foreword
学习笔记【NLP英文分词方法和中文分词方法】
机器无法理解文本。当我们将句子序列输入模型时,模型只能看到一串字节。它无法知道单词的开始和结束位置,因此它不知道单词是如何形成的。为了帮助机器理解文本,它需要:
1将文本分成一个个小片段
2然后将这些片段表示为一个向量作为模型的输入
3同时,我们需要将一个个小片段(token) 表示为向量,作为词嵌入矩阵, 通过在语料库上训练来优化token的表示,使其蕴含更多有用的信息,用于之后的任务
分词详细介绍[0]
英文分词方法
1.古典分词方法
基于空格的分词方法、基于语法规则的分词方法、基于标点的分词方法,这些方法容易产生大量冗余词汇,无法处理OOV词,词表中的低频词/稀疏词在模型训无法得到训练(因为词表大小有限,太大的话会影响效率)。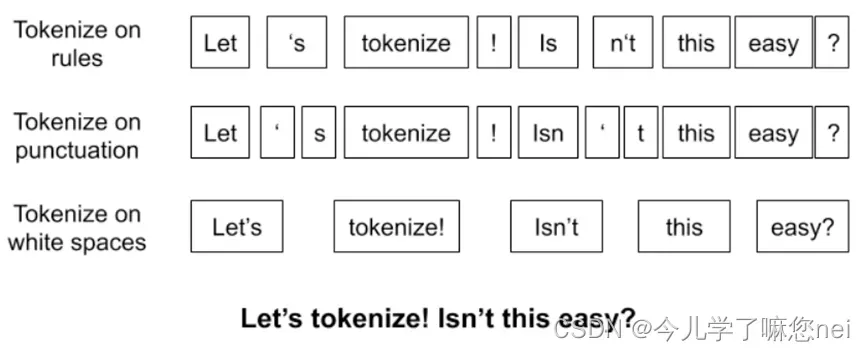
基于字母的分词方法:将每个字符看作一个词,优点是不用担心未知词汇,可以为每一个单词生成词嵌入向量表示,缺点是字母本身就没有任何的内在含义,得到的词嵌入向量缺乏含义;计算复杂度提升(字母的数目远大于token的数目);输出序列的长度将变大,对于Bert、CNN等限制最大长度的模型将很容易达到最大值。
2.基于子词的分词方法(Subword Tokenization)
这种方法的目的是通过一个有限的词表 来解决所有单词的分词问题,同时尽可能将结果中 token 的数目降到最低。有点类似英语中的词根词缀拼词法,其中的这些小片段又可以用来构造其他词。可见这样做,既可以降低词表的大小,同时对相近词也能更好地处理。
这种方法与传统分词方法相比,优点是可以较好的处理OOV问题;可以学习词根词缀之间的关系;分词的粒度合适,不会像基于字母分词那样太细,也不会像基于空格分词那样太粗。
目前主要有三种Subword Tokenization算法:Byte Pair Encoding (BPE)、WordPiece 和 Unigram Language Model
2.1 BPE
BPE原理[0]
BPE是一种数据压缩算法。首先将词分成字符,然后找出出现频率最高的一对字符,用另一个字符替换掉,直到循环结束或者达到设置的词汇数量。
实施过程:
1根据语料库建立一个词典,词典中仅包含单个字符,如英文中就是a-z
2统计语料库中出现次数最多的字符对(词典中两项的组合),然后将字符对加入到词典中
3重复步骤2直到到达规定的步骤数目或者词典尺寸缩小到了指定的值。
随着合并次数的增加,词汇量通常先增加然后减少。迭代次数太少,大部分都是字母,没有意义;迭代次数太多,又把原来的词改了。所以词汇量应该取一个中间值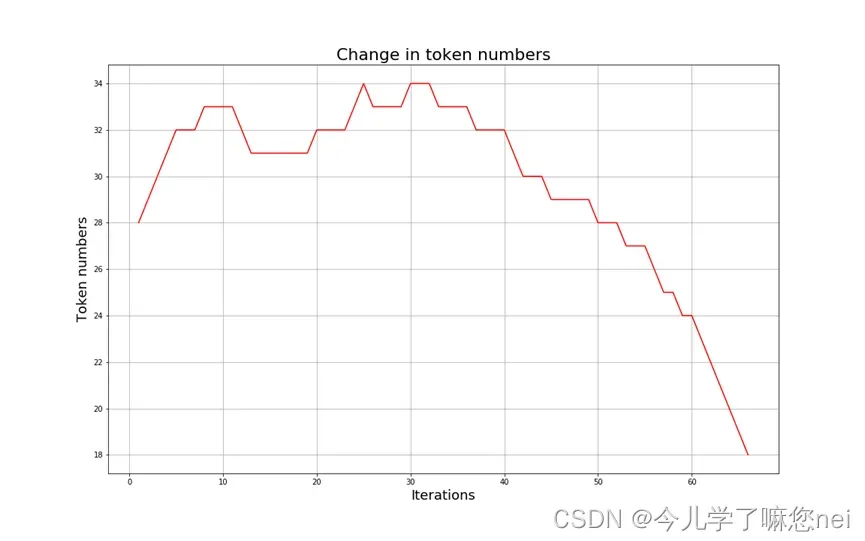
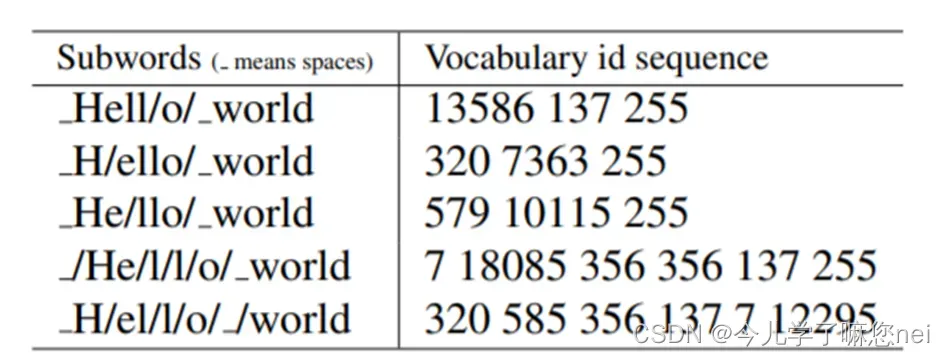
优点:可以很有效地平衡词典大小和编码步骤数(将语料编码所需要的 token 数量)
缺点:对于同一个句子, 例如Hello world,如图所示,可能会有不同的Subword序列。不同的Subword序列会产生完全不同的id序列表示,这种歧义可能在解码阶段无法解决。在翻译任务中,不同的id序列可能翻译出不同的句子,这显然是错误的;在训练任务中,如果能对不同的Subword进行训练的话,将增加模型的健壮性,能够容忍更多的噪声,而BPE的贪心算法无法对随机分布进行学习
2.2 WordPiece
WordPiece
BERT在分词的时候使用的是WordPiece算法。与BPE算法类似,WordPiece算法也是每次从词表中选出两个子词合并成新的子词。与BPE的最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。[0]
分词原则:
假设句子S = (t1,t2,…,tn)由n个子词组成,ti表示子词,且假设各个子词之间是独立存在的,则句子S的语言模型似然值等价于所有子词概率的乘积:
假设把相邻位置的x和y两个子词进行合并,合并后产生的子词记为z,此时句子S似然值的变化可表示为: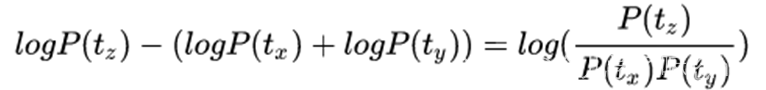
从上面的公式很容易发现,似然值的变化就是两个子词之间的互信息。简而言之,WordPiece每次选择合并的两个子词,他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性,它们经常在语料中以相邻方式同时出现。
(来自百度百科:互信息(Mutual Information)是信息论里一种有用的信息度量,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。)
2.3 Unigram Language Model
与WordPiece一样,Unigram Language Model(ULM)同样使用语言模型来挑选子词。不同之处在于,BPE和WordPiece算法的词表大小都是从小到大变化,属于增量法。而Unigram Language Model则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
对于句子S,X = (x1,x2,…,xm)为句子的一个分词结果,由m个子词组成。所以,当前分词下句子S的似然值可以表示为: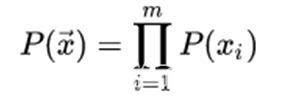
对于句子S,挑选似然值最大的作为分词结果,则可以表示为: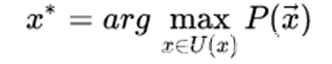
这里U(x)包含了句子的所有分词结果。在实际应用中,词表大小有上万个,直接罗列所有可能的分词组合不具有操作性。针对这个问题,可通过维特比算法得到X*来解决。
(摘自百度百科:维特比算法是一种动态规划算法,用于寻找最有可能产生观测事件序列的-维特比路径隐藏状态序列,尤其是在马尔可夫信息源和隐马尔可夫模型的上下文中。中.)
那怎么求解每个子词的概率P(xi)呢?ULM通过EM算法来估计。假设当前词表V, 则M步最大化的对象是如下似然函数:
(EM 算法是一种求解最大似然估计的方法)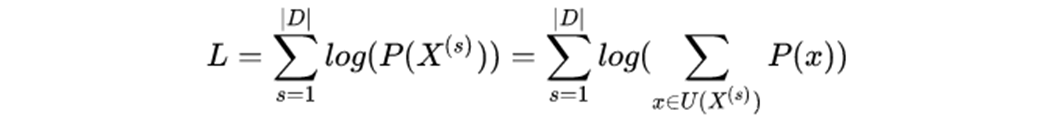
其中,|D|是语料库中语料数量。上述公式的一个直观理解是,将语料库中所有句子的所有分词组合形成的概率相加。
但是,初始时,词表V并不存在。因而,ULM算法采用不断迭代的方法来构造词表以及求解分词概率:
1 初始时,建立一个足够大的词表。一般,可用语料中的所有字符加上常见的子字符串初始化词表,也可以通过BPE算法初始化。
2 针对当前词表,用EM算法求解每个子词在语料上的概率。
3 对于每个子词,计算当该子词被从词表中移除时,总的loss降低了多少,记为该子词的loss。loss代表如果将某个词去掉,上述似然函数值会减少多少。若某个子词经常以很高的频率出现在很多句子的分词结果中,那么其损失将会很大,所以要保留这样的子词。
4 将子词按照loss大小进行排序,丢弃一定比例loss最小的子词(比如20%),保留下来的子词生成新的词表。这里需要注意的是,单字符不能被丢弃,这是为了避免OOV情况。
5 重复步骤2到4,直到词表大小减少到设定范围。
可以看出,ULM会保留那些以较高频率出现在很多句子的分词结果中的子词,因为这些子词如果被丢弃,其损失会很大。
三种分词方法的关系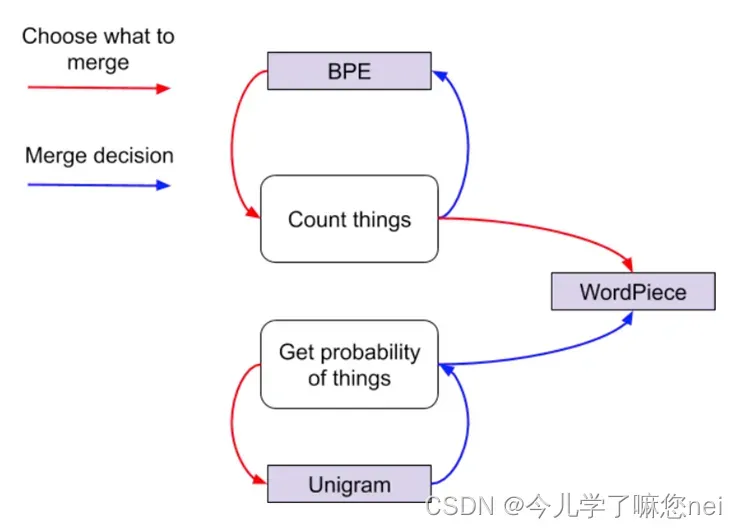
(SentencePiece、Huggingface tokenizers等库可以调用以上分词方法)
中文分词方法
中文分词简介
中英文分词的区别
英文分词比中文分词简单,因为英文单词可以表示名词、形容词、副词等,单词之间用空格隔开。写分割程序的时候,只要匹配一个空格,就可以了。
而在中文本词语没有明显的区分标记,而中文分词的目的就是由机器在中文文本中加上词与词之间的标记。中文分词存在困难是由于存在交集型歧义、组合型歧义和混合型歧义,交集型歧义如对ATB,有AT、TB同时成词,eg.成为了,有成为/为了;组合型歧义如对AB,有A、B、AB同时成词,eg.门把手坏了,有门/把手/坏/了,混合型歧义由交集型歧义和组合型歧义组成[0]
目前的中文分词技术包括:基于规则、基于统计、混合分词、基于深度学习
1.基于规则的分词
在基于规则的分词中,在已经建立词库的前提下,对文本内容进行扫描并与词库进行匹配。如果词库中的文本中有单词,则单独提取该单词。思路是在分句的时候将句子中的每个字符串与词汇表中的单词一一匹配,如果找到就进行分词,否则不进行分词。根据匹配分割方法,可分为前向匹配、反向匹配和双向匹配。
前向最大匹配算法
1 假定分词词典中的最长词有m个汉字字符,将待分词的中文文本中当前的前m个字符作为匹配字段,查找匹配字典中的词,若存在这样一个m字词,则匹配成功,该匹配字段被作为一个词切分出来
2 若文本中找不到词典中最长m字词,则匹配失败,将匹配字段的最后一个字去掉,对剩下的m-1字串重新进行匹配处理
3 不断循环处理下去,直到匹配成功,即成功切分一个词或者剩余字符长度为0,这样完成了一轮匹配。然后取下一个m字字串进行匹配处理,直到文本扫描完毕
class MM(object):
def __init__(self, window_size, dict):
self.window_size = window_size
self.dict = dict
def cut(self, text):
result = []
index = 0
text_length = len(text)
while text_length > index:
for size in range(self.window_size + index, index, -1):
peice = text[index:size]
if peice in self.dict:
index = size - 1
break
index = index + 1
result.append(peice)
return result
逆最大匹配算法
反向最大匹配算法的思想类似于前向最大匹配算法。不同的是,正向拆分匹配方向从文档头部开始,反向拆分从尾部开始。
1每次取末端的m个字符作为匹配字段,查找字典并匹配,若匹配失败,则需要去掉匹配字段最前面的一个字,继续匹配
2直到匹配成功或者剩余字符数目为0,即完成了且切分
3切分好的词是逆序词典,每个词条做一个逆序方式存放
class RMM(object):
def __init__(self, window_size, dict):
self.window_size = window_size
self.dict = dict
def cut(self,text):
result = []
index =len(text)
while index>0:
for size in range(index-self.window_size,index):
peice = text[size:index]
if peice in self.dict:
index = size+1
break
index= index-1
result.append(peice)
result.reverse()
return result
双向匹配算法
分别使用前向最大匹配算法和反向最大匹配算法得到的两种分割结果。
1若两者的切分结果词数不同,取两者中分词数较少的那个结果
2若两者结果分词数相同,取单字词数目较少的那个
class BMM():
def __init__(self, dict):
self.dict = dict
def cut(self, text):
# 正向
token_mm = MM(3, self.dict)
result_mm = token_mm.cut(text)
token_rmm = RMM(3, self.dict)
result_rmm = token_rmm.cut(text)
# 双向最大匹配
if len(result_mm) == len(result_rmm):
if result_rmm == result_mm:
result = result_mm
else:
temp_mm = 0
for i in range(len(result_mm)):
if len(result_mm[i]) == 1:
temp_mm += 1
temp_rmm = 0
for i in range(len(result_rmm)):
if len(result_rmm[i]) == 1:
temp_rmm += 1
result = [result_rmm if temp_mm > temp_rmm else result_mm]
else:
result = [result_rmm if len(result_mm) > len(result_rmm) else result_mm]
2.基于统计的分词
统计分词需要建立语料库并设计分词模型,通过训练好的模型自动对中文文本进行分词。基本思想是把一个词看作是由词的最小单位的字符组成的。如果连接词在不同文本中出现的频率较高,则证明它是一个高频词,其信度较高。很高。一般步骤是:
1 建立语言统计模型,训练模型
2 对句子进行单词划分,对划分结果进行概率计算,获得概率最大的分词结果
语言模型用数学语言描述就是:长度为m的字符串确定其概率分布P(w1.w2,…,wm),其中w1到wm依次表示文本中每个词,采用链式法则计算其概率值,如下式: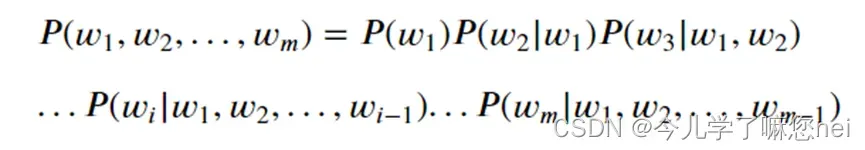
隐马尔科夫模型HMM
HMM模型是将分词作为字在字串中的序列标注任务来完成的,基本思路:每个字在构造一个特定的词语时都占据一个确定的构词位置(即词位),现规定标签B(词首)、M(词中)、E(词尾)、S(单独成词),eg.研究生/要/读/三年使用词位标注是:研/B究/M生/E/要/S/读/S/三/B年/E
用贝叶斯公式转换,我们得到: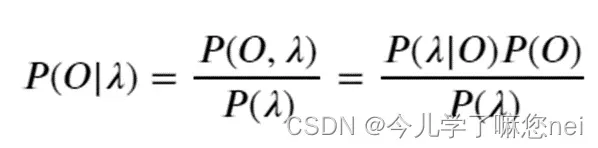

这可以进一步优化。每个输出只与前一个输出相关。这称为齐次马尔可夫假设,也称为二元模型: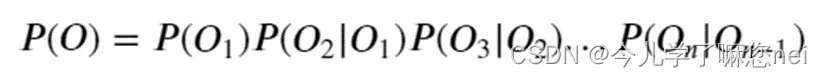
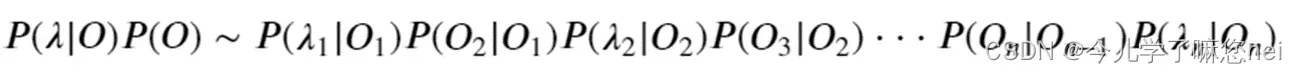
使用HMM求解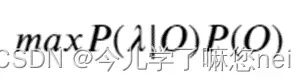
常用一个Veterbi算法,该算法是一种动态规划算法:每一个节点Oi只会影响其前后两个的节点P(Oi-1 | Oi) 和 P(Oi | Oi+1) ,所以如果最终的最优路径经过某个Oi,那么从初始节点到Oi-1的路径必然也是一个最优路径。
根据这个思想,可以通过递推的方法在求每个Oi时只需要求出所有经过各Oi-1的候选点的最优路径,然后再和当前的Oi结合比较,就可以逐步找出最优路径。
实现统计分词的步骤如下:
1 使用已经分好词的训练集去训练HMM模型,计算频数得到HMM的三要素(初始状态概率,状态转移概率和发射概率)
2 使用Viterbi算法以及训练好的三个概率矩阵,将待分词的句子转换为’BMES’类型的状态序列
3 根据已经求出的状态序列,划分句子进行分词,得出分词结果
3.混合分词
简单的统计分词也有缺点,就是过于依赖语料的质量。因此,在实践中,多采用统计和规则两种方法相结合的方式,即混合分词。混合分词先进行基于规则的分词,再进行基于统计的分词,所以分词效果最好,但也最麻烦。
4.基于深度学习的分词
基于深度学习的分词介绍
基于深度学习的分词是利用深度学习技术,结合传统分词方法改善分词效果。优点是准确率高、适应性强,缺点是成本高、速度慢,例如有人员尝试使用双向LSTM+CRF实现分词器,其本质上是序列标注,所以有通用性,命名实体识别等都可以使用该模型,据报道其分词器字符准确率可高达97.5%。常见的分词器都是使用机器学习算法和词典相结合,一方面能够提高分词准确率,另一方面能够改善领域适应性。[0]
目前不管是基于规则的算法、还是基于HMM、CRF或者深度学习等的方法,其分词效果在具体任务中,其实差距并没有那么明显。在实际工程应用中,多是基于一种分词算法,然后用其他分词算法加以辅助。最常用的方式就是先基于词典的方式进行分词,然后再用统计分词方法进行辅助。如此,能在保证词典分词准确率的基础上,对未登录词和歧义词有较好的识别。
文章出处登录后可见!