

手动随机森林和决策树——无需编码


Introduction
在本文中,我们将讨论决策树和随机森林,这是机器学习中用于分类和回归任务的两种算法。
我将展示如何使用笔和纸从头开始构建决策树,以及如何对其进行概括并构建随机森林模型。
Dataset
让我们看看它在实践中是如何使用一个简单的数据集进行的。

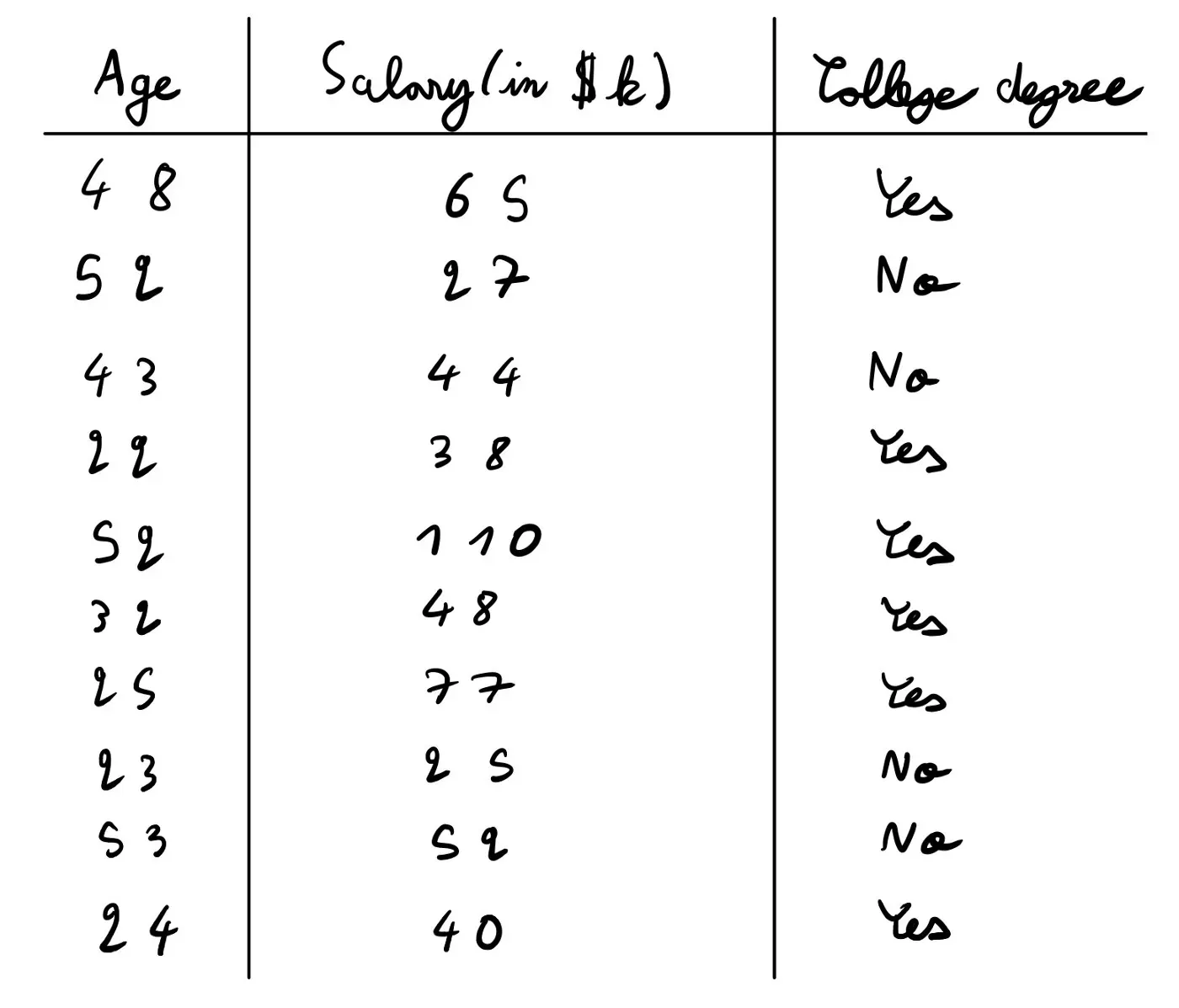
在这里,我们试图预测某人是否拥有大学学位。我们有 2 个数值变量,那个人的年龄和薪水(以千美元计)。
关于数据集的初步假设
当您查看新数据集时,我总是建议您提出一件事,即提出您对它的假设,看看它们是否正确。
我个人在这里有两个假设:
- 高薪的人更有可能拥有大学学位。我基于这样一个事实,即大量高薪职业(医学、法律、技术、咨询、金融等)需要大学学位。
- 与年长者相比,年轻人更有可能上大学。我基于皮尤研究中心的研究和个人经验(我经常听到我周围的老年人说他们觉得我这一代人上大学的次数比他们上大学的次数多得多——现在,我知道这是真的)。[0]
我很快计算了一些平均值,发现上大学的人在数据集中的平均年龄是 34 岁,而没有上过大学的人的平均年龄是 43 岁。关于工资,上过大学的人平均工资为 63K,而没有上过大学的人平均工资为 37K。因此,我们的两个假设都是正确的。
这样做不是强制性的,但它总是有用的,可以让你更好地理解你正在使用的数据集。
Decision Tree
现在,让我们看看如何在该数据集上训练决策树并进行预测。

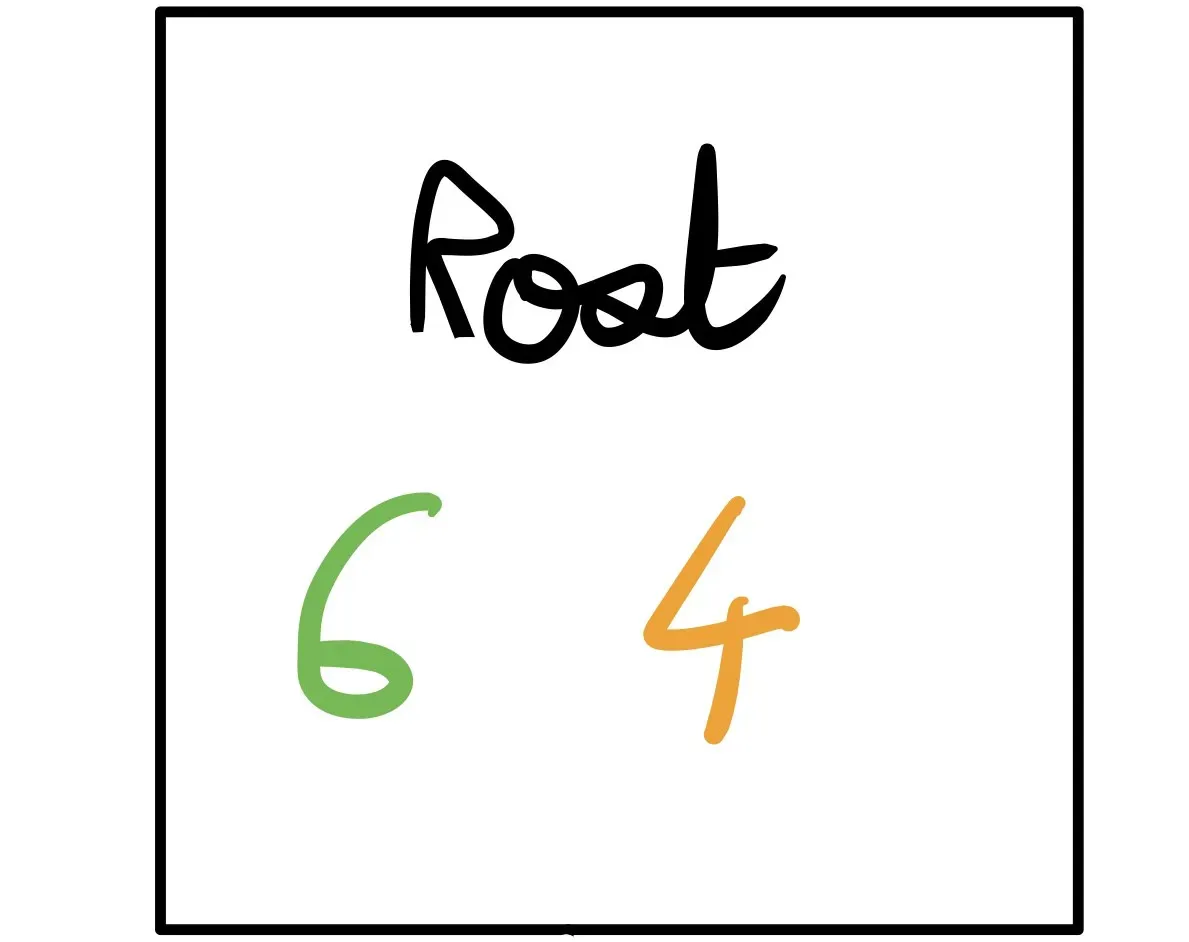
一开始,我们有 6 个 Yes 和 4 No. 这将成为我们的根节点。
在任何时候,我们总是可以访问真正的标签(即,我们总是知道整个决策树的例子是“是”还是“否”)。记住这一点,这对接下来的事情很重要。
在决策树的每个节点,我们可以预测其中一个类。在这里,我们可以预测是或否。
- 如果我们预测是,我们将正确分类我们拥有的 10 个数据点中的 6 个数据点并错误分类 4 个。因此,我们将有 4/10 =0.4 错误率。
- 如果我们预测否,我们将正确分类我们拥有的 10 个数据点中的 4 个数据点并错误分类 6 个。因此,我们将有 6/10 =0.6 的错误率。
因此,在这里,我们应该预测 Yes 以获得最低的错误率。
现在,让我们看看如何改进这一点。请记住,我们在这里仍然没有使用任何特征,只有数据集的真实标签。
Splits
现在的问题是我们如何使用我们的特征来改进我们的预测并做得比 0.4 更好。我们将为此使用一个阈值:如果某人的薪水高于 X,那么我们预测是。如果他们的薪水低于 X,我们预测为否。让我们看一个例子:

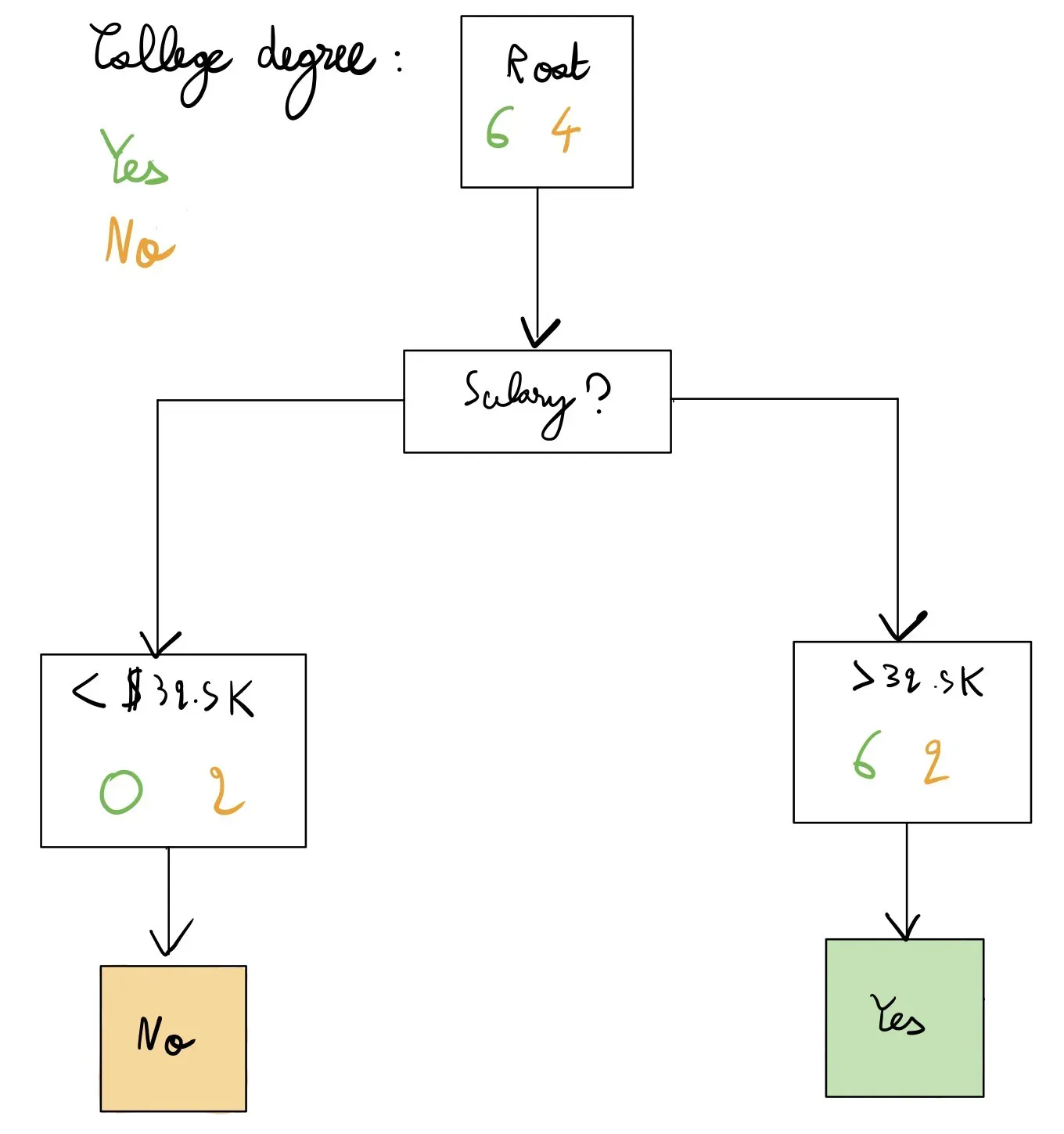
在这里,我们仍然有我们的根节点,但我们不是直接预测,而是首先在 Salary 上以 32.5K 的拆分值拆分(剧透:这是这里最好的拆分),然后进行预测——再次,我们有真实的标签.我们的错误率现在是 0.2(我们只错误分类了右侧方框中的两个黄色点,其中显示 6 | 2 – 我们预测的是那些,而我们应该预测的是否)。
所以,有两个问题:为什么我们决定先拆分薪水(而不是年龄或其他功能,如果我们有更多),为什么我们拆分为 32.5K 而不是其他值?
如何找到最佳阈值?


在这里,我将工资从小到大排序。为给定特征找到最佳阈值的想法如下:
- 对特征的值进行排序(如上)
- 取两点之间的中间值
- 像之前一样将其用作阈值并计算损失
- 对所有中间值(即所有拆分)执行此操作
- 为给定特征选择最佳分割
让我们看一个例子。

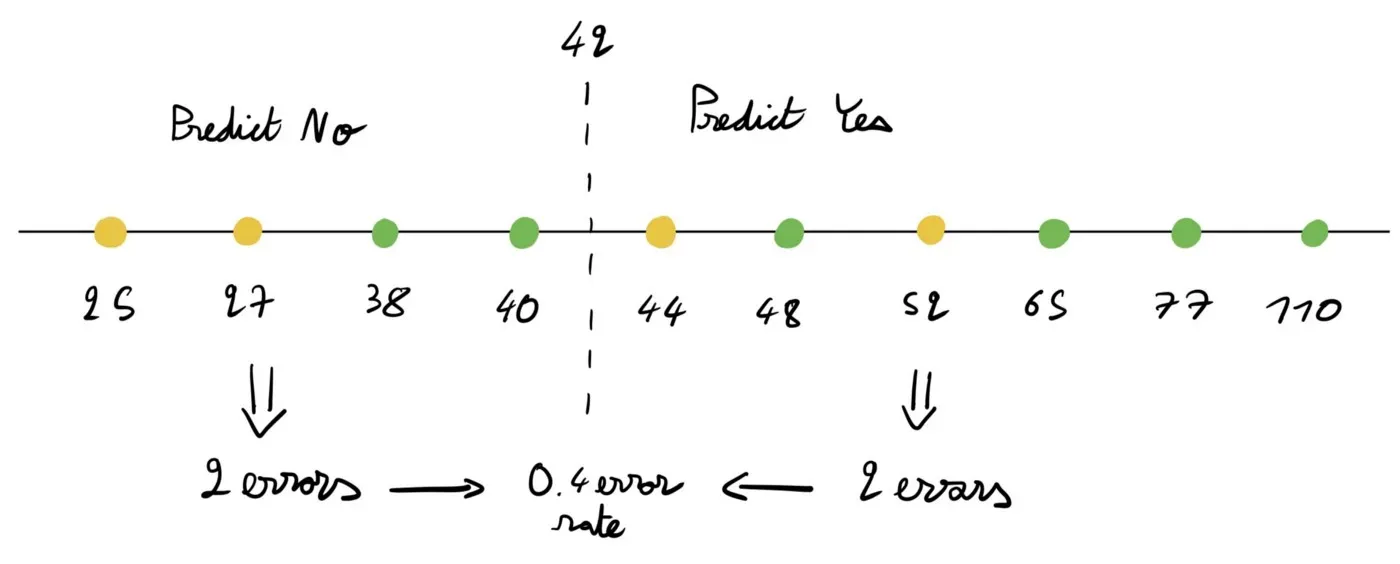
在这里,我们将 42 作为阈值,它是 40 和 44 之间的中间值。这将我们的数字列表分成两部分。
对于每个部分,我们可以预测是或否。
- 如果我们在左边预测 Yes 而在右边预测 No(与我们在图片上所做的相反),我们将有 6 个错误 = 0.6 错误率。
- 如果我们反过来做,如图所示,我们会得到 4 个错误 = 0.4 个错误率。
因此,我们在这里可以达到的最低错误率是 0.4(如图所示)。
现在的想法是计算所有可能拆分值的损失。让我们看看这是什么样子。


在这里,我们有所有可能的方式来分配薪水。我们看到 32.5K 是最好的分割值,因为它的错误率最低。
请记住,只要您在所拥有的两个值之间选择一个阈值,您是否在 42 或 42.005 上进行拆分并不重要。这就是我的意思:

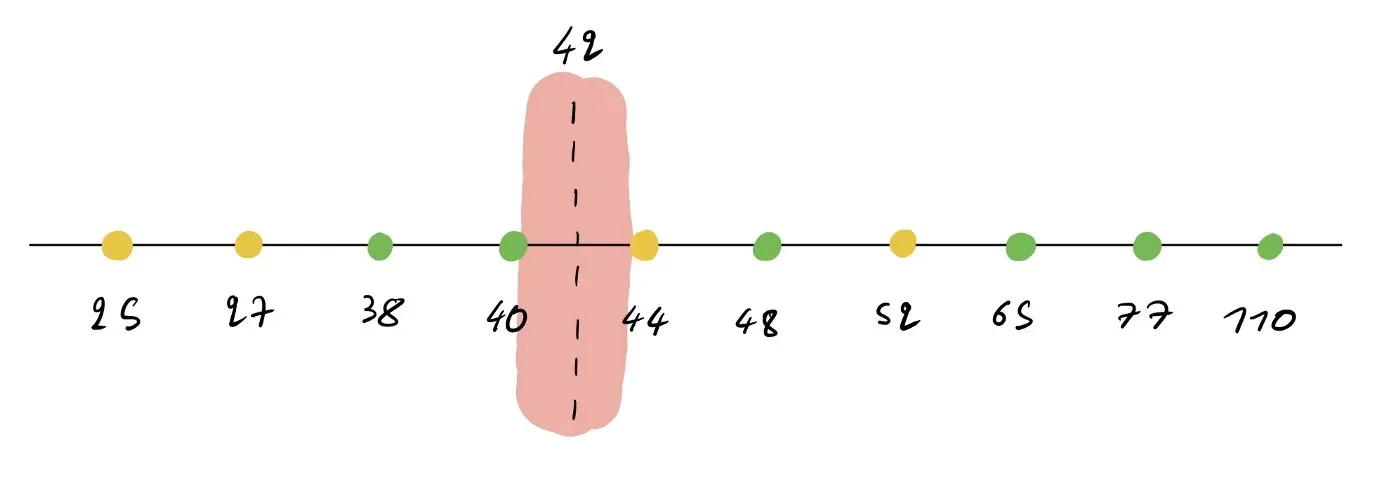
在这里,您可以选择红色区域中的任何值,只要它大于 40 且小于 44(因此 40.1 和 43.9 都有效)。原因是这些值仍然会得到相同的错误率。因此,您选择哪一个并不重要。我们只是选择中点作为约定。
决定拆分哪个变量
现在,我们知道,在我们可以按薪水分割的所有方式中,32.5K 的阈值是最好的分割方式。
现在,我们如何决定是否应该按年龄或薪水划分?简单的。像我们对 Salary 所做的那样计算 Age 的错误率,并从两者中选择最低的错误率并将其用作我们的拆分值。让我们这样做。

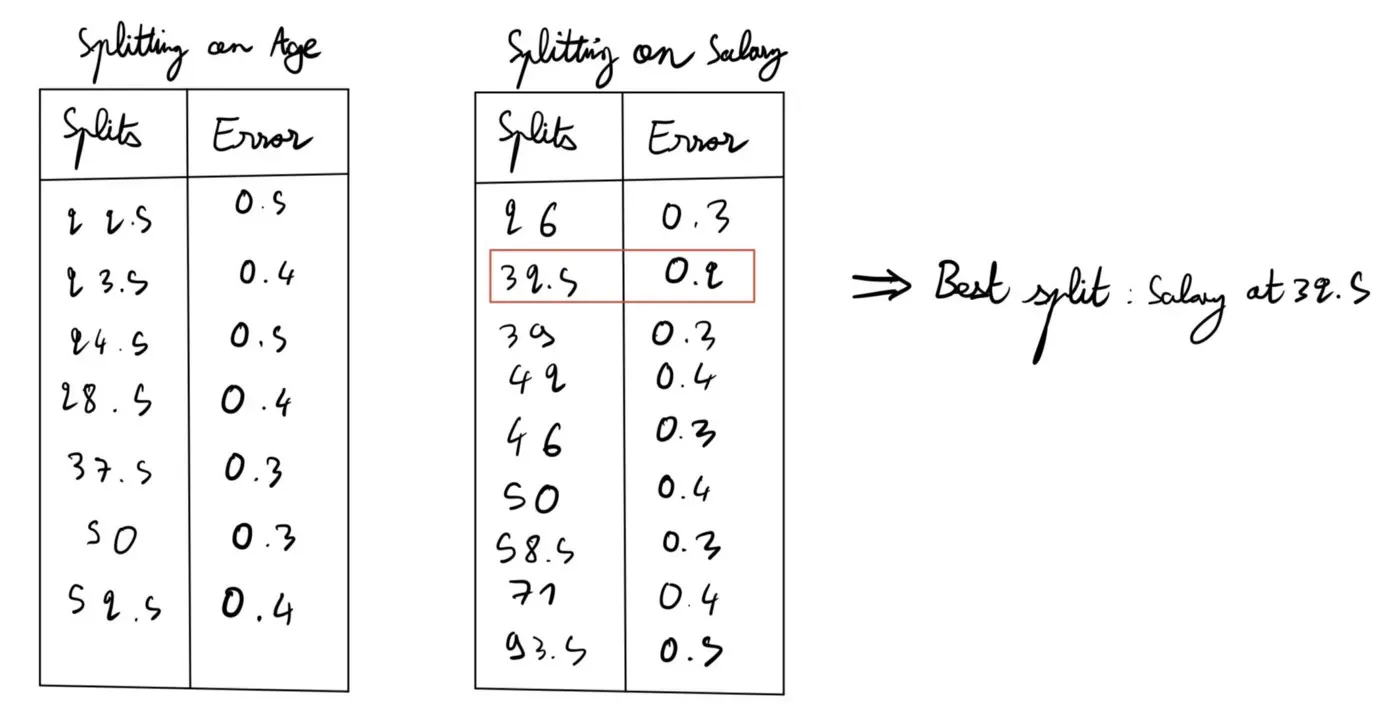
我们可以使用 Age 实现的最低错误率是 0.3,而使用 Salary 是 0.2。因此,我们将薪水分成 32.5K,并选择这个作为我们的第一个拆分。
现在,我们递归:只要我们在给定节点中没有 0 错误或没有特征,我们就会继续分裂。这是我们的树到目前为止的样子:
- 在左侧,您会看到我们不能做得更好(我们已经完美地分类了这 2 点)。因此,我们不需要进一步拆分。
- 在右侧,我们仍然可以根据年龄进行拆分,并且可能会做得更好。
让我们计算年龄的所有可能拆分。在这里,我们有 8 个数据点而不是 10 个,因为我们只使用树右侧的数据点。
我们开始像之前所做的那样对数据点进行排序。

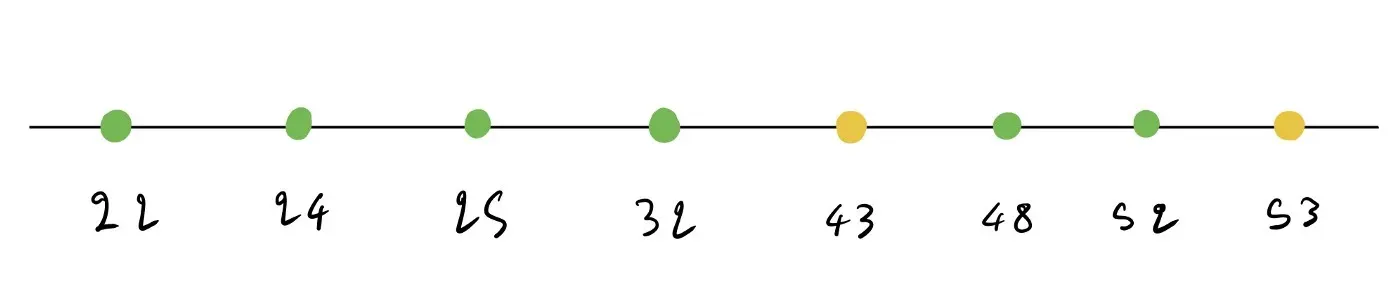
现在,我们得到以下拆分列表。


因此,我们在 52.5 的年龄上进行拆分,如果年龄低于 52.5,则预测是,如果年龄高于 52.5,则预测否。这给了我们以下树:

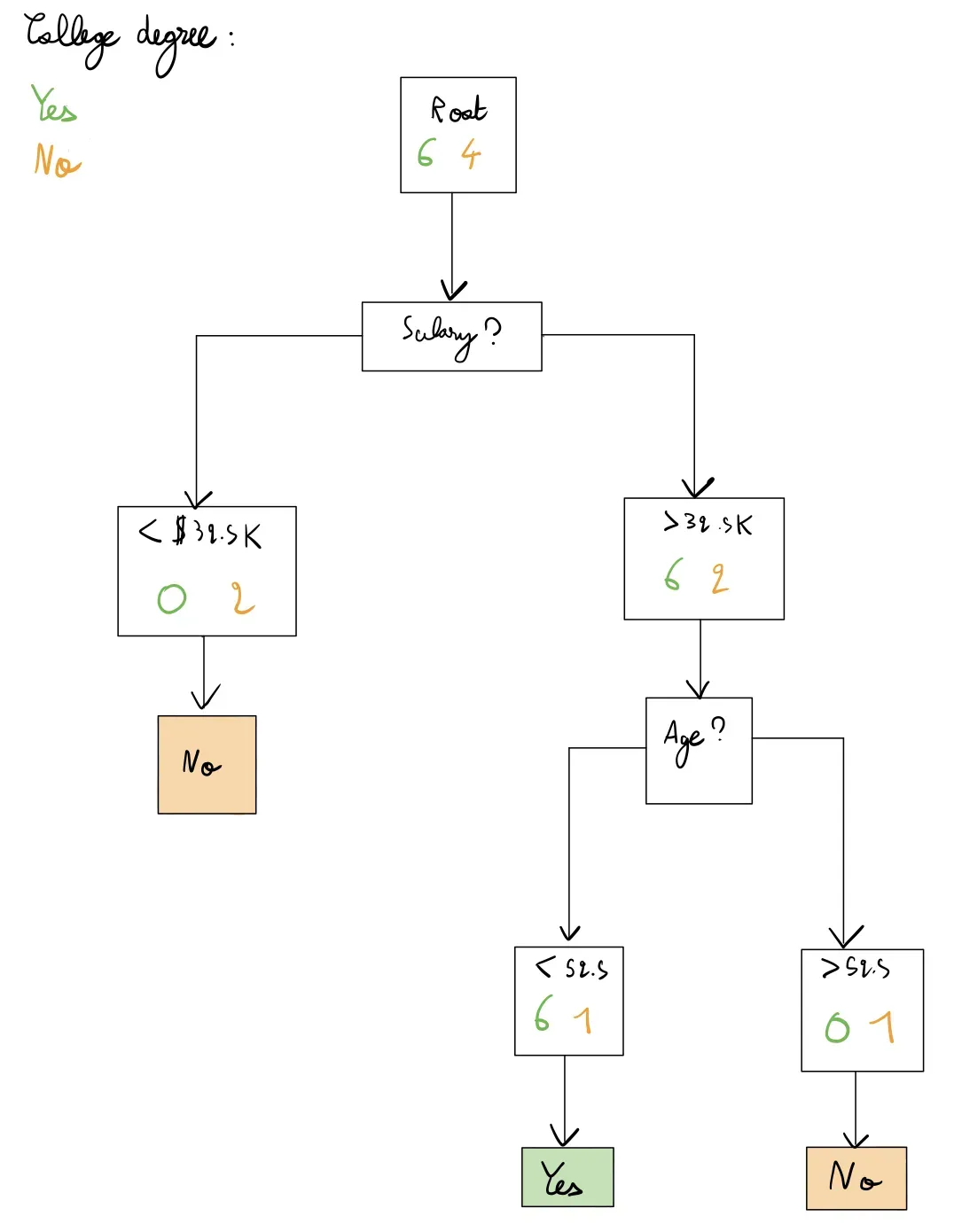
我们的最终树的错误率为 0.1,因为它只会将 1 个点误分类为是而不是否。我们无法进一步拆分,因为我们没有要拆分的特征。
Categorical Features
如果您有分类而不是数字特征,则过程与上述相同。您只需对您拥有的值进行拆分。
例如,如果你有一个分类特征来指示某人是住在农村还是住在城市,你会对此进行拆分,看看它的表现如何。然后,您将与其他功能进行比较。基本相同的过程。这就是为什么我首先介绍了数字特征,因为分类特征基本相同,但你已经有了拆分。
什么时候停止种树?
早些时候,我们没有可以拆分的其他特征(我们有 2 个特征,Age 和 Salary,并且拆分了两次)。因此,这个问题没有提出来。
在实践中,你将拥有更多的特征,你将能够分裂更多,让你的树长得更大,
正如我在前一篇文章中所介绍的,您将在这里进行偏差-方差权衡。树越深,它就越适合数据集,但过拟合的风险就越高。您的树将开始捕捉数据的噪音。因此,出现了何时停止种植树木的问题。[0]
有两种主要技术:早期停止和修剪。
在提前停止中,您根据给定条件停止在树的给定节点上进行拆分。以下是早期分裂条件的示例:
- 设置叶节点所需的最小样本数
- 设置树的最大深度
在修剪中,您只需像我们之前所做的那样构建树,并构建一个比提前停止更复杂的树。然后,根据给定条件删除一些节点。
两者都有其优点和缺点,并在实践中使用。我建议为此查看 Scikit-learn 文档。我介绍的参数称为 pruning、max_depth 和 min_samples_leaf。还有很多,我建议尽可能多地浏览文档。[0]
Random Forest
现在,如何构建一个随机森林分类器?简单的。
首先,您创建一定数量的决策树。然后,您从数据集中统一采样(有替换),采样次数与您在数据集中拥有的示例数量相同。因此,如果您的数据集中有 100 个示例,您将从其中采样 100 个点。替换意味着一旦您对给定点进行了采样,您就不会将其从数据集中移除(您基本上可以对同一点进行两次采样)。
这为我们提供了以下构建随机森林分类器的过程:
- 从您的数据集中替换样本
- 在此子数据集上训练其中一个决策树
- 重复所需数量的树
一旦你有了你的决策树集,你只需进行多数表决。在我们之前的示例中,假设您已经训练了 100 个决策树。对于给定的示例,如果 64 棵树预测为“是”,36 棵树预测“否”,那么您将预测为“是”。
Going further
我在本文中保持了相对较高的水平,并没有涵盖一些内容,例如可用于拆分的不同指标以及树如何解决回归问题。您还可以在 Scikit-learn 文档中找到更多参数。
但是,对于以前没有使用过这个算法的人来说,这应该是一个坚实的基础。我建议在一张纸上重新计算,看看是否得到相同的结果。这确实有助于理解算法。
我最近写了一篇关于 Ridge 和 Lasso 的文章,这两种用于回归问题的正则化算法。尽管它们不能用于分类,但本文将帮助您了解偏差-方差权衡。这在决策树的上下文中很有用,可以理解为什么在训练树或修剪它们时应该提前停止。[0]
我希望你喜欢这个教程!让我知道你的想法。
随时在 LinkedIn 和 GitHub 上联系,以讨论更多关于数据科学和机器学习的信息,并在 Medium 上关注我![0][1][2]
文章出处登录后可见!