DispNet论文阅读之一 | 传送门
基于Caffe的DispNet模型文件下载 | 传送门[0][1]
层介绍
此处略过图像增强层。直接从网络的输入部分开始(下图中的红色箭头)。
train.prototxt文件,(数据输入部分)可视化如下: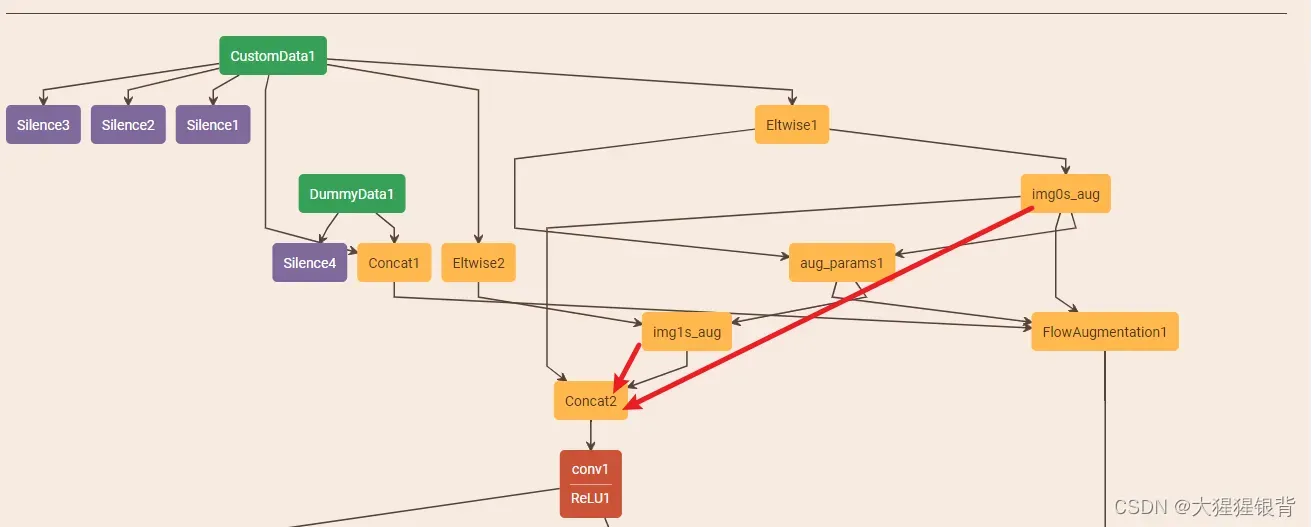
基础层介绍
train.prototxt文件介绍如下(跳过了图像增强部分!):
自定义数据层
layer {
name: "CustomData1"
type: "CustomData" # 自定义数据层,用于输入数据
top: "blob0" # top,表示输出
top: "blob1"
top: "blob2"
include {
phase: TRAIN
}
data_param {
source: "../../../data/FlyingThings3D_release_TRAIN_lmdb"
batch_size: 4
backend: LMDB # 数据格式
rand_permute: true # 随机排列
rand_permute_seed: 77
slice_point: 3 # 三个输出的划分点,0 1 2; 3 4 5; 6
slice_point: 6
encoding: UINT8 # 分别指定三个输出数据的编码方式
encoding: UINT8
encoding: UINT16FLOW
verbose: true
}
}
Concat层
layer {
name: "Concat1"
type: "Concat" # 按维度拼接
bottom: "blob2" # bottom, 表示输入
bottom: "blob9"
top: "blob10"
concat_param {
concat_dim: 1
}
}
layer {
name: "Concat2"
type: "Concat" # 将增强后的左右视图在通道维拼接后作为网络的输入
bottom: "img0_aug"
bottom: "img1_aug"
top: "input"
concat_param {
axis: 1
}
}
卷积层 + 激活函数
layer {
name: "conv1"
type: "Convolution" # 卷积层
bottom: "input"
top: "conv1"
param {
lr_mult: 1 # 指定权重的学习率系数,要与超参数配置在文件中的学习率相乘
decay_mult: 1 # 指定权重的衰减系数
}
param {
lr_mult: 1 # 指定偏差的学习率系数
decay_mult: 0 # 指定偏差的学习率系数
}
convolution_param {
num_output: 64
pad: 3
kernel_size: 7
stride: 2
weight_filler {
type: "msra" # 权重初始化策略
}
bias_filler {
type: "constant"
}
engine: CUDNN
}
}
layer {
name: "ReLU1"
type: "ReLU" # 激活函数
bottom: "conv1"
top: "conv1"
relu_param {
negative_slope: 0.1 # 指定负斜率为0.1,即leakyRelu
}
}
卷积得到预测视差
layer {
name: "Convolution5"
type: "Convolution" # 卷积层,预测输出
bottom: "concat4"
top: "predict_flow4"
param {
lr_mult: 1
decay_mult: 0
}
param {
lr_mult: 1
decay_mult: 0
}
convolution_param {
num_output: 1 # 输出通道数为1
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
}
engine: CUDNN
}
}
下采样层
layer {
name: "Downsample3"
type: "Downsample" # 下采样层
bottom: "disp_gt_aug" # 输入为视差标签
bottom: "predict_flow4" # 预测视差
top: "blob38" # 将视差标签下采样到和预测视差相同的尺寸
propagate_down: false
propagate_down: false
}
损失层
layer {
name: "flow_loss4"
type: "L1Loss" # 损失层,L1loss
bottom: "predict_flow4" # 预测视差
bottom: "blob38" # 同尺度的视差标签
top: "flow_loss4"
loss_weight: 0.2 # 损失权重
l1_loss_param {
l2_per_location: false
normalize_by_num_entries: true # 求均值,loss为标量
}
}
模型初始化
模型权重的初始化:msra
只考虑输入个数时,MSRA初始化是一个均值为0方差为2/n的高斯分布:
基于pytorch的实现
DispNetSample架构的pytorch实现
# 自行导入相应的模块
class DispNetS(nn.Module):
"""
对论文中基于caffe的dispnets的pytorch的复现
"""
def __init__(self):
super(DispNetS, self).__init__()
# the extraction part
self.conv1 = self.conv2d_leakyrelu(6, 64, 7, 2, 3) # 1/2
self.conv2 = self.conv2d_leakyrelu(64, 128, 5, 2, 2) # 1/4
self.conv3a = self.conv2d_leakyrelu(128, 256, 5, 2, 2) # 1/8
self.conv3b = self.conv2d_leakyrelu(256, 256, 3, 1, 1)
self.conv4a = self.conv2d_leakyrelu(256, 512, 3, 2, 1) # 1/16
self.conv4b = self.conv2d_leakyrelu(512, 512, 3, 1, 1)
self.conv5a = self.conv2d_leakyrelu(512, 512, 3, 2, 1) # 1/32
self.conv5b = self.conv2d_leakyrelu(512, 512, 3, 1, 1)
self.conv6a = self.conv2d_leakyrelu(512, 1024, 3, 2, 1) # 1/64
self.conv6b = self.conv2d_leakyrelu(1024, 1024, 3, 1, 1)
# the expanding part
self.upconv5 = self.convTranspose2d_leakyrelu(1024, 512, 4, 2, 1) # conv6b
self.upconv4 = self.convTranspose2d_leakyrelu(512, 256, 4, 2, 1) # iconv5
self.upconv3 = self.convTranspose2d_leakyrelu(256, 128, 4, 2, 1) # iconv4
self.upconv2 = self.convTranspose2d_leakyrelu(128, 64, 4, 2, 1) # iconv3
self.upconv1 = self.convTranspose2d_leakyrelu(64, 32, 4, 2, 1) # iconv2
self.iconv5 = nn.Conv2d(512 + 1 + 512, 512, 3, 1, 1) # upconv5+pre6+conv5b
self.iconv4 = nn.Conv2d(256 + 1 + 512, 256, 3, 1, 1) # upconv4+pre5+conv4b
self.iconv3 = nn.Conv2d(128 + 1 + 256, 128, 3, 1, 1) # upconv3+pre4+conv3b
self.iconv2 = nn.Conv2d(64 + 1 + 128, 64, 3, 1, 1) # upconv2+pre3+conv2
self.iconv1 = nn.Conv2d(32 + 1 + 64, 32, 3, 1, 1) # upconv1+pre2+conv1
# the predict part
self.upscale2 = nn.ConvTranspose2d(1, 1, 4, 2, 1)
self.upscale3 = nn.ConvTranspose2d(1, 1, 4, 2, 1)
self.upscale4 = nn.ConvTranspose2d(1, 1, 4, 2, 1)
self.upscale5 = nn.ConvTranspose2d(1, 1, 4, 2, 1)
self.upscale6 = nn.ConvTranspose2d(1, 1, 4, 2, 1)
self.pr6 = nn.Conv2d(1024, 1, 3, 1, 1) # conv6b
self.pr5 = nn.Conv2d(512, 1, 3, 1, 1) # iconv5
self.pr4 = nn.Conv2d(256, 1, 3, 1, 1) # iconv4
self.pr3 = nn.Conv2d(128, 1, 3, 1, 1) # iconv3
self.pr2 = nn.Conv2d(64, 1, 3, 1, 1) # iconv2
self.pr1 = nn.Conv2d(32, 1, 3, 1, 1) # iconv1
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
m.bias.data.zero_()
elif isinstance(m, nn.Conv3d):
n = m.kernel_size[0] * m.kernel_size[1]*m.kernel_size[2] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm3d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.bias.data.zero_()
def forward(self, imgl, imgr):
# the extraction part
conv1 = self.conv1(torch.cat((imgl, imgr), dim=1))
conv2 = self.conv2(conv1)
conv3b = self.conv3a(conv2)
conv3b = self.conv3b(conv3b)
conv4b = self.conv4a(conv3b)
conv4b = self.conv4b(conv4b)
conv5b = self.conv5a(conv4b)
conv5b = self.conv5b(conv5b)
conv6b = self.conv6a(conv5b)
conv6b = self.conv6b(conv6b)
# the predict part 直接卷积得到视差
pre6 = self.pr6(conv6b) # 1/64 [B 1 H/64 W/64]
iconv5 = self.iconv5(torch.cat((self.upconv5(conv6b), self.upscale6(pre6), conv5b), dim=1))
pre5 = self.pr5(iconv5) # 1/32
iconv4 = self.iconv4(torch.cat((self.upconv4(iconv5), self.upscale5(pre5), conv4b), dim=1))
pre4 = self.pr4(iconv4) # 1/16
iconv3 = self.iconv3(torch.cat((self.upconv3(iconv4), self.upscale4(pre4), conv3b), dim=1))
pre3 = self.pr3(iconv3) # 1/8
iconv2 = self.iconv2(torch.cat((self.upconv2(iconv3), self.upscale3(pre3), conv2), dim=1))
pre2 = self.pr2(iconv2) # 1/4
iconv1 = self.iconv1(torch.cat((self.upconv1(iconv2), self.upscale2(pre2), conv1), dim=1))
pre1 = self.pr1(iconv1) # 1/2
if self.training:
return torch.squeeze(pre1), torch.squeeze(pre2), torch.squeeze(pre3), \
torch.squeeze(pre4), torch.squeeze(pre5), torch.squeeze(pre6) # [B H W] if B != 1 else [H W]
else:
pre1 = F.interpolate(pre1, (imgl.shape[2], imgl.shape[3]), mode='bilinear')
return torch.squeeze(pre1)
def conv2d_leakyrelu(self, *args, **kwargs):
return nn.Sequential(
nn.Conv2d(*args, **kwargs),
nn.LeakyReLU(negative_slope=0.1, inplace=True)
)
def convTranspose2d_leakyrelu(self, *args, **kwargs):
return nn.Sequential(
nn.ConvTranspose2d(*args, **kwargs),
nn.LeakyReLU(negative_slope=0.1, inplace=True)
)
数据增强、数据加载器的实现:(借鉴了 PSMNet,完整代码请自行下载查看)[0]
Training
超参数设置:
- maxdisp:DispNetSample架构没有使用该参数
- epoch: 5
- batch_size: 4
- optimizer: optim.Adam(model.parameters(), lr=0.0001, betas=(0.9, 0.999), weight_decay=0.0004)
- DataAugment: Fasle
- datasets: FlyingThings3D(train 21818, test 4248)
- 针对实验环境做了如下调整
- 实验环境:NVIDIA GeForce GTX 1660 SUPER,6G显存
- 学习率策略:不变(与原来不同,因为训练次数少)
- 损失策略:自适应损失权重(与原来不同,没有具体操作)
自适应损失权重:
1、将六个尺度的损失求和得到sum_loss
2、将六个损失分别平方再除以sum_loss后求和,得到最终的loss
【部分代码借鉴了 PSMNet,完整代码请自行下载查看】[0]
def compute_loss(pre, disp):
assert len(pre.shape) == 3 # [B H W]
assert len(disp.shape) == 4 # [B 1 H W]
disp = F.interpolate(disp, (pre.shape[1], pre.shape[2]), mode='bilinear').squeeze(1)
mask = (disp < args.maxdisp).detach_()
loss = F.l1_loss(pre[mask], disp[mask], reduction='mean')
return loss
def train_dispnet(imgL, imgR, disp_L):
model.train()
imgL, imgR, disp_true = imgL.cuda(), imgR.cuda(), disp_L.cuda()
mask = (disp_true < args.maxdisp).detach_()
# 每次计算梯度前,将上一次梯度置零
optimizer.zero_grad()
pre1, pre2, pre3, pre4, pre5, pre6 = model(imgL, imgR)
disp_true = disp_true.unsqueeze(1) # [B H W] -> [B 1 H W]
loss1 = compute_loss(pre1, disp_true)
loss2 = compute_loss(pre2, disp_true)
loss3 = compute_loss(pre3, disp_true)
loss4 = compute_loss(pre4, disp_true)
loss5 = compute_loss(pre5, disp_true)
loss6 = compute_loss(pre6, disp_true)
sum_loss = loss1 + loss2 + loss3 + loss4 + loss5 + loss6
loss = loss1 * loss1 / sum_loss + loss2 * loss2 / sum_loss + loss3 * loss3 / sum_loss \
+ loss4 * loss4 / sum_loss + loss5 * loss5 / sum_loss + loss6 * loss6 / sum_loss
# 计算梯度
loss.backward()
# 更新权重
optimizer.step()
return loss.data
def test(imgL, imgR, disp_true):
model.eval()
imgL, imgR, disp_true = imgL.cuda(), imgR.cuda(), disp_true.cuda()
# 视差图掩膜
mask = disp_true < 192
# 维度调整
if imgL.shape[2] % 64 != 0:
times = imgL.shape[2] // 64
top_pad = (times + 1) * 64 - imgL.shape[2]
else:
top_pad = 0
if imgL.shape[3] % 64 != 0:
times = imgL.shape[3] // 64
right_pad = (times + 1) * 64 - imgL.shape[3]
else:
right_pad = 0
imgL = F.pad(imgL, (0, right_pad, top_pad, 0))
imgR = F.pad(imgR, (0, right_pad, top_pad, 0))
with torch.no_grad():
output = model(imgL, imgR)
# 维度裁剪
if top_pad != 0:
img = output[:, top_pad:, :]
else:
img = output
if right_pad != 0:
img = img[:, :, :-right_pad]
else:
img = img
if len(disp_true[mask]) == 0:
loss = torch.tensor(0)
else:
loss = F.l1_loss(img[mask], disp_true[mask], size_average=True)
return loss.data.cpu()
def main():
start_full_time = time.time()
writer = SummaryWriter()
for epoch in range(1+pre_epoch, pre_epoch+args.epochs+1):
print('%d-th epoch:' % epoch)
# train
total_train_loss = 0
epoch_time = time.time()
for batch_idx, (imgL_crop, imgR_crop, disp_crop_L) in enumerate(train_loader):
iter_time = time.time()
loss = train_dispnet(imgL_crop, imgR_crop, disp_crop_L)
print(' -- Iter %d-th, training loss = %.3f, time = %.2f s' %
(batch_idx, loss, time.time()-iter_time))
total_train_loss += loss
print(' epoch %d-th total training loss = %.3f, time = %.2f s' %
(epoch, total_train_loss/len(train_loader), time.time()-epoch_time))
# save
savefilename = args.savemodel+'/dispnets_caffe_'+str(epoch)+'.tar'
torch.save({
'epoch': epoch,
'state_dict': model.state_dict(),
'train_loss': total_train_loss/len(train_loader),
}, savefilename)
# test
total_test_loss = 0
epoch_test_time = time.time()
for batch_idx, (imgL, imgR, disp_L) in enumerate(test_loader):
batch_time = time.time()
test_loss = test(imgL, imgR, disp_L)
print(' -- Batch %d-th, test loss = %.3f, time = %.2f s' %
(batch_idx, test_loss, time.time()-batch_time))
total_test_loss += test_loss
print(' epoch %d-th total test loss = %.3f, time = %.2f s' %
(epoch, total_test_loss / len(test_loader), time.time()-epoch_test_time))
# view
writer.add_scalars(main_tag='Loss',
tag_scalar_dict={'train_loss': total_train_loss / len(train_loader),
'test_loss': total_test_loss / len(test_loader)},
global_step=epoch)
writer.flush()
print('full running time = %.2f h' % ((time.time() - start_full_time)/3600))
Results
训练分为了两次进行:Loss曲线图如下: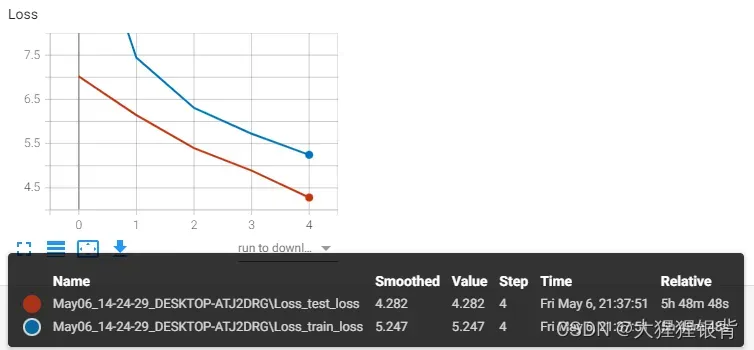
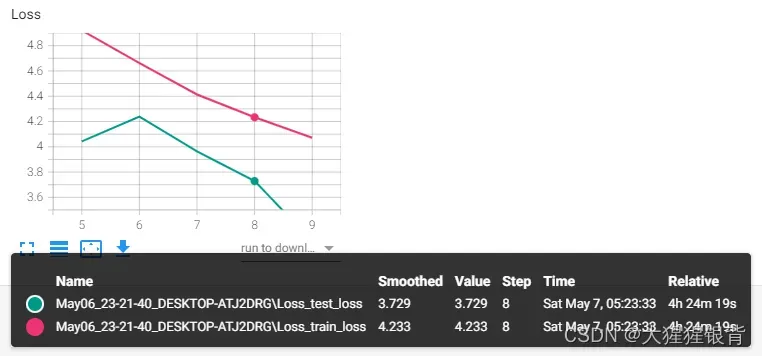
详细情况如下:
epoch 0-th
train loss = 11.328, test loss = 7.021, time = 5072.18 s
epoch 1-th
train loss = 7.444, test loss = 6.144, time = 4990.81 s
epoch 2-th
train loss = 6.307, test loss = 5.398, time = 5604.45 s
epoch 3-th
train loss = 5.723, test loss = 4.889, time = 5049.20 s
epoch 4-th
train loss = 5.247, test loss = 4.282, time = 5283.79 s
epoch 5-th
train loss = 4.921, test loss = 4.043, time = 5843.47 s
epoch 6-th
train loss = 4.661, test loss = 4.238, time = 5250.17 s
epoch 7-th
train loss = 4.414, test loss = 3.964, time = 5498.60 s
epoch 8-th
train loss = 4.233, test loss = 3.729, time = 5110.17 s
epoch 9-th
train loss = 4.071, test loss = 3.254, time = 4895.95 s
End
以上是对DispNetSample架构的DispNet进行的实验,后续会进行一些对比实验。欢迎正在做相关工作的伙伴一起交流~
如有错误,请强烈指正! ! !
文章出处登录后可见!
已经登录?立即刷新