
官方逻辑回归链接
一,参数说明
1.1重要参数solver(求解器)详解
该参数用于优化问题,达到线性收敛的结果,相当于对逻辑回归进行优化
该参数对应的选项有
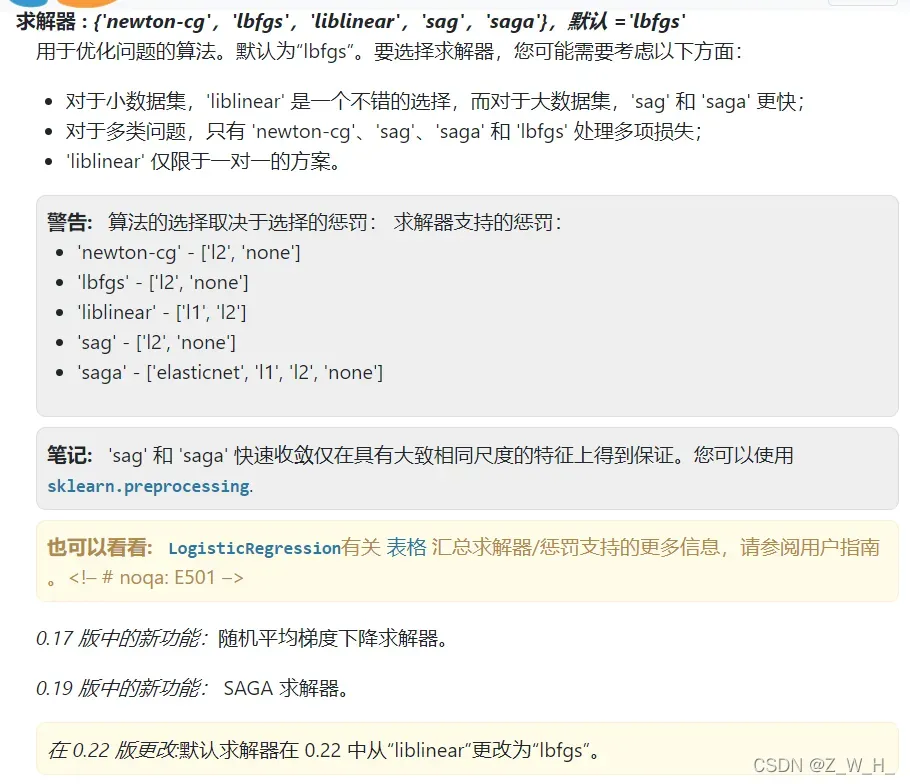
{‘newton-cg’,’lbfgs’,’liblinear’,’sag’,’saga’},默认 =’lbfgs’
newton-cg
传统的牛顿法是每一次迭代都要求Hessian矩阵的逆,这个复杂度就很高,为了避免求矩阵的逆,Newton-CG就用CG共轭梯度法来求解线性方程组,从而避免了求矩阵逆。
lbfgs
有限内存中进行BFGS算法
L-BFGS算法是一种在牛顿法基础上提出的一种求解函数根的算法
liblinear
官方网站
https://www.csie.ntu.edu.tw/~cjlin/papers/liblinear.pdf![]() https://www.csie.ntu.edu.tw/~cjlin/papers/liblinear.pdf是一个简单的解决大规模线性化分类和回归问题的软件包
https://www.csie.ntu.edu.tw/~cjlin/papers/liblinear.pdf是一个简单的解决大规模线性化分类和回归问题的软件包
是具有数百万个实例和特征的数据的线性分类器
sag
随机梯度下降算法
saga
SAGA算法是SAG算法的一个加速版本
如何区分两者
penalty,dual,intercept_scaling,max_iter
1.2其他参数说明
| 参数 | 参数说明 |
|---|---|
| penalty |
{‘l1’, ‘l2’, ‘elasticnet’, ‘none’}, default=’l2′
警告 某些惩罚可能不适用于某些求解器。请参阅参数 |
| dual | 双重或原始配方。对偶公式仅适用于使用 liblinear 求解器的 l2 惩罚。当 n_samples > n_features 时首选 dual=False。 |
| class_weight |
dict or ‘balanced’, default=None “balanced”模式使用 y 的值自动调整与输入数据中的类频率成反比的权重 如果指定了 sample_weight,这些权重将与 sample_weight(通过 fit 方法传递)相乘 |
| max_iter |
默认=100 求解器收敛的最大迭代次数 |
| multi_class |
{‘auto’, ‘ovr’, ‘multinomial’}, default=’auto’ 如果选择的选项是“ovr”,那么每个标签都适合一个二元问题。 对于“多项式”,最小化的损失是拟合整个概率分布的多项式损失,即使数据是二元的。 |
| random_state |
随机种子 当 |
| solver | {‘newton-cg’,’lbfgs’,’liblinear’,’sag’,’saga’},默认 =’lbfgs’ |
对于是否再逻辑回归之前做归一化或者标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X)逻辑回归模型中特征是否需要归一化? – 简书从前向过程来看:逻辑回归模型的输出是经过softmax的概率值,概率值的排序不受归一化的影响。从另一个角度来看,softmax其实也就实现了归一化的目的。 从反向过程来看:逻…https://www.jianshu.com/p/544c457a9947
二、优化方法(一下优化仅个人观点)
2.1方法一,使用自编代码求解权重,让后将权重作为参数传入
参数优化参考文献
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 读取文本数据,返回数据集和目标值
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_curve, auc
from sklearn.preprocessing import StandardScaler
def loadDataSet():
dataMat = []
labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
# 该数据集中,添加了一列并初始化为1,便于后续的计算,但是在其他数据集中,一般没有必要添加
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
# 运算的核心函数Sigmoid
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
def stocGradAscent0(dataMatrix, classLabels):
dataMatrix = np.array(dataMatrix) #将列表转换格式
m,n = np.shape(dataMatrix)
alpha = 0.01
weights = np.ones(n)
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
dataMatrix = np.array(dataMatrix) #将列表转换格式
m,n = np.shape(dataMatrix)
weights = np.ones(n)
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #变化的alpha
randIndex = int(np.random.uniform(0,len(dataIndex))) #随机样本下标
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex]) #从整个数据中去除已经使用过的样本
return weights
# 核心函数alpha*gradient更新回归系数
def gradAscent(dataMatIn, classLabels):
# 为了便于计算,mat将两个列表数据转换为numpy的数组
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose() # transpose矩阵转置
m, n = np.shape(dataMatrix)
alpha = 0.001 # 设置步长
maxCycles = 500 # 设置循环次数
weights = np.ones((n, 1)) # 初始化每个特征的回归系数为1
for k in range(maxCycles):
# 得到每一行的sigmoid值 (两个相乘得到z值)
h = sigmoid(dataMatrix * weights) # 矩阵相乘 sigmoid(sum(每个特征*每个系数)) 行*列,由于是矩阵相乘,所以在相乘时便求和了
# 用一直更新的回归系数求预测值,然后与真实值之间求误差,误差越来越小,则系数更新变化也越来越小,最后趋于稳定
error = (labelMat - h) # 每行分类与对应sigmoid相减 误差值越来越小了
# 数据集转置*误差 每条样本*该样本的误差值
weights = weights + alpha * dataMatrix.transpose() * error
return weights
# 1.读取训练数据集
# 设置随机种子
random_state_model = 40
filepath = r"文件路径"
#特征因子个数
feature_number = 特征个数
data = pd.read_excel(filepath) # reading file
data = np.array(data)
classifypointdata = data[:, 0:feature_number]
classifypointlabel = data[:, -1]
scaler = StandardScaler()
classifypointdata = scaler.fit_transform(classifypointdata)
# 切分数据,固定随机种子(random_state)时,同样的代码,得到的训练集数据相同。
# 此处运行完的结果可能是string类型之后用于计算时记得类型转换
train_data, test_data, train_label, test_label = model_selection.train_test_split(classifypointdata, classifypointlabel, random_state=random_state_model,
train_size=0.8, test_size=0.2)
train_data = np.array(train_data)
test_data = np.array(test_data)
train_label = np.array(train_label)
test_label = np.array(test_label)
#dataArr, labelMat = loadDataSet()
weights = gradAscent(train_data, train_label)
print(weights)
LC_model = LogisticRegression(random_state=random_state_model,class_weight=weights)
LC_model.fit(train_data, train_label)
y_test_pred = LC_model.predict(test_data)
print("Accuracy %0.6f:" % (accuracy_score(test_label, y_test_pred)))
y_test_predict_proba = LC_model.predict_proba(test_data)[:, 1]
y_test_two_model = np.array(test_label, dtype=int)
test_fpr, test_tpr, test_thresholds = roc_curve(y_test_two_model, y_test_predict_proba, pos_label=1)
test_roc_auc = auc(test_fpr, test_tpr)
print("auc %0.6f:" % (test_roc_auc))2.2方法二,综合以上基于求解器我们使用网格搜索进行参数优化,其主要是优化的参数是solver,penalty,max_iter
import pandas as pd
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_curve, auc
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler
import numpy as np
# 1.读取训练数据集
# 设置随机种子
random_state_model = 40
filepath = r"文件路径"
#特征因子个数
feature_number = 因子个数/特征值数
data = pd.read_excel(filepath) # reading file
data = np.array(data)
classifypointdata = data[:, 0:feature_number]
classifypointlabel = data[:, -1]
# 1.标准化处理
#标准差标准化(standardScale)使得经过处理的数据符合标准正态分布,即均值为0,标准差为1
#概念
#标准化:缩放和每个点都有关系,通过均值μ和标准差σ体现出来;输出范围是负无穷到正无穷
#优点
#提升模型的收敛速度
#提升模型的精度
#使用场景
#如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响
scaler = StandardScaler()
classifypointdata = scaler.fit_transform(classifypointdata)
# 切分数据,固定随机种子(random_state)时,同样的代码,得到的训练集数据相同。
# 此处运行完的结果可能是string类型之后用于计算时记得类型转换
train_data, test_data, train_label, test_label = model_selection.train_test_split(classifypointdata, classifypointlabel, random_state=random_state_model,
train_size=0.8, test_size=0.2)
# 2.构建RF模型
#参数是基于个人数据优化的结果
LC_model = LogisticRegression(random_state=random_state_model)
param_grid = [{'solver':['newton-cg'],'penalty':['l2','none'],'max_iter':[10,50,100,1000,2000]},
{'solver':['lbfgs'],'penalty':['l2','none'],'max_iter':[10,50,100,1000,2000]},
{'solver':['liblinear'],'penalty':['l2','l1'],'max_iter':[10,50,100,1000,2000]},
{'solver':['sag'],'penalty':['l2','none'],'max_iter':[10,50,100,1000,2000]},
{'solver':['saga'],'penalty':['l2','none','elasticnet','l1'],'max_iter':[10,50,100,1000,2000]}]
LC_GSC = GridSearchCV(LC_model, param_grid, cv=10)
LC_GSC.fit(train_data, train_label)
print(LC_GSC.best_params_)
print(LC_GSC.best_score_)
optimal_LC = LC_GSC.best_params_
LC_model = LogisticRegression(random_state=random_state_model,**optimal_LC)
LC_model.fit(train_data, train_label)
y_test_pred = LC_model.predict(test_data)
print("Accuracy %0.6f:" % (accuracy_score(test_label, y_test_pred)))
y_test_predict_proba = LC_model.predict_proba(test_data)[:, 1]
y_test_two_model = np.array(test_label, dtype=int)
test_fpr, test_tpr, test_thresholds = roc_curve(y_test_two_model, y_test_predict_proba, pos_label=1)
test_roc_auc = auc(test_fpr, test_tpr)
print("auc %0.6f:" % (test_roc_auc))2.3结果
两者的auc是相同的,准确率相差0.05,但是方法一只相当于方法二的一部分
版权声明:本文为博主Z_W_H_原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_39397927/article/details/114535874