虽然很多时候一些模块内置的数据集使用起来非常的方便,搭建模型,做实例项目非常快,但是这种形式的数据建模本质上并不通用,我们使用模型大多是要解决现实生活中的很多实际问题,在不同的应用场景和业务问题中都会遇上各式各样的数据集,没有办法像那些使用起来很方便的内置数据集一样直接导入使用,这时候我们就要把问题的处理过程抽象成一个标准的数据流程,抽象出来标准流程的好处就是,之后任何问题我们都可以将其朝着标准流程的形式进行转化,从而讲一个复杂的问题标准化,就像很多时候搭建模型一样,明确需要定义的部分就是输入层的shape,跟这里标准数据流程是一个性质的。
背景闲话就说这些,接下来回到正题,本文主要的内容是将经典的手写数字识别数据集转化为标准的图像进行存储,之后建模的数据加载会选择从本地加载图像数据的形式进行实施,这里主要是为了数据流程的标准化,本质上你不需要转化也可以直接使用emnist数据集,远比加载图像要快得多。
本文是内置mnist数据转化解析存储系列的第三篇文章,前面两篇分别是:
《Python实现将scikit-learn内置的mnist数据集转化为图像进行存储》
《Python实现将tensorflow内置的二进制格式的mnist数据集转化为图像进行存储》
《Python实现将Keras内置的mnist数据集转化为图像进行存储》
有需要的话可以自行查看。
相比于大名鼎鼎的手写数字识别数据集mnist而言,手写字母数据集emnist就显得逊色了很多了,很多人甚至都没有听过这个,我最开始的时候也是没有怎么听说过的,查询了一下才知道sciki-learn也内置了emnist数据,详情如下所示:
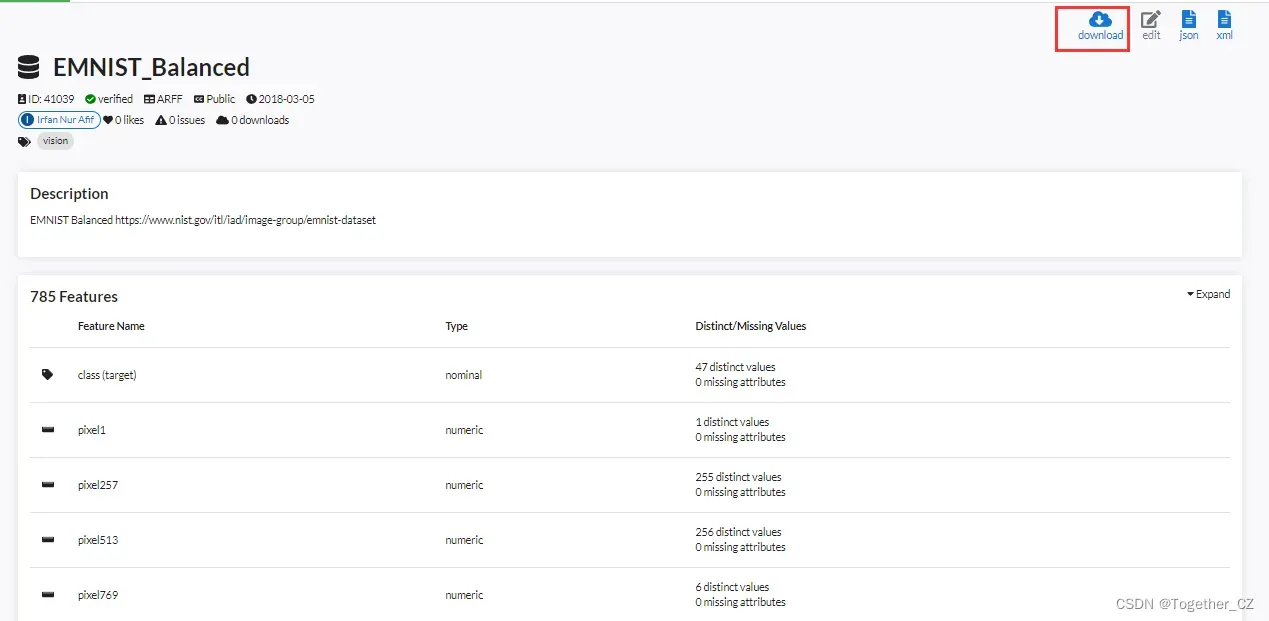
该数据集对应的描述信息如下:
{
"data_set_description": {
"id": "41039",
"name": "EMNIST_Balanced",
"version": "1",
"description": "EMNIST Balanced https://www.nist.gov/itl/iad/image-group/emnist-dataset",
"description_version": "1",
"format": "ARFF",
"upload_date": "2018-03-05T10:29:25",
"licence": "Public",
"url": "https://old.openml.org/data/v1/download/18660482/EMNIST_Balanced.arff",
"file_id": "18660482",
"default_target_attribute": "class",
"tag": "vision",
"visibility": "public",
"minio_url": "http://openml1.win.tue.nl/dataset41039/dataset_41039.pq",
"status": "active",
"processing_date": "2021-01-15 23:15:12",
"md5_checksum": "c496b0d4549c78c52da1e8c67abdbc80"
}
}下载到本地可以看到如下:
有243MB的大小,本文并不是要基于sklearn内置的emnist数据集来进行图像的转储处理,而是基于论文中给出来的mat格式的数据集来进行转储处理,整体代码实现如下所示:
#!usr/bin/env python
# encoding:utf-8
from __future__ import division
"""
功能: emnist 手写字母数据集转化
"""
import os
import cv2
import json
import pickle
import numpy as np
from PIL import Image
from scipy.io import loadmat
def reshape(img, width, height):
"""
塑形
"""
img = np.array(img).reshape(width, height)
return img
def parseData2Img(data="emnist-letters", width=28, height=28, resDir="emnist-dataset/"):
"""
mat文件解析为图像文件
"""
mat = loadmat(data)
mapping = {kv[0] - 1: kv[1:][0] for kv in mat["dataset"][0][0][2]}
print("mapping: ", mapping)
pickle.dump(mapping, open("bin/mapping.p", "wb"))
# 解析训练集
max_ = len(mat["dataset"][0][0][0][0][0][0])
training_images = mat["dataset"][0][0][0][0][0][0][:max_]
training_labels = mat["dataset"][0][0][0][0][0][1][:max_]
trainDir = resDir + "train/"
print("training_images_nums: ", len(training_images))
for i in range(len(training_images)):
one_train_data = reshape(training_images[i], width, height)
print("one_train_data_shape: ", one_train_data.shape)
one_train_img = Image.fromarray(np.array(one_train_data))
one_train_label = str(training_labels[i][0])
print("one_train_label: ", one_train_label)
oneDir = trainDir + one_train_label + "/"
if not os.path.exists(oneDir):
os.makedirs(oneDir)
one_path = (
oneDir + one_train_label + "_" + str(len(os.listdir(oneDir)) + 1) + ".jpg"
)
one_train_img.save(one_path)
# 解析测试集
testDir = resDir + "test/"
max_ = len(mat["dataset"][0][0][1][0][0][0])
testing_images = mat["dataset"][0][0][1][0][0][0][:max_]
testing_labels = mat["dataset"][0][0][1][0][0][1][:max_]
print("testing_images_nums: ", len(testing_images))
for i in range(len(testing_images)):
one_test_data = reshape(testing_images[i], width, height)
print("one_test_data_shape: ", one_test_data.shape)
one_test_img = Image.fromarray(np.array(one_test_data))
one_test_label = str(testing_labels[i][0])
print("one_test_label: ", one_test_label)
oneDir = testDir + one_test_label + "/"
if not os.path.exists(oneDir):
os.makedirs(oneDir)
one_path = (
oneDir + one_test_label + "_" + str(len(os.listdir(oneDir)) + 1) + ".jpg"
)
one_test_img.save(one_path)
if __name__ == "__main__":
print(
"=========================================Loading emnist mat2Img==========================================="
)
label_map_dict={}
for i in range(26):
one_char=chr(65+i)
label_map_dict[i+1]=one_char
print(label_map_dict)
with open("label_map_dict.json", "w") as f:
f.write(json.dumps(label_map_dict))
parseData2Img(data="emnist", width=28, height=28, resDir="emnist-dataset/")
执行会先创建标签映射字典,如下:
{
"1": "A",
"2": "B",
"3": "C",
"4": "D",
"5": "E",
"6": "F",
"7": "G",
"8": "H",
"9": "I",
"10": "J",
"11": "K",
"12": "L",
"13": "M",
"14": "N",
"15": "O",
"16": "P",
"17": "Q",
"18": "R",
"19": "S",
"20": "T",
"21": "U",
"22": "V",
"23": "W",
"24": "X",
"25": "Y",
"26": "Z"
}运行结束后会自动生成26个子目录,如下所示:
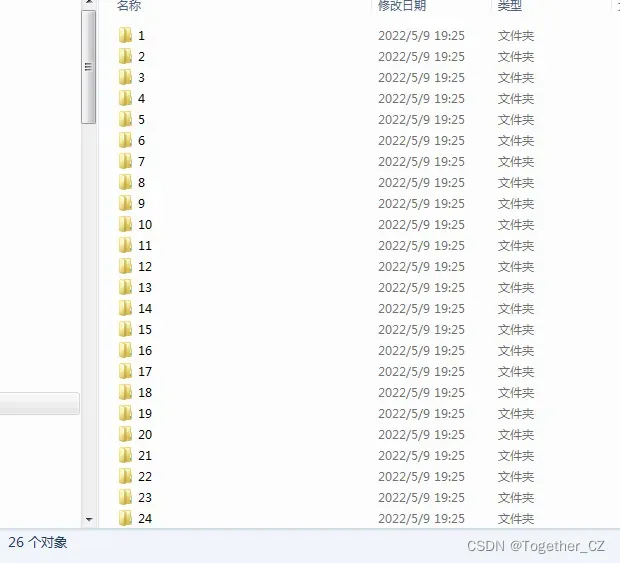
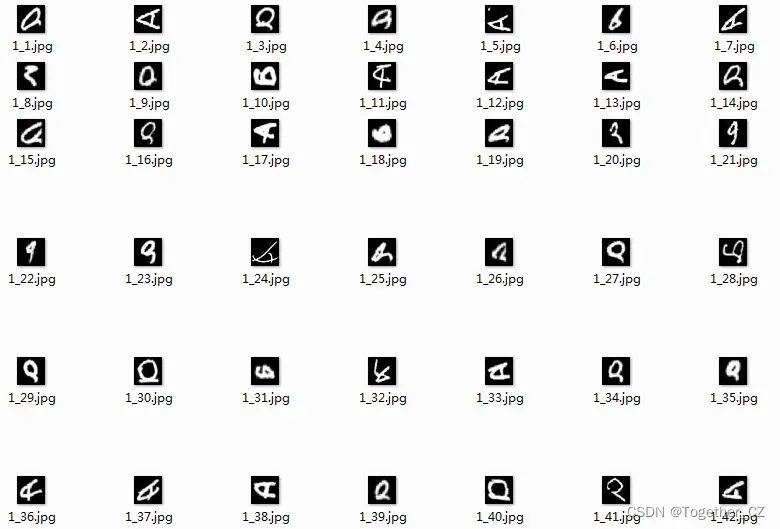
随机看几个样例如下所示:
【A】
【I】
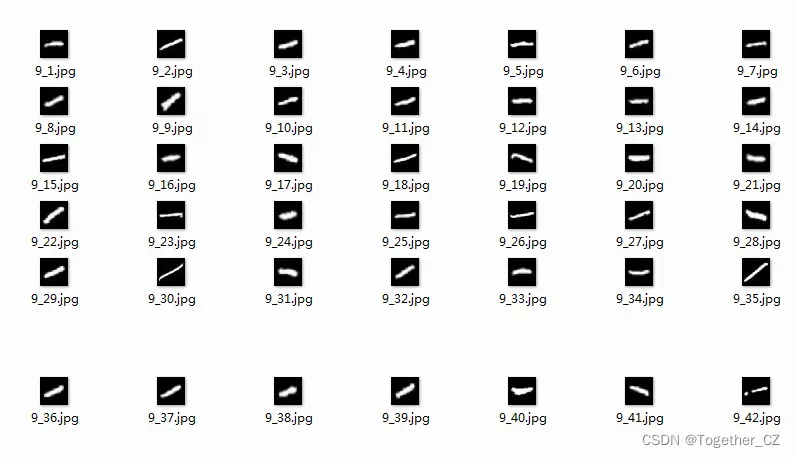
【P】
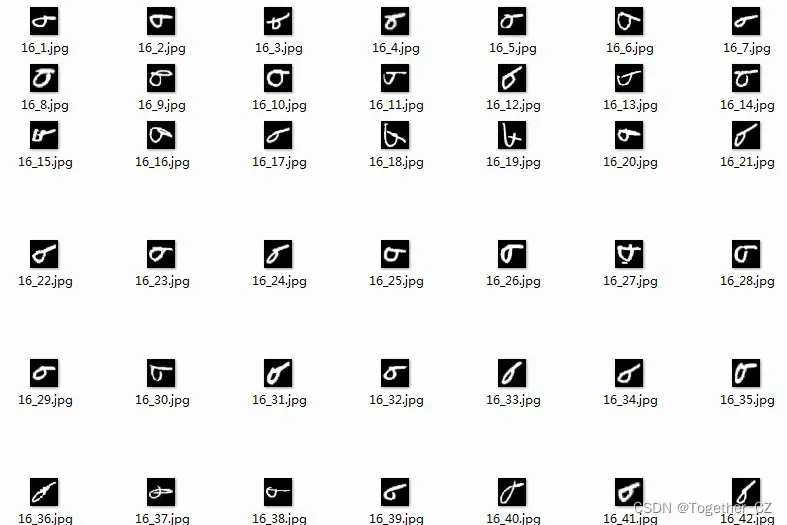
【X】
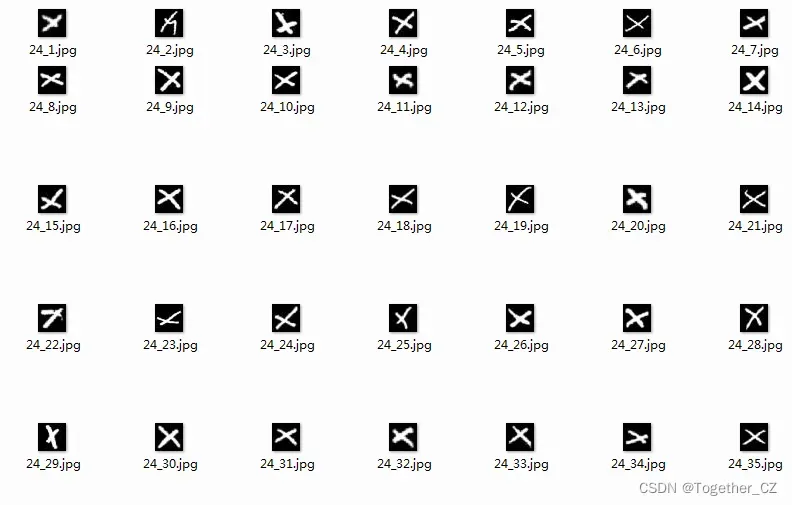
【Z】
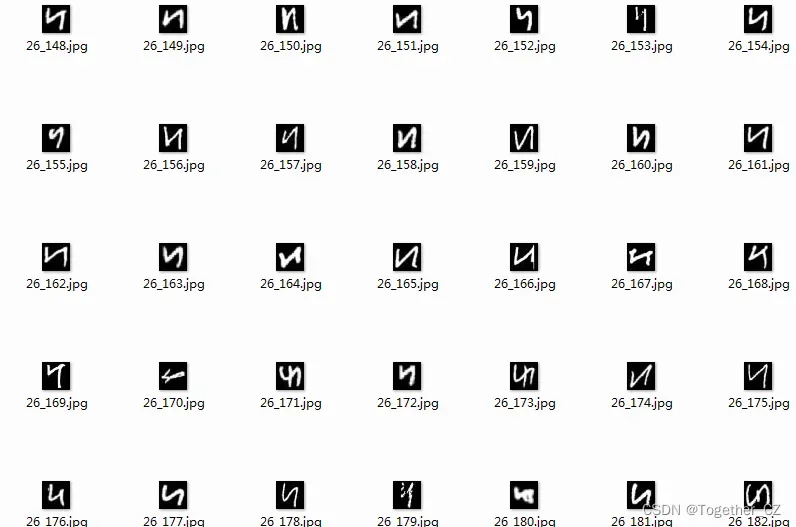
感兴趣的话可以自己试试。
文章出处登录后可见!