之前我们介绍了机器学习的一些基础性工作,介绍了如何对数据进行预处理,接下来我们可以根据这些数据以及我们的研究目标建立模型。那么如何选择合适的模型呢?首先需要对这些模型的效果进行评估。本文介绍如何使用 sklearn代码进行模型评估
模型评估
模型评估的基本步骤如下:
- 首先,将数据集分为训练集和测试集
- 将模型拟合到训练集
- 确定合适的评估指标
- 在测试集上计算的评估指标
数据集分区
在机器学习问题中,理论上我们需要将数据集划分为训练集、验证集和测试集。
- 训练集:拟合模型(通常的作业和测试)
- 验证集:计算验证集的误差,选择模型(模拟测试)
- 测试集:评估模型(期末考试)
但是在实际应用中,一般分为训练集和测试集两个。其中训练集:70%,测试集:30%.这个比例在深度学习中可以进行相应的调整。
我们可以使用sklearn中的train_test_split划分数据集
数据分区的演变
1、训练集+测试集
如果在一个数据集A上进行训练,同样再用A作为评估数据集,无法评估在新数据集上的表现,为了避免这种情况,通常会取出一部分未被训练的数据作为测试集。
如果我们用训练集训练一个随机森林模型,用测试集对模型进行评估,在评估过程中,我们会手动调整树的数量或者树的深度等超参数,然后去测试集看看效果如何。其实这个操作是错误的。它迎合了测试集并导致测试集中的数据泄漏。如果下次随机划分测试集,效果可能不好,所以这是一个高方差的估计。
以任何方式使用来自测试集的信息都是“偷窥”。
传统上,我们将评估最终模型性能的数据集称为“测试集”,最终模型的评估必须在尚未用于训练模型或调整参数的数据集上进行。
问:如果测试集是“归档”的,用什么来评估模型在未见数据上的性能?通过什么标准参数调整(超参数)?
答案:验证集
2、训练集+验证集+测试集
验证集用于对模型能力进行初步评估,当对验证集的评估实验成功后,对测试集进行最终评估。
但是只有一个验证集有局限性:
- 如果样本数据少,则进行划分,少用数据进行训练。可能存在丢失训练数据信息的风险。
- 不同的验证集产生不同的结果,导致验证集具有很大的不确定性。 (比如验证块中的某些数据可能存在误差值、异常值,导致测试结果偏低,或者验证数据的某些部分过于简单,混杂的噪声较少,导致测试结果偏高)因为我们在验证集需要调整超参数,所以必须降低这个不确定性。
所以用K折交叉验证的方式来评估模型,能够减小偏差,并且评估性能较稳定。
如何解决上述问题?
答案:K折交叉验证
3、K折交叉验证+测试集
首先简述下K折交叉验证思路:
验证数据其实是训练数据的一部分,假设将训练数据分成4折:
- 第一次使用A+B+C训练,D验证,分数S1
- 第二次使用A+B+D训练,C验证,分数S2
- 第三次使用A+C+D训练,B验证,分数S3
- 第四次使用B+C+D训练,A验证,分数S4
最终分数是S1、S2、S3、S4的平均。
K-cv解决的问题:
训练集中的每一个数据都可以参与训练,解决了训练数据不足的问题。
K折就是K个验证集,验证了K次,减小了验证集的不确定性。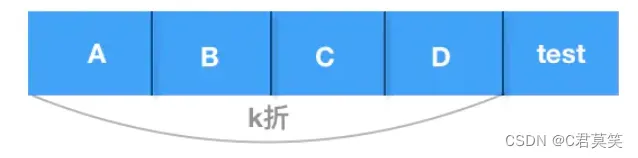
K折交叉验证(K-Fold Cross Validation)
把数据集分成K份,每个子集互不相交且大小相同,依次从K份中选出1份作为验证集,其余K-1份作为训练集,这样进行K次单独的模型训练和验证,最后将K次验证结果取平均值,作为此模型的验证误差。当K=m时,就变为留一法。可见留一法是K折交叉验证的特例。
根据经验,K一般取10。(在各种真实数据集上进行实验发现,10折交叉验证在偏差和方差之间取得了最佳的平衡。)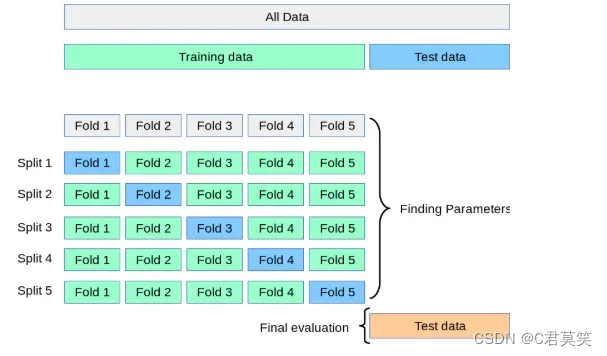
数据集分区案例
# 导入相关库
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import metrics
from sklearn.model_selection import KFold, cross_val_score
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
import pandas as pd
# 导入数据
df = pd.read_csv(r'D:\Program Files (x86)\Python\Lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\data\iris.csv')
# 划分数据集和测试集
print(df.shape)
train_set, test_set = train_test_split(df, test_size=0.3,
random_state=12345)
print(train_set.shape,test_set.shape)

可以看出此时训练集只有105个数据,测试集有45个数据。
交叉验证模型
在评估模型时,我们最常用的方法之一是交叉验证
例如10折交叉验证(10-fold cross validation),将数据集分成十份,轮流将其中9份做训练1份做验证,10次的结果的均值作为对算法精度的估计,一般还需要进行多次10折交叉验证求均值,例如:10次10折交叉验证,以求更精确一点。
# 加载数据
digits = datasets.load_digits()
# 创建特征矩阵
features = digits.data
target = digits.target
# 进行标准化
stand = StandardScaler()
# 创建logistic回归器
logistic = LogisticRegression()
# 创建一个包含数据标准化和逻辑回归的流水线
pipline = make_pipeline(stand, logistic)# 先对数据进行标准化,再用logistic回归拟合
# 创建k折交叉验证对象
kf = KFold(n_splits=10, shuffle=True, random_state=1)
# 进行k折交叉验证
cv_results = cross_val_score(pipline,
features,
target,
cv=kf,
scoring='accuracy',#评估的指标
n_jobs=-1)#调用所有的cpu
print(cv_results.mean())
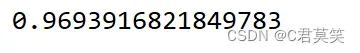
使用pipeline方法可以使得我们这个过程很方便,上述我们是直接对数据集进行了交叉验证,在实际应用中,建议先对数据集进行划分,再对训练集使用交叉验证。
# 导入相关库
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import metrics
from sklearn.model_selection import KFold, cross_val_score
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
import pandas as pd
# 导入数据
df = pd.read_csv(r'D:\Program Files (x86)\Python\Lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\data\iris.csv')
# 划分数据集和测试集
print(df.shape)
train_set, test_set = train_test_split(df, test_size=0.3,
random_state=12345)
print(train_set.shape,test_set.shape)
# 加载数据
digits = datasets.load_digits()
# 创建特征矩阵
features = digits.data
target = digits.target
# 划分数据集
features_train, features_test, target_train, target_test = train_test_split(features,
target,
test_size=0.1,random_state=1)
# 进行标准化
stand = StandardScaler()
# 使用训练集来计算标准化参数
stand.fit(features_train)
# 然后在训练集和测试集上运用
features_train_std = stand.transform(features_train)
features_test_std = stand.transform(features_test)
# 创建logistic回归器
logistic = LogisticRegression()
pipeline = make_pipeline(stand, logistic)
# 创建k折交叉验证对象
kf = KFold(n_splits=10, shuffle=True, random_state=1)
cv_results = cross_val_score(pipeline,
features_train_std,
target_train,
cv=kf,
scoring='accuracy',
n_jobs=-1)
print(cv_results.mean())
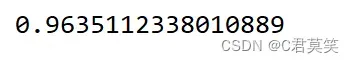
这里之所以这样处理是因为我们的测试集是未知数据,如果使用测试集和训练集一起训练预处理器的话,测试集的信息有一部分就会泄露,因此是不科学的。在这里我认为更general的做法是先将训练集训练模型,用验证集评估选择模型,最后再用训练集和验证集一起来训练选择好的模型,再来在测试集上进行测试。
文章出处登录后可见!