一、前馈神经网络(Feedforward Neural Network,FNN)是最早发明的简单人工神经网络。
【前馈网络理解:】给定一组神经元,我们可以以神经元为节点来构建一个网络。不同的神经网络模型有着不同网络连接的拓扑结构。一种比较直接的拓扑结构就是前馈网络。
下图为简单的前馈神经网络图层表示:
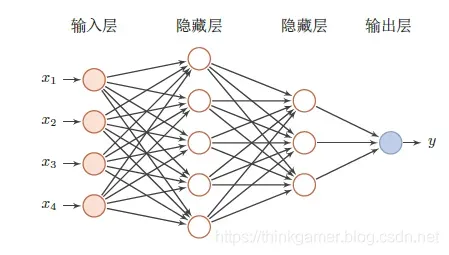 |
特点: ①在前馈神经网络中,不同的神经元属于不同的层,每一层的神经元可以接受到前一层的神经元信号,并产生信号输出到下一层。 ②第0层叫做输入层,最后一层叫做输出层,中间的叫做隐藏层 ③整个网络中无反馈,信号从输入层到输出层单向传播,可用一个有用无环图表示。 |
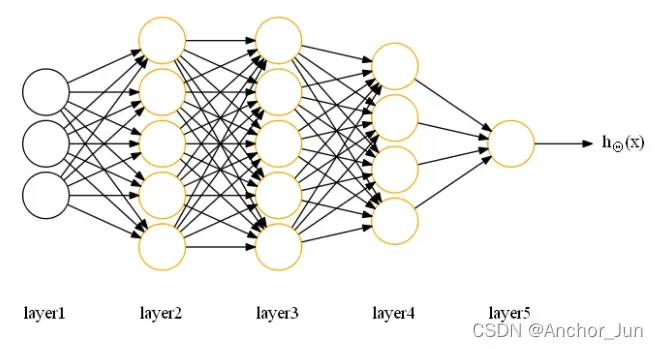
| 对应二分类问题的网络结构 | 对应多分类问题的网络结构 |
 |
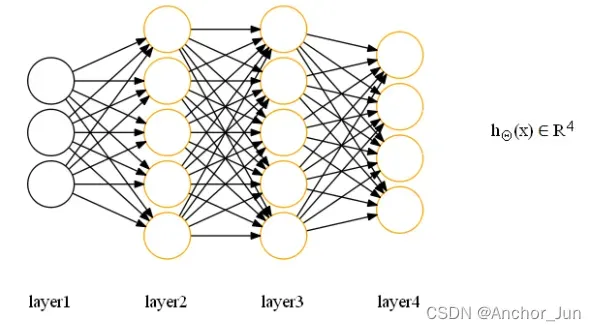 |
Layer层:
最左边的层为输入层(input layer),对应样本特征
最右边的层为输出层(output layer),对应预测结果
Node:
输入层节点:对应样本的特征输入,每一个节点表示样本的特征向量x中的一个特征变量或特征项
输出层节点:对应样本的预测输出,每个节点表示样本在不同类别下的预测概率
隐藏层节点:对应中间的激活计算,称为隐藏单元,在神经网络中隐藏单元的作用可以理解为对输入层的特征进行变换并将其进行层层转换传递到输出层进行类别预测
【计算图中常见的节点:】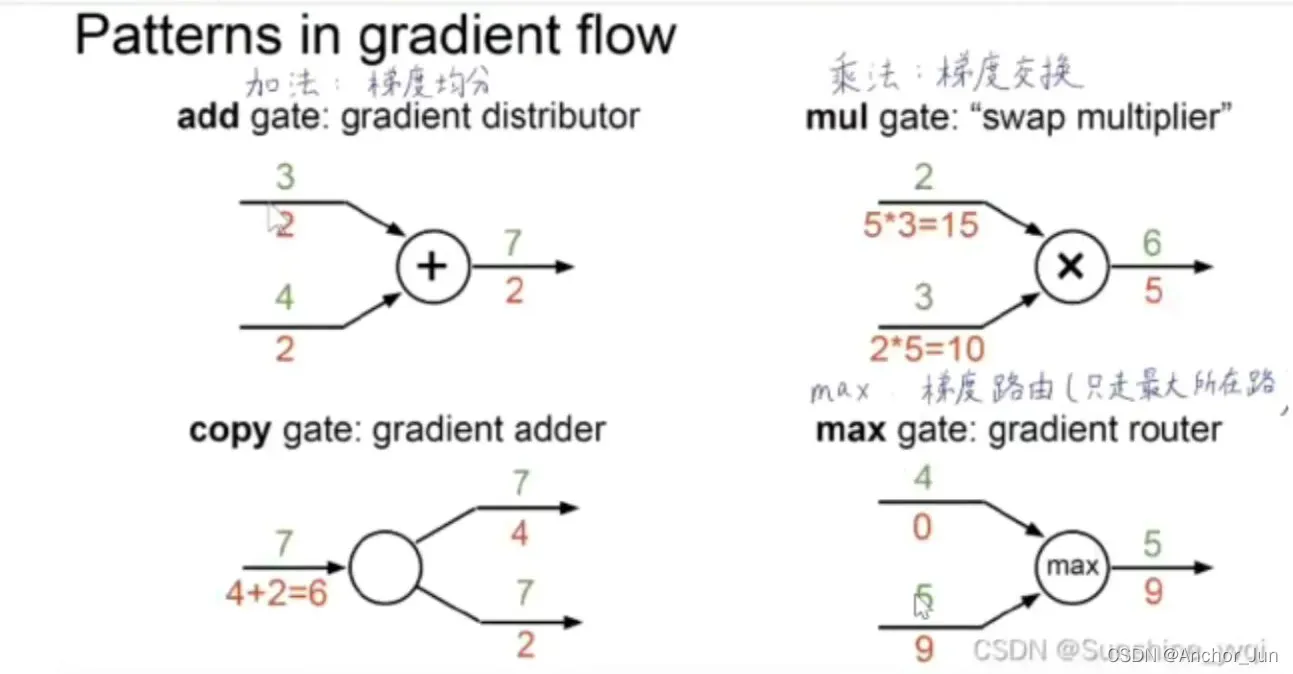
介绍一个神经网络可视化工具Tensorflow_playground(可以直接观察拟合图像与分类)
二、激活函数
激活单元的计算过程称为激活,指一个神经元读入特征,执行计算并产生输出的过程。
激活函数是非线性函数,用于为神经网络模型加入非线性因素,使其能够处理复杂的非线性任务。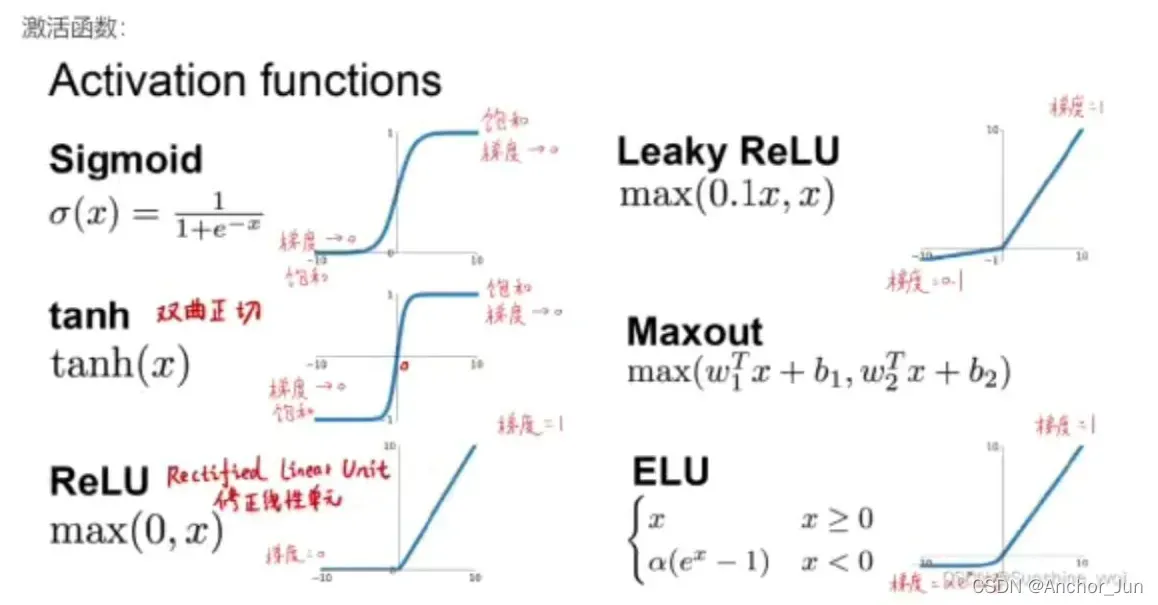 一般常用的激活函数有如下几种:
一般常用的激活函数有如下几种:
(1)sigmoid函数(0~1):
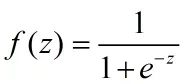
(2)tanh函数(-1~1):
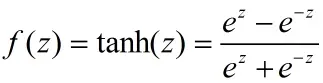
(3)ReLu函数(0~+)
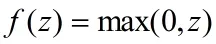
(4)Leaky ReLu函数
【 注:】①sigmoid或tanh作为激活函数做无监督学习时,会因为饱和遇到梯度消失问题导致无法收敛,而且是指数运算导致计算量大。②ReLu函数在神经网络模型研究及实际应用中较多,因为可以避免以上的问题,但是缺点是不能计算x<0。③Leaky ReLu函数超参数可以自行定义,解决ReLu函数的缺点。
三、正则化
1.目的:正则化是为了防止训练的模型产生过拟合, 进而增强泛化能力。
2.正则化的本质:约束(限制)要优化的参数。
3.【理解】 正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束、调整或缩小。也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险。
4.概念
过拟合:当模型过度地学习训练样本中的细节与噪音,把训练样本自身的一些特点当做了所有潜在样本都会具有的一般性质,这样就会导致泛化性能的下降,以至于模型在新的数据上表现很差。
欠拟合:对训练样本的一般性质尚未学好。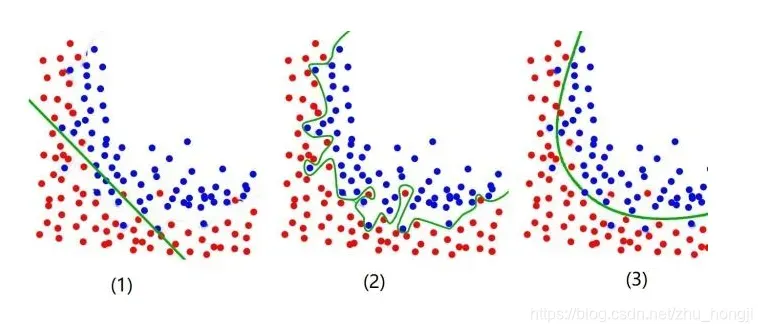
图(1)——欠拟合:模型对训练和预测样本表现很差,特征维度过少,模型过于简单,导致拟合的函数无法满足训练集,误差较大。 需要增加特征维度,增加训练数据;。
图(2)——过拟合:模型过度地学习训练样本中的细节与噪音,把训练样本自身的一些特点当做了所有潜在样本都会具有的一般性质,即特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合的函数完美的预测训练集,但对新数据的测试集预测结果差。 过度的拟合了训练数据,而没有考虑到泛化能力。需要减少特征维度;或者正则化,降低参数值。
图(3)——模型泛化能力较好。
版权声明:本文为博主Anchor_Jun原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Anchor_Jun/article/details/122551088