

自然语言处理在行动
我们可以想象这样一个场景,在网上购物时,我们总是要在多个电商平台之间跳来跳去,才能找到价格更低、质量更好的产品。显然这个过程既复杂又耗时,那么我们能不能用人工智能来帮助我们完成这个目标呢?
哪里有需求,哪里就有市场。
如今,越来越多的商家意识到推荐的重要性,推出了智能推荐服务。实现智能推荐的方法有很多。商用比较成熟的有以下两种:
- 首先,寻找同类产品。即根据您的历史记录,例如您浏览过的商品、观看过的视频等,从软件提供的商品开始,向您推荐具有相似属性的商品。
- 二是寻找相似用户。即根据你的个人信息和使用习惯,为你绘制一张用户画像,并从成千上万的用户中,找到与你画像相似的用户,向你推荐他们浏览过的产品和听过的歌曲。
对于像我们这样的个人用户,显然不可能获得其他用户的使用数据。但是,我们可以通过另一种方式来分析产品评论,找到最受消费者认可的产品,即评论的整体情感色彩更积极,从而达到智能推荐的效果。
接下来,我们可以自己设计一个智能产品推荐系统
项目分析
商品推荐,自然离不开商品的评论数据。我已经事先帮你爬取了某平台上多种笔记本电脑的评论数据,并从中筛选出了一部分,转换成 Python 中的数据格式,放在 data.py 文件中:
# data.py
laptop_data = {
'笔记本A': [
'很薄,很重,外观漂亮。可惜就像大家说的,屏幕的分辨率不是很给力,另外电脑正面的材质还是比较容易收集指纹的。散热还不错。有一点很奇怪,第二次开机时由于不小心碰掉了电源,再开时,系统居然自己进行了重装还原。'
# 其余评论省略
],
'笔记本B': [
'最失败的1次,笔记本买来后根本没法用,明明是本子问题,卖家非得说可能是快递和我们人为的,折腾好几天搭上不少时间和费用才能好,以后再也不在这店买了。'
# 其余评论省略
],
'笔记本C': [
'绝对是便携的轻便本,配24G的SSD硬盘。不过启动速度感觉不出来快。1T的硬盘,8G的内存,配置还不错。颜色也还不错,键盘的手感确实非常不错,还带背光键盘,值得称赞下。感觉非常不爽的是整体没有硬盘/cap等状态指示灯,除去屏幕外只有一个电源的开机指示灯等。对习惯了靠硬盘闪烁判断是否死机的,肯定要适应一段时间。',
# 其余评论省略
]
}
这个获取商品评论的过程,在实际应用中,我们一般是通过爬虫来获取的
首先我们的第一想法:既然百度的情感倾向分析接口,一次可以容纳长度在 2048 字节以内(UTF-8 编码下约为 682 个汉字,GBK 编码下为 1024 个汉字)的文本,这些评论应该都没有超过此限度。并且百度情感倾向分析接口得到的情感极性标签都是数字,那我们直接把每条评论的情感极性标签加起来,作为该商品总得分。再找出得分最高的商品,不就行了?🤔️
等等,让我们想象一个极端的情况:
- A 商品有 10 条评论,每条评论的情感分类都是 1(中立),用上述方法计算,总得分为 10 分;
- B 商品有 4 条评论,每条评论的情感得分都是 2(积极),用上述方法计算,总得分为 8 分;
- 由于 A 商品总得分更好,因此计算机将认为,A 商品更受欢迎。
这显然与我们的直观感受相悖。虽然 A 得分高,但它的好评率是 0%;相反,B 得分稍低,但好评率为 100%。所以应当是 B 更受欢迎。
为了消除评论数量对最终结果的影响,我们可以选择平均值作为指标,将评论的情感极性标签的平均值作为最终的产品情感得分。


此时 A 商品情感得分为 10 / 10 = 1 分,B 商品情感得分为 8 / 4 = 2 分,计算机将认为 B 商品更受欢迎。这就比较符合我们的认知了。
这个分析过程也让我们思考:用评论情感极性标签的总和来表示商品的情感分数是不科学的。那么简单地使用情感极性标签来表示评论的情感分数是否科学?
我们可以找一个例子来试试:
# A 店铺评论
天啊,这家店也太太太好吃了吧!咖喱鱼蛋Q弹有嚼劲,咖喱香十足,虾皇饺外皮薄而韧,虾仁贼大,我一口差点没包下哈哈哈。还送了一小杯鸳鸯奶茶,爱了爱了!
# B 店铺评论
蒜蓉扇贝口感一般。不过整体还不错,下次再来。
比如对于机器来说,上面两条评论的情感倾向都是积极的,情感极性标签都是 2(积极),并没有区别:
# A 店铺评论情感分析结果
{
'positive_prob': 0.999921,
'confidence': 0.999825,
'negative_prob': 7.86681e-05, # 此处为科学计数法,值为 0.0000786681
'sentiment': 2
}
# B 店铺评论情感分析结果
{
'positive_prob': 0.963015,
'confidence': 0.917812,
'negative_prob': 0.0369847,
'sentiment': 2
}
但我们一眼就能看出,A 店铺的评论情感色彩较 B 店铺更浓。如果在某点评网站看到这样两条评价,相信有不少人会选择 A 店铺而不是 B 店铺。因此我们不能囫囵地把它当作整体来处理,否则很可能会稀释情感浓度。
有很多方法可以解决这个问题。
由于百度 SDK 在正确分析文本情感倾向后,会返回积极概率、消极概率、情感极性标签和本次分类置信度。其中 积极概率 取值范围为 0~1,越靠近 1,说明该文本情感偏向积极的可能性越大。因此我们可以用积极概率与情感极性标签的乘积,表示整段评论的情感得分。

此时 A 店铺评论情感得分为 0.999921 * 2 = 1.999842 分,B 店铺情感得分为 0.963015 * 2 = 1.92603 分,计算机便能辨别出来,A 店铺很可能是更受欢迎的。

这样,我们就可以画出智能推荐系统的整体流程: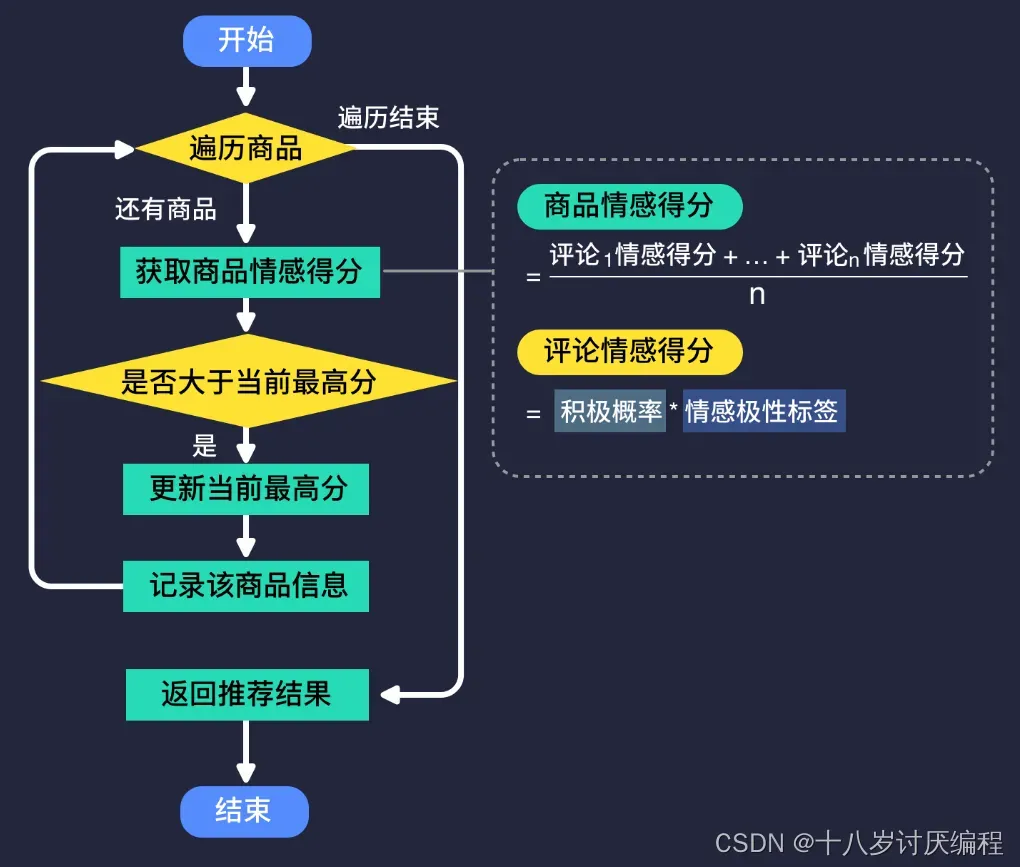
可以看出,我们的智能推荐系统可以分为三个部分:

- 计算评论情绪得分
- 计算项目情绪得分
- 控制整个过程
计算评论情绪得分
我们将这一部分功能封装成函数 calc_comment_senti(),用来计算评论情感得分。它接受 1 个参数,表示需要处理的评论文本内容。
如果百度接口调用成功,则返回情感分数;如果调用失败,将返回错误码和错误原因。
from aip import AipNlp
# 你的 App ID, API Key 及 Secret Key
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
def calc_comment_senti(comment):
# 调用情感倾向分析接口
r = client.sentimentClassify(comment)
# 判断请求是否成功
if r.get('error_code'):
# 请求失败时,返回错误码和错误原因
return r['error_code'], r['error_msg']
else:
# 请求成功时,返回评论情感得分
# 评论情感得分 = 积极概率 * 情感极性标签
item = r['items'][0]
return item['positive_prob'] * item['sentiment']
计算项目情绪得分
在项目分析环节我们知道,商品情感得分是评论情感得分的平均值。因此我们实际上需要完成的任务是遍历每条评论,调用 calc_comment_senti() 函数计算、累计评论情感得分,最终计算出评论情感得分平均值并返回。
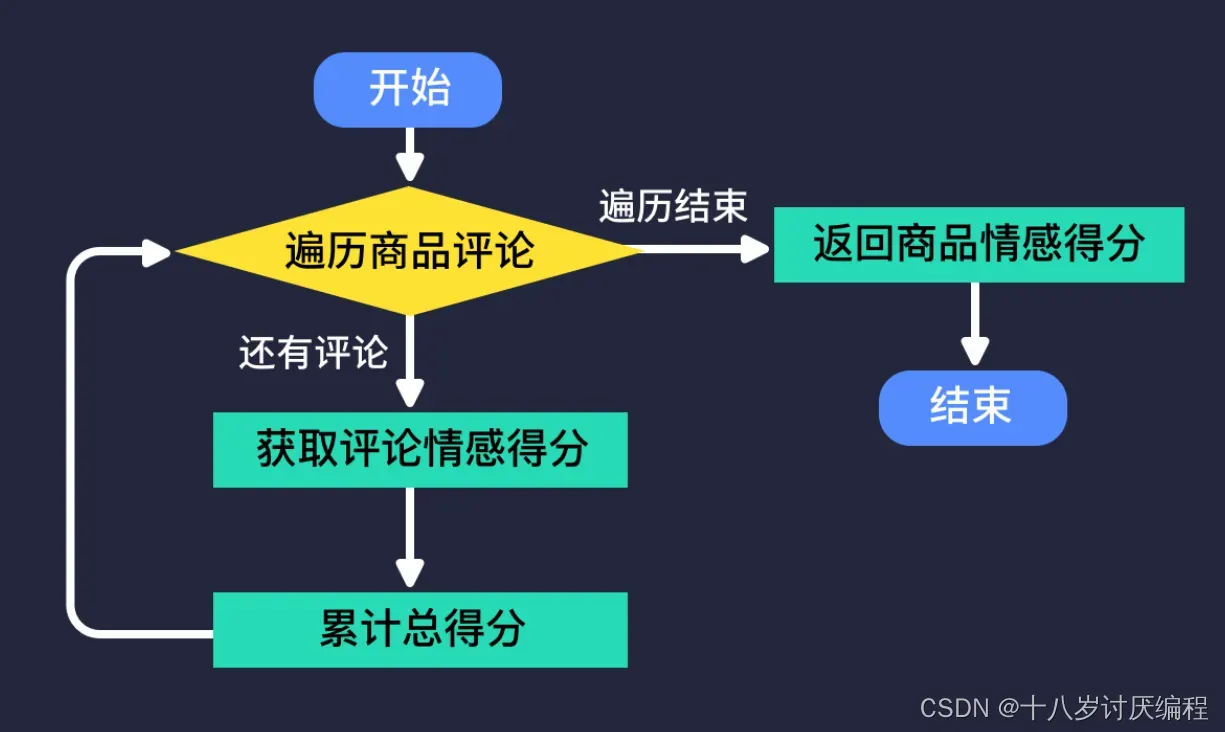

我们把这部分功能抽象为 calc_product_senti() 函数:
def calc_product_senti(comments):
sum_score = 0 # 用来累计得分
for comment in comments:
# 调用函数,计算单条评论情感得分
comment_senti = calc_comment_senti(comment)
# 若返回值为浮点数,表示分析成功;否则表示分析失败
if type(comment_senti) == float:
sum_score += comment_senti
else:
print('评论“{}...”分析失败,错误码:{},错误原因:{}'.format(
comment[:5], comment_senti[0], comment_senti[1]
))
# 返回商品情感得分
return sum_score / len(comments)
不过在这一个部分,我们要注意一个问题百度AI智能云平台提供给我们的接口有QPS限制。如果我们不间断的反复请求会得不到返回结果。所以这里我们要引入time模块,使用其中的sleep()方法来实现间断请求的要求。
sleep() 函数
它接受一个参数,单位为秒,表示需要暂停的时间。当我们调用函数 sleep(1) 时,计算机会暂停 1 秒,再继续执行后面的代码。
百度接口对每个接口的 QPS 限制是固定的,因此我们可以用 常量 QPS_LIMIT 来表示接口 QPS 限制,每当访问一次接口,便暂停 1 / QPS_LIMIT 秒,从而控制访问速度。一般情况下,我们为 QPS_LIMIT 赋值为 2 即可满足需要,不过保险起见,我们也可以延长暂停时间,赋值为 1.8、1.5 等等,使程序运行更加稳定。写成代码就是这样:
from aip import AipNlp
from time import sleep
from data import laptop_data
# 你的 App ID, API Key 及 Secret Key
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
# 该接口每秒最多可处理几条信息(query per second)
QPS_LIMIT = 2 # 可减小数值,提升程序稳定性
# 实例化 AipNlp 类,用以调用百度自然语言处理相关服务
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
# calc_comment_senti() 函数省略
def calc_product_senti(comments):
sum_score = 0 # 用来累计得分
for comment in comments:
# 调用函数,计算单条评论情感得分
comment_senti = calc_comment_senti(comment)
sleep(1 / QPS_LIMIT) # 防止请求过快
# 若返回值为浮点数,表示分析成功;否则表示分析失败
if type(comment_senti) == float:
sum_score += comment_senti
else:
print('评论“{}...”分析失败,错误码:{},错误原因:{}'.format(
comment[:5], comment_senti[0], comment_senti[1]
))
# 返回商品情感得分
return sum_score / len(comments)
控制整个过程
def recommend(data):
# 定义变量 max_senti,用于保存当前最高商品情感得分
max_senti = 0
# 定义变量 recommend_pro,用于保存情感得分最高商品名
recommend_pro = ''
# 遍历 data 中每件商品
for i in laptop_data:
# 计算商品得分
score = calc_product_senti(laptop_data[i])
# 若该商品得分大于目前最高分
if score > max_senti:
# 更新当前最高分
max_senti = score
# 记录商品名
recommend_pro = i
# 遍历结束,返回最终结果
return max_senti,recommend_pro
最后我们整合以上步骤,整体代码实现如下:
from aip import AipNlp
from time import sleep
from data import laptop_data
# 你的 App ID, API Key 及 Secret Key
APP_ID = 'xxxxx'
API_KEY = 'xxxxxxxxxxxxxxxxxxx'
SECRET_KEY = 'xxxxxxxxxxxxxxxxx'
# 该接口每秒最多可处理几条信息(query per second)
QPS_LIMIT = 2
# 实例化 AipNlp 类,用以调用百度自然语言处理相关服务
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
def calc_comment_senti(comment):
# 调用情感倾向分析接口
r = client.sentimentClassify(comment)
# 判断请求是否成功
if r.get('error_code'):
# 请求失败时,返回错误码和错误原因
return r['error_code'], r['error_msg']
else:
# 请求成功时,返回评论情感得分
# 评论情感得分 = 积极概率 * 情感极性标签
item = r['items'][0]
return item['positive_prob'] * item['sentiment']
def calc_product_senti(comments):
sum_score = 0 # 用来累计得分
for comment in comments:
# 调用函数,计算单条评论情感得分
comment_senti = calc_comment_senti(comment)
sleep(1 / QPS_LIMIT) # 防止请求过快
# 若返回值为浮点数,表示分析成功;否则表示分析失败
if type(comment_senti) == float:
sum_score += comment_senti
else:
print('评论“{}...”分析失败,错误码:{},错误原因:{}'.format(
comment[:5], comment_senti[0], comment_senti[1]
))
# 返回商品情感得分
return sum_score / len(comments)
# 请根据提示,完成函数 recommend()编写
def recommend(data):
# 定义变量 max_senti,用于保存当前最高商品情感得分
max_senti = 0
# 定义变量 recommend_pro,用于保存情感得分最高商品名
recommend_pro = ''
# 遍历 data 中每件商品
for i in laptop_data:
# 计算商品得分
score = calc_product_senti(laptop_data[i])
# 若该商品得分大于目前最高分
if score > max_senti:
# 更新当前最高分
max_senti = score
# 记录商品名
recommend_pro = i
# 遍历结束,返回最终结果
return max_senti,recommend_pro
senti, product = recommend(laptop_data)
print('评价更好的商品是:{},得分为:{}'.format(product, senti))
文章出处登录后可见!