

人类向机器学习:第 1 部分
维度的诅咒;更多并不总是更好
人工智能和机器学习概念的哲学启示


在我作为一名人工智能从业者的这些年里,我观察到我们教给机器的人工智能中的几个概念也可以应用到生活中,以改善我们的幸福感和生产力。人类从机器学习是一个系列,我试图介绍人工智能中一些有趣的概念,并讨论它们在我们生活中的哲学意义。我将尝试尽可能简单地解释技术概念,以便所有技术水平的读者都能阅读和理解它们。
在一个机器越来越聪明,人类越来越懒惰的世界里,让我们从人类教给机器的东西中吸取一些教训,并将它们应用到我们的生活中!因为最终,人工智能和编程它的人类一样好!
从史蒂夫乔布斯的我最喜欢的一句话开始;[0]
每个人都应该学习编程计算机,因为它教你如何思考
– Steve Jobs
PS:我在之前的一篇文章中使用了相同的引用,10 条没有人会教你的编码原则。好吧,报价在这里也有效:P[0]
让我们开始吧!
1. 维度的诅咒

随着技术的出现,从 Alexa 到自动驾驶汽车,一切都由数据驱动技术推动。据 Statista 称,到 2025 年,生成的数据量预计将增长到 181 万亿 GB!!!这个数字呈指数级增长,以至于 90% 的总数据是在过去三年中创建的。直观地说,我们假设更多的数据意味着模型可以更好地学习,并且可以驱动更多的洞察力。好吧,越多越好,对吧?[0]
答案是……并非总是如此!
这通常被称为维度的诅咒!让我们看看更多数据如何影响计算负担、空间体积、可视化和参数估计方面的可学习性。[0]
1.1 计算负担和空间体积
考虑这种情况,您是一名园丁,想要在 100 米的线性花园中种植相距 1 米的玫瑰。很简单吧?种下 100 朵玫瑰,你就完成了。园艺太有趣了!这只是激情的问题……我喜欢它!开设了名为 Fun with Gardening 的 YouTube 频道,如何在没有任何背景的情况下进入园艺领域! :P
如果花园是一个每边100米的方形花园怎么办?在这种情况下,我们需要种植 100 x 100 朵玫瑰。复杂性刚刚乘以 100 倍。园艺是一项乏味的工作,但如果你充满激情且始终如一,那么你就可以做到! YouTube视频发布,如何通过坚持不懈地赢得生活! :P
100立方米的立方花园怎么样?在这种情况下,我们需要种植 100x100x100 的玫瑰。好吧,我突然对园艺失去了兴趣!不可能!一个名为“知道何时戒烟”的新视频!园艺生活课程发布,订阅者很失望:P
现在想象一下,如果园丁在上面花园的某个地方留下了一把铲子,他需要找到它。对于每个花园,他最多分别需要遍历 100 米、10000 米(10 KM)和 1000000 米(1000 KM 哇!!)。
因此,计算复杂度和空间体积随着维度的增加呈指数增长。我们将在接下来的部分讨论这一空间量的影响。
1.2 Visualisation & Parameter Estimation
我们可以可视化高达 4 维的数据

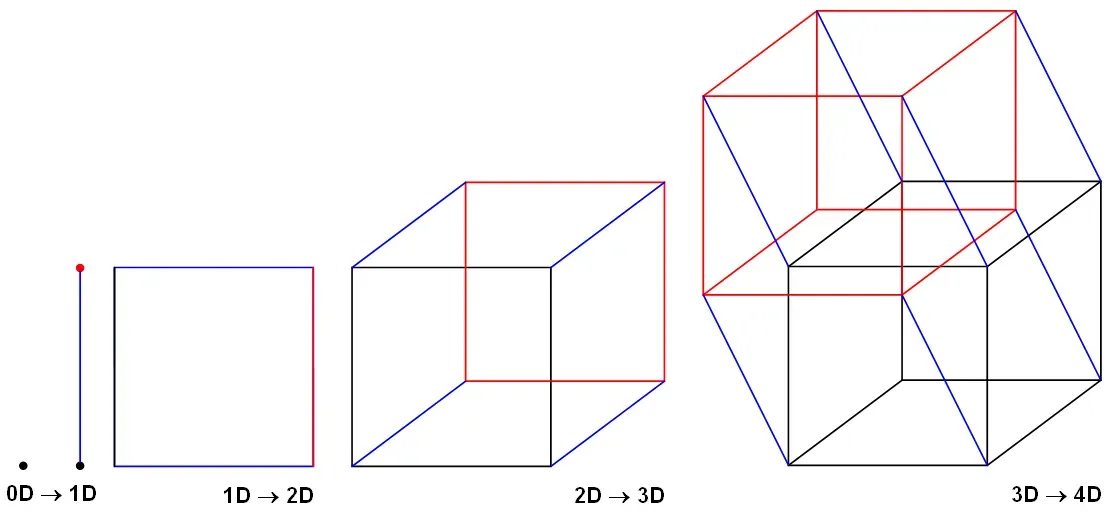
之后会发生什么?数学家甚至可以使用方程式轻松地表示无限维数据。关于切线,Bruno Joyal 在 MathExchange 中的一个有趣的回答说[0][1]
当有人说“高维空间很难想象”时,他们正在考虑用眼睛来想象。但是数学家用大脑来想象!
有史以来最伟大的数学家之一伦纳德·欧拉(Leonard Euler)在他生命的最后 17 年里一直失明。令人惊讶的是,他对世界的一半贡献是在他失明之后发生的。您可以在盲人数学家的世界中阅读类似的有趣故事。[0][1]
Micheal Simmons 有一篇关于在 4-Dimensions 中构建生命模型的非常有趣的文章,按 control/command 并单击此处稍后阅读,完成这篇文章后:P[0][1]
由于我们看不到更高维度的数据,我们尝试推断我们对高达 4D 数据的直觉。那么数据在高维中的表现如何呢?它与我们在 4 天之前所知道的相似吗?
我们的几何直觉在更高维度上失败了
让我们尝试通过考虑一个 d 维球体来理解这一点。


- 所以,根据我们人类的直觉,我们假设如果我们从较大的球体中移除稍小的球体,大部分信息都会丢失,对吧?因为理想情况下,我们将只留下较大球体的表层。让我们通过计算体积的相对差异来进行数学处理。

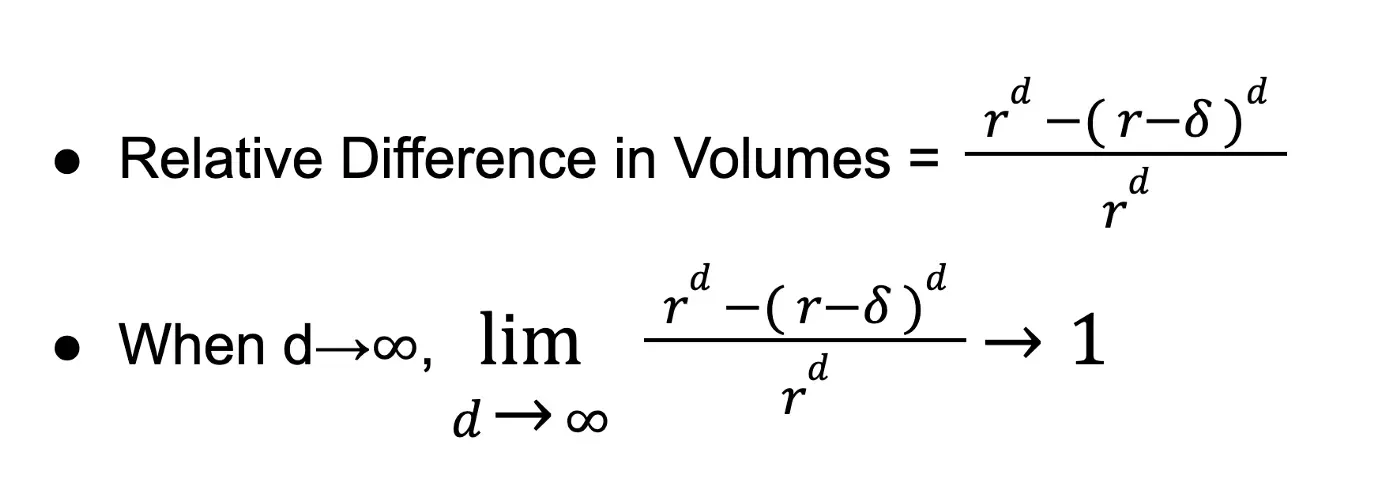
在 3D 中,如果我们假设一个半径为 3 个单位的球体,并且 𝛿 为 0.1,则体积的相对差异为 0.096。因此,当内部球体被移除时,超过 99% 的数据会丢失。而在更高维度中,比如说一个 100 维的球体,体积的相对差异为 0.966,当去除内部球体时,丢失的信息不到 1%。因此我们可以看到体积倾向于集中在更高维度的边缘周围。
1.3 Implications
高维数据的这种行为如何影响我们?
- 可用数据变得稀疏。表示数据所需的空间量呈指数增长,而密度随着维度的增加而降低。我们可以从 1.1 节的园艺比喻中推断出这一点。
- “最远”和“最近”对之间的相对差异
objects diminish.

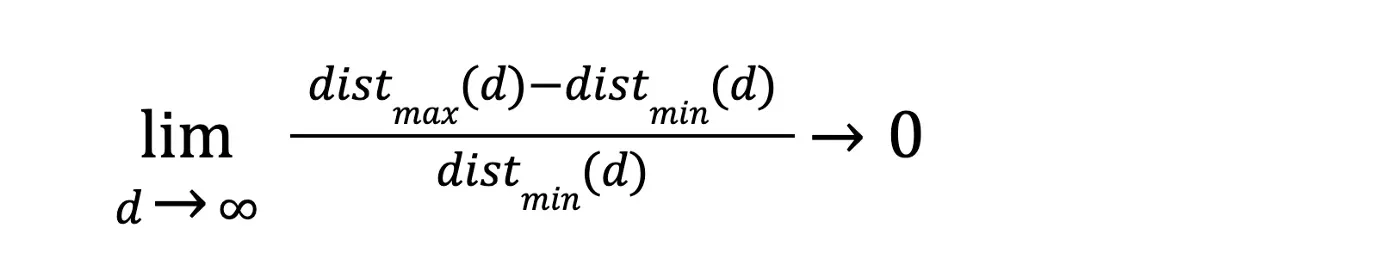
随着维度趋于无穷大,“近”或“远”等比较因素变得毫无意义。这直接影响所有基于相似性的算法,例如聚类。不可能根据它们的相对距离检测相似的数据点,因为它们被表示占据了如此巨大的空间,因此,这就像尝试进行 K 表示聚类,其中 K 等于特征向量的数量,每一行都将自己标识为一个新的集群,从而使信息变得无关紧要。
1.4 处理维度灾难
现在您可以看到拥有更高维数据的含义。更多并不总是更好。有时我们会被大量流入大脑的数据所淹没。无限可能性的存在使我们失去焦点,不知所措。看不完的电影/连续剧,无尽的卷轴,无尽的课程,无尽的职业选择,无尽的 youtube 视频……..选择的斗争是真实的!突然之间,我们都需要吃得好,通过比特币赚钱,担心股市,完成工作,花时间与家人在一起,锻炼,社交,做爱好……啊啊啊啊……头脑已经在飞翔了……这压倒性的信息本质上使我们的大脑疲倦,我们最终将无所事事。对生活的无限可能性的担忧困扰着我们,我们最终变得悲伤和沮丧。维度的诅咒也是生活中的诅咒。
思绪纷至沓来时,该如何整理?如何处理维度灾难?
答案是一样的。我们只是改变我们的观点,尝试从不同的角度看待事物。从新的角度来看,我们可以优先考虑哪些信息很重要,哪些只是噪音!这称为主成分分析,我们将在本系列的下一篇文章中讨论。改变你的观点,以了解这个信息过载世界的大局!
人类向机器学习:第 2 部分,从新视角观察的力量,主成分分析
下个月发售! (写得慢!为延误道歉:P)
非常感谢您花费宝贵的时间……希望我的观点对您有所帮助!请通过 LinkedIn 或电子邮件告诉我您的宝贵建议和反馈。[0][1]
致谢:维度诅咒的技术方面我从伯明翰大学计算机科学系的 Iain Styles 博士和 Kashif Rajpoot 博士的讲座中了解到。花点时间表达我对他们无价服务的感激之情! :D[0][1]
As always,
Happy Learning :D
文章出处登录后可见!