一、动物的视觉注意力
- 动物需要在复杂环境下有效关注值得注意的点。
- 心理学框架:人类根据随意线索
(主观)和不随意(客观)线索选择注意点。
比如如下例子,第一眼我们会看到红色的杯子,它相比于其它物品颜色偏亮,属于不随意线索。假设拿起杯子喝了之后,接下来想读书,那这就是随意线索(跟随意志,有意识:有意识的关注你想要的)。想要读书的这个随意线索,就代表了我们把注意力要投入到书本当中。
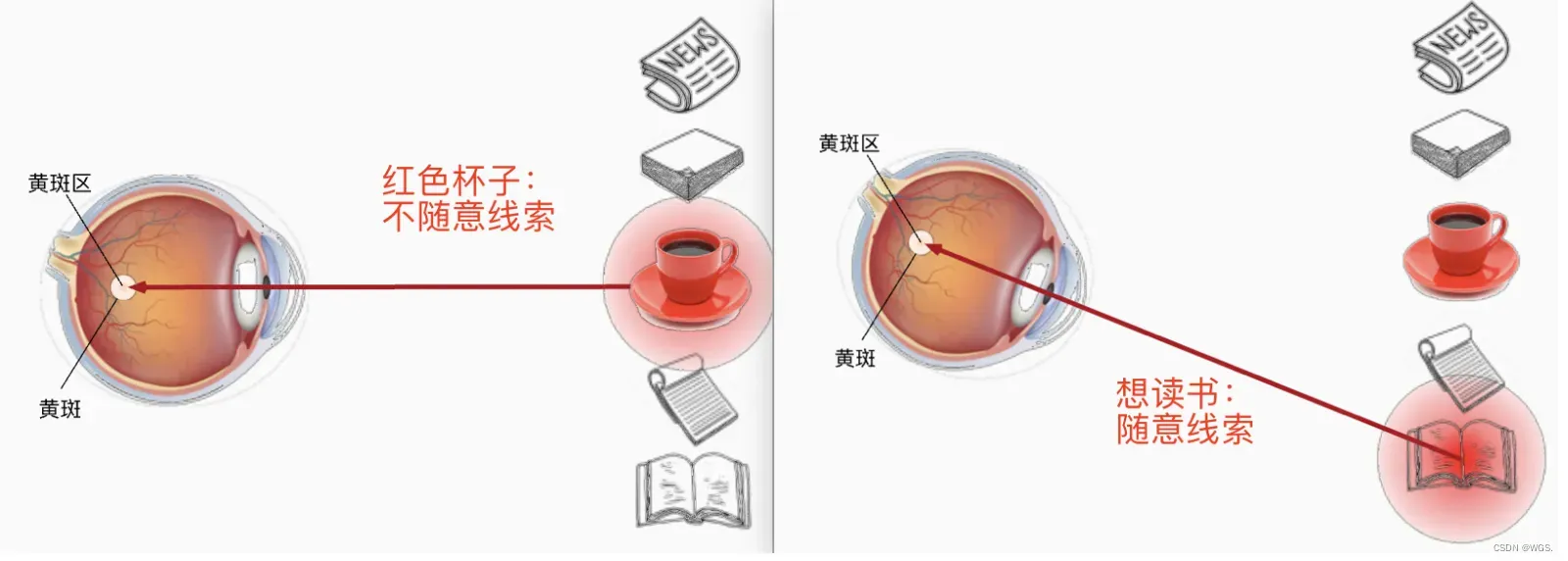
也就是说人类的视野开阔,但是焦点只有一小范围或一个点,这就是所谓的注意力Attention,但是人眼不可能一次性把所有东西都看全面,总会通过一些刻意或不刻意的线索然后通过注意力来接受视野。再比如当你看到这句话的时候,你的注意力在这里,而不是在其它地方。所以在当前计算机算力资源的限制下,注意力机制绝对是提高效率的一种必要手段,将注意力集中到有用的信息上,从而减小在噪声中花费的时间。
二、快速理解Attention思想
深度学习中的注意力和人类的注意力机制有关,上学的时候可能会经常听到老师说:”低着头干嘛,看黑板,听讲“,老师会什么要这么强调听讲呢?因为人类的注意力资源是有限的,我们在关注的目标区域投入更多的注意力资源,从而在目标区域获得更多的信息,抑制其它无用的信息。这种机制可以让我们从大量信息中快速筛选出有价值的信息,而课堂上老师讲的做题技巧和考点对我们来说是更有价值的信息,如果我们把注意力资源全都投入在课本上,就会忽略掉老师讲的重点。
再比如,面对食物的时候,我们会先辨认它的形状、颜色,随后可能会闻一闻气味,再尝一尝味道,然后确认这是一盘小酥肉。那么在认出小酥肉的这个过程中,每个阶段我们关注的内容都有所不同。在令Attention崛起的机器翻译场景中亦是如此,比如翻译“我爱你中国时”,我们会格外注意其中的一部分汉子,比如“China”。我们希望机器也能学会这种处理信息的方式,于是就有了注意力机制Attention,可以形象的理解为,注意力可以从纷繁复杂的输入信息中,找出对当前输出最重要的部分。
- 所以注意力的核心目标就是从众多信息中选择出对当前任务目标更关键的信息,将注意力放在上面。
- 本质思想就是【从大量信息中】【有选择的筛选出】【少量重要信息】并【聚焦到这些重要信息上】,【忽略大多不重要的信息】。聚焦的过程体现在【权重系数】的计算上,权重越大越聚焦于其对应的value值上。即权重代表了信息 的重要性,而value是其对应的信息。
三、从Encoder-Decoder框架中理解为什么要有Attention机制
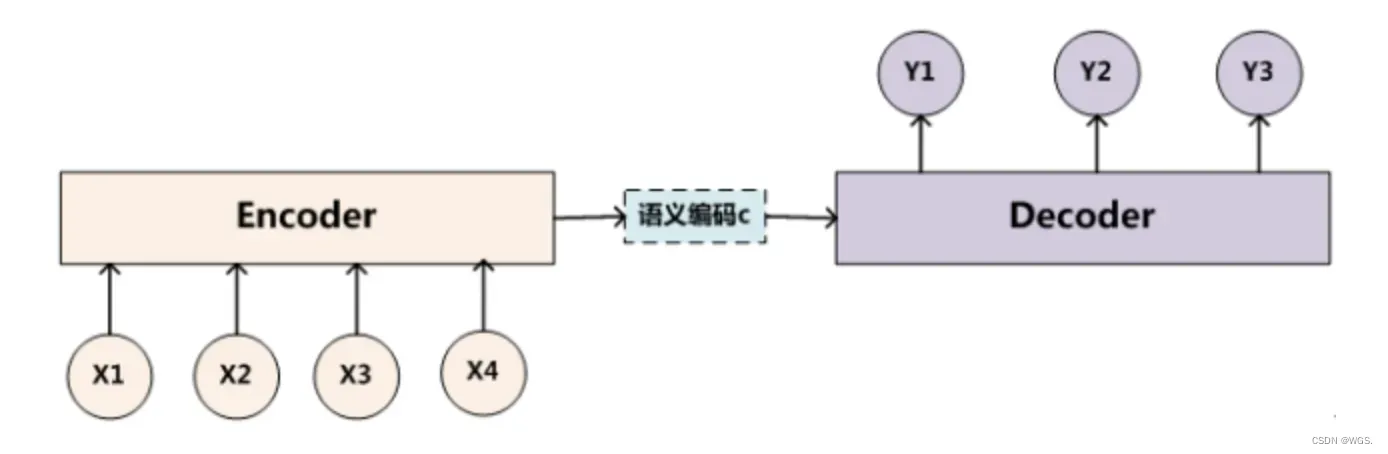
上图中的框架并没有体现出注意力机制,所以可以把它看做分心模型,为什么说它注意力不集中分心呢?请看Decoder部分每个单词的生成过程:
其中f是解码器的非线性变换函数,从这里我们可以看出,在生成目标句子的单词时,无论生成那个单词,它们使用的输入句子的语义编码c都是一样的,没有任何区别。
而语义编码c是由句子的每个单词经过Encoder编码产生的,这意味着不论是生成哪个单词,句子中任意单词对某个目标单词y的影响力都是相同的,就像是人类的眼中没有注意力焦点是一样的。
比如在机器翻译场景中,输入的英文句子为:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:”汤姆“、”追逐“、”杰瑞“。在翻译”杰瑞“这个单词的时候,分心模型里面每个英文单词对于翻译目标单词”杰瑞“的贡献程度是相同的,这很显然是不合道理的。显然”Jerry“对于翻译成”杰瑞“更为重要。
那么它会存在什么问题呢?类似RNN无法捕捉长序列的道理,没有引入Attention机制在输入句子较短时影响不大,但是如果输入句子比较长,此时所有语义通过一个中间语义向量表示,单词自身的信息避免不了会消失,也就是会丢失很多细节信息,这也是为何引入Attention机制的原因。
例如上面的例子,如果引入Attention的话,在翻译”杰瑞“的时候,会体现出英文单词对于翻译当前中文单词的不同程度影响,比如给出类似下面的概率分布:
每个英文单词的概率代表了翻译当前单词”杰瑞“时,注意力分配给不同英文单词的权重大小,这对于正确翻译目标单词是有着积极作用的。
目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词yi的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的Ci。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。增加了注意力模型的Encoder-Decoder框架理解起来如下图所示:
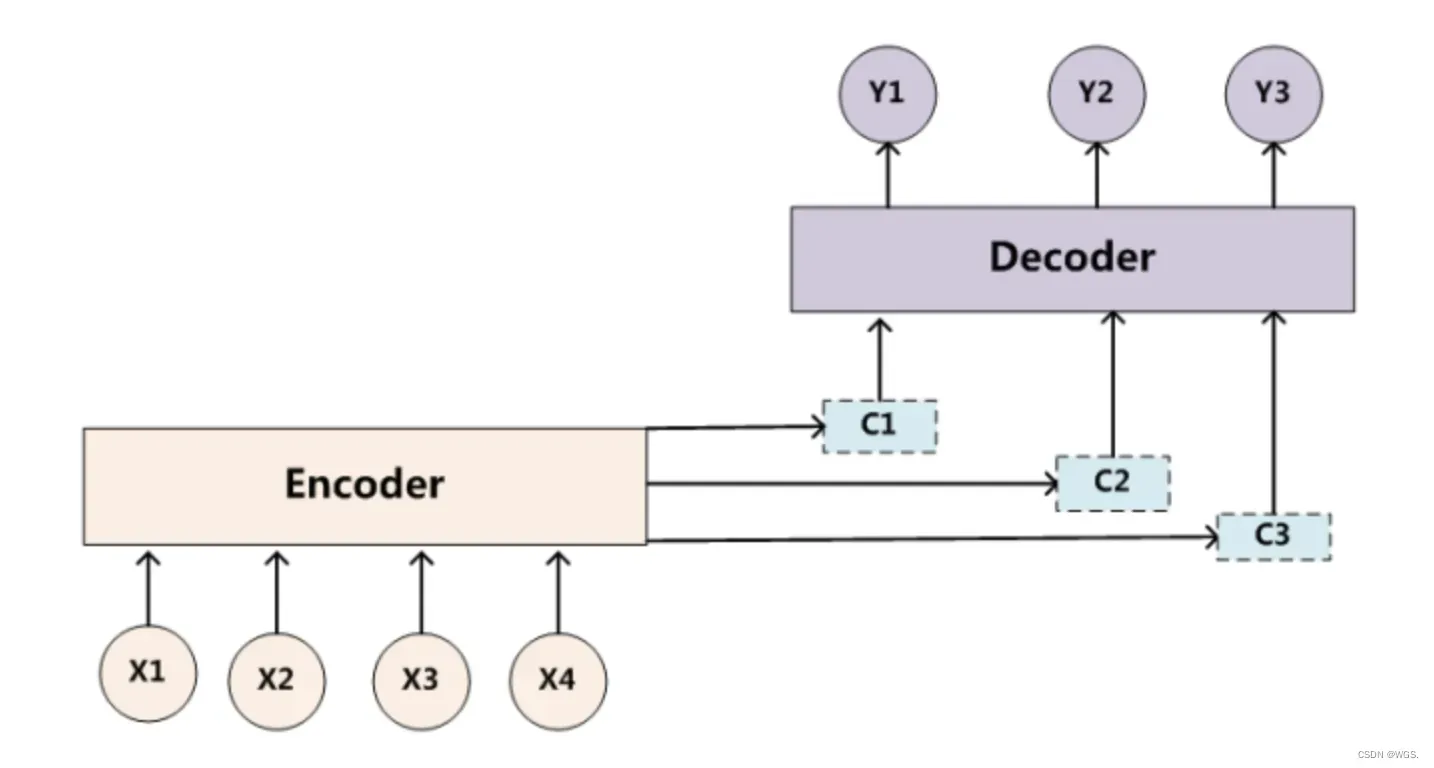
即生成目标句子单词的过程成了下面的形式:
而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:
其中,f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入xi后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即下列公式:
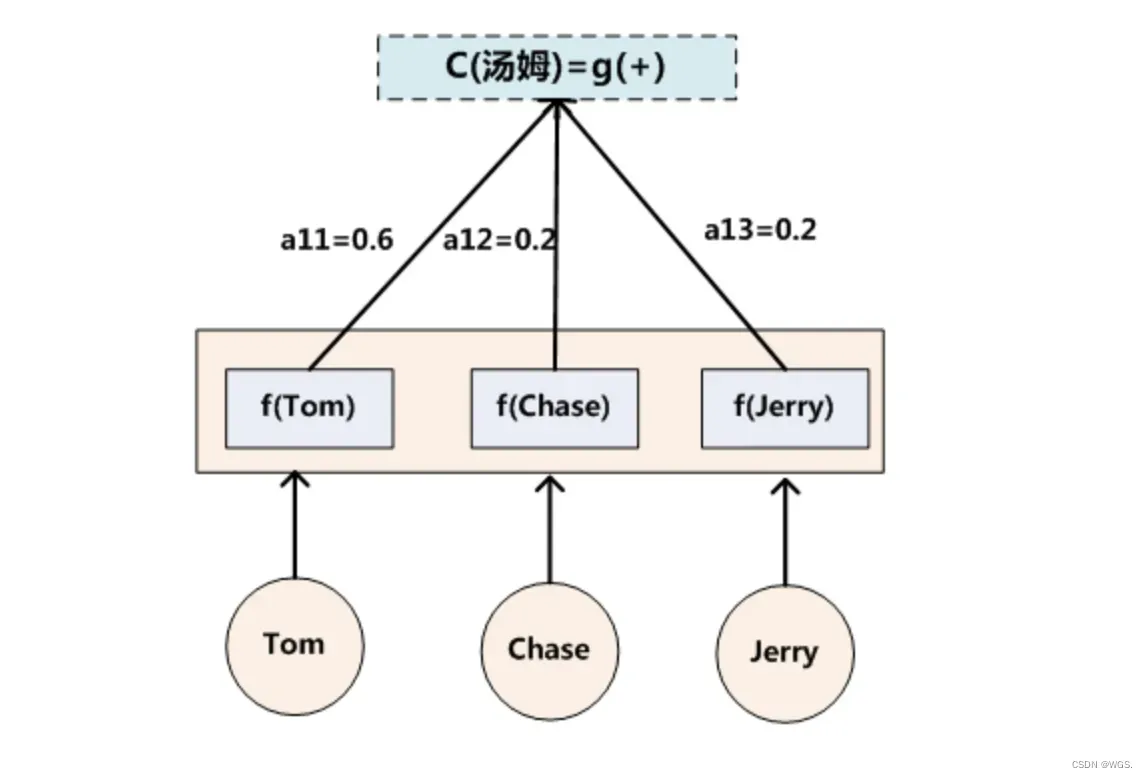
其中,Lx代表输入句子Source的长度,aij代表在Target输出第i个单词时Source输入句子中第j个单词的注意力分配系数,而hj则是Source输入句子中第j个单词的语义编码。假设下标i就是上面例子所说的“ 汤姆” ,那么Lx就是3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是0.6,0.2,0.2,所以g函数本质上就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,公式对应的中间语义表示Ci的形成过程类似下图。
四、Attention思想步骤
一个典型的Attention思想包括三部分:Qquery、Kkey、Vvalue。
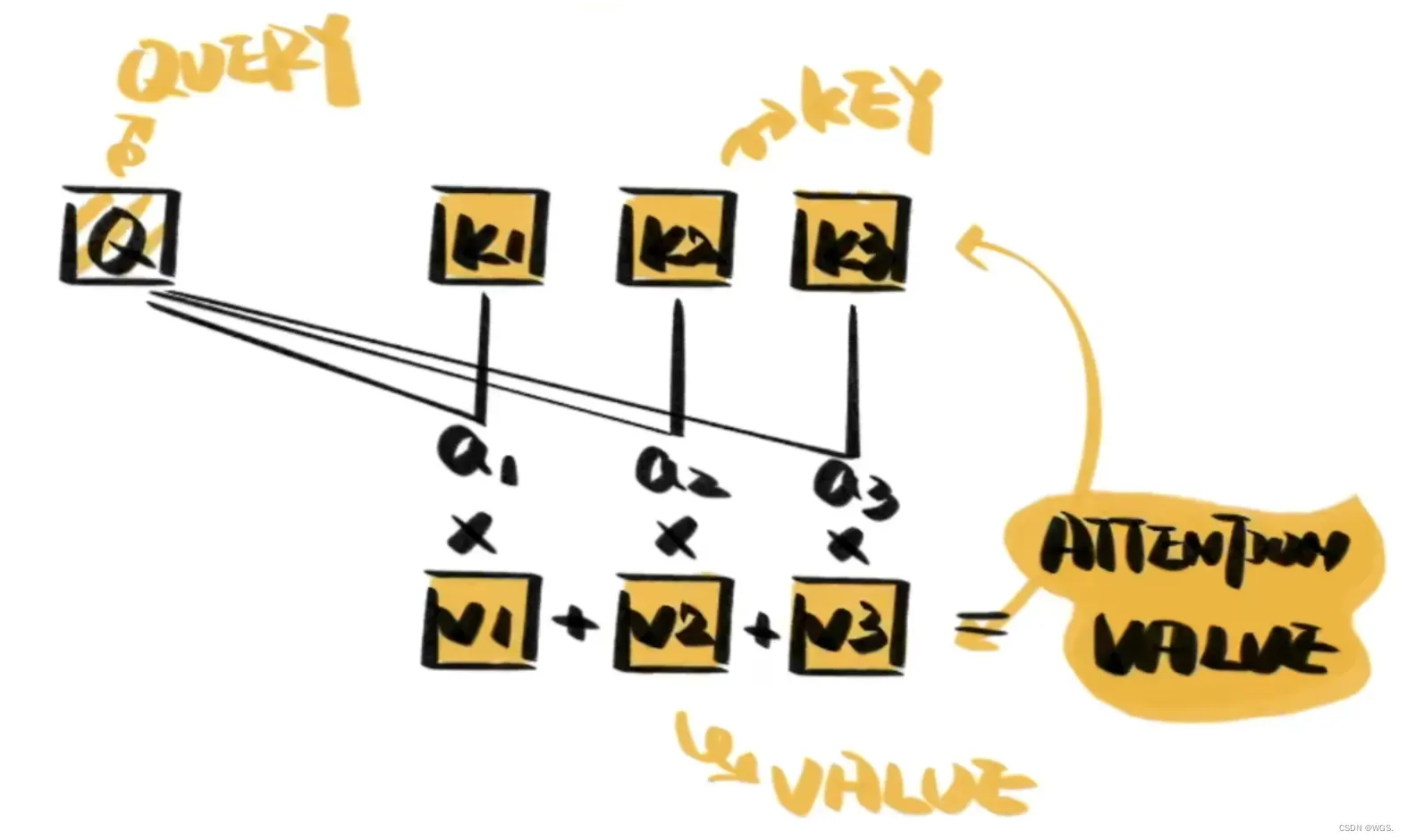
- Q是query,是输入的信息;key和value成组出现,通常是原始文本等已有的信息;
- 通过计算Q与K之间的相关性a,得出不同的K对输出的重要程度;
- 再与对应的v进行相乘求和,就得到了Q的输出;
来看下面更详细一点的图:
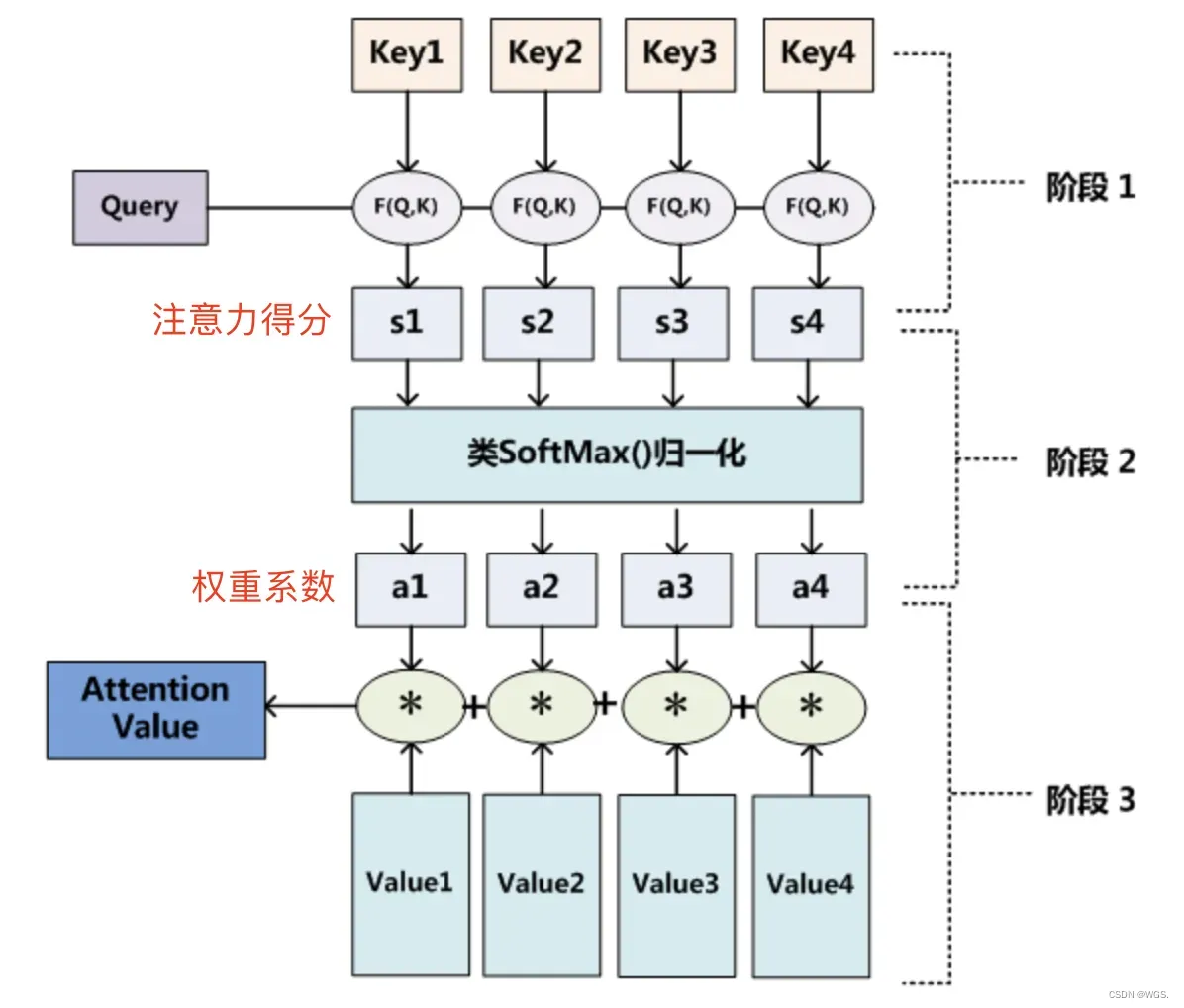
- step1,计算Q对每个K的相关性
相似性,即函数;
- 这里计算相关性的方式有很多种,常见方法比如有:
- 求两者的【向量点击】,
。
- 求两者的向量【余弦相似度】,
。
- 引入一个额外的神经网络来求值,
。
- step2,对step1的注意力的分进行归一化;
- softmax的好处首先可以将原始计算分值整理成所有元素权重之和为1的概率分布;
- 其次是可以通过softmax的内在机制更加突出重要元素的权重;
即为value_i对应的权重系数;
- step3,根据权重系数对V进行加权求和,即可求出针对Query的Attention数值。
值得强调的一点是:K和V等价,它俩是一个东西。
五、Self-Attention
self-attention,顾名思义它只关注输入序列元素之间的关系,即每个输入元素都有它自己的Q、K、V,比如在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素Query和Source中的所有元素之间。而Self Attention指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。
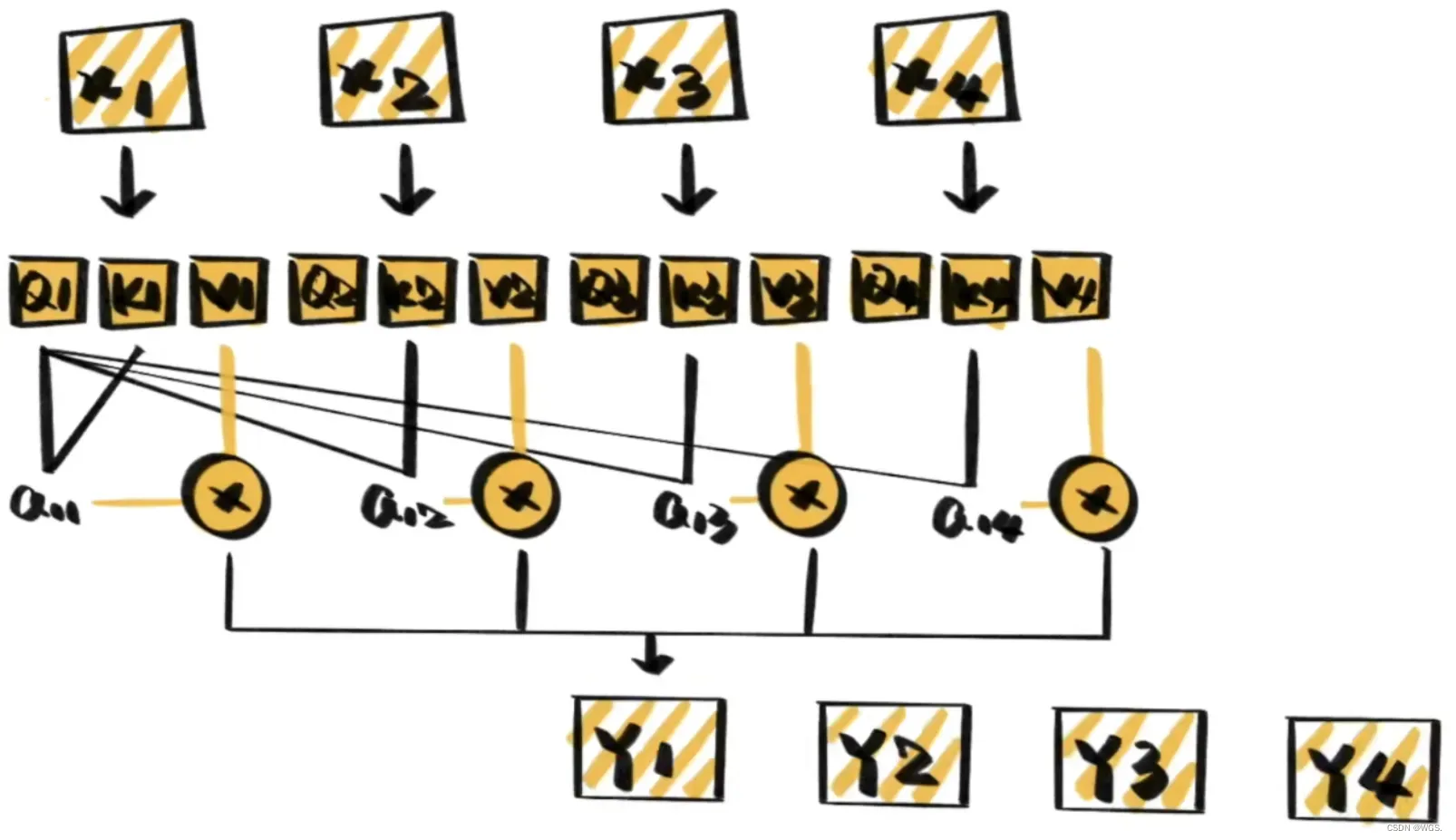
5.1 Self-Attention的计算步骤
根据attention is all you need原文给出的缩放点击注意力公式来看self-attention的计算过程:
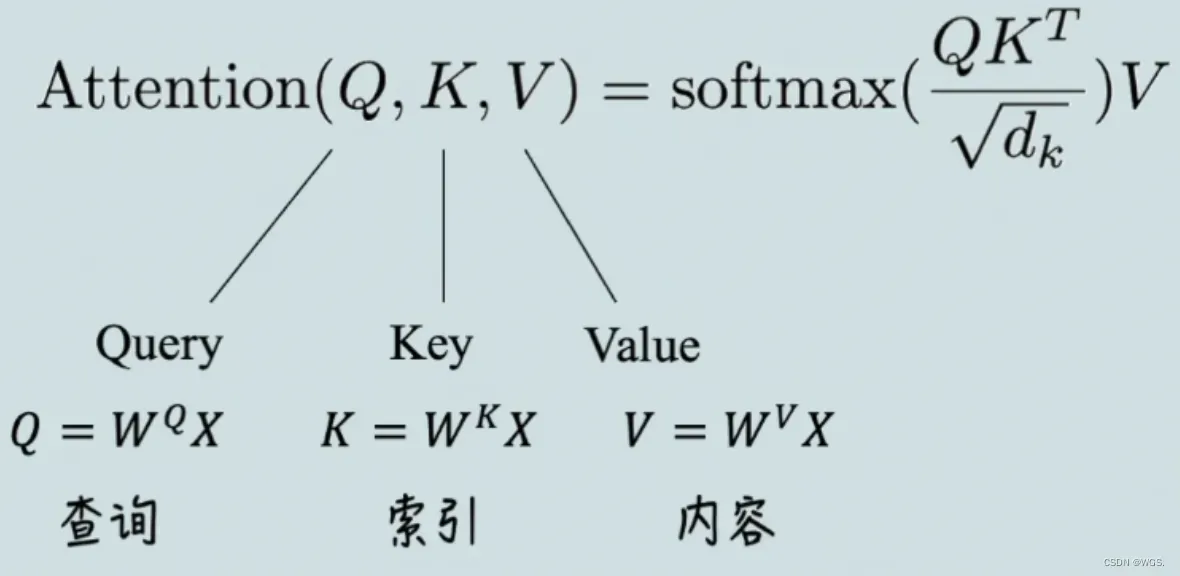
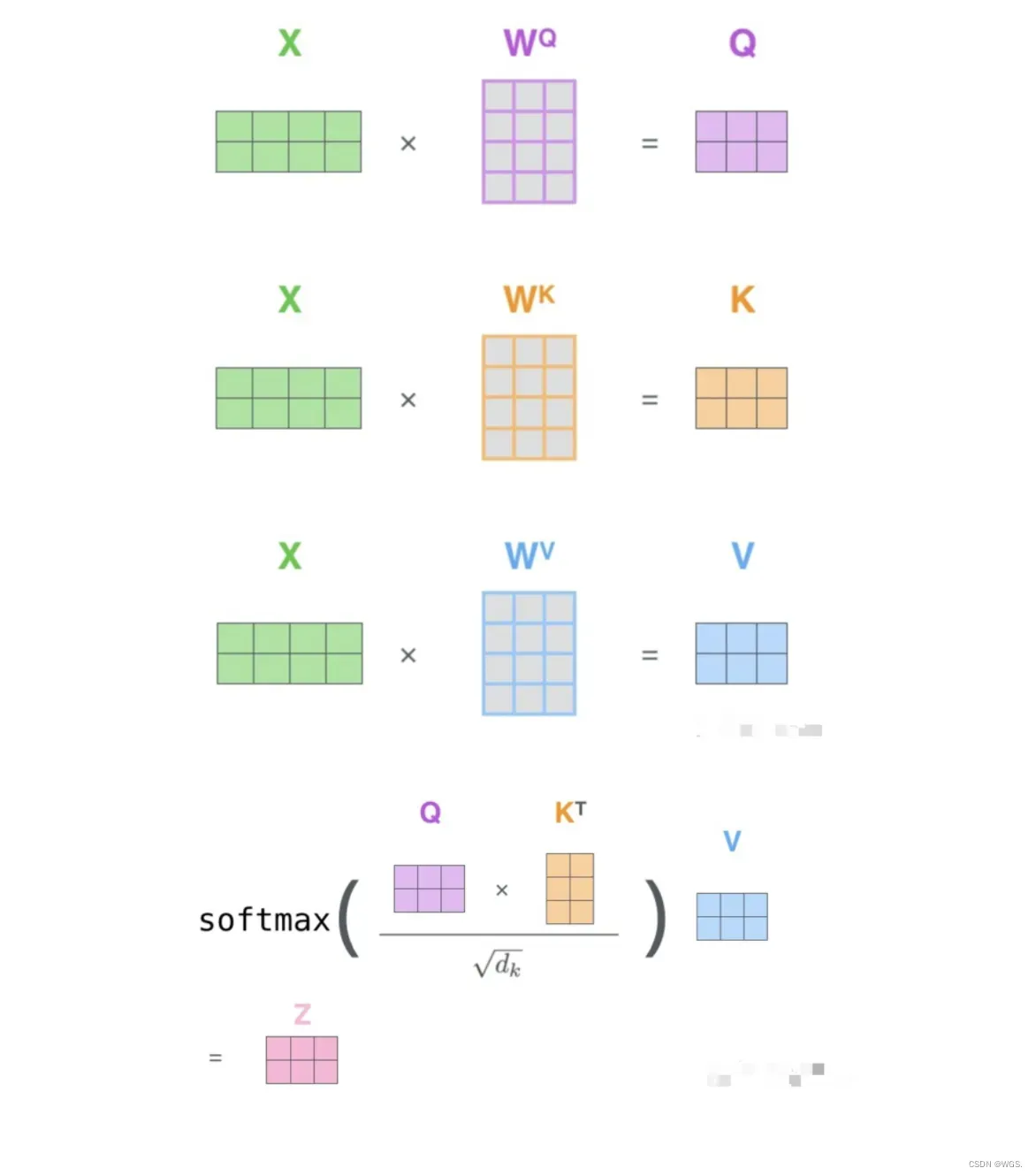
在self-attention中,每个单词有3个不同的向量,即Q、K、V。它们是通过X乘以三个不同的权值矩阵得到的,其中三个矩阵的尺寸也是相同的,这三个矩阵也是需要学习的。
可以理解为:self-Attention中的Q是对自身(self)输入的变换,而在传统的Attention中,Q来自于外部。
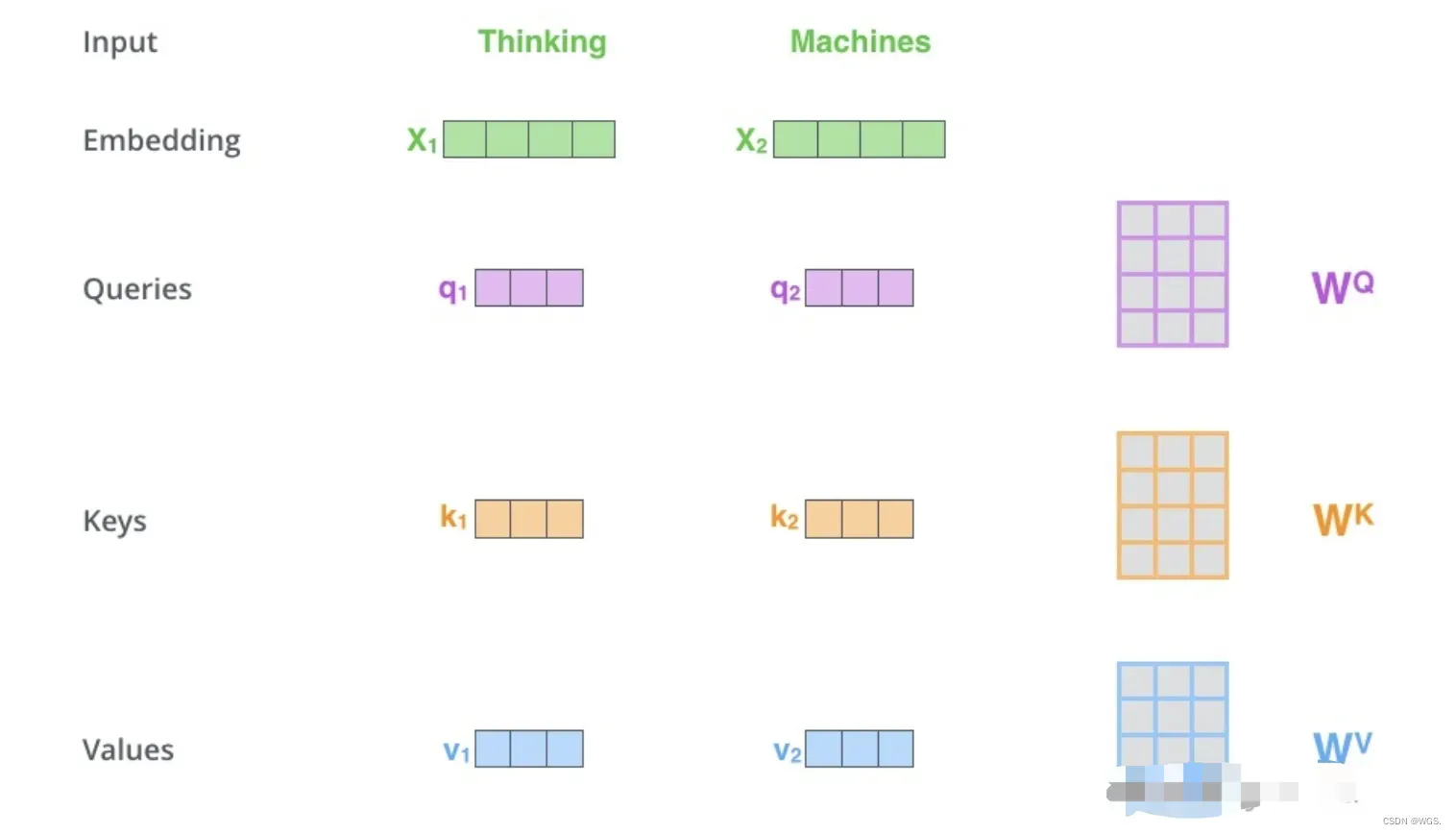
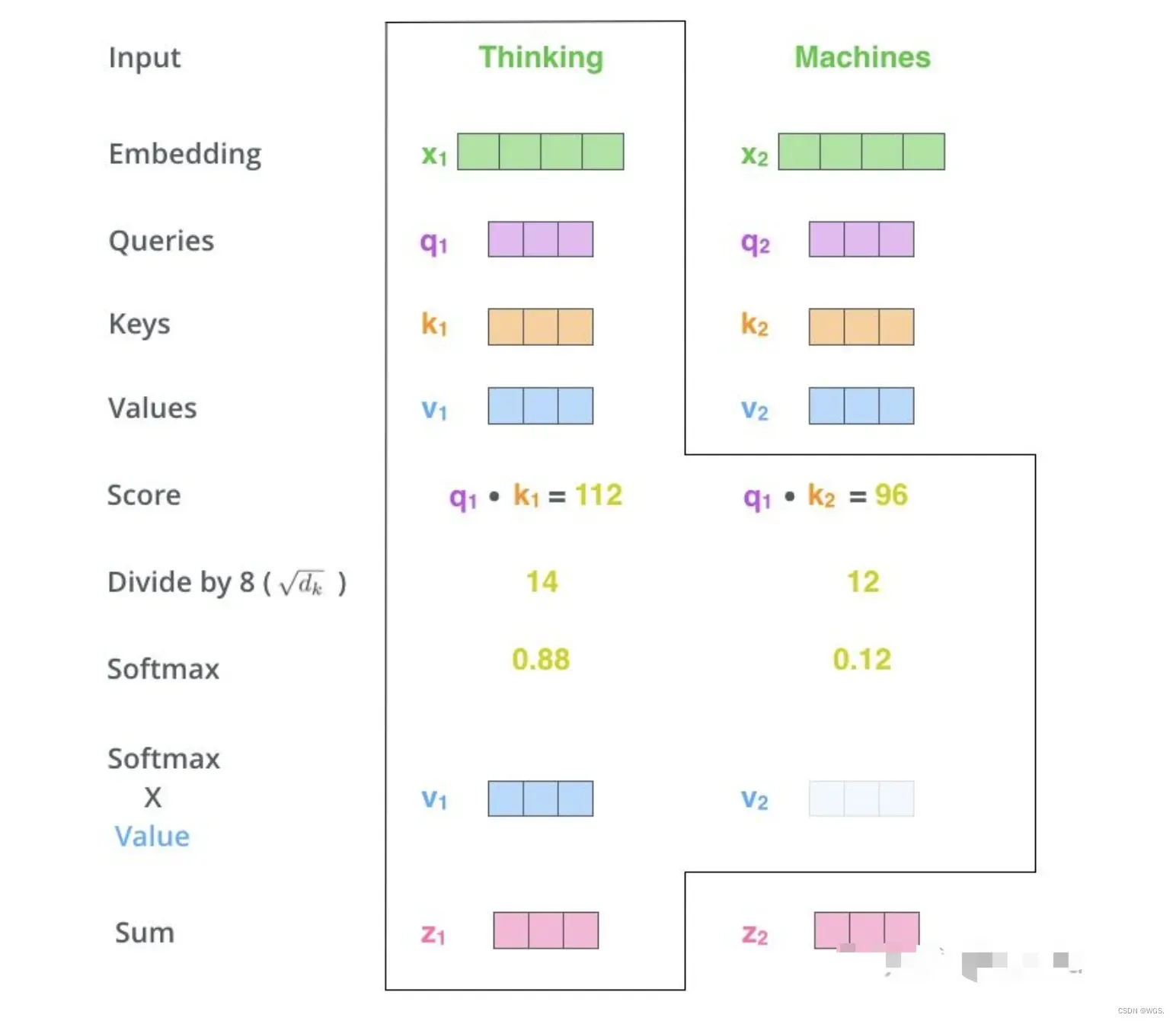
那么整个self-attention的计算过程可以如下:
- 1.首先就是基本的embedding将输入单词转为词向量;
- 2.根据嵌入向量利用矩阵乘法得到q、k、v三个向量;
- 3.为每一个向量计算一个相关性score:
;
- 4.为了梯度的稳定,除以根号dk,下面会给出推导;
- 5.进行softmax归一化得到权重系数;
- 6.与value点乘得到加权的每个输入向量的评分v;
- 7.相加之后得到最终的输出结果
;
Q、K、V的矩阵计算示意图如下:
5.2 根据代码进一步理解Q、K、V
- 首先定义三个线性变换矩阵:
;
class BertSelfAttention(nn.Module):
self.w_q = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
self.w_k = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
self.w_v = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
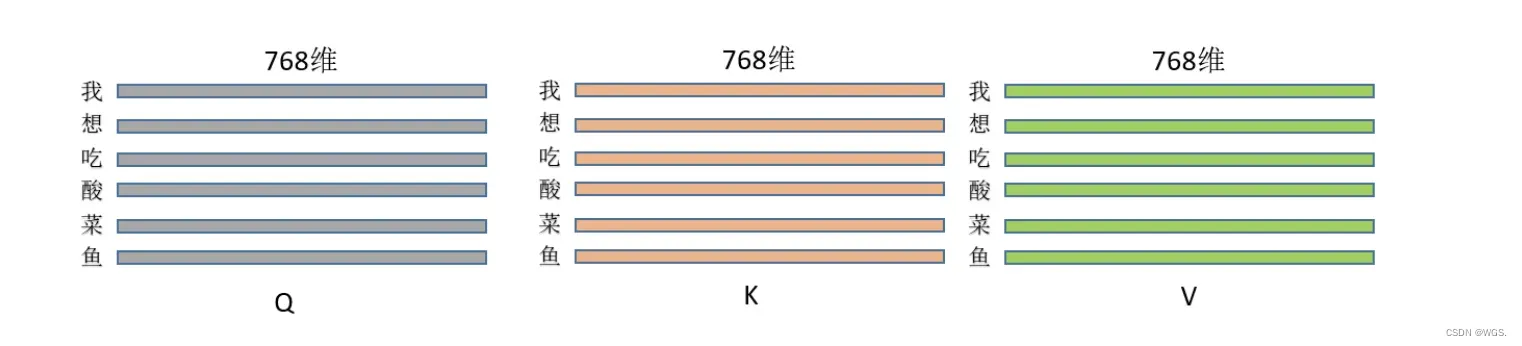
- 假设三种操作的输入都是同一个矩阵,这里暂且定为长度为L的句子,每个token的特征维度是768,那么输入就是(L, 768),每一行就是一个字,像这样:
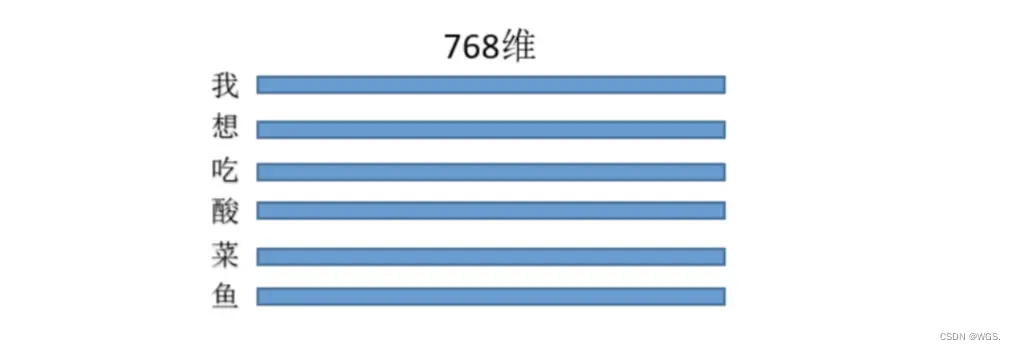
乘以上面三种操作就得到了Q、K、V,(L, 768)*(768,768) = (L,768),维度其实没变,即此刻的Q、K、V分别为:
class BertSelfAttention(nn.Module):
def __init__(self, config):
self.w_q = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
self.w_k = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
self.w_v = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
def forward(self,hidden_states): # hidden_states 维度是(L, 768)
Q = self.query(hidden_states)
K = self.key(hidden_states)
V = self.value(hidden_states)
- 然后根据缩放点积公式进行打分;
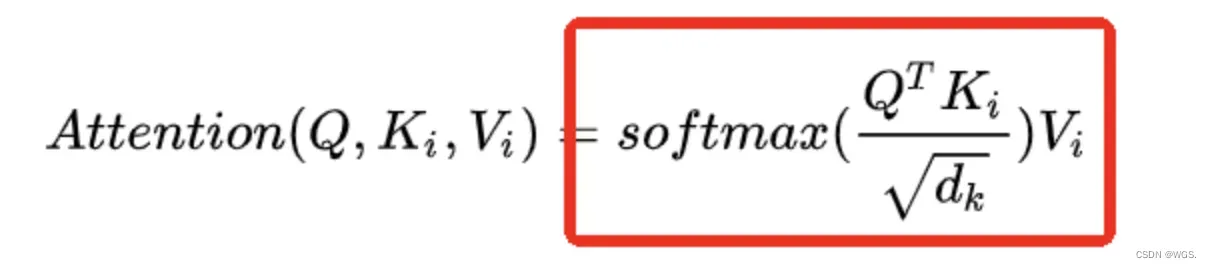
3.1 首先是Q和K矩阵乘,,看图:
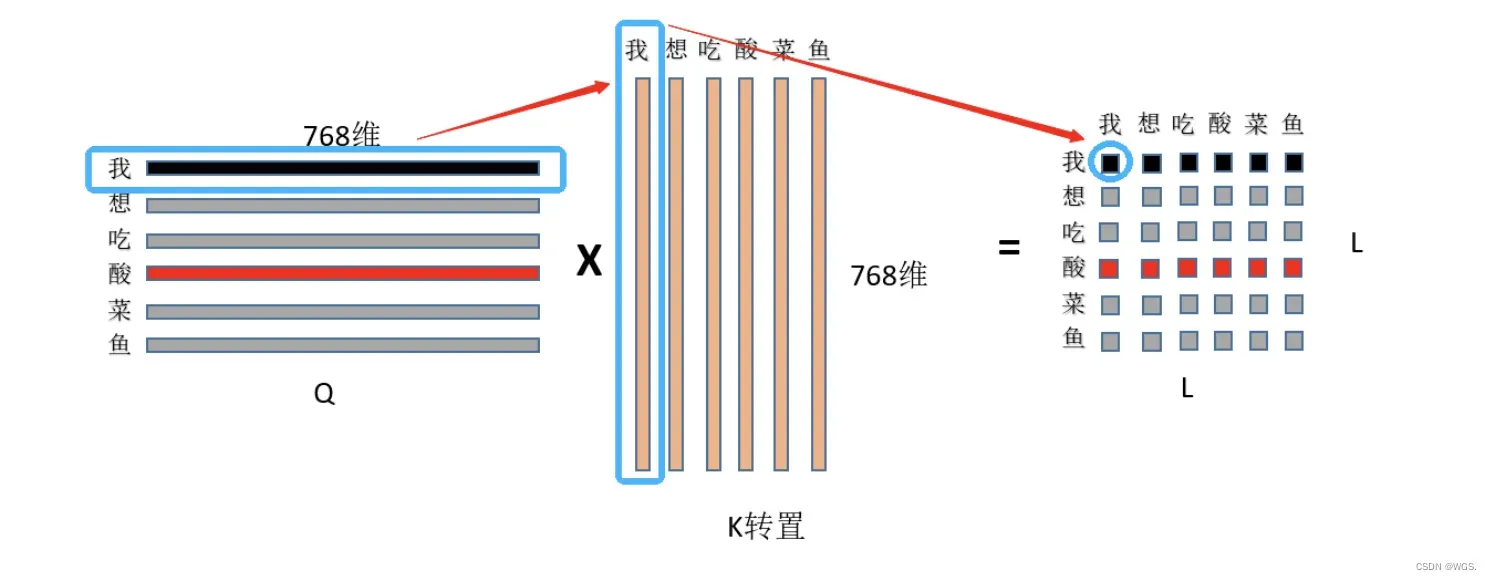
- 首先用Q的第一行,即“我”字的768特征和K中“我”字的768为特征点乘求和,得到输出(0,0)位置的数值,这个数值就代表了“我想吃酸菜鱼”中“我”字对“我”字的注意力权重,
- 然后显而易见输出的第一行就是“我”字对“我想吃酸菜鱼”里面每个字的注意力权重;整个结果自然就是“我想吃酸菜鱼”里面每个字对其它字(包括自己)的注意力权重(就是一个数值)了。
3.2 然后是除以根号dim,这个dim就是768,至于为什么要除以这个数值?主要是为了缩小点积范围,确保softmax梯度稳定性。
3.3 然后就是刚才的注意力权重和V矩阵乘了,如图:
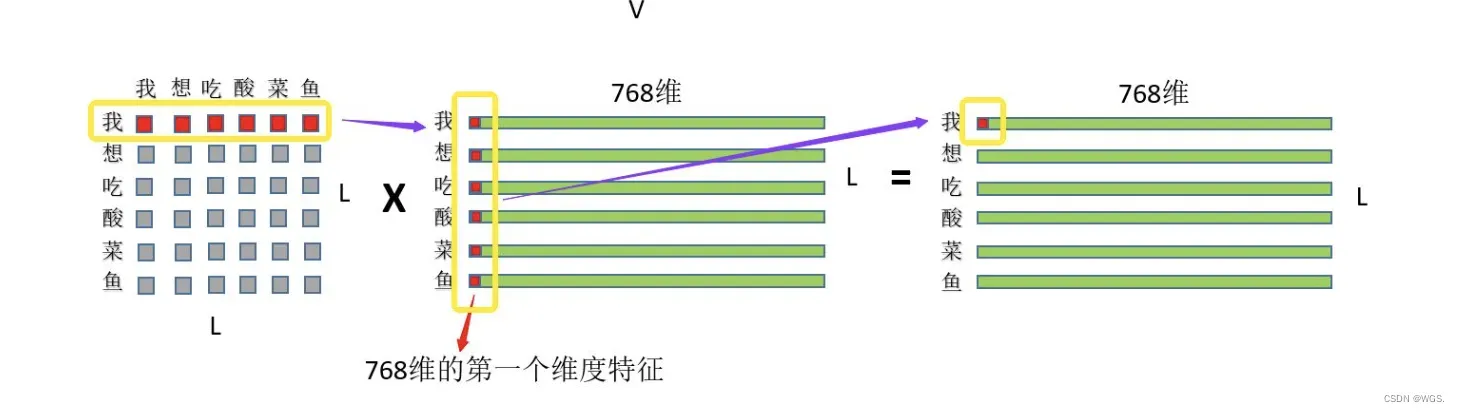
首先是“我”这个字对“我想吃酸菜鱼”这句话里面每个字的注意力权重,和V中“我想吃酸菜鱼”里面每个字的第一维特征进行相乘再求和,这个过程其实就相当于用每个字的权重对每个字的特征进行加权求和,然后再用“我”这个字对对“我想吃酸菜鱼”这句话里面每个字的注意力权重和V中“我想吃酸菜鱼”里面每个字的第二维特征进行相乘再求和,依次类推最终也就得到了(L,768)的结果矩阵,和输入保持一致。
class BertSelfAttention(nn.Module):
def __init__(self, config):
self.w_q = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
self.w_k = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
self.w_v = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
def forward(self,hidden_states): # hidden_states 维度是(L, 768)
Q = self.query(hidden_states)
K = self.key(hidden_states)
V = self.value(hidden_states)
attention_scores = torch.matmul(Q, K.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = nn.Softmax(dim=-1)(attention_scores)
out = torch.matmul(attention_probs, V)
return out
看到这里是不是会注意力有了很深的印象,当然这里埋伏一手:
注意力机制是没有位置信息的,所以需要引入位置编码,下一篇transformer中会讲解。
5.3 再来一个例子理解
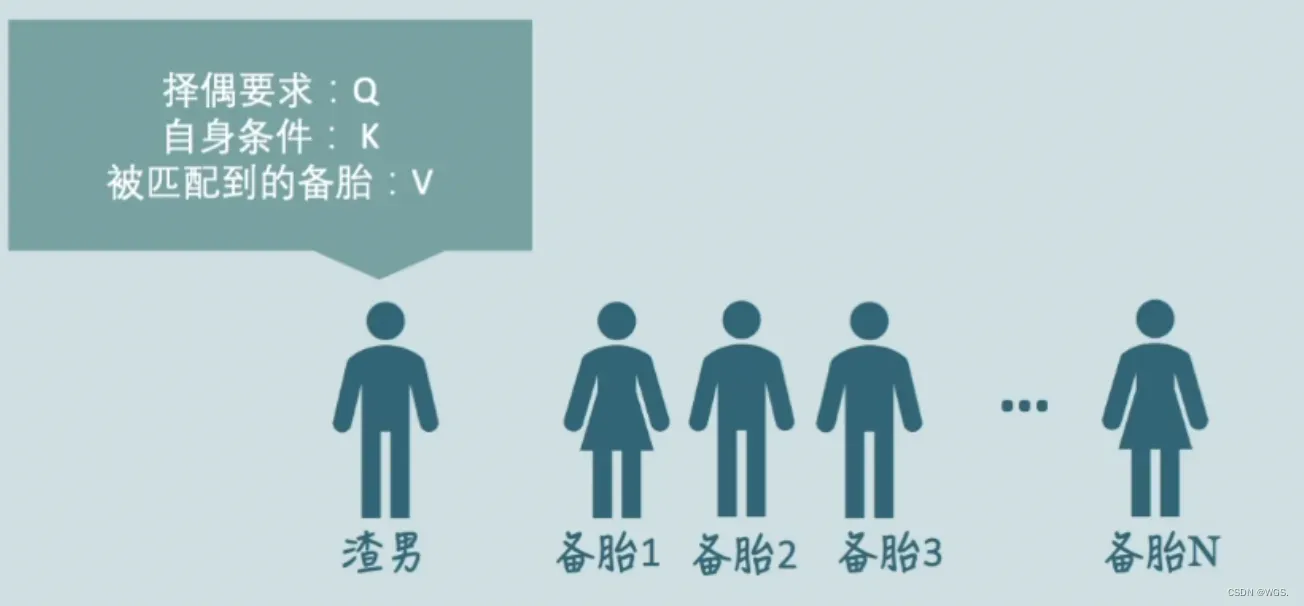
有一个渣男,他有N个备胎,他想要从自己的备胎里寻找出最符合自己期望的好分配注意力和管理时间,我们用Q来表示它的期望条件,渣男选备胎的同时,备胎也要看他的条件,我们就用K来表示渣男的自身条件,无论是渣男还是备胎,都有自己的一套Q、K、V。
那么什么样的备胎更适合渣男呢?
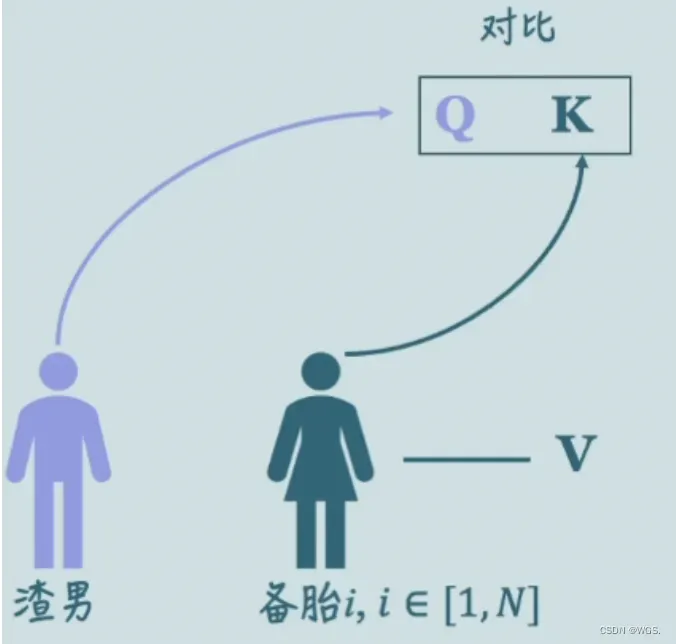
当然是条件和渣男的择偶标准更相似的,也就是备胎的K和渣男的Q相似度更高的。
我们来回忆一下点乘的几何意义,向量A和向量B的点乘,也就是A在B上的投影和B的模相乘,这个值反应了这两个向量的相似度。
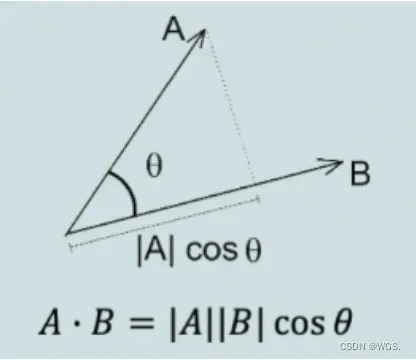
如果这两个向量相互垂直,它们的点乘就是0,这两个向量就没有一点相关性,如果它们的点乘越大,两个向量之间的相似度也就越高。
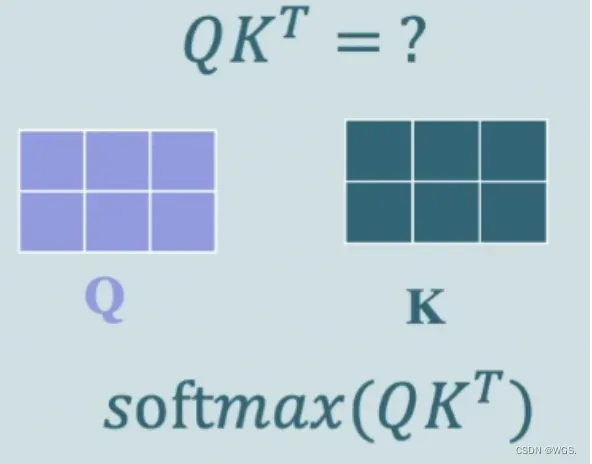
Q和K的转置相乘是在算什么呢?是Q的每一行和K的每一行的点乘,是每个行向量的相关性,然后用softmax进行归一化,就得到了权重矩阵;
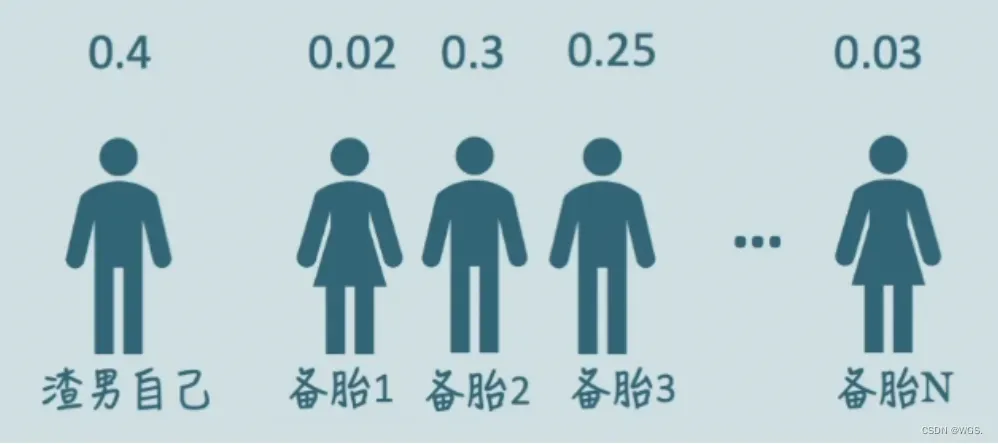
接下来用得到的权重给备胎加权,渣男就知道该对谁付出多少的注意力了。当然也会有理想型是自己的情况,即渣男最需要关注的是自己。
复习下流程:
- 输入X和三个矩阵相乘,分别得到三个矩阵Q、K、V,Q是我们正要查询的信息,K是正在被查询的信息,V是被查询到的内容;
- 我们用Q和K的转置的点乘得到这两条信息的相似程度,再除以根号dk,使训练时的梯度保存稳定;
- 经过softmax得到权重矩阵,用这个权重矩阵和内容V进行加权,也就是相乘,这就是self-attention的原理。
六、缩放点积中为什么要除以根号dk
在两个向量维度非常大的时候,点乘结果的方差也会很大,即结果中的元素差距很大,在点乘的值非常大的时候,softmax的梯度会趋近于0,也就是梯度消失。在原文中有提到,假设q和k的元素是相互独立维度为dk的随机变量,它们的均值是0,方差为1,那么q和k的点乘的平均值为0,方差为dk,如果将点乘的结果进行缩放操作,也就是除以dk,就可以有效控制方差从dk回到1,也就是有效控制梯度消失问题。
6.1 为什么比较大的输入会使得softmax的梯度变得很小?
对于一个输入向量,softmax将其归一化到一个分布
。在这个过程中,softmax是先用一个自然底数
将输入中的元素间差距”拉大“,然后归一化到一个分布。假设某个输入x中最大的元素下标是k,如果输入的数量级变大(每个元素都很大),那么
会非常接近于1。
我们可以用一个小例子来看看x的数量级对输入最大元素对应的预测概率的影响。假定输入:
,我们来看不同量级的a产生的
有什么区别:
我们不妨把a在不同取值下,对应的全部绘制出来。代码如下:
from math import exp
from matplotlib import pyplot as plt
import numpy as np
f = lambda x: exp(x * 2) / (exp(x) + exp(x) + exp(x * 2))
x = np.linspace(0, 100, 100)
y_3 = [f(x_i) for x_i in x]
plt.plot(x, y_3)
plt.show()
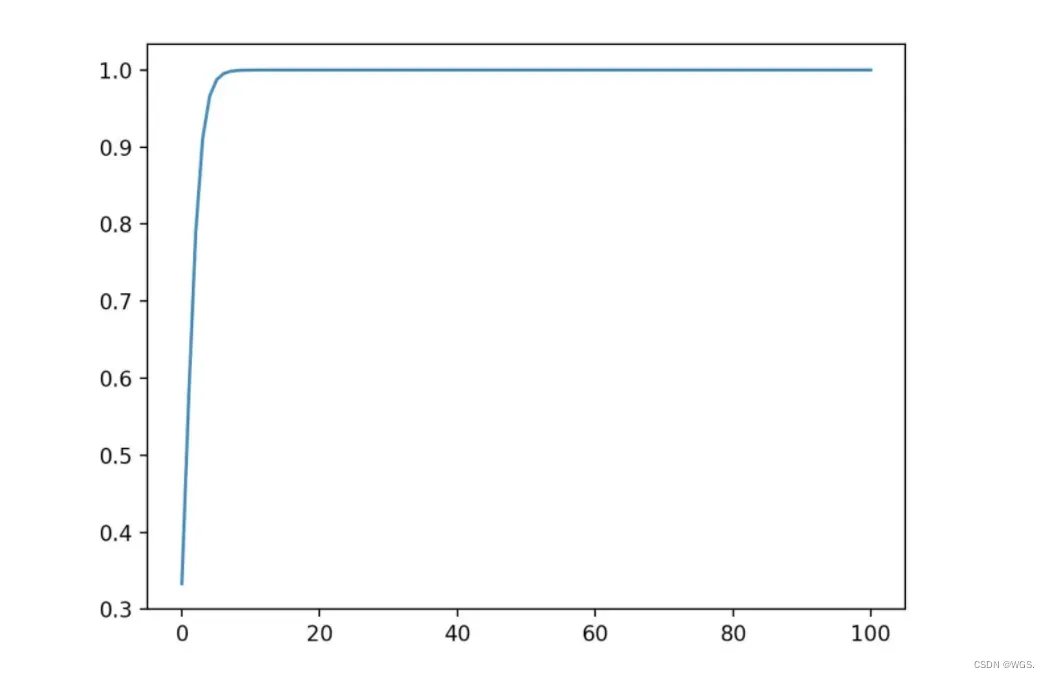
可以看到,数量级对softmax得到的分布影响非常大。在数量级较大时,softmax将几乎全部的概率分布都分配给了最大值对应的标签。

6.2 维度与点积大小的关系是怎么样的,为什么使用维度的根号来放缩?
针对为什么维度会影响点积的大小,在论文的脚注中其实给出了一点解释:

方差大表示各个分量的差距较大,然后softmax中的指数运算会进一步加大差距,导致最大值对应的概率很大,其他分量的概率很小。容易导致梯度消失,所以需要将其方差归一化到1。
七、Multi-Head Attention
在理解了self-attention之后,对于多头注意力的理解就很简单了。多头注意力机制,是在自注意力的基础上,使用多种变换生成的Q、K、V进行计算,再将它们对相关性的结论综合起来,进一步增强自注意力的效果。
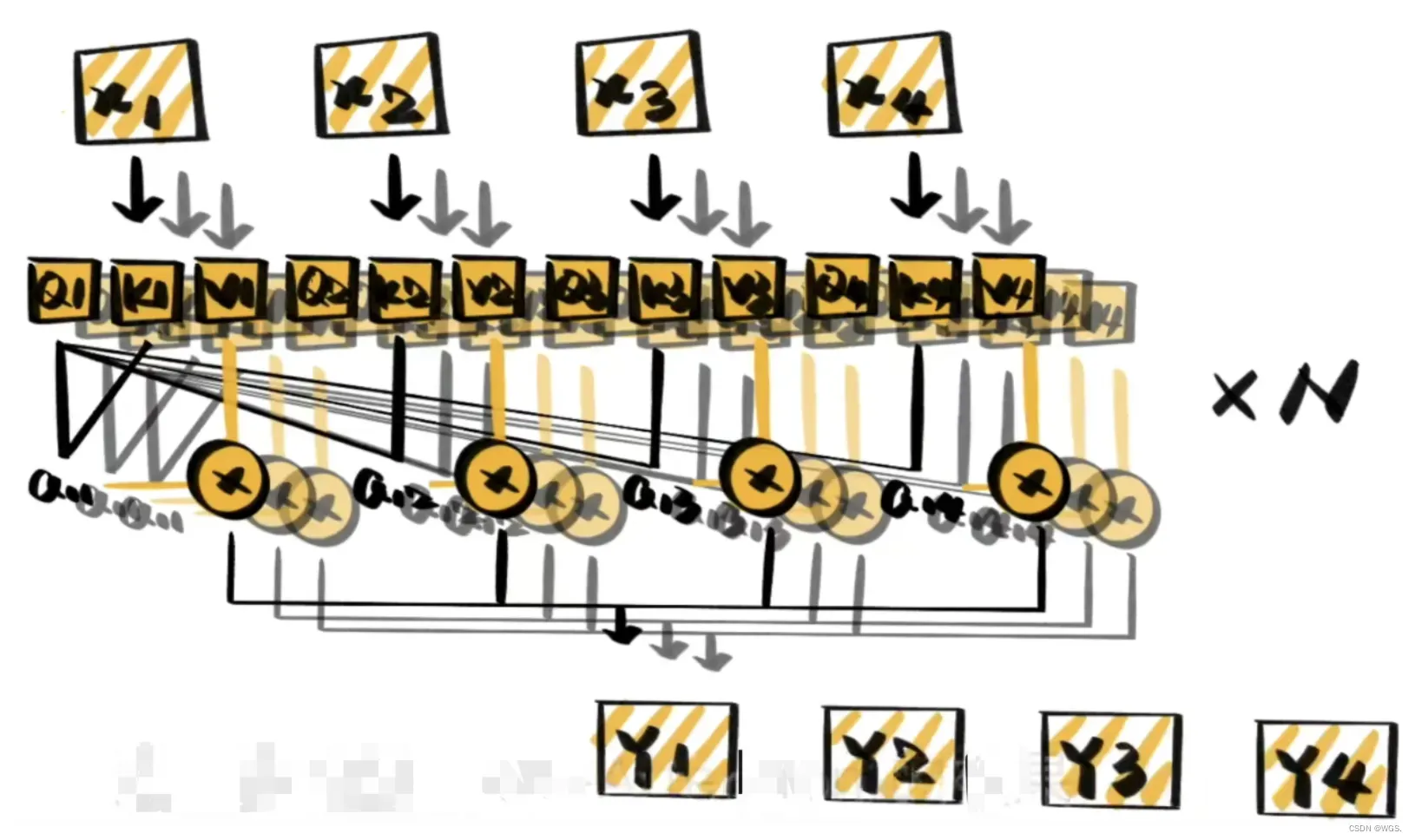
进一步的,multi-head attention相当于h个不同的self-attention的集成,说白了就是对其的简单堆叠,在这里以h=8举例说明:
- 1.将数据X分别输入到下图8个self-attention中,得到8个加权后的特征矩阵
;
- 2.将8个
按列拼成一个大的特征矩阵;
- 3.将特征矩阵经过一层全连接得到输出
。
本文没提,self-attention和multi-head attention之后都用了残差网络的跳跃连接。
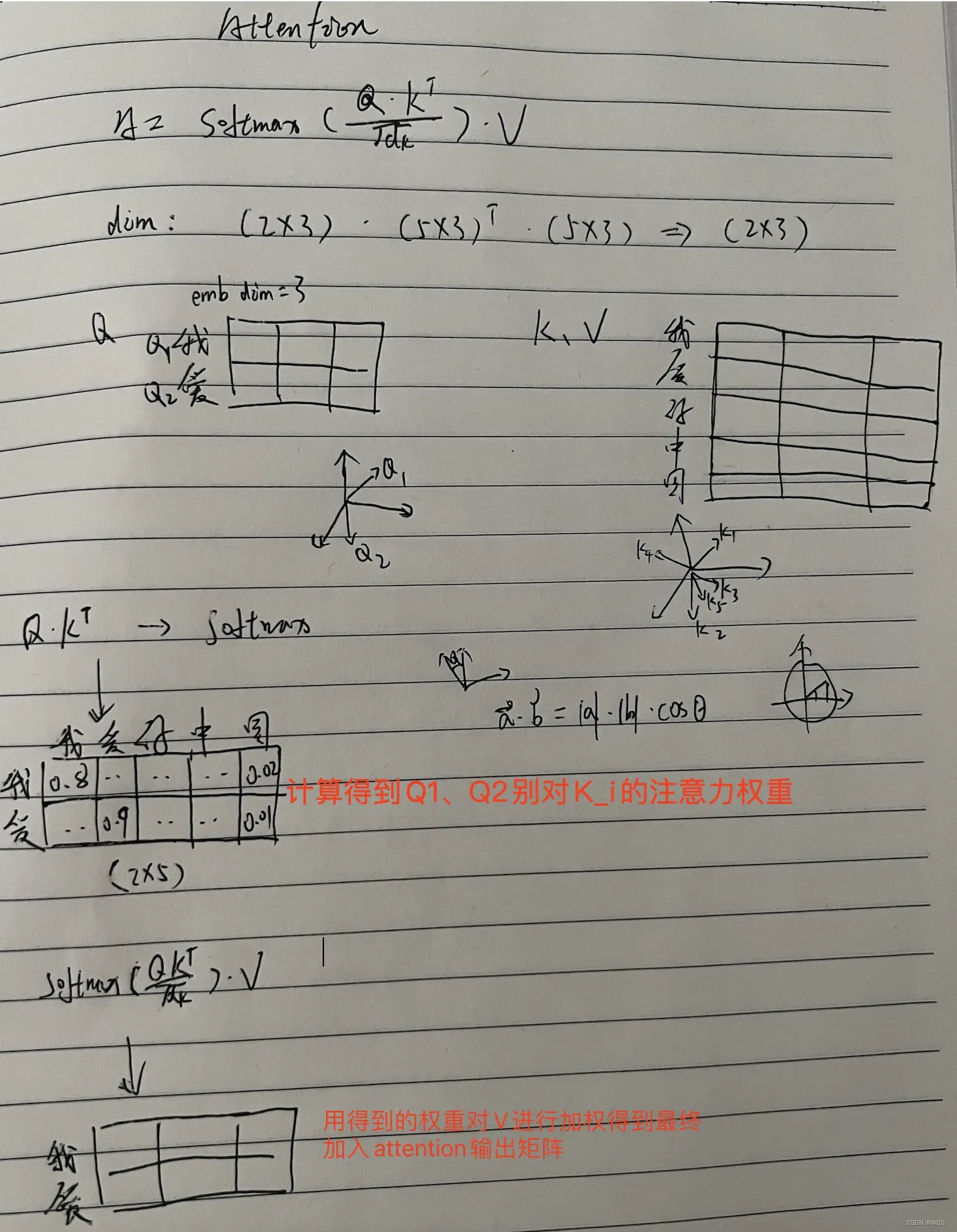
八、Attention手稿
如果看到这了,你还不明白Attention是怎么回事,那就看下博主的亲笔吧!
References
https://www.zhihu.com/question/339723385/answer/782509914
https://zhuanlan.zhihu.com/p/48508221
https://fanrenyi.com/blog/467
https://www.bilibili.com/video/BV1PP4y1T7Yu/?spm_id_from=333.788
https://luweikxy.gitbook.io/machine-learning-notes/self-attention-and-transformer
https://www.bilibili.com/video/BV1XT4y1y7P7?spm_id_from=333.337.search-card.all.click
文章出处登录后可见!