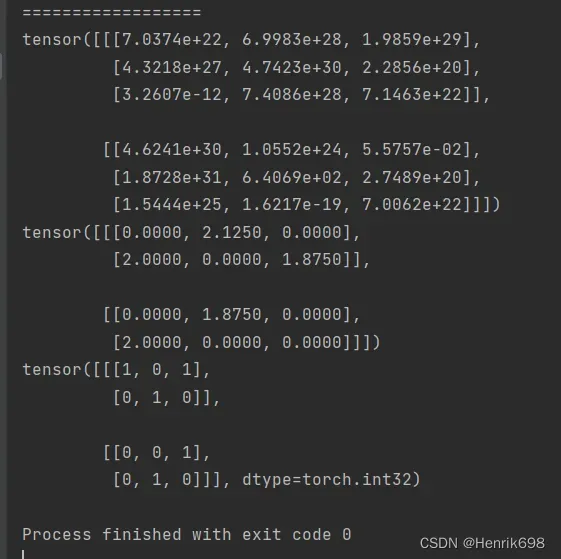
#torch.empty()返回指定维度的,未经初始化的数组
a7 = torch.empty(2,3,3)
print(a7)
a8 = torch.FloatTensor(2,2,3)
print(a8)
a9 = torch.IntTensor(2,2,3)
print(a9)
为初始化的Tensor会出现一个问题:
#为初始化的Tensor会出现一个问题:
#会存在有的数据非常非常大,有的数据非常非常小。
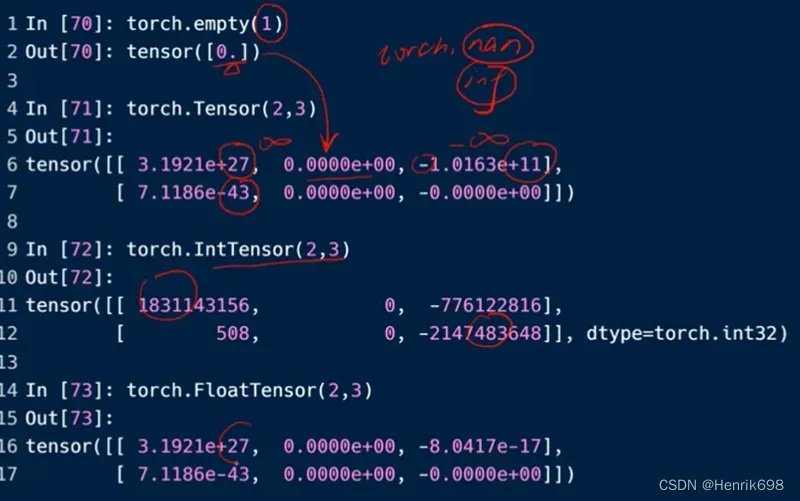
未初始化的情况可以使用,但是使用的时候仅作为一个容器,后面一定要将数据写进来。不然直接使会造成一些报错,比如torch.nan或则torch.inf这样的报错。
设置默认数据类型
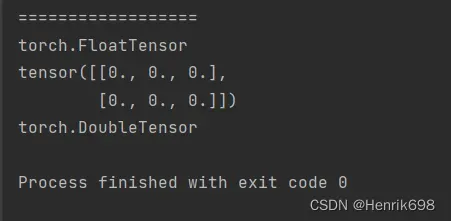
print('==================')
#设置默认数据类型
#torch.tensor([])和torch.Tensor(d1,d2),这两个默认的都是FloatTensor类型。
a10 = torch.tensor([1.2,3])
print(a10.type())
torch.set_default_tensor_type(torch.DoubleTensor)
a11 = torch.Tensor(2,3)
print(a11)
print(a11.type())
随机初始化 rand/rand_like, randint
推荐使用这种随机初始化:
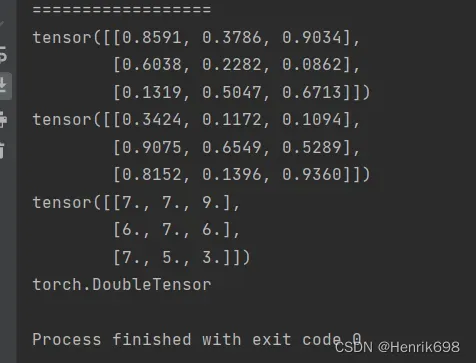
print('==================')
#随机初始化(推荐使用)
#rand函数是会随机产生0~1之间的数据,不包括1。
a12 = torch.rand(3,3)
print(a12)
#torch.rand_like()需要传入tensor,相当于将a12.shape读出来后送给rand()中。
a13 = torch.rand_like(a12)
print(a13)
#randint()需要传入一个极小值参数和一个极大值参数,且不包含极大值,并再传入一个[]shape。
a14 = torch.randint(1,10,[3,3],dtype=float)
print(a14)
print(a14.type())
randn
正太分布的随机化参数(均值为0,方差为1,数据会在0周围以方差为1来进行波动)。
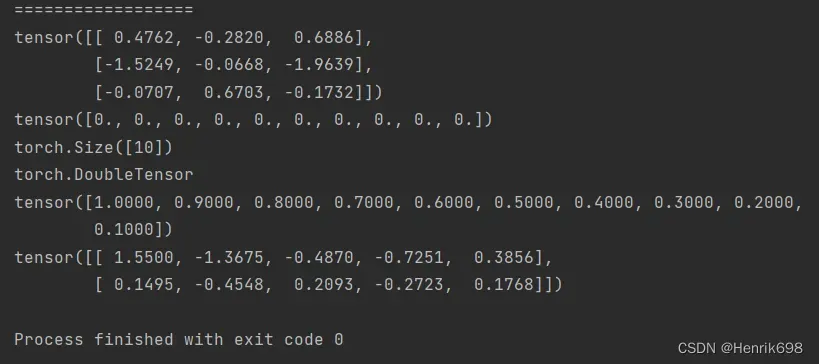
print('==================')
#randn正太分布的随机化参数:
a15 = torch.randn(3,3)
print(a15)
#指定mean和方差的正太分布的随机化参数:
#torch.full生成长度为10,且数值都为0的向量。
#均值
mean = torch.full([10],0.)#全部赋值为0
print(mean)
print(mean.shape)
print(mean.type())
#方差,是从1慢慢减小到0,且不包括0,减小的步长是0.1
std = torch.arange(1,0.,-0.1)
print(std)
#这里均值为0,方差是从1慢慢减小到0,这里之所以会出现大于1的数据出现,是因为最开始的方差为1比较大,所以会有大于1的数。
#这里需要注意torch.normal()传入的参数数据类型要都是浮点型,且mean和std的数据类型一致。否则会报错。
a16 = torch.normal(mean = torch.full([10],0.),std = torch.arange(1.0,0.0,-0.1))
print(a16.reshape(2,5))
full
print('==================')
#full (表示全部都是)
a17 = torch.full([2,3],7.)
print(a17)
print(a17.type())
#标量
a18 = torch.full([],7)
print(a18)
#1维
a19 = torch.full([1],7)
print(a19)
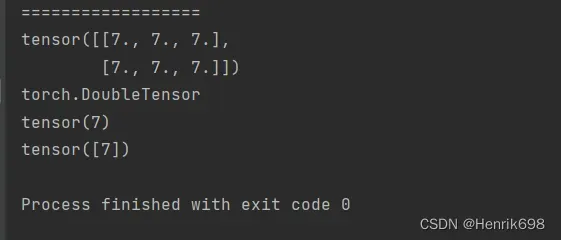
arange / range 递增递减生成等差数列
print('==================')
#arange/range 递增递减生成等差数列
a20 = torch.arange(0,10) #生成一个从0到9,且不含10的等差数列
print(a20)
a21 = torch.arange(0,10,2) #参数3为步长
print(a21)
a22 = torch.range(0,10) #pytorch是不建议使用range的,这里是包含10的
print(a22)
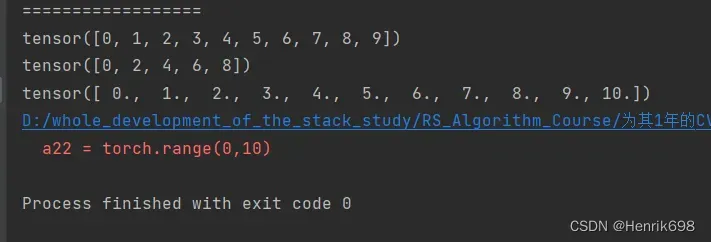
linspace / logspace 等分
print('==================')
#linspace / logspace 等分
#linspace
a23 = torch.linspace(0,10,steps=4) #注意这里的10是包含进来的。参数3不在是步长,而是数量,等分切出4个值。
print(a23)
a24 = torch.linspace(0,10,steps=10) #要切10个数出来,即分出10个数,就会比1大一点点
print(a24)
a25 = torch.linspace(0,10,steps=11) #要切11个数出来,即分出11个数,就刚好是等分切割。
print(a25)
#logspace的base参数可以设置为2,10,e等底数
#这里是从10^0到10^-1之间取出等差数列,即1到0.1之间。
a26 = torch.logspace(0,-1,steps=10)
print(a26)
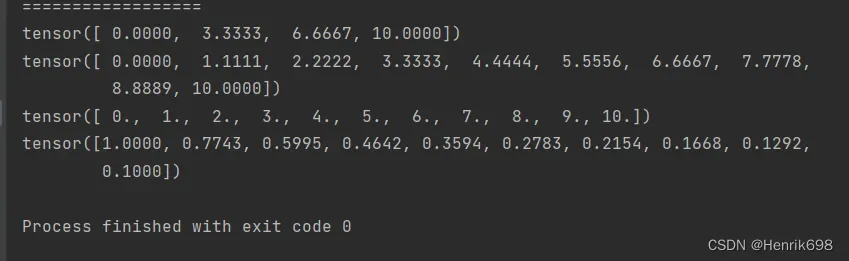
ones / zeros / eye / ones_like / zeros_like生成全部是0或全部是1的
print('==================')
#Ones / zeros / eye 生成全部是0或全部是1的
#torch.ones()传入shape就可以
a27 = torch.ones(3,3)
print(a27)
#torch.zeros()传入shape就可以
a28 = torch.zeros(3,3)
print(a28)
#对角项全部为1
#torch.eye()传入shape,也可以传入单一数值,表示方阵。
a29 = torch.eye(3,4)
print(a29)
a30 = torch.eye(3)
print(a30)
#此外也可以使用like方法:
a31 = torch.zeros_like(a30)
print(a31)
a32 = torch.ones_like(a30)
print(a32)
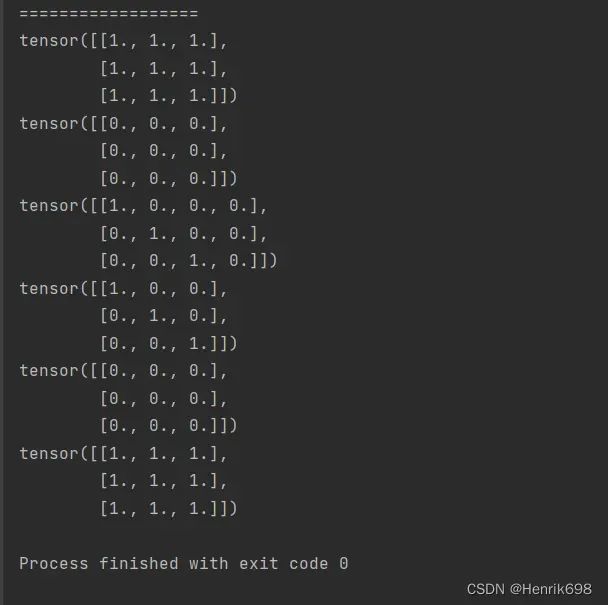
randperm 随机打散 随机种子
类似numpy中random.shuffle() 随机打乱序列,但是在pytorch中没有这个函数的,因此使用torch.randperm()生成随机打乱的索引,从而通过对tensor的索引控制以实现随机打乱的功能。
print('==================')
#randperm 随机打散 随机种子
#生成[0,10),不含10的10个索引。
a33 = torch.randperm(10)
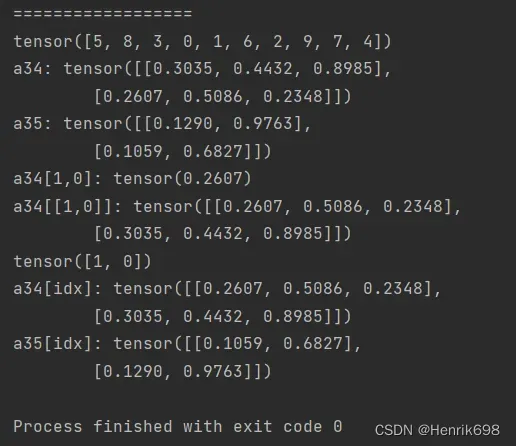
print(a33)
a34 = torch.rand(2,3)
print('a34:',a34)
a35 = torch.rand(2,2)
print('a35:',a35)
print('a34[1,0]:',a34[1,0])
print('a34[[1,0]]:',a34[[1,0]])
#以同一个随机索引种子,来横向大乱矩阵。
idx = torch.randperm(2)
print(idx)
print('a34[idx]:',a34[idx])
print('a35[idx]:',a35[idx])
三、对Tensor索引与切片
Indexing(类似于python中的索引方式)
print('==================')
#indexing
#类似于python中的索引方式
#卷积神经网络的一个输入,是一个4维的,torch.rand(batch size, channel, row, column)
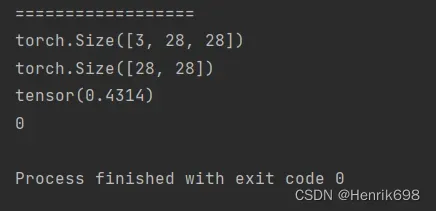
a36 = torch.rand(4,3,28,28)
#print(a36)
#这里可以使用一个数来进行索引,一个数来索引默认的是第一个维度,即batch size从最左边开始索引。
print(a36[0].shape)
#该索引表示,取出第0张图片的第0个通道
print(a36[0,0].shape)
#该索引表示,取出第0张图片的,第0个通道的,第2行,第4列的像素点,并打印出来。
print(a36[0,0,2,4]) #这个就是一个标量scale,维度为0。
print(a36[0,0,2,4].dim())
select first / last N (取连续的片段,取连续的前一部分和后一部分)
print('==================')
#select first / last N
#取连续的片段,取连续的前一部分和后一部分。
#取前两张或者后两张图片,该怎么办呢?
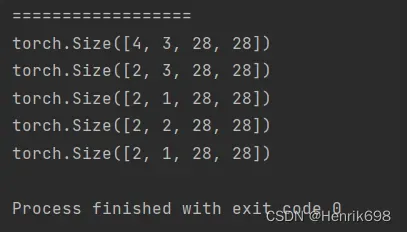
print(a36.shape)
#取前两张图片,这里2是不包含的,只有索引0和1,即取出了两张图片。
print(a36[:2].shape)
#在上面的基础上,对通道channel取连续的片段,这里1是不包含的,所以只有0所以,取出了两个图片的索引为0的通道。
print(a36[:2,:1,:,:].shape)
#如果:冒号后面没有写数字,表示一直取到最后。
#这里1:表示从索引为1的通道开始,一直取到末尾,一共就三个通道,所以取出了索引为1和索引为2的通道。
print(a36[:2,1:,:,:].shape)
#这里需要了解一下反向索引,对应一个向量[0,1,2],其正向索引为[0,1,2],而反向索引为[-3,-2,-1]
#这里-1:表示从索引为-1的通道开始取向最末尾,因为-1就是最后一个通道,所以只有1个通道被取出。
print(a36[:2,-1:,:,:].shape)
select by steps 选取不在是连续的而是有一定的间隔
print('==================')
#select by steps 选取不在是连续的而是有一定的间隔。
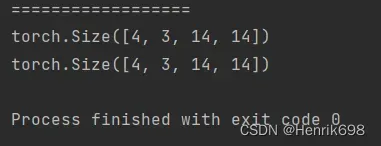
#对a36进行像素点的隔点采样:
#这里0:28:2表示从第0行到第27行(不包含第28),以步长为2进行选取;列的选取也是一样的。
print(a36[:,:,0:28:2,0:28:2].shape)
#::2与0:28:2所表达的意思相同
print(a36[:,:,::2,::2].shape)
#其实只有一种通用形式:start:end:step
select by specific index 在不同维度上选取特定索引
print('==================')
#select by specific index 给具体的索引
print(a36.shape)
#a36.index_select(0,torch.tensor([0,2])).shape
#.index_select()中:
#参数1表示第几个维度上进行操作,这是0,在第0维上选取,表示对batch size图片张数进行操作。
#参数2,torch.tensor([0,2])表示所要选取的索引号,这里就选取了索引为0和索引为2的图片。
#这里需要注意:参数2需要将[]list转换为tensor。
print(a36.index_select(0,torch.tensor([0,2])).shape)
#这里参数1表示在第1维进行选取,即在channel上进行选取
#参数2表示选取索引为1和索引为2的通道
print(a36.index_select(1,torch.tensor([1,2])).shape)
#这里参数1表示在第2维进行选取,即在行上进行选取
#参数2表会选取索引从0到27的所有行。参数2必须是填入tensor类型。
print(torch.arange(28))
print(a36.index_select(2,torch.arange(28)).shape)
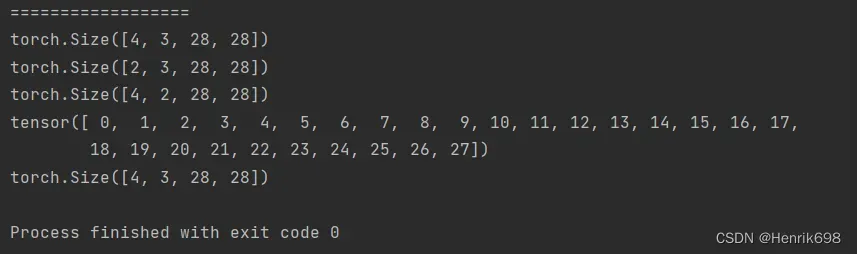
……(三个点,表示取出每个维度)
print('==================')
# ... 三个点,表示每个维度都取出
#当有...出现时,右边的索引需要理解为最右边
print(a36.shape)
print(a36[...].shape)
print(a36[0,...].shape)
print(a36[:,1,...].shape)
print(a36[...,:2].shape)
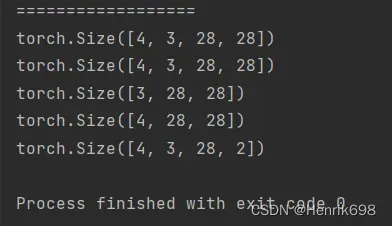
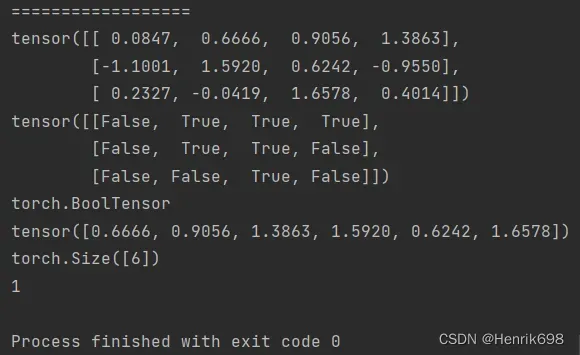
select by mask 使用掩码来索引,会将数据默认打平
使用掩码.masked_select(tensor矩阵,mask)来索引,使用的不是很多,因为这种方式是有一个弊端的,会将数据默认打平。
print('==================')
#select by mask
a37 = torch.randn(3,4) #三行四列的tensor
print(a37)
#a37中大于等于0.5的元素位置记为1,1表示为true,这样就获得了掩码
#构建掩码
mask = a37.ge(0.5)
print(mask)
print(mask.type())
#根据掩码来取,掩码为true的就取出
selectByMask = torch.masked_select(a37,mask)
print(selectByMask)
#取出来的数据就被打平了,成为了1维张量,长度取决于有多少元素满足掩码的要求。
print(selectByMask.shape)
print(selectByMask.dim())
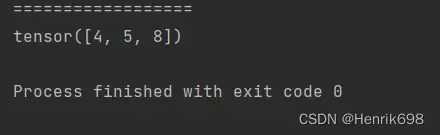
select by flatten index 也是将数据打平来选取的torch.take()
print('==================')
# select by flatten index 也是将数据打平来选取的torch.take(tensor矩阵,打平后所对应的索引(该索引列需要是tensor类型))
a38 = torch.tensor([[4,3,5],[6,7,8]])
print(torch.take(a38,torch.tensor([0,2,-1])))
四、Tensor维度变换
常用的API:
· View / reshape
pytorch中也提供了一个reshape函数,调用reshape函数,在保持tensor整个大小不变的情况下,可以将一个shape转变为任意的另一个shape。
· Squeeze / unsqueeze
挤压与增加维度的操作,第一个是删减维度Squeeze ,第二个是增加维度unsqueeze。
· Transpose / t / permute
矩阵的转至,针对多维的tensor,有单次的交换操作Transpose ,以及多次的交换操作permute。
· Expand / repeat
维度扩展,将小维度转化为高维度变量。
View / reshape
pytorch在0.3版本的时候默认的是view函数,为了跟numpy保持一致,在0.4以后pytorch增加了一个reshape,这两个是完全一模一样的,完全可以通用,使用任意一个都可以完成相应的功能。view和reshape操作的前提是要保证numel()元素个数一致即可,此外如果更改了维度,需要恢复,就必须要保证恢复时与原tensor矩阵所对应的维度信息相同才行,否则不能使用恢复后的tensor数据。
print('==================')
#view reshape
a39 = torch.rand(4,1,28,28)
print(a39.shape)
#使用view和reshape前提是保证numel()所有元素个数一致即可
#即要保证prod(a.size)==prod(a'.size)
#这里所表示的含义是:忽略掉位置信息以及通道信息。
#这种数据特别适合全连接层。
print(a39.view(4,28*28))
print(a39.view(4,28*28).shape)
#重要:view和reshape存在一个致命问题:失去了原本数据的维度信息。
a40 = a39.view(4,784) #改变了原有维度信息
print(a40.reshape(4,28,28,1).shape)
#这里是不会报错的,但是与原本的a39的维度信息是不同的,因为a39的维度信息是[batch,channel,row,column],而a40.reshape()后的维度信息是[batch,row,column,channel]。
#如果要恢复与a39相同,就必须保证所有维度信息是相同的。
print(a40.reshape(4,1,28,28).shape)
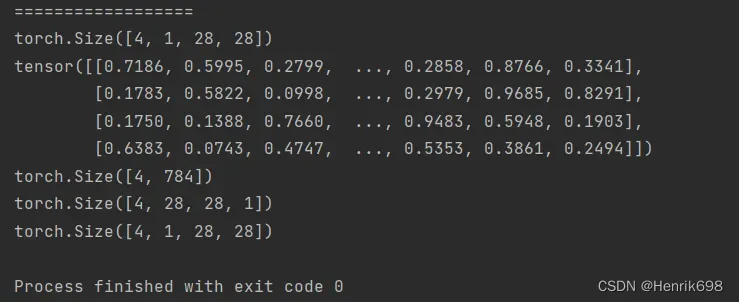
Flexible but prone to corrupt 需要保证view \ reshape更改维度后的元素数量与原tensor矩阵中元素数量相同,否则会报错
print('==================')
#Flexible but prone to corrupt
#如果reshape后numel()所对应的索引元素数量不同时,就会报错
a39.reshape(4,783) #原本的a39 = torch.rand(4,1,28,28)
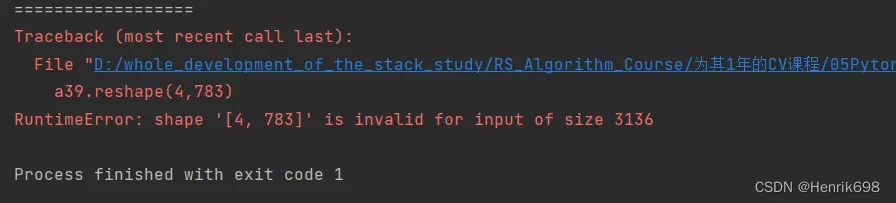
squeeze减少维度 v.s. unsqueeze增加维度
unsqueeze增加维度
print('==================')
#Squeeze减少维度 v.s. unsqueeze增加维度
a39 = torch.rand(4,1,28,28)
print(a39.shape)
#这里一个tensor张量的维度索引是[-a.dim()-1,a.dim()+1)
#a39的维度索引的[0,1,2,3,4),逆向维度索引是[-5,-4,-3,-2,-1,]
#正向维度索引是在索引对应的维度前插入,而逆向维度索引是在索引对应的维度后插入。
#这里a39的torch.Size([4, 1, 28, 28]),其中4所对应的维度索引就是0。
#这里.unsqueeze()所传入的参数是维度的索引值
print(a39.unsqueeze(0).shape)
print(a39.unsqueeze(-5).shape)
#这里的-1是指的原来的a的最后一个维度。在最后一个维度后面再添加一个维度。
print(a39.unsqueeze(-1).shape)
print(a39.unsqueeze(4).shape)
#注意从数据最后添加一个维度与从数据最开头添加一个维度是不同的:
print('注意从数据最后添加一个维度与从数据最开头添加一个维度是不同的:')
a40 = torch.tensor([1.2,2.3])
print(a40) #tensor([1.2000, 2.3000])
print(a40.shape) #torch.Size([2])
print(a40.unsqueeze(-1)) #最后添加一层维度是在数据里面包了一层tensor([[1.2000],[2.3000]])
print(a40.unsqueeze(-1).shape) #torch.Size([2, 1])
print(a40.unsqueeze(0)) #最开始添加一层维度是将整个数据外部在包一层tensor([[1.2000, 2.3000]])
print(a40.unsqueeze(0).shape) #torch.Size([1, 2])
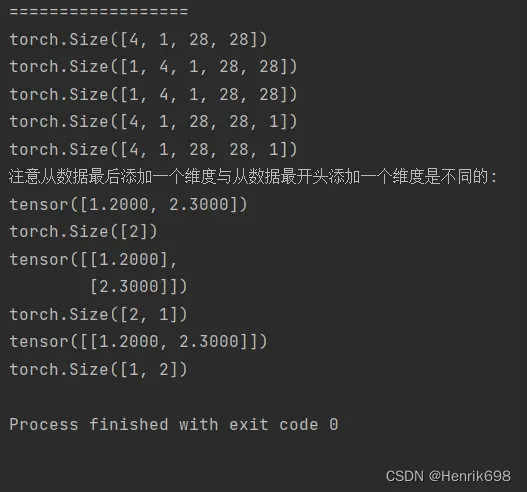
For example案例:(unsqueeze)
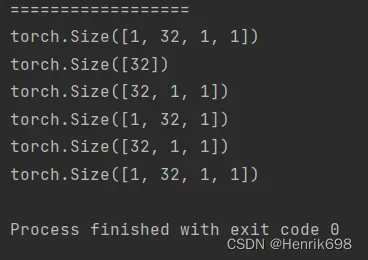
print('==================')
#for example案例
b = torch.rand(32) #bias
#bias相当于给每个channel上的所有像素增加一个偏置
print(b)
print(b.shape)
f = torch.rand(4,32,14,14) #feature map
#将f叠加在b上面,就需要对b进行升维,变成4维,f和b的dimension是不同的,只有维度相同才能进行累加操作。
b = b.unsqueeze(1).unsqueeze(2).unsqueeze(0)
# b = b.reshape(1,32,1,1)
print(b.shape)
#这样就可以与f进行累加了
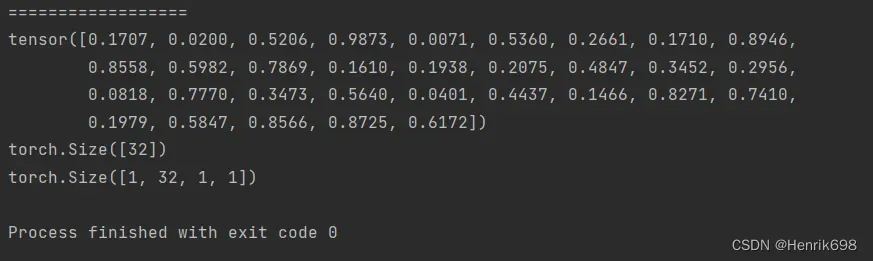
squeeze减少维度
print('==================')
#维度压缩 squeeze
b = torch.rand(32) #bias
b = b.unsqueeze(1).unsqueeze(2).unsqueeze(0)
print(b.shape)
#对b进行维度压缩
#不给指定的维度,全部进行压缩,将维度为1的都要压缩。
print(b.squeeze().shape)
#指定维度压缩
print(b.squeeze(0).shape)
print(b.squeeze(-1).shape)
print(b.squeeze(-4).shape)
#这里能挤压掉第1维的32吗,很显然不能,所以将没有变化的b直接返回了。
#即当前索引下的维度对应的不是1,则返回的是没有变化的
print(b.squeeze(1).shape)
expand / repeat 维度扩展
· expand:broadcasting (推荐使用)
本扩展不添加实际数据,只是改变理解方式,不主动复制数据。
· repeat:memory copied
该扩展增加了实际的数据,比如从一张照片扩展到4张照片时,该扩展会将后面所有的通道、行、列所对应的维度都拷贝一遍。
expand:
print('==================')
#expand / repeat 维度扩展
a41 = torch.rand(4,32,14,14)
b2 = torch.rand(32) #bias
b2 = b2.unsqueeze(1).unsqueeze(2).unsqueeze(0)
print(b2.shape)
print(b2.expand(4,32,14,14).shape)
#调用expand有一个前提,就是原来tensor的shape与之后tensor的shape二者之间的dimension必须一致,
#此外对于原来是1的维度,是可以扩张到N维的;对于原来是3的维度,扩展为M维的话是没办法执行的,3变成M不能够简单的复制,必须告诉其策略是什么,会报错。
#也就是所expand可以扩张的情况有两种,一种是1维扩张到N维,另一种是N维扩张到N维(即扩张前后维数不变)。
print(b2.expand(-1,32,14,14).shape)
#这里.expand()传入-1表示不扩张,保持不变
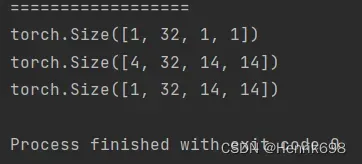
repeat:
print('==================')
#repeat:(不推荐)
a42 = torch.rand(4,32,14,14)
b2 = torch.rand(32) #bias
b2 = b2.unsqueeze(1).unsqueeze(2).unsqueeze(0)
print(b2.shape)
#这里repeat所传入的参数表示要拷贝的次数,比如第一个参数就是表示对应的维度上拷贝4次,32表示在对应的维度上拷贝32次(32*32=1024)。
print(b2.repeat(4,32,1,1).shape)
print(b2.repeat(4,1,14,14).shape)
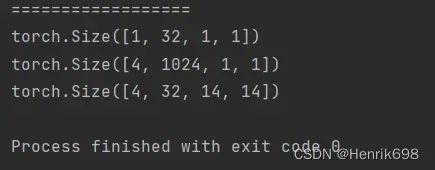
.t 矩阵转置操作
print('==================')
#.t 矩阵的转置操作
#.t方法只能适用于2维的矩阵,对于3维4维的会报错
a43 = torch.randn(3,4)
print(a43)
print(a43.t())

Transpose 矩阵维度交换操作
print('==================')
#transpose 矩阵维度交换操作,只能两两交换
#涉及到维度交换,原来数据的存储方式就会改变。
a44 = torch.rand(4,3,32,32)
print(a44.shape)
a45 = a44.transpose(1,3)
print(a45.shape)
#这里会报错,需要注意数据的维度顺序必须和存储顺序一致。
print(a45.view(4,3*32*32).view(4,3,32,32)) #这里会报错

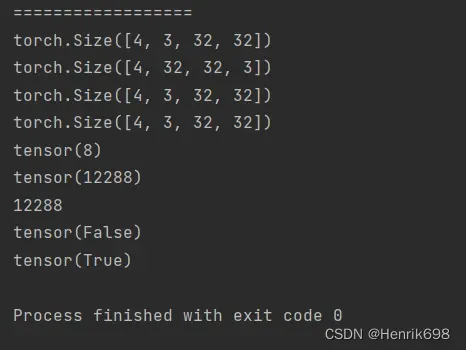
print('==================')
#transpose 矩阵维度交换操作,只能两两交换
#涉及到维度交换,原来数据的存储方式就会改变。
a44 = torch.rand(4,3,32,32)
print(a44.shape)
a45 = a44.transpose(1,3)
print(a45.shape)
#这里会报错,需要注意数据的维度顺序必须和存储顺序一致。
# print(a45.view(4,3*32*32).view(4,3,32,32)) #这里会报错
#.contiguous()将数据变成连续的
#view会导致维度顺序关系变模糊,所以需要人为跟踪。
print(a45.contiguous().view(4,3*32*32).view(4,3,32,32).shape) #这里是错误的,在第二个view时,没有恢复到a45的维度情况,与a45维度情况不同,所以是错的,一定要注意原始数据的维度。
a =a45.contiguous().view(4,3*32*32).view(4,3,32,32)
print(a45.contiguous().view(4,3*32*32).view(4,32,32,3).transpose(1,3).shape) #这里的是正确的,第二个view时,恢复到了a45维度的情况。
b = a45.contiguous().view(4,3*32*32).view(4,32,32,3).transpose(1,3)
print((a == b).sum() ) #这个说明view调整后a与b是不同的
print((b==a44).sum()) #这个说明b于a44是相同的,b有恢复成功,维度没有被打乱。
print(4*3*32*32)
#也可以使用torch.all()方法类判断两个tensor是否一样
print(torch.all(torch.eq(a44,a))) #反回布尔值,false表示不一样,true表示一样
print(torch.all(torch.eq(a44,b)))
permute 可以多维调整
print('==================')
# permute 可以多维调整,这里也会将内存顺序打乱,如果涉及到contiguous连续这个错误的话,就必须要用到.contiguous()这个函数来让内存顺序变得连续,也就是从新生成一片内存,在复制过来。
a46 = torch.rand(4,3,28,32)
print(a46.shape)
#permute可以按照维度索引来调整
print(a46.permute(0,2,3,1).shape)
五、Broadcast自动扩展
Broadcasting
·expand 可以自动扩展维度
·without copying data 在扩展时不需要拷贝数据
Key idea关键点:
·Insert 1 dim ahead: 如果最前面没有维度,则插入一个新的维度
·Expand dims with size 1 to same size: 这里将dim为1的维度扩展成另一个tensor矩阵所对应维度的量级(注意一定是所有dim为1的维度)(即tensorA与tensorB各自dim为1的都需要扩展成对方所对应维度的量级)。
example:
·Feature maps: [4,32,14,14]
将1维的偏执Bias(偏执是添加到每一个channel上的,所以这里Bias是[32])与四维的Feature maps进行对应位置元素相加呢?
=>为了让Bias符合Broadcasting的条件,需要对1维的Bias[32]后面插入两个维度[32,1,1],这一步是为了让Bias[32]对应Feature maps的tensor的channel维而补齐后面的两个维度,这一步是需要手动操作的。
=>[32,1,1]与Feature maps的tensor相比,最前面没有维度,因为32所对应的是Feature maps的tensor的channel的维度,则需要插入一个新的维度,变成[1,32,1,1],该步骤是boardcasting自动完成的。
=>[1,32,1,1]根据boardcasting的意思,将dim为1的扩展成Feature maps的tensor所对应的维度量级,扩展成为[4,32,14,14]。
·Bias: [32]=>[32,1,1]=>[1,32,1,1]=>[4,32,14,14]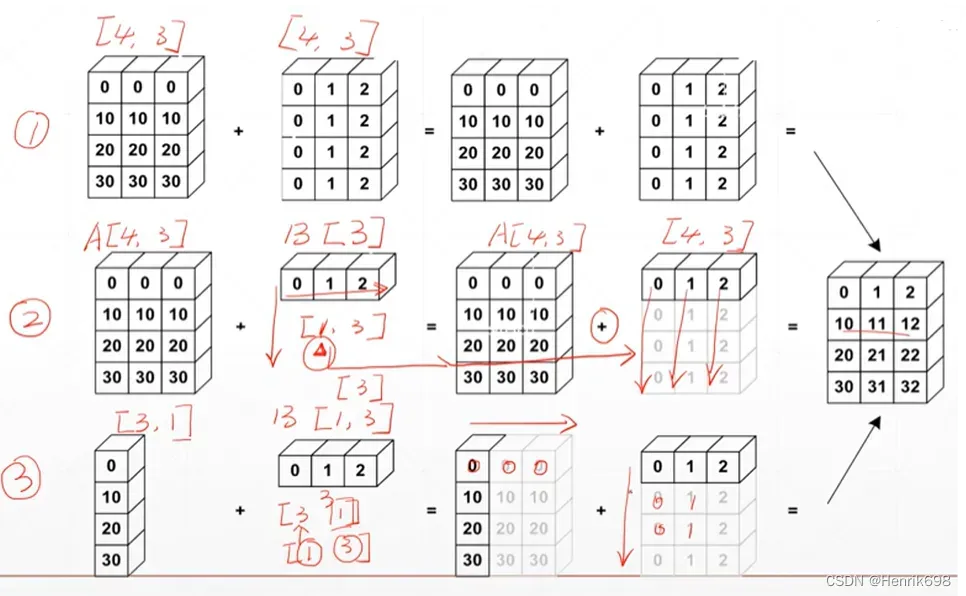
使用boardcasting的意义:
1、for actual demanding
·[class,students,scores] (这里是4个班级,32行表示32个学生,8列表示8门不同科目的分数。理解数据的内容和数据的shape之间的区别。)
·Add bias for every students: +5 score (这里加的5分可以看做是维度为1的[5])
·[4,32,8] + [4,32,8] (如果相加,就需要将[5]变成[4,32,8])
·[4,32,8]+[5.0] (这里[5]对应的是[4,32,8]的8的位置,因为8表示scores分数,我们要加的也是分数)
2、memory consumption内存消耗
example:
[class,students,scores] (这里是4个班级,32行表示32个学生,8列表示8门不同科目的分数。理解数据的内容和数据的shape之间的区别。)
如果不使用boardcasting的操作:
import torch
import numpy as np
a = torch.rand(4,32,8)
print(a.shape)
b = torch.tensor([5])
print(b.shape)
print(b.unsqueeze(0).unsqueeze(0).expand_as(a).shape) #只有先转换成维度都相同后才能相加。
使用boardcasting理论:(快捷方便)
import torch
import numpy as np
a = torch.rand(1,5,8)
print(a.shape)
b = torch.tensor([5])
print(b)
print(b.shape)
#通过boardcasting理论a和b可以直接相加,在相加过程中,boardcasting自动完成了上面b.unsqueeze(0).unsqueeze(0).expand_as(a)的相关操作。
c =a+b
print(c)
print(c.shape)
如何理解boardcasting的行为呢?how to understand this behavior?
·When it has no dim
·treat it as all own the same(加分数,所有学生,所有班级都加)
·[cass,student,scores]+[scores] (这种是可行的)
·When it has dim of size 1
·Treat it shared by all (加分数,只是针对某一部分学生加)
·[class,student,scores]+[student,1] (这种是不可行的)
重要:我们要从最后一个开始匹配,即最小维度开始匹配(match from last dim),因为我们相信高维的都是通识的(即维度shape靠左侧的),小维度的会各有个的不同(即维度shape靠右侧的)。人为设定从最后一个维度开始匹配,如果从最高维度开始匹配,就可以直接用boardcasting的规则进行匹配操作就好。
Case:
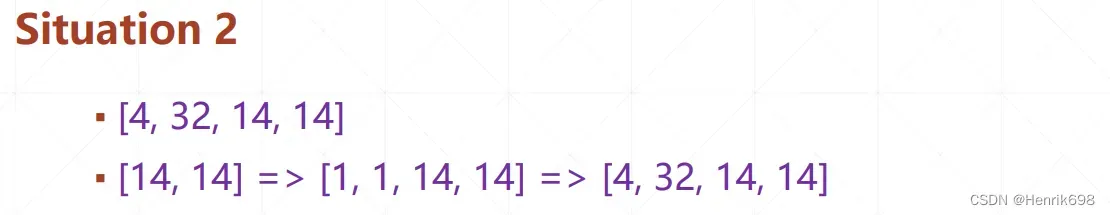

六、拼接拆分
Merge or split
▪ Cat (concat) (拼接)
▪ Stack (也是拼接,与Cat略有不同)
▪ Split (按照长度进行拆分)
▪ Chunk (按照数量进行拆分)
cat
▪ Statistics about scores
▪ [class1-4, students, scores]
▪ [class5-9, students, scores]
import torch
import numpy as np
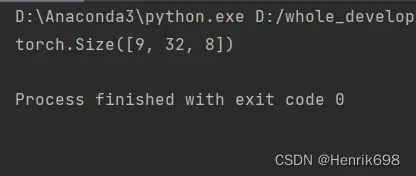
a = torch.rand(4,32,8)
b = torch.rand(5,32,8)
print(torch.cat([a,b],dim=0).shape)
文章出处登录后可见!