用 Python 从 LIME 中榨取更多
如何创建 LIME 权重的全局聚合

LIME 是一种解释机器学习模型如何工作的流行方法。它旨在解释如何做出个人预测。 LIME Python 包可以很容易地获得这些本地解释。但是,如果我们想了解模型作为一个整体是如何工作的,那么它是缺乏的。我们将向您展示如何解决此问题以创建 LIME 权重的全局聚合。
我们将引导您完成为多个预测收集 LIME 权重的过程。然后,我们将向您展示如何以 3 种方式汇总这些数据。那就是查看特征趋势、绝对平均权重和蜂群图。最后,我们还将向您展示如何“指挥” SHAP 包。我们将使用它的内置函数来可视化我们的 LIME 权重。我们将讨论关键代码片段,您可以在 GitHub 上找到完整的项目。[0]
Dataset
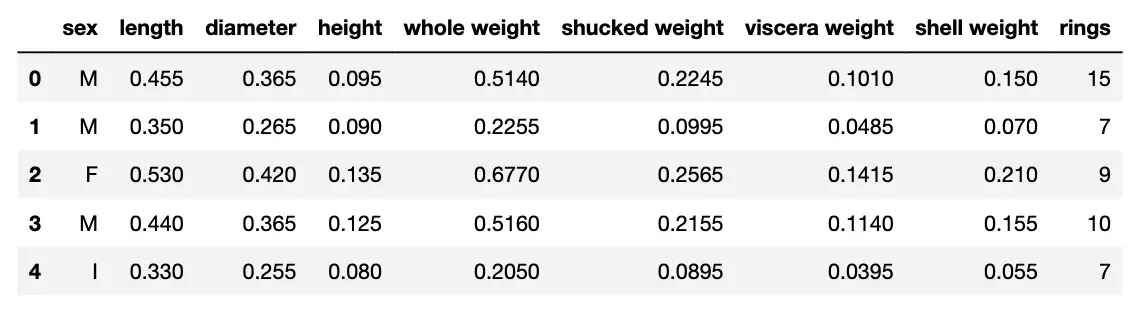
我们将使用鲍鱼数据集构建模型。您可以在表 1 中看到该数据集的快照。鲍鱼是一种贝类。鲍鱼壳上的环数大致相当于它的年龄。目标是预测环的数量。我们使用剩余的特征来做到这一点,例如壳长、壳直径和鲍鱼的总重量。[0]
Packages
在我们分析这些数据之前,我们需要导入一些 Python 包。我们有一些用于管理和可视化数据的标准库(第 2-4 行)。我们导入用于建模目标变量的 XGBoost(第 7 行)。当我们处理表格数据时,我们导入 LimeTabularExplainer 函数(第 9 行)。最后,我们导入我们将在最后使用的 SHAP 包(第 10 行)。确保您已安装所有这些。
Modelling
在计算 LIME 权重之前,我们需要训练一个模型。我们首先在下面的代码中导入我们的数据集(第 2-4 行)。我们得到 y,我们的目标变量,(第 7 行)和 X 特征矩阵(第 8 行)。性别是一个分类特征,因此,在我们可以在模型中使用它之前,我们需要将其转换为 3 个虚拟变量(第 11-13 行)。最后,我们从特征矩阵中删除原始的性别特征(第 16 行)。
在下面的代码中,我们训练了一个模型来预测鲍鱼壳中的环数(第 2-4 行)。我们的目标变量是连续的,所以我们使用 XGBoost 回归。然后我们得到模型对整个特征集的预测(第 7 行)。
我们可以使用图 1 中的散点图来帮助评估这个模型。在这里,我们可以看到模型的预测环数与实际环数的比较。我们忽略了一些最佳实践,但该模型应该足以展示 LIME 包。
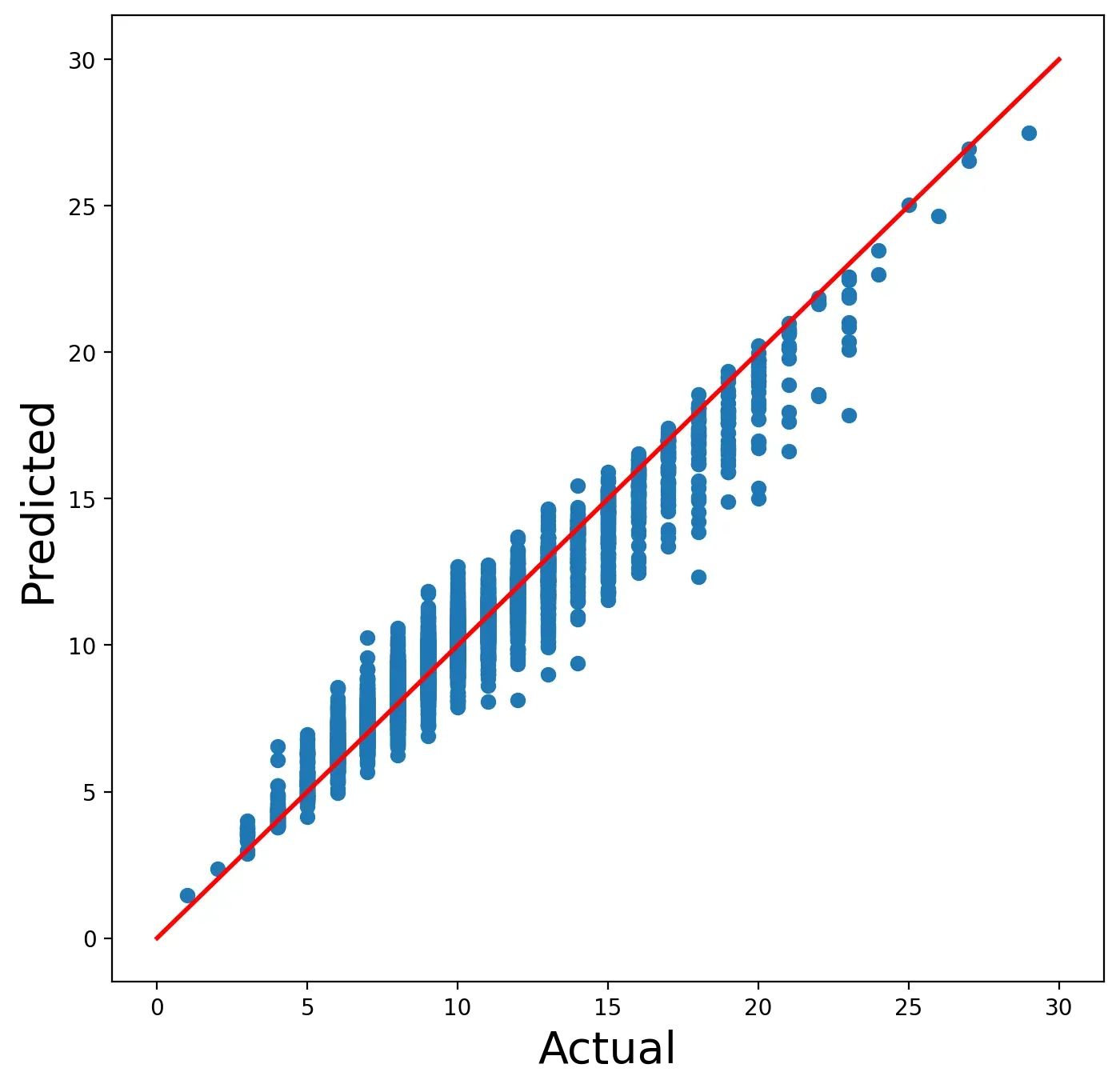
在我们继续使用 LIME 之前,您可以用自己的模型替换此模型。或者您可以尝试不同的模型功能。这是因为 LIME 是一种与模型无关的方法。这意味着它可以与任何模型一起使用。这也使得调整其余代码为您的应用程序运行变得容易。[0]
Local explanations
让我们深入了解 LIME 本地解释。在图 2 中,您可以看到第一个预测的解释。这是我们数据集中第一只鲍鱼的预测环数。查看左侧的图表可以告诉我们每个特征如何对预测做出贡献。例如,对于这只鲍鱼,整体重量的值减少了预测的环数。精确值 -1.68 是整个重量的 LIME 重量。
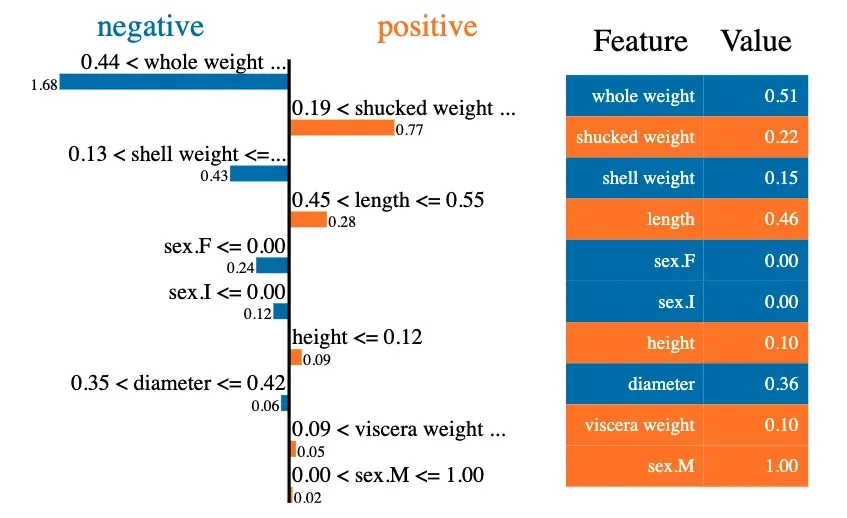
我们使用下面的代码来创建这个本地解释。我们假设你对 LIME 包有点熟悉,所以我们不会详细解释代码。为了给出一个概述,我们首先创建一个 LIME 解释器(第 2-6 行)。然后我们使用这个解释器为我们的第一个预测创建一个解释器对象 exp(第 9-12 行)。最后,我们显示这个解释器对象(第 15 行)。其输出如图 2 所示。
# Create the explainer
explainer = LimeTabularExplainer(X.values,
feature_names=X.columns,
class_names=['rings'],
verbose=True,
mode='regression')
# Get explanation for first row
exp = explainer.explain_instance(X.iloc[0],
model.predict,
num_features=10,
labels=X.columns)
#Display explanation
exp.show_in_notebook(show_table=True,show_predicted_value=False)Global aggregations
当您想了解如何做出个别预测时,本地解释非常有用。然而,看一个单一的预测并不能告诉我们这个模型是如何工作的。为此,我们可以使用不同的局部解释聚合。也就是说,我们将使用不同的图表组合许多预测的 LIME 权重。
首先,我们需要从解释器对象中获取 LIME 权重。为此,我们可以使用下面的函数 return_weights。这个函数接受一个解释器对象,exp。从这个对象中,它将获取并返回一个 LIME 权重列表 exp_weight。这些权重将按照与 X 特征矩阵中的特征相同的顺序进行排序。
def return_weights(exp):
"""Get weights from LIME explanation object"""
exp_list = exp.as_map()[1]
exp_list = sorted(exp_list, key=lambda x: x[0])
exp_weight = [x[1] for x in exp_list]
return exp_weight要使用此函数,我们将遍历 X 特征矩阵中的前 100 行(第 4 行)。对于每次迭代,我们将创建一个解释对象(第 7-10 行)。我们使用 return_weights 函数(第 13 行)从该对象获取权重,并将它们附加到权重列表(第 14 行)。最后,我们使用这个权重列表(第 17 行)创建 DataFrame,lime_weights。
weights = []
#Iterate over first 100 rows in feature matrix
for x in X.values[0:100]:
#Get explanation
exp = explainer.explain_instance(x,
model.predict,
num_features=10,
labels=X.columns)
#Get weights
exp_weight = return_weights(exp)
weights.append(exp_weight)
#Create DataFrame
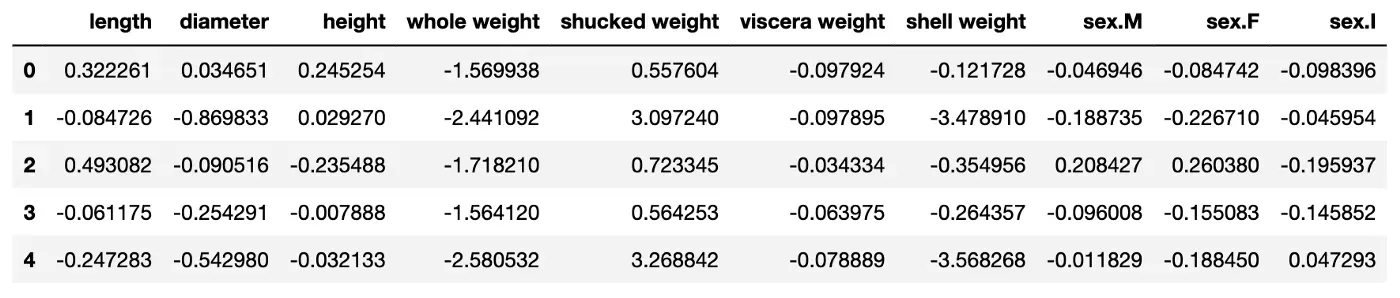
lime_weights = pd.DataFrame(data=weights,columns=X.columns)您可以在表 2 中看到此过程的结果。这里我们看到了lime_weights DataFrame 的快照。该数据集共有 100 行。每行代表一个不同的预测。对于每个预测,每个特征都有一个 LIME 权重。我们现在可以使用这个数据集来创建 LIME 权重的全局聚合。如果您愿意,您可以调整代码以运行超过 100 行。
Feature trends
我们的第一个聚合着眼于模型特征之一的趋势——整体重量。这是整个鲍鱼的重量。在图 3 中,我们可以看到随着整体重量的增加,LIME 的重量增加。较高的 LIME 权重表明,对于特定的预测,特征值增加了预测的环数。因此,这张图表告诉我们,随着鲍鱼重量的增加,其壳中的环数往往会增加。这是有道理的,因为我们预计老鲍鱼会更大/更重。

要创建此图表,我们首先获取整个权重特征的 LIME 权重(第 4 行)。我们还得到了相应的特征值(第 5 行)。然后我们创建权重和特征值的散点图(第 7 行)。
fig, ax = plt.subplots(nrows=1, ncols=1,figsize=(8,8))
#Get weights and feature values
feature_weigth = lime_weights['whole weight']
feature_value = X['whole weight'][0:100]
plt.scatter(x=feature_value ,y=feature_weigth)
plt.ylabel('LIME Weight',size=20)
plt.xlabel('whole weight',size=20)Mean LIME weight
接下来的聚合可以帮助我们了解哪些特征是最重要的。具有高正或负 LIME 权重的特征对预测的影响更大。对于每个特征,我们可以取所有 LIME 权重的绝对平均值。通常,具有较大平均权重的特征对预测做出了很大贡献。
我们可以在图 4 中看到我们模型的平均权重。请注意,与其他特征相比,整重、壳重和去壳重的平均权重更大。这告诉我们,在预测环数时,这些特征是最重要的。
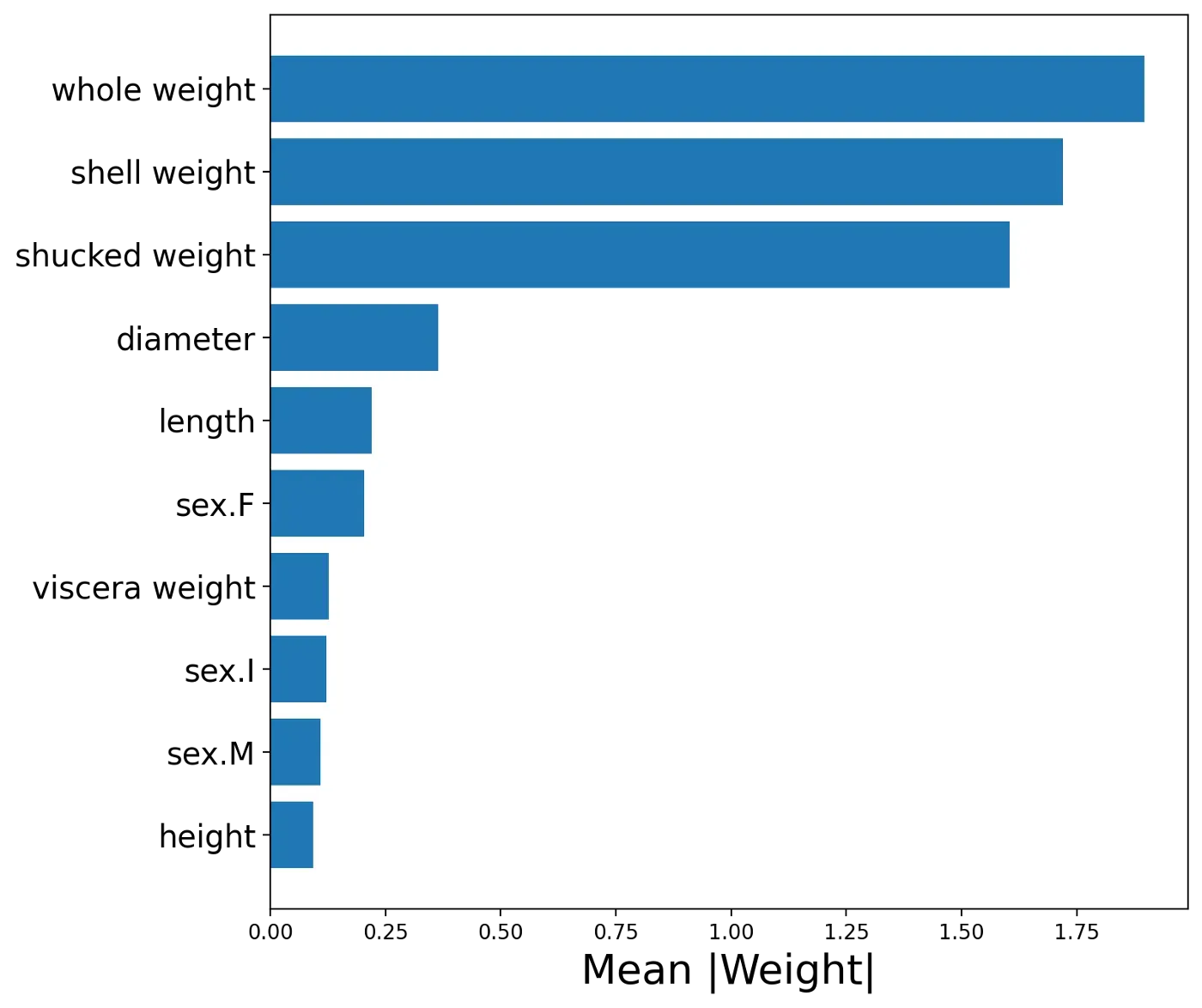
要创建此图表,我们首先获取权重的绝对平均值(第 2 行)。然后,我们创建一个包含两列的新 DataFrame——特征名称和绝对平均值(第 3 行)。我们按从最大到最小的平均权重排序这个 DataFrame(第 4 行)。然后我们只需要使用这个 DataFrame 绘制一个条形图(第 9-11 行)。
#Get abs mean of LIME weights
abs_mean = lime_weights.abs().mean(axis=0)
abs_mean = pd.DataFrame(data={'feature':abs_mean.index, 'abs_mean':abs_mean})
abs_mean = abs_mean.sort_values('abs_mean')
#Plot abs mean
fig, ax = plt.subplots(nrows=1, ncols=1,figsize=(8,8))
y_ticks = range(len(abs_mean))
y_labels = abs_mean.feature
plt.barh(y=y_ticks,width=abs_mean.abs_mean)
plt.yticks(ticks=y_ticks,labels=y_labels,size= 15)
plt.title('')
plt.ylabel('')
plt.xlabel('Mean |Weight|',size=20)Beeswarm
我们最终的聚合是一个蜂群图。如图 5 所示,这是所有 LIME 权重的图。这些值按 y 轴上的特征分组。对于每一组,点的颜色由相同特征的值决定(即更高的特征值是红色的)。这些特征按平均 LIME 权重排序。换句话说,与图 4 的顺序相同。
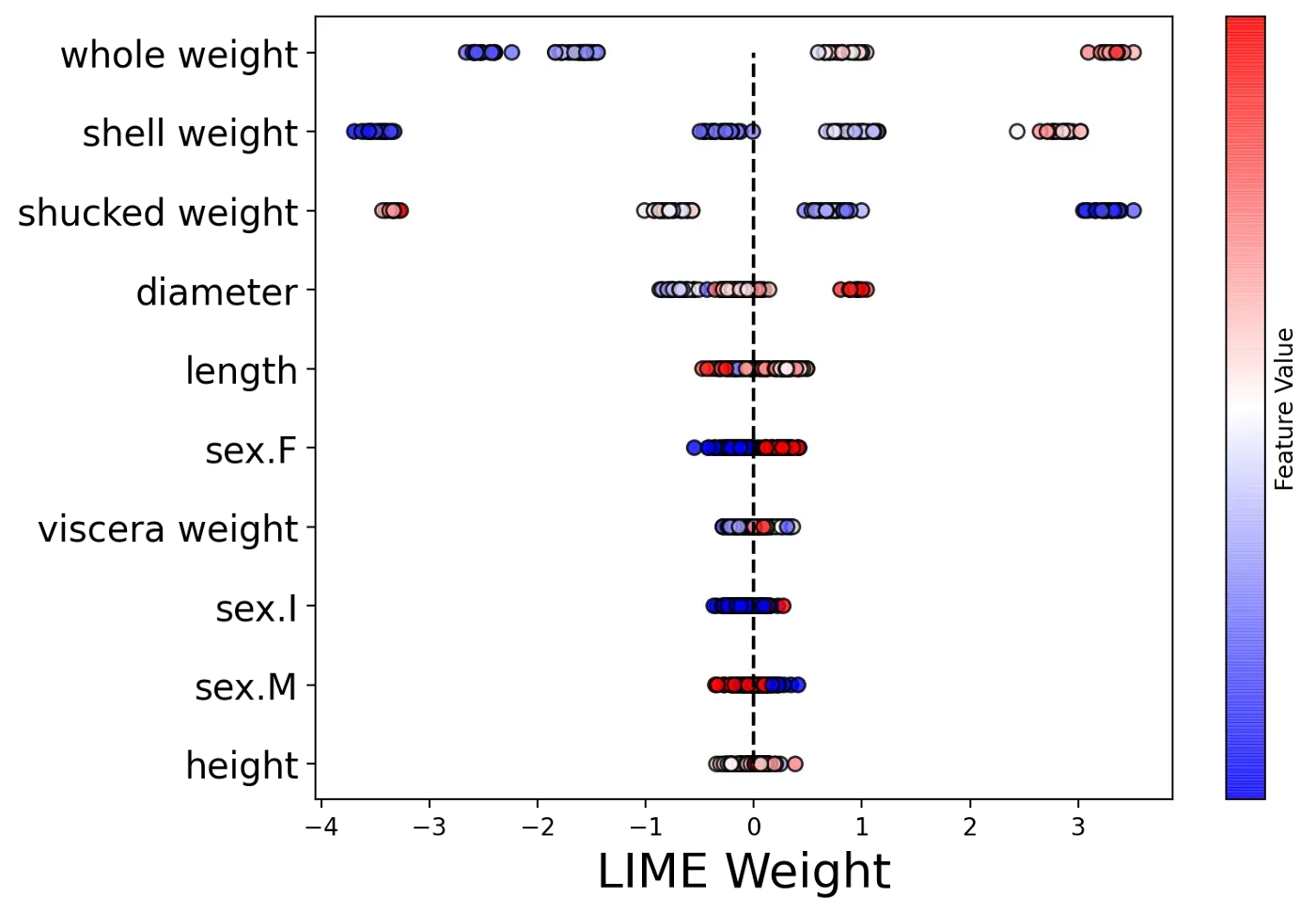
为了创建这个图表,我们使用下面的代码。为了给出一个概述,我们迭代了每个特征(第 8 行)。对于每个特征,我们得到权重和值(第 10-11 行)。使用这些,我们然后创建一个散点图(第 13-18 行)。诀窍是将每个点的 y 值设置为相同的值(第 14 行)。这就是我们如何在一条直线上获得每个散点图。
fig, ax = plt.subplots(nrows=1, ncols=1,figsize=(8,6))
#Use same order as mean plot
y_ticks = range(len(abs_mean))
y_labels = abs_mean.feature
#plot scatterplot for each feature
for i,feature in enumerate(y_labels):
feature_weigth = lime_weights[feature]
feature_value = X[feature][0:100]
plt.scatter(x=feature_weigth ,
y=[i]*len(feature_weigth),
c=feature_value,
cmap='bwr',
edgecolors='black',
alpha=0.8)
plt.vlines(x=0,ymin=0,ymax=9,colors='black',linestyles="--")
plt.colorbar(label='Feature Value',ticks=[])
plt.yticks(ticks=y_ticks,labels=y_labels,size=15)
plt.xlabel('LIME Weight',size=20)如果你熟悉 SHAP 包,你就会认出这个 beeswarm 图。它是包提供的内置可视化之一。上面的可视化远没有 SHAP 创建的那样令人愉悦。因此,在下一节中,我们将向您展示如何使用 SHAP 包来绘制 LIME 权重。
使用 SHAP 包
首先,我们计算特征矩阵中前 100 个观测值的 SHAP 值(第 2-3 行)。然后我们创建 shap_placeholder 对象(第 6 行)。这最初将包含 SHAP 值。然后,我们只需将 SHAP 值替换为 LIME 权重(第 7 行)。
#Get SHAP values
explainer = shap.Explainer(model)
shap_values = explainer(X[0:100])
#Replace SHAP values with LIME weights
shap_placeholder = explainer(X[0:100])
shap_placeholder.values = np.array(lime_weights)在下面的代码中,我们使用原始 SHAP 值创建了一个蜂群图。在这种情况下,我们传递 shap_values 对象。您可以在图 6 中看到此结果。
#Beeswarm plot using SHAP values
shap.plots.beeswarm(shap_values,show=False)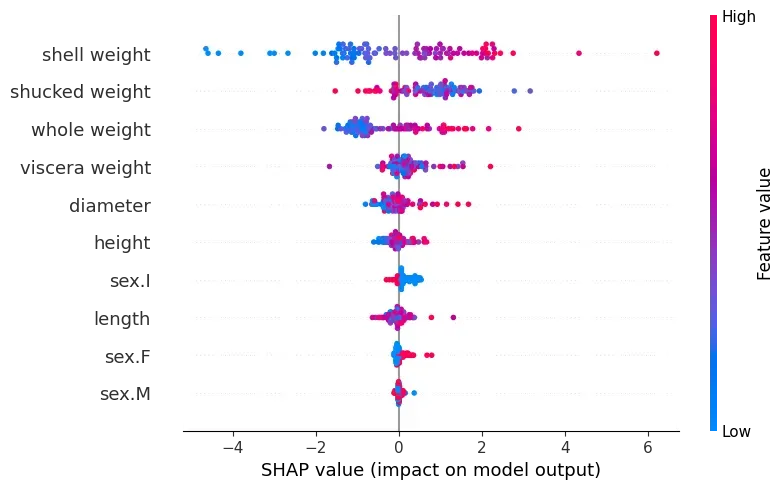
我们可以使用该函数创建 LIME 权重的蜂群图。唯一的区别是我们传递 shap_placeholder 对象而不是 SHAP 值。您可以在图 7 中看到此结果。请注意,此图表与我们在图 5 中创建的图表非常相似。除了我们避免自己编写代码,结果更令人赏心悦目。
#Beeswarm plot using LIME values
shap.plots.beeswarm(shap_placeholder, show=False)
plt.xlabel('LIME value')
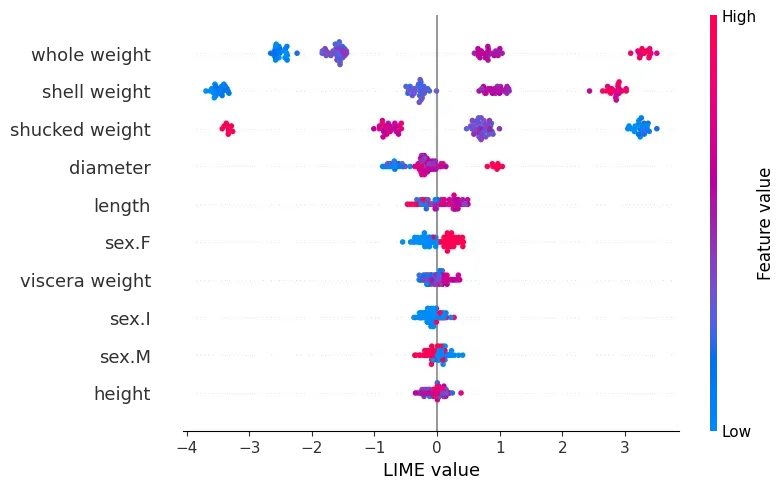
上面的图表还允许我们比较 LIME 权重和 SHAP 值。这可以帮助我们理解两种局部解释方法之间的区别。例如,请注意图 7 中一些 LIME 权重是如何聚集在一起的。这来自 LIME 权重的计算方式。该过程涉及将连续特征分为 4 组。
蜂群图只是 SHAP 包中的可视化之一。我们还可以使用其他一些来可视化 LIME 权重。在下面的文章中,我们将探讨这些图。我们给出了 Python 代码,并详细介绍了如何解释每个图表。
我希望你觉得这篇文章有帮助!如果你想看到更多,你可以成为我推荐的成员之一来支持我。您将可以访问媒体上的所有文章,我将获得您的部分费用。[0]
Dataset
W. J 纳什等。 al.,1994,鲍鱼数据集,加利福尼亚州欧文市:加利福尼亚大学信息与计算机科学学院(许可证:CC0:公共领域),https://archive.ics.uci.edu/ml/datasets/Abalone[0]
References
Ribeiro, M.T.、Singh, S. 和 Guestrin, C.,2016 年“我为什么要相信你?”解释任何分类器的预测。 https://arxiv.org/abs/1602.04938[0]
C. Molnar,可解释的机器学习,2021 https://christophm.github.io/interpretable-ml-book/lime.html[0]
LIME Python 包,https://github.com/marcotcr/lime[0]
SHAP Python 包,https://github.com/slundberg/shap[0]
文章出处登录后可见!