content
foreword[0]
最小二乘[0]
最大似然估计[0]
Summarize[0]
foreword
设计损失函数的三种方法
1、最小二乘法
2、极大似然估计法
3、交叉熵法
最小二乘
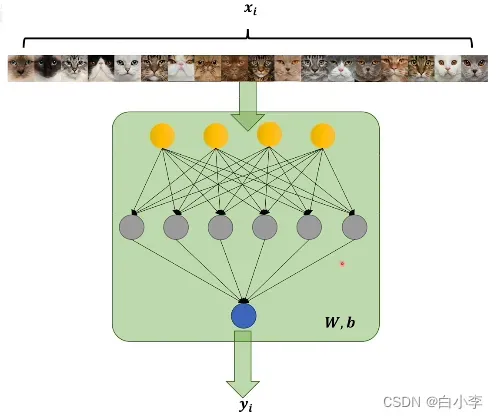
x是经过人的认定后给图片打上的标签结果,x为0,则代表不是猫,为1则代表是猫
y则是图片经过神经网络后,由sigmoid函数输出的一个值,范围是0到1,即待变这个图片是猫的概率是多大。
w代表神经网络中感知机线性函数未知数的系数,b是代表线性函数的偏置系数。
在最后就是算x和y之间的差距,每一张图的差值都算出来,最后选取一个最小的,相当于神经网络中判断猫的模型和人脑中判断猫的模型最近似的结果。
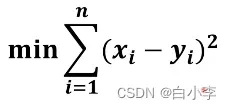
上面的说法是最小二乘法。
缺点:当使用它作为梯度下降的损失函数时特别麻烦。
最大似然估计
理念世界会指导显示世界。倘若硬币的概率分布按照正反都是0.5的方式进行,那抛硬币的结果就是正反0.5分布。
现实世界也能往理念世界进行反推,抛了10次硬币结果是正反各5个,即认定硬币遵守的概率分布就是正反0.5。
但理念世界和现实世界中间隔着一层次元壁。即抛10次硬币,正反不一定是0.5。
通过计算现实世界中的情况来计算该模型在理论世界中出现正面或负面情况的概率。


似然值是真实情况已经发生,假设它有很多模型,在这个概率模型下,找到这种情况的概率。
即从结果推断产生结果的概率模型时,常使用最大似然估计法。
最大似然估计本质上是计算神经网络中概率模型的似然值,找到最大似然值,也就是最接近现实的概率模型。
同样是猫输入到神经网络的例子。
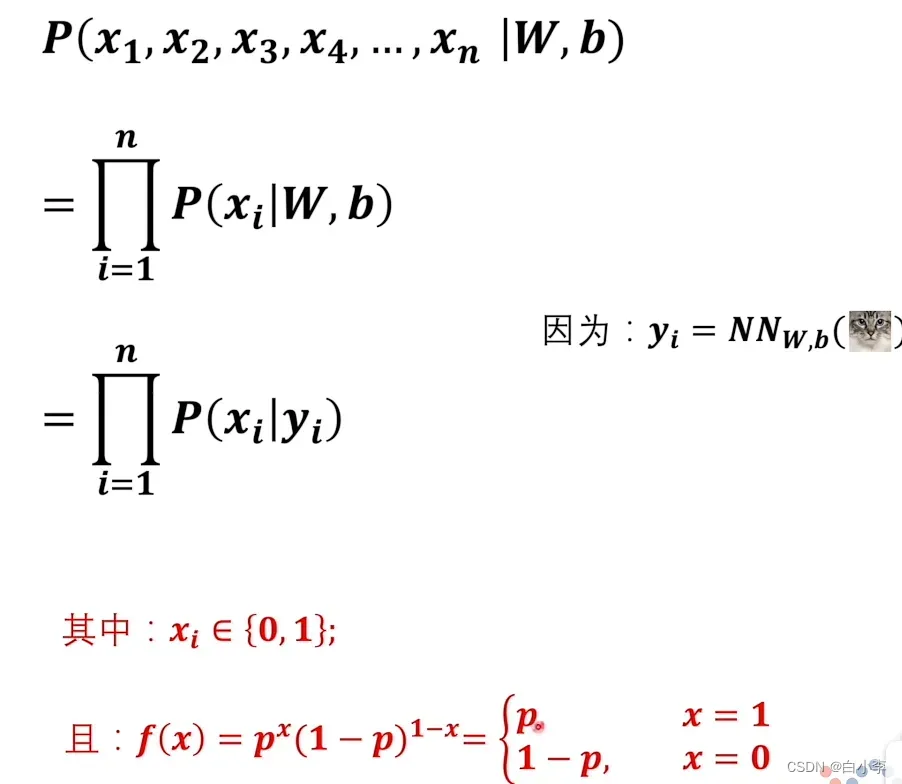
将其转换为
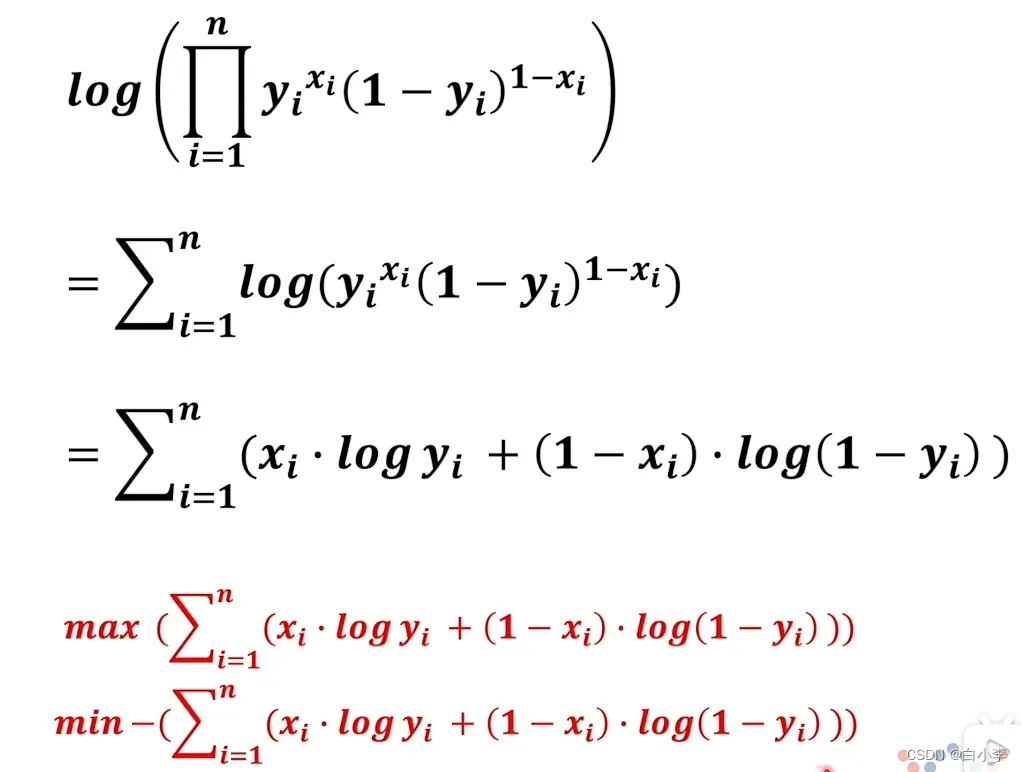
最终值是似然值。当似然值最大时,可以确定神经网络中的模型与人脑中的模型最接近。
Summarize
还有一种交叉熵方法要学,我打算下周学。
文章出处登录后可见!
已经登录?立即刷新