影响力扩散问题大多集中于IM问题,设定seed set使得最终或特定时间点影响力/流行度最大。我们想要关注的是传播模型中每个用户被激活的概率。
Deepis这篇文章采用 GNN 来预测易感性susceptibility, 即每个用户被影响的概率。
估计敏感性可以看作是节点上的回归任务
GNN通过堆叠multiple layers 来 aggregate multi-hop neighbor 的信息,这会导致过度平滑,并且不利于对单个节点预测任务
DeepIS:第一步,构建特征,将特送入 multi-layers GNN, 用于粗粒度(coarse-grained)的易感性估计;第二步,如何实现细粒度计算,提出了一个传播方案,将每个节点的估计值扩散到邻居间。我们设计了一个传播方程,其动机是随机行走过程的静止分布概念。由于影响力的扩散与随机行走有本质的不同,我们设计了一个迭代传播方案,考虑到扩散动力学的具体特征。该模型是以端到端方式进行训练的。我们注意到DeepIS是归纳式的,也就是说,我们可以在一个图上训练模型,然后在其他图上运行,这就避免了在大数据集上昂贵的再训练,并实现了实时影响分析。
DeepIS和MONSTOR与PPNP算法密切相关。MONSTOR专注于基于多个GNN的堆叠结构的IC模型下的节点的增量影响传播测定。By the way, 感觉MONSTOR算法可以关注一下,应该会有启发
这篇文章的灵感主要来自这两篇文章:
[19] Johannes Klicpera, Aleksandar Bojchevski, and Stephan G ̈unnemann. 2019. Predict then propagate: Graph neural networks meet personalized pagerank. In ICLR. 1–14.
[20] Jihoon Ko, Kyuhan Lee, Kijung Shin, and Noseong Park. 2020. MONSTOR: An Inductive Approach for Estimating and Maximizing Influence over Unseen Social Networks. arXiv preprint arXiv:2001.08853 (2020).
Preliminary
IC model
![]()
The Susceptibility Estimation Problem
代表一个扩散实例,
表示节点 i 在 D 中的状态,收到 S 影响为1,否则为0
敏感性表示为
![]()
DeepIS
DeepIS包括两个阶段,即:(1)构建特征,为每个节点的粗粒度易感性估计提供GNN。(2) 传播估计,通过迭代过程将每个节点的估计易感性传播给邻居。最后,我们计算这些程序后的估计值与训练标签之间的损失,以端到端方式优化模型。注意,我们把特征构建和粗粒度计算称为GNN阶段,而把估计传播称为传播阶段。
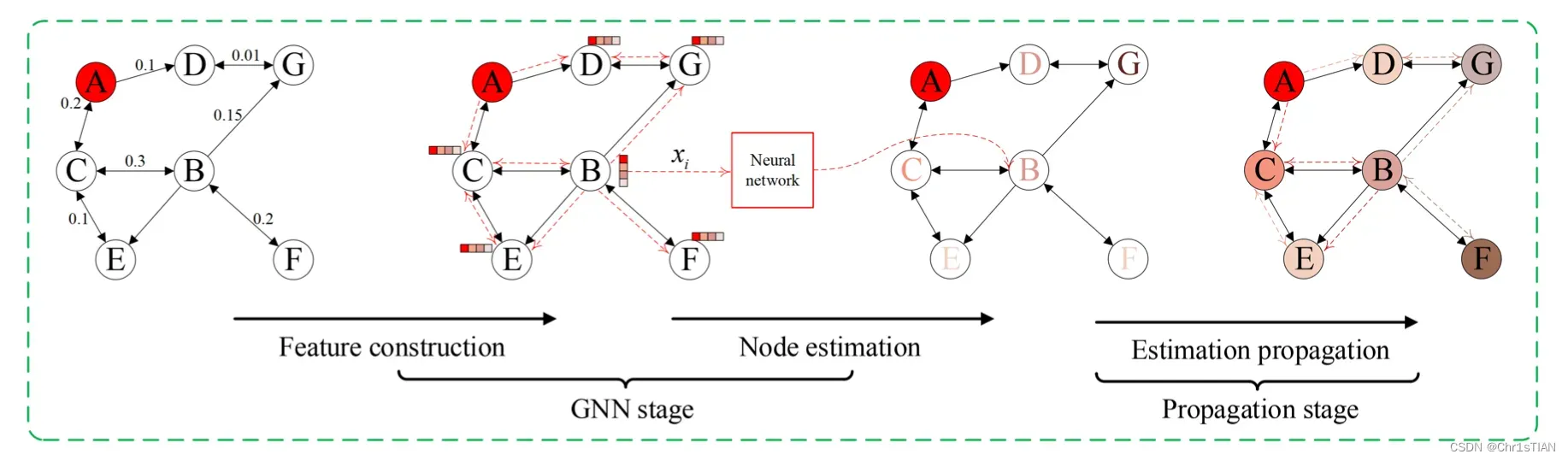
GNN stage :特征构建与粗粒度计算
特色建设
将seed set 表示为 multi-hop vector x:![]()
利用矩阵 和 x 来构建特征矩阵

节点估计
得到特征矩阵后,使用非线性神经函数
预测每个节点的敏感性

Propagation Stage
这一步先沿用论文的方法,重点是实验和上一部分
EXPERIMENTAL SETUP
四个数据集:CORA-ML [31], CITE- SEER [38], PUBMED [32], and MS-ACADEMIC [40]
每个数据集选用 largest connected component 进行实验
对于节点间的影响概率,作者使用与前作相同的这些参数的手动生成,并且对这块进行了一些改进,考虑是否可以从其他地方捕获一些特征作为节点间的影响概率
对于每个数据集,我们根据以下两种策略生成传播级联。首先,我们生成大小为50、100、150、200、250、300的种子集。对于每个种子大小,我们生成100个随机种子向量𝒙。我们对每个种子集重复进行10000次MC模拟,以获得真实的易感概率向量𝒚。每个级联实例𝐶由𝒙和𝒚组成,也就是说,我们将𝐶构建为一个|V | × 2的矩阵,其中𝐶[:, 0] = 𝒙, 𝐶[:, 1] = 𝒚。我们随机抽取这些级联中的80%作为训练集,10%作为验证集,10%作为测试集。其次,为了避免随机种子的小影响概率,我们进一步计算出每个种子大小的前K个度数最高的节点作为种子集作为测试集。我们将分别比较该模型在两种种子集上的表现。
对于GCN和GraphSAGE,我们采用了2层结构,正如它们的原始论文[13, 18]中所报道的那样。对于GAT,我们将注意头的数量设置为4,每个注意通道的维度为8[43]。对于SGC,我们将预处理阶段的迭代数设为2,如原始工作中所报告的。对于MONSTOR,我们将堆栈的数量设置为3,对于每个堆栈,我们采用2层的GCN网络,如[20]中所报道的。对于提议的DeepIS模型,我们利用2层MLP作为fucntion 𝑓(-),如4.1节所述。对于特征构建阶段的特征维度𝑑+1和传播阶段的迭代数𝑞,我们在[2, 5]中改变𝑑,在[1, 4]中改变𝑞。我们将在第6.4节讨论这些重要超参数的影响。请注意,所有基线模型和DeepIS的隐藏单元数都设置为64。为了公平比较,我们为所有模型提供了使用方程(4)构建的相同的特征矩阵
Evaluation Metrics


结果是下一篇文章。
文章出处登录后可见!