


写在前面:《计算机模拟》;承办单位:中国航天科工集团公司第十七研究所;中文核心;每月一次;

1 摘要
- 提出方法)(模型):SP_GA算法优化LSTM模型参数 即 SP_GA_LSTM
- LSTM 模型参数难以确定,采用SP_GA来进行参数寻优
- SP_GA算法,在遗传算法中引入粒子群算法公式作为变异算子,并且在种群进化后期,进行模拟退火操作,一次提高收敛速度和全局搜索能力。【这一段话是非常费解的…】
2 结语(conclusion)
- 创新点(作者提出的东西):一种改进的混合遗传算法SP_GA。
- 创新出来的东西干什么用:可以用来优化SVM 、LSTM 等深度学习模型。
下图是实验章节中的实验对比图。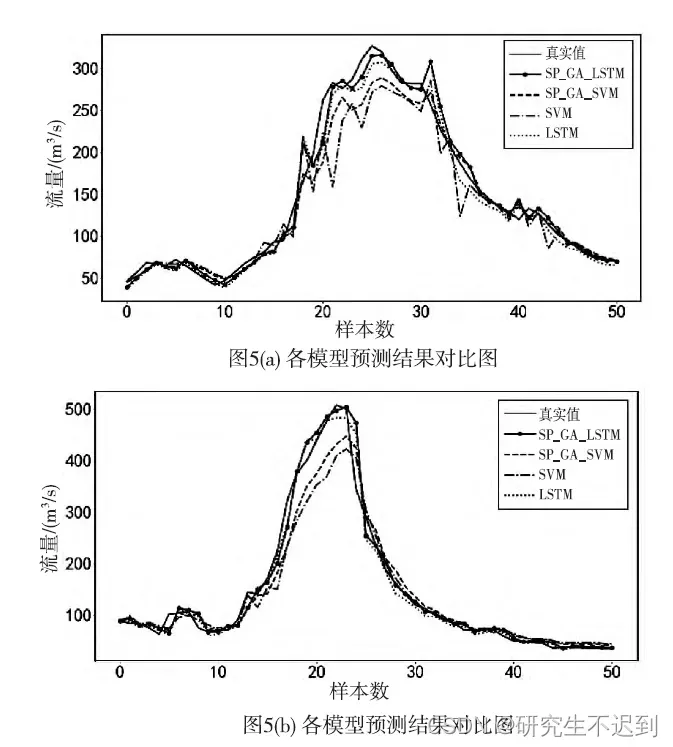

3 引言
- 流域径流趋势的模拟与预测是一个重要课题
- 与大河流相比,中小河流具有分布广、降水和下垫面空间异质性强、产流和汇流时间短、突发性强等特点。
- 与支持向量机SVM、BP神经网络、极限学习机ELM等模型相比,带有记忆功能的LSTM 既可对连续的径流数据进行处理,又能考虑到常时间 径流序列 的季节性和周期性,因此能更合理处理序列信息,实现序列预测。
- 为了更好地确定LSTM 的参数,就提出了一种混合遗传算法(SP_GA)
漳州龙山站时间径流预报
4 基于LSTM的流量预测模型
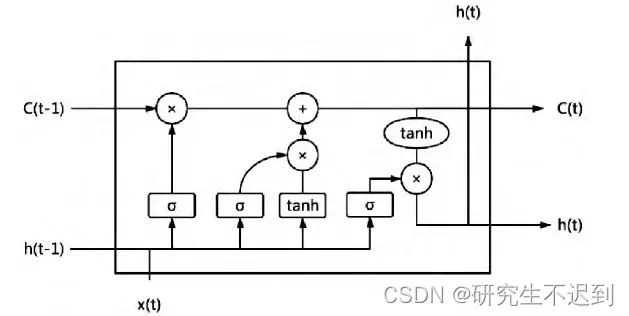
4.1 LSTM神经网络浅介绍
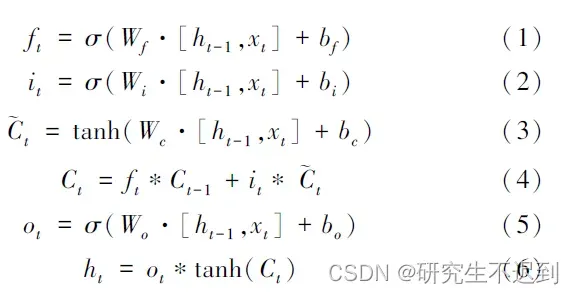


4.2 数据选择与处理
- 龙山流域作为研究对象,上游设有4个雨量站提供降雨信息,分别是月明、和溪、后眷、龙山。
- 实验 选取2010 年1 月到2014 年7 月的龙山站小时流量数据和龙山流域内4 个雨量站的时雨量数据共39998 条数据作为实验数据。取前28000 条数据作为训练样本数据,后11998 条作为测试样本数据。
- 预报因子的选择:运用相关系数分析法之后,确定将前5小时的龙山水文站 前期的流量值, 以及龙山流域内 雨量站前期降雨量值 选择为预报因子。
5 SVM + BP + LSTM 三种单预测模型建模
相关参数设置: BP与LSTM的结构设置为 25 – 50 -1, lr= 0.001, epochs = 100
SVM 选择径向基(RBF)核函数,惩罚因子C=100, 核函数参数

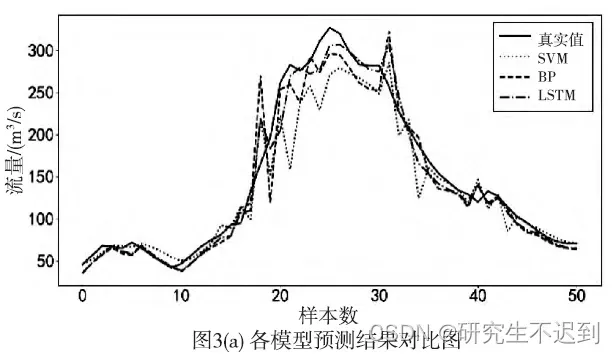

- 从图3 和表1 可以看出,SVM 的预测误差在三者中最大,预测曲线具有明显波动,且峰值预测效果最差;BP 的预测精度较SVM 有所提高,预测曲线与真实值贴合程度也更好;
- LSTM 的均方根误差和确定性系数为7. 95 和0. 909,在三个模型中最优,并且整体预测曲线和峰值预测最贴合真实值,说明LSTM 模型更具优势。
- 所以说,作者就使用了LSTM来进行参数优化,进行下面一系列的事情。
6 LSTM 模型参数优化及其预测模型
以下内容摘自文章内容:
LSTM 模型的非线性建模性能与3 个主要参数密切相关 : 隐含层节点数hidden_size、学习率lr、训练次数epoch。 【这一点还是需要研究的~~不能相信一家之言】
本文将通过混合遗传算法确定这三个参数。
6.1 遗传算法 GA
简介:遗传算法的基本思想是基于达尔文的进化论和孟德尔的遗传变异理论。主要步骤包括编码、种群初始化、选择、交叉、变异等操作。通过这些步骤,种群中个体的适应度越来越高,最终收敛到最适应环境的一组个体,从而得到问题的最优解。
6.2 混合遗传算法
作为典型的群体智能算法,遗传算法在寻找全局最优解方面具有独特的优势,但在局部搜索能力上明显不足。
- 可用于遗传算法过程中,并集成其他优化方法(爬山法、粒子群算法、蚁群算法、模拟退火算法),形成混合遗传算法




文章出处登录后可见!
已经登录?立即刷新