先贴一张核心流程图: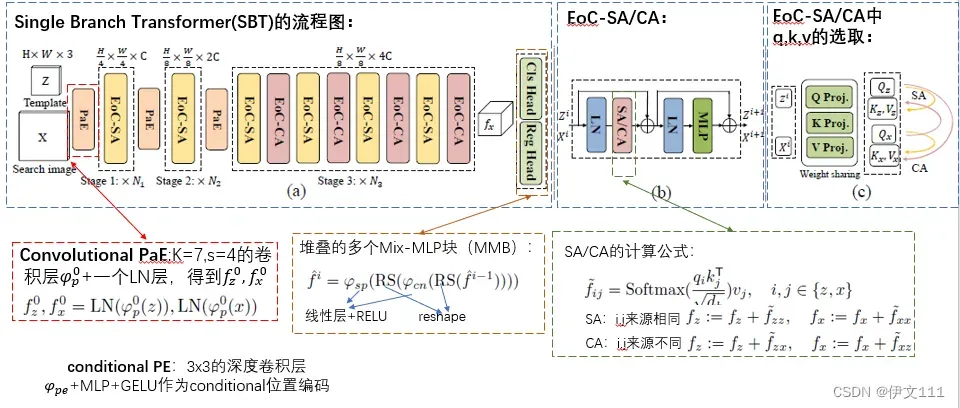 本文认为有必要为同一目标生成相干特征,以及与干扰物的对比特征。
本文认为有必要为同一目标生成相干特征,以及与干扰物的对比特征。
Abstract
背景:鲁棒性和判别能力是模板跟踪的两个基本要求。 Siamese network-like 算法提取的特征不能完全区分模板和干扰项,现在大多数算法都专注于设计鲁棒的相关操作。
本文:受到自/相关注意力的启发,提出a target-dependent feature network,将跨图像特征相关性深度嵌入到特征网络的多个层中,可以压制非目标的特征,拥有实例变化的特征提取能力。搜索区域的输出特征可以直接被用于预测模板位置,而不用额外的相关操作。
【注】:本文的核心是提出了一种用于跟踪的新的Backbone:Single Branch Transformer (SBT),将其他算法的backbone替换为SBT被称之为Correlation-Aware Trackers(CAT),如SiamFCpp-CA, DiMP-CA, STARK-CA, STM-CA。
1. Introduction
目标跟踪2大基本但矛盾的要求:1. 在目标形变下识别目标;2. 过滤掉背景中的干扰物。
现存算法的缺陷:2类解决以上问题方法:1. 通过孪生网络学习更有力的特征嵌入空间;2. 发展更鲁棒的相关操作,如Siamese cropping, online filter learning, Transformer-based fusion。现在大部分算法都集中在相关操作的设计,希望能抵抗干扰物对算法的影响。但这些跟踪算法中很少有人注意到这两个相互竞争的目标可能会使特征网络陷入目标-干扰器的困境,从而带来更多困难。
原因分析:1. Siamese 编码过程不知道模板和搜索图像,这削弱了学习嵌入的实例级区分;2. Backbone没有明确建模学习将两个竞争目标分开的决策边界,从而导致次优嵌入空间;3. 每个训练视频仅注释一个对象,而在推理过程中可以跟踪包括干扰物在内的任意对象。
本文观点:特征提取应该具有动态的实例变化行为,以便为 VOT 生成“适当的”嵌入以缓解困境。具体地,它需要在视频的所有帧中为同一对象生成连贯的特征; 另一方面,它需要为目标和具有相似外观的干扰物生成对比特征。
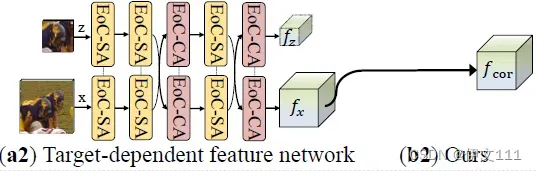
本文做法:在注意力机制上加入动态特征网络。提出SBT,允许2个图像的特征在每个阶段深度交互。直观地,交叉注意力权重逐渐过滤出目标不相关的特征;自注意力权重增强了目标的特征表达能力。因此,特征提取过程是目标独立且图像对不对称的,SBT将目标和干扰物进行区分同时保持不同目标之间的连贯特征。
效果如下图所示: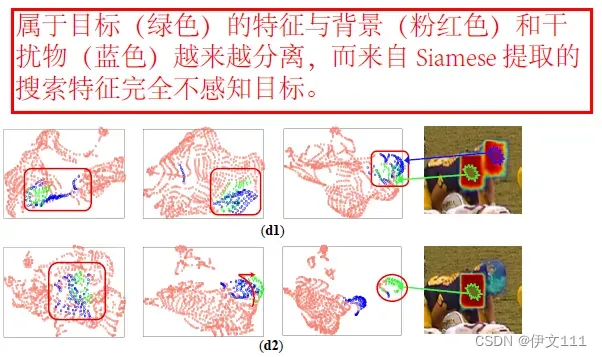
2. Related Work
Visual Tracking:
| 类别 | 解释 | 改进 |
|---|---|---|
| Siamese网络 | 相关改进包括注意力机制,在线模块,级联架构,更新机制,目标感知的模型精调 | 缺乏对干扰物的鉴别能力,即使相关改进但也带来了巨大的计算复杂度。 |
| DCF | 在线求解基于最小二乘的回归,改进包括快速梯度算法,端到端地学习,基于CNN的尺度估计 | 对复杂的手工优化及在有挑战性场景下缺乏实例级区分的特征质量高度敏感 |
| Transformer | 可以探索长时依赖 | 主要用于语言处理,在CV领域中难以正确初始化,计算代价高 |
Vision Backbone:
CNN, ViT等。但VOT的动态属性需要对模板和搜索区域不对成的编码,在先前的工作中还没有对这个方面有充分的关注。
3. Architecture
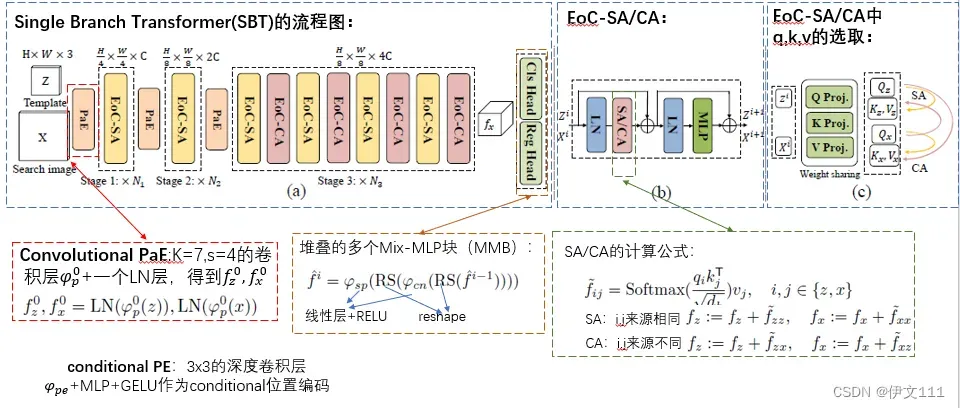
4. Empirical Study of SBT Instantiations (类似于消融实验)
下表的左边比较了SBT不同的注意力计算方式/位置编码方式/Patch嵌入方式的模型参数量等;右边比较了SBT在A_5设置下,每个阶段不同的特征维度/块的数量/特征图的步幅下模型的参数量等。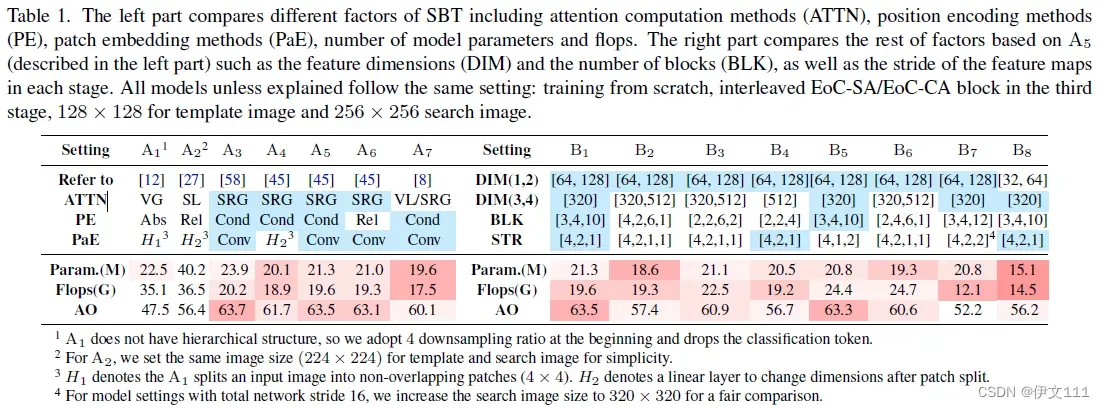
综上所述:
- hierarchical structure比单阶段效果好得多
- conditional位置编码影响不大
- convolutional PaE更实用
下图比较了不同EoC-CA/SA数量和位置对跟踪性能的影响: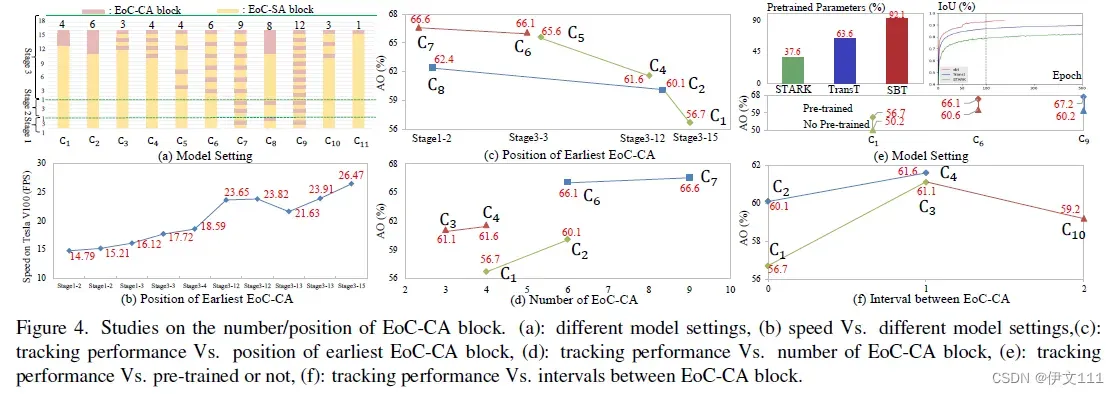
| 问题 | 结论 |
|---|---|
| Which attention computation is better for SBT tracker? | 只用SRG(Spatial-Reduction Global attention)块更好 |
| Do earlier and more EoC-CA blocks help to tracking better? | 不一定,EoC-CA分布越全面且均匀效果最好 |
| Is tracking performance related to the placement pattern of EoC-CA blocks? | EoC-CA和EoC-SA交错出现效果最好 |
| What is the optimal network variants for tracking model? | 其他设置相同时,3阶段比4阶段更优;SBT更偏好大的特征spatial size;很重要在block数量和通道维度之间平衡 |
| Does flexible design of EoC-SA/EoC-CA bring negative/positive effects? | early-cross和speed之间应该达到平衡 |
5. Single Branch Transformer Driven Tracking(理论分析)
5.1 Theoretical Analysis on SBT for Tracking
- SBT克服了深度跟踪器的本质限制——严格的平移不变性
- Cross-attention 的效果是依赖于深度的操作的两倍以上(cross-attention 可以分解为动态卷积)
- 分层特征利用被嵌入在serial pipeline中
5.2. Four Versions of SBT network
SBT的4个版本如下表所示: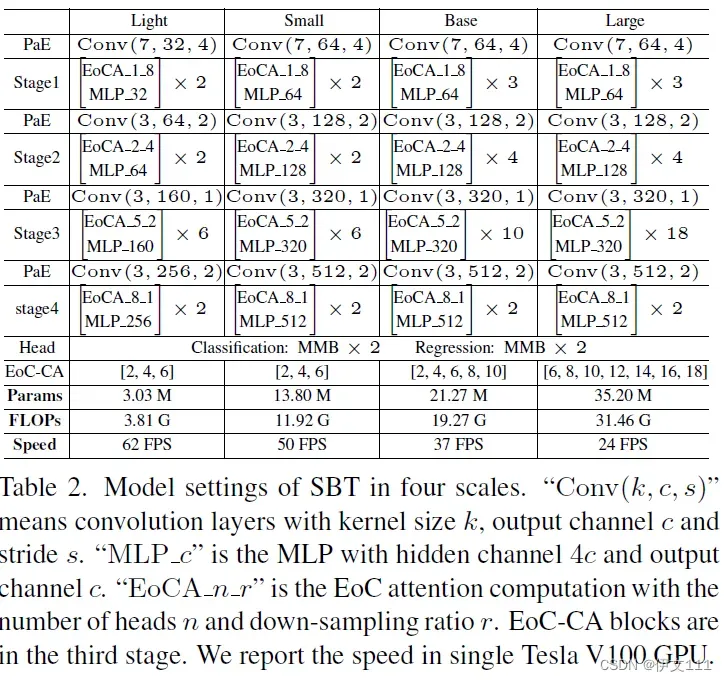
5.3. Correlation-Aware Feature for Other Trackers
本文将4个经典跟踪器的backbone替换为SBT,称之为Correlation-Aware Trackers (CAT),替换后算法的名称分别是SiamFCpp-CA. DiMP-CA. STARK-CA. STM-CA
6. Experiments
6.1 Implementation Details
| 参数 | 具体值 |
|---|---|
| 预训练 | 在ImageNet上先训练4阶段SBTwith分类head。 AdamW优化器300个epochs, 输出尺寸resize到224×224,使用了数据增强和正则化策略 |
| 在跟踪任务上精调 | 分类损失:交叉熵;回归损失:GIoU和L1损失。8 tesla V100 GPUs, batch size=160,模板尺寸128×128。搜索图像尺寸256×256。共600个epochs,其中每个epoch有50000个图像对。lr=10^-4 for head, lr=10^-5 for the rest, 衰减因子是10,分别在第200和400个epoch。训练数据集:LaSOT, GOT-10k, COCO, TrackingNet |
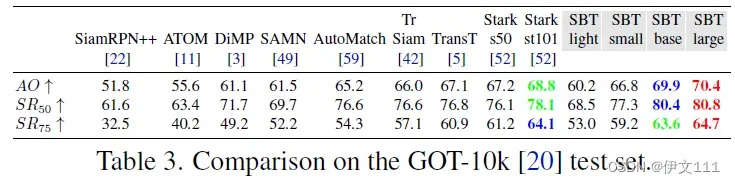
6.2 Comparison to State-of-the-Art Trackers
(1) GOT-10K
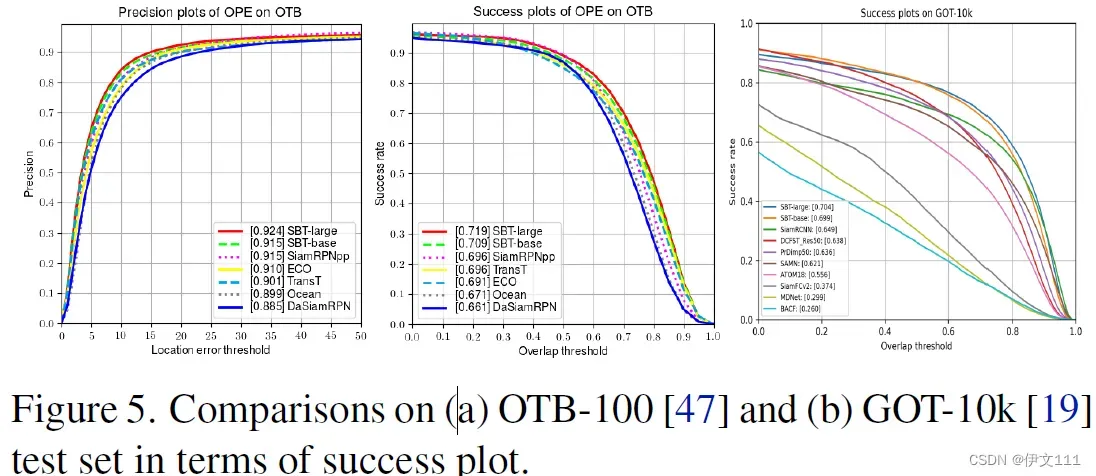
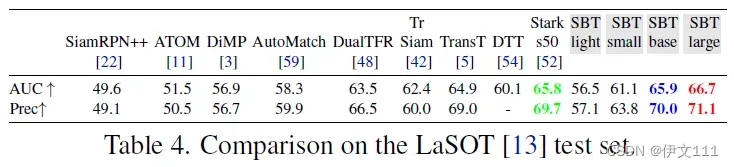
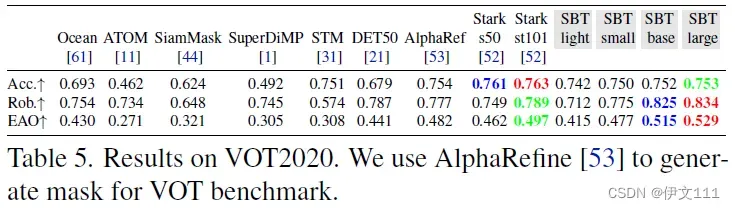
(2) OTB100/VOT2020/LaSOT
6.3 Improvement over Baselines
(1) Box-Level tracking
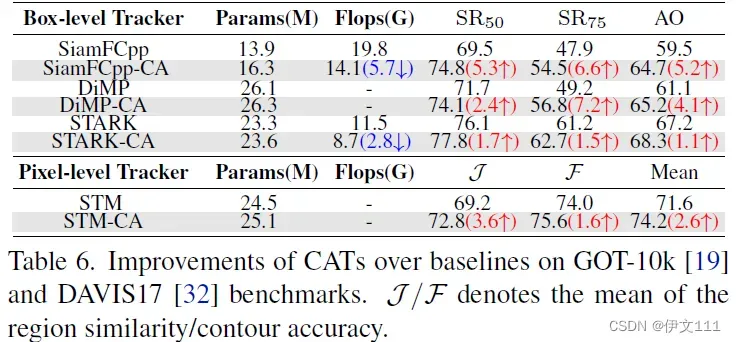
(2) Pixel-Level tracking
在多目标视频分割数据集上验证。
6.4 Exploration Study
(1)Correlation-embedded structure


(2)Target-dependent feature embedding
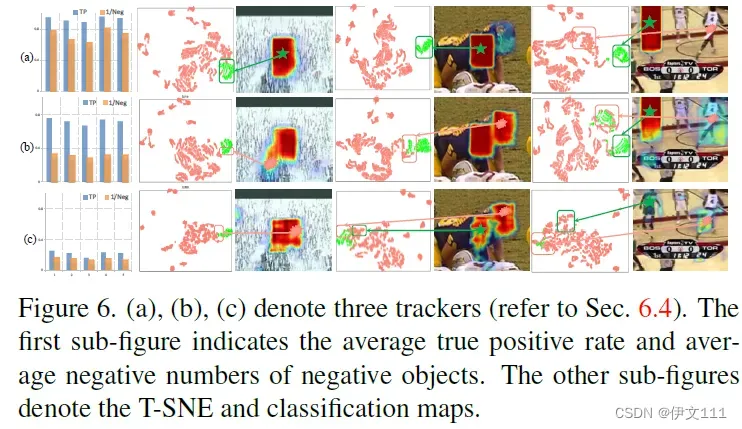
(3)Benefits from pre-training

文章出处登录后可见!